1.其他通信协议
sftp为ssh的一部分更安全。ping基于ICMP协议(是TCP/IP协议族的一个子协议),ping:是否ping通,丢包率,延迟时间。ping是不能加端口的,telnet可加端口。
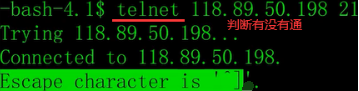
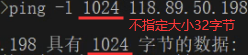
ftp21,ssh22,telnet23,http80,以下是ssh的两种实现
第一种:
本地到虚拟机(sftp),虚拟机到阿里云(ftp)

get取文件,get -r取文件夹

第二种:

2.linux环境变量


所有可执行程序都要PATH指定,比如ls,pwd不加./,因为在冒号分隔的几个目录下找,PATH在env中可查看




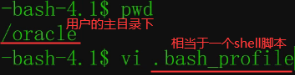


下面对所有用户有效




3.动静态库
3.1 源代码组织
我们通常把公用的自定义函数和类从主程序中分离出来,函数和类的声明在头文件中,定义在程序文件中,主程序中要包含头文件,编译时要和程序文件一起编译。
// public.h
#ifndef PUBLIC_H
#define PUBLIC_H 1
#include <stdio.h>
void func(); // 自定义函数的声明
#endif
// public.cpp
#include "public.h" // 包含自定义函数声明的头文件
void func() // 自定义函数的实现
{
printf("我心匪石,不可转也。我心匪席,不可卷也。威仪棣棣,不可选也。\n");
}
// book265.cpp
#include "public.h" // 把public.h头文件包含进来
int main()
{
func();
}
编译指令:
g++ -o book265 book265.cpp public.cpp
运行效果:
./book265
我心匪石,不可转也。我心匪席,不可卷也。威仪棣棣,不可选也。
公用函数库的public.cpp是源代码,对任何人可见,没有安全性,实际开发出于技术保密,开发者并不希望提供公用函数库源代码。C/C++提供了一个保证代码安全性方法,把公共程序文件public.cpp编译成库(库分为静态库与动态库),库是一种可执行代码的二进制形式,可以与其它的源程序一起编译,也可以被操作系统载入内存执行。
3.2 静态库
静态库在编译的时候,主程序文件与静态库一起编译,把主程序与主程序中用到的库函数一起整合进了目标文件。这样做优点是在编译后的可执行程序可以独立运行,因为所使用的函数都已经被编译进去了。缺点如果所使用的静态库发生更新改变,我们的程序必须重新编译。静态库文件名的命名方式是“libxxx.a”,库名前加”lib”,后缀用”.a”,“xxx”为静态库名。如下把程序文件public.cpp编译成静态库指令:
gcc -c -o libpublic.a public.cpp
使用静态库的方法一,直接把调用者源代码和静态库文件名一起编译:
g++ -o book265 book265.cpp libpublic.a
使用静态库的方法二,采用L参数指定静态库文件的目录,-l参数指定静态库名:
g++ -o book265 book265.cpp -L/home/w/demo -lpublic
./book265
我心匪石,不可转也。我心匪席,不可卷也。威仪棣棣,不可选也。
注意:(1)如果要指定多个静态库文件的目录,用法是“-L/目录1 -L目录2 -L目录3”;(2)链接库的文件名是libpublic.a,但链接库名是”public”,不是“libpublic.a”;(3)如果要指定多个静态库,用法是“-l库名1 -l库名2 -l库名3”。
3.3 动态库
动态库在编译时并不会被连接到目标代码中,而是在程序运行时才被载入,因此在程序运行时还需要指定动态库的目录。动态库的命名方式与静态库类似,前缀相同,为“lib”,后缀变为“.so” “xxx”为动态库名。把程序文件public.cpp编译成动态库的指令:
g++ -fPIC -shared -o libpublic.so public.cpp
使用动态库的方法与使用静态库的方法相同。如果在动态库文件和静态库文件同时存在,优先使用动态库编译:
g++ -o book265 book265.cpp -L/home/w/demo -lpublic
执行程序./book265时,出现以下提示:/book265: error while loading shared libraries: libpublic.so: cannot open shared object file: No such file or directory,因为采用了动态链接库的可执行程序在运行时需要指定动态库文件的目录,Linux系统中采用LD_LIBRARY_PATH环境变量指定动态库文件的目录。采用以下命令设置LD_LIBRARY_PATH环境变量。
export LD_LIBRARY_PATH=/home/w/demo:.
注意:如果要指定多个动态库文件的目录,用法是“export LD_LIBRARY_PATH=目录1:目录2:目录3:.”,目录之间用半角的冒号分隔,最后的圆点指当前目录。接下来修改动态库中func函数的代码:
printf("我心匪石,不可转也。我心匪席,不可卷也。威仪棣棣,不可选也。\n");
改为
printf("生活美好如鲜花,不懂享受是傻瓜;\n");
printf("傻呀傻呀傻呀傻,比不上小鸟和乌鸦。\n");
printf("芳草地啊美如画,谁要不去是傻瓜;\n");
printf("我是一只傻傻鸟,独在枯枝丫上趴。\n");
重新编译动态库,无需重新编译book265,直接执行程序
g++ -fPIC -shared -o libpublic.so public.cpp
./book265
生活美好如鲜花,不懂享受是傻瓜;
傻呀傻呀傻呀傻,比不上小鸟和乌鸦。
芳草地啊美如画,谁要不去是傻瓜;
我是一只傻傻鸟,独在枯枝丫上趴。
动态库在编译的时候只做语法检查,并没有被编译进目标代码,当程序执行到动态库中的函数时才调用该函数库里的代码。动态函数库并没有整合进程序,所以程序的运行环境必须提供动态库路径。优点是,如果所使用的动态库发生更新改变,程序不需要重新编译,所以动态库升级比较方便。
