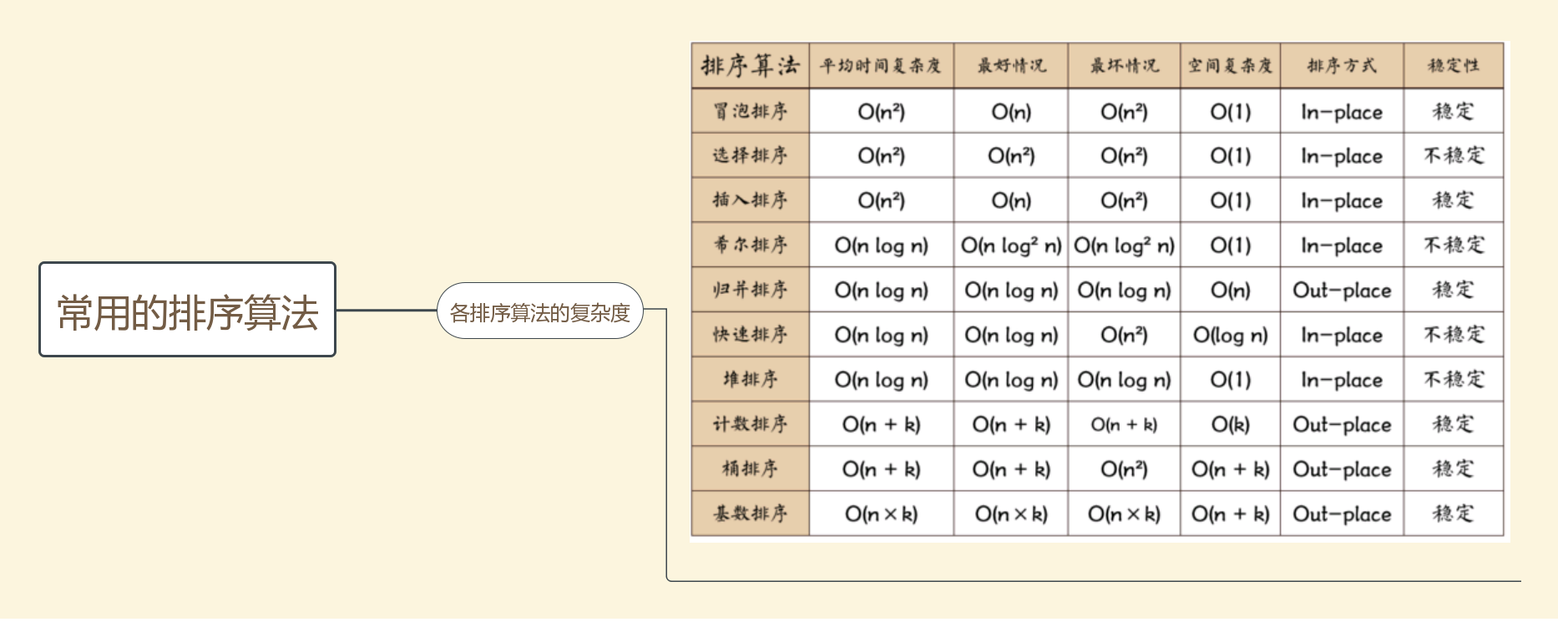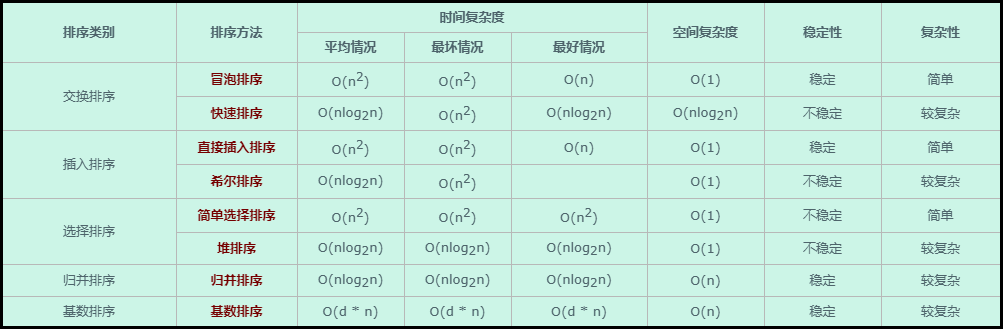
针对排序算法,网上有比较好的讲解,参考自:程序员内功:八大排序算法和 程序员的内功——数据结构和算法系列 这里主要是学习过程中的重新记录,记录典型的排序算法实现模板;
排序算法稳定性讲解:
https://www.cnblogs.com/codingmylife/archive/2012/10/21/2732980.html
https://blog.csdn.net/qq_43152052/article/details/100078825
排序的稳定性:首先,排序算法的稳定性大家应该都知道,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj,Ai原来在位置前,排序后Ai还是要在Aj位置前。算法有的可以稳定,也可以不稳定(冒泡排序),稳定否要看算法是否符合稳定的定义;
冒泡排序:简单交换,从左端开始从大到小开始冒泡;每次冒泡后,最大值归位;减治思想,缩小问题规模;


#include <iostream> #include <cstdio> #include <vector> using namespace std; vector<int> inarray; int main(){ freopen("in.txt", "r", stdin); // 重定向到输入 int i = 0; int tmp; // 方法1 while (cin >> tmp) { inarray.push_back(tmp); // cout << inarray[i] << endl; i++; } int num = i; cout << "输入数据:" << endl; for(i = 0; i < num; i++){ cout << inarray[i] << " "; } cout << endl << endl; cout << "排序过程:" << endl; for(i=1; i < num; i++){ for (int j = 0; j < num-i;j++){ if(inarray[j] >= inarray[j+1]){ int tmp = inarray[j]; inarray[j] = inarray[j+1]; inarray[j+1] = tmp; } } for(int k = 0; k < num; k++){ cout << inarray[k] << " "; } cout << endl; } for(i = 0; i < num; i++){ cout << inarray[i] << " "; } cout << endl; return 0; }
输入数据: 9 8 7 6 5 4 3 2 1 0 排序过程: 8 7 6 5 4 3 2 1 0 9 7 6 5 4 3 2 1 0 8 9 6 5 4 3 2 1 0 7 8 9 5 4 3 2 1 0 6 7 8 9 4 3 2 1 0 5 6 7 8 9 3 2 1 0 4 5 6 7 8 9 2 1 0 3 4 5 6 7 8 9 1 0 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
快速排序:通过一趟排序将排序的数据分割成独立的两部分,分割点左边都是比它小的数据,右边都是比它大的数; 使用分治方法,缩小问题规模,递归求解;
实现方法:
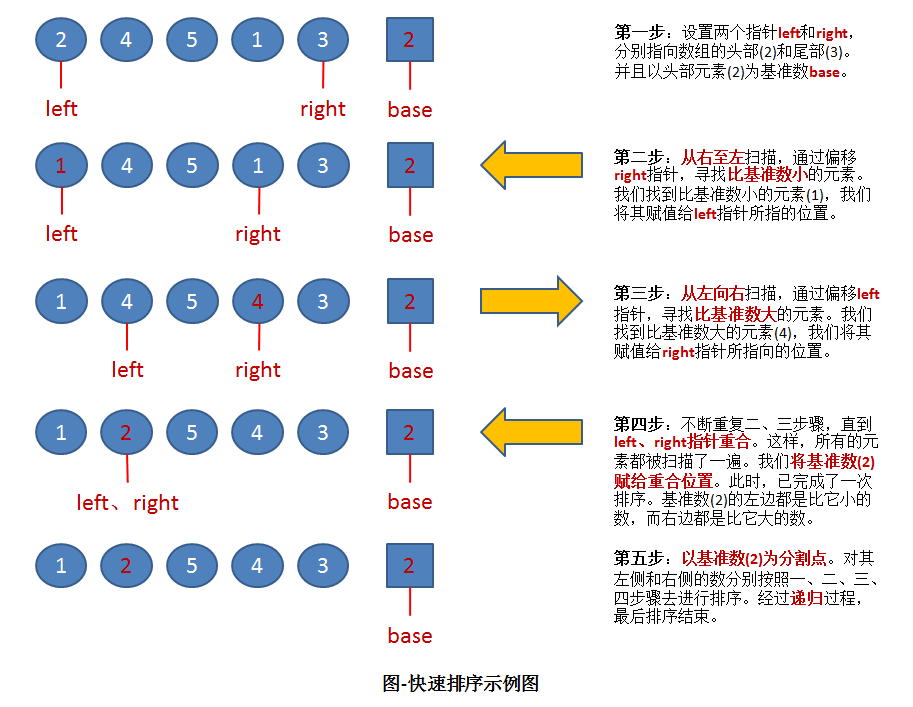
#define DEBUG 1 #include <iostream> #include <cstdio> #include <vector> using namespace std; void printarray(vector<int> &arr, int left, int right); // 分解 第一版本; int divide_1(vector<int> &arr, int left, int right){ int base = arr[left]; // 选取第一个元素为left; if(DEBUG){ cout << endl << "base:" << base << " " << "left:" << left << " " << "right:" << right << endl; } while (true) { while (arr[right] >= base && right > left) { right --; } if (right == left){ printarray(arr, left, right); break; } arr[left] = arr[right]; arr[right] = base; left ++; printarray(arr, left, right); while (arr[left] <= base && left < right) { left ++; } if (left == right){ printarray(arr, left, right); break; } arr[right] = arr[left]; arr[left] = base; right --; printarray(arr, left, right); } return left; // 返回当前 base 所在的索引 } // 分解第二版本 int divide_2(vector<int> &arr, int left, int right){ int base = arr[left]; while (left < right) { while (left < right && base <= arr[right]) { right --; } arr[left] = arr[right]; while (left < right && arr[left] <= base) { left ++; } arr[right] = arr[left]; } arr[left] = base; return left; // 返回当前base的索引; } // 快速排序算法 void quicksort(vector<int> &arr, int left, int right){ // 设置递归出口 if (left >= right){ return; } int baseindex = divide_1(arr, left, right); quicksort(arr, left, baseindex-1); quicksort(arr, baseindex+1, right); // 快速排序算法,强调对问题原有数据的分解; // 每分解一次,一个元素归位;为减治; // 每分解一次,转化为两个独立的子问题;为分治; } // 打印函数; void printarray(vector<int> &arr, int left, int right){ if((left == -1 && right== -1)|| DEBUG){ for(int i = 0; i < arr.size(); i++){ cout << arr[i] << " "; } cout << endl; } if((left != -1&&right != -1)&& DEBUG){ cout << "left:" << left << " " << "right:" << right << endl; } } int main(){ vector<int> arr; freopen("in.txt", "r", stdin); // 重定向到输入 int i = 0; int tmp; while (cin >> tmp) { arr.push_back(tmp); // cout << inarray[i] << endl; i++; } int num = i; cout << "输入数据:" << endl; printarray(arr, -1, -1); cout << endl; if (DEBUG){ cout << "排序过程:" << endl; } // 快速排序算法调用;其他代码为调试输出代码; quicksort(arr, 0, num-1); if (DEBUG){ cout << endl; } cout << "排序结果:" << endl; printarray(arr, -1, -1); return 0; }
bash-3.2$ c++ 快速排序.cc; ./a.out 输入数据: 7 8 9 6 5 4 3 2 1 排序过程: base:7 left:0 right:8 1 8 9 6 5 4 3 2 7 left:1 right:8 1 7 9 6 5 4 3 2 8 left:1 right:7 1 2 9 6 5 4 3 7 8 left:2 right:7 1 2 7 6 5 4 3 9 8 left:2 right:6 1 2 3 6 5 4 7 9 8 left:3 right:6 1 2 3 6 5 4 7 9 8 left:6 right:6 base:1 left:0 right:5 1 2 3 6 5 4 7 9 8 left:0 right:0 base:2 left:1 right:5 1 2 3 6 5 4 7 9 8 left:1 right:1 base:3 left:2 right:5 1 2 3 6 5 4 7 9 8 left:2 right:2 base:6 left:3 right:5 1 2 3 4 5 6 7 9 8 left:4 right:5 1 2 3 4 5 6 7 9 8 left:5 right:5 base:4 left:3 right:4 1 2 3 4 5 6 7 9 8 left:3 right:3 base:9 left:7 right:8 1 2 3 4 5 6 7 8 9 left:8 right:8 1 2 3 4 5 6 7 8 9 left:8 right:8 排序结果: 1 2 3 4 5 6 7 8 9
排序类型:交换排序;
排序方法:快速排序;
时间复杂度:
数据基本有序的时候,以第一个元素为基准,二分后;第一个子序列为空;此时效率较差;
当随机分布的时候,两个子序列的元素个数相接近的时候,此时效率最好;
最好时间复杂度:nlogn;
最坏时间复杂度:n2;
空间复杂度:因为每次排序,都需要1个空间,存储base;所以空间复杂度为 logn;最坏的时候为n;
算法稳定性:因为排序过程中,相等的元素可能会因为分区而交换顺序;所以不是稳定的算法;
快速排序为什么比冒泡排序快:因为快速排序利用分治的算法,把当前数据分为大于base的数组和小于base的数组;这样可以减少两个数组间的元素比较,而分治成两个独立的子问题;所以能够减少比较次数,从而加快了排序的速度;
直接插入排序:直接插入排序每一趟,将一个等待排序的记录,按照关键字的大小插入到前面有序队列中;直到扫描所有的数字后,每次都有一个数字归位排序完成;减治,缩小问题规模;
#define DEBUG 1 #include <iostream> #include <cstdio> #include <vector> using namespace std; void printarray(vector<int> &arr); //直接插入排序 void insertsort(vector<int> &arr){ int toins; for(int i =1; i < arr.size(); i++){ toins = arr[i]; cout << "toins: " << toins << endl; int j; // 进行循环挪动左侧有序数组,找到待插入位置 for (j = i-1; j >=0; j--) { if(arr[j]>= toins){ arr[j+1] = arr[j]; }else{ break; } } arr[j+1] = toins; // 进行插入数组 printarray(arr); } } // 打印函数; void printarray(vector<int> &arr){ for(int i = 0; i < arr.size(); i++){ cout << arr[i] << " "; } cout << endl; if(DEBUG){ //cout << "left:" << left << " " << "right:" << right << endl; } } int main(){ vector<int> arr; freopen("in.txt", "r", stdin); // 重定向到输入 int i = 0; int tmp; while (cin >> tmp) { arr.push_back(tmp); // cout << inarray[i] << endl; i++; } int num = i; cout << "输入数据:" << endl; printarray(arr); cout << endl; if (DEBUG){ cout << "排序过程:" << endl; } // 插入排序算法调用;其他代码为调试输出代码; insertsort(arr); if (DEBUG){ cout << endl; } cout << "排序结果:" << endl; printarray(arr); return 0; }
bash-3.2$ c++ 直接插入排序.cc ; ./a.out 输入数据: 7 6 5 3 4 2 1 排序过程: toins: 6 6 7 5 3 4 2 1 toins: 5 5 6 7 3 4 2 1 toins: 3 3 5 6 7 4 2 1 toins: 4 3 4 5 6 7 2 1 toins: 2 2 3 4 5 6 7 1 toins: 1 1 2 3 4 5 6 7 排序结果: 1 2 3 4 5 6 7
排序类型:插入排序;
关键操作:元素比较次数;
时间复杂度:
最好时间复杂度:当数据在正序的时候,执行效率最好;时间复杂度为n;
最坏时间复杂度:当数据为逆序的时候,执行效率最差;时间复杂度为n2;
空间复杂度:不过使用交换还是插入,都需要使用一个空间存储要插入的值,复杂度为1;
算法稳定性:主要还是看实现方式,基本上是稳定的算法;当然也能实现为不稳定的;
优化方法:寻找插入位置的时候,可以使用二分查找来进行优化;
希尔排序:希尔排序
保持更新,转载请注明出处;更多内容请关注cnblogs.com/xuyaowen;
注:本题图整理自参考博客;