3.4 动静态库优缺点
静态库:1.优点
静态链接相当于复制一份库文件到可执行程序中,不需要像动态库那样有动态加载和识别函数地址的开销,也就是说采用静态链接编译的可执行程序运行更快。
2.缺点
1)静态链接生成的可执行程序比动态链接生成的大很多,运行时占用的内存也更多。
2)库文件的更新不会反映到可执行程序中,可执行程序需要重新编译。
动态库:1.优点
1)相对于静态库,动态库在时候更新(修复bug,增加新的功能)不需要重新编译。
2)全部的可执行程序共享动态库的代码,运行时占用的内存空间更少。
2.缺点
1)使可执行程序在不同平台上移植变得更复杂,因为它需要为每每个不同的平台提供相应平台的共享库。
2)增加可执行程序运行时的时间和空间开销,因为应用程序需要在运行过程中查找依赖的库函数,并加载到内存中。
3.5 编译的优先级
静态库与动态库各有优缺点,该怎么选择,要看应用的场景。所谓有得必有失,动态库在程序运行时被链接,故程序的运行速度和链接静态库的版本相比必然会打折扣。然而瑕不掩瑜,动态库的不足相对于它带来的好处在现今硬件下简直是微不足道的,所以链接程序在链接时一般是优先链接动态库,除非用-static参数指定链接静态库。
4.Linux中文字符集
4.1 字符编码和字符集
1.字符编码(character encoding)
字符编码是一种法则,在数字与符号之间建立的对应关系。不同的国家有不同的语言,包含的文字、标点符号、图形符号各有不同。例如在ASCII编码中,用数字97表达字符’a’与字符集相对应,常见的字符编码有ASCII,GBK,GB18030,Unicode等。
2.字符集(Character set)
字符集是字符的集合,字符是文字和符号的总称,用ASCII编码的字符集称之为ASCII字符集,用GBK编码的字符集称之为GBK字符集。
3.国际编码(Unicode)
为了解决传统的字符编码方案的局限,1994年发布了Unicode(国际编码、统一码、万国码、单一码、通用码),它是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 将全世界所有的字符统一化,统一编码,再也不存在字符集不兼容和字符转换的问题。
Unicode 有以下三种编码方式:
1)UTF-8:兼容ASCII编码;拉丁文、希腊文等使用两个字节;包括汉字在内的其它常用字符使用三个字节;剩下的极少使用的字符使用四个字节。
2)UTF-16:对相对常用的60000余个字符使用两个字节进行编码,其余的使用4字节。
3)UTF-32:固定使用4个字节来表示一个字符,存在空间利用效率的问题。
4.2 汉字的编码
1.汉字的编码
支持汉字(简体中文)的编码有GB2312、GB13000、GBK、GB18030和Unicode(UTF-8、UTF-16、UTF-32)。
1)GB2312
仅包含大部分的常用简体汉字,但已经不能适应现在的需要。
2)GB13000
由于GB2312的局限性,国家标准化委员会制定了GB13000编码; 但由于当时的硬件和软件都已经支持了GB2312,而GB13000与GB2312完全不兼容,所以没有能够得到大范围的推广使用。
3)GBK
有了GB13000的教训,中国国家标准化委员会制定了GBK标准,并兼容了GB2312标准,同时在GB2312标准的基础上扩展了GB13000包含的字; 由于该标准有微软的支持,得到了广泛的应用。
4)GB18030
GB18030编码比GBK又新增了几千个汉字,但由于码位不足使用了2byte与4byte混合编码方式,这给软件开发增加了难度。
5)Unicode
包含全世界所有国家需要用到的字符,是国际编码,通用性强。
2.汉字的编码选择
在操作系统和数据库中,常用的汉字编码有GBK、GB18030和Unicode,GBK和GB18030的优势是占用空间小,Unicode的优势是全球化的支持。
在应用开发中,如果不考虑全球化,最好的选择是GBK和GB18030。
3.编码的转换
GBK和GB18030与Unicode编码之间需要转换,否则会出现汉字乱码。
4.3 设置Linux的字符集
1、查看当前系统已安装的字符集
1)locale命令用于查看当前系统全部的已安装的字符集,Linux支持的符集约800种。
locale -a
2)查看已安装的中文字符集(只查看中国大陆的,不包括香港和台湾)
locale -a|grep zh_CN
上图表示已经安装了中文字符集。
2.安装中文字符集
如果您的Linux系统没有安装中文字符集,可以用yum命令安装。
我查了一些资料,安装中文字符集软件包的方法比较多,没找到准确的说法,所以把多种方法都写了进来,以下命令都可以执行,不会有副作用。
yum -y groupinstall chinese-support
yum -y install chinese-support
yum -y install kde-l10n-Chinese
yum -y install ibus-table-chinese-1.4.6-3.el7.noarch
安装后,执行locale -a|grep zh_CN,如果显示的内容如下,表示安装成功。
3.修改字符集配置文件
CentOS6.x字符集配置文件在/etc/sysconfig/i18n文件中。
CentOS7.x字符集配置文件在/etc/locale.conf文件中,内容如下
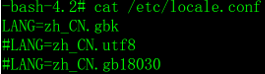
执行以下命令或者重启系统使修改生效。
CentOS6.x:source /etc/sysconfig/i18n
CentOS7.x:source /etc/locale.conf
4.centos7修改 /etc/locale.conf 不生效
centos7的语言环境变量是通过/etc/profile.d/lang.sh加载locale.conf来设置的。我在修改 /etc/locale.conf 内容为 LANG=“zh_CN.UTF-8” 并重启后发现并没有什么效果。local得出的依然是默认的en_US。于是我去检查lang.sh的代码。发现中间有一段是这样的:

可以看到,当变量为zh*的时候,依然将LANG赋值为en_US.UTF-8。不知道官方为什么会采用这种默认设置,所以我将代码改成这样。重启之后,再次查看locale,就好了。

5.Oracle的字符集
1.字符集和国家字符集
字符集在创建数据库实例时指定,可以指定字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。
1)字符集(CHARACTER SET)
用来存储char、varchar2、clob、long等类型数据,还可以用来标识表名、列名以及PL/SQL变量等。
2)国家字符集(NATIONAL CHARACTER SET)
用以存储nchar、nvarchar2、nclob等类型数据。国家字符集实质上是为Oracle选择的附加字符集,主要作用是为了增强字符处理能力,因为nchar数据类型可以提供对亚洲使用定长多字节编码的支持,而数据库字符集则不一定能。国家字符集只能在unicode编码中的AF16UTF16和UTF8中选择,默认值是AF16UTF16。
2.支持中文的字符集
Oracle支持汉字(简体中文,繁体不介绍)的字符集有多种,常用的有ZHS16GBK、UTF8、AL32UTF8和AL16UTF16。
1)ZHS16GBK
表示简体中文,一个字符需要16位比特,采用GBK编码标准。
2)UTF8
Oracle从8i版本开始使用的属于UTF-8编码的字符集,采用的Unicode标准为3.0,在11.2版本中,UTF8已经不是推荐字符集列表中的一员了。
3)AL32UTF8
与UTF8相比,它采用的Unicode版本更新,在10g版本中使用的是Unicode 4.01标准,而UTF8因为兼容性的考虑,在10g版本中用的是Unicode 3.0标准。
4)AL16UTF16
是ORACLE第一种采用UTF-16编码方式的字符集,从ORACLE9开始使用,是作为缺省的国家字符集使用,它不能被用作数据库的字符集。
3.NLS_LANG参数
Oracle数据库字符集最重要的参数是NLS_LANG参数。
格式: NLS_LANG=‘language_territory.charset’,不区分大小写,例如’ SIMPLIFIED CHINESE_CHINA.ZHS16GBK’。
它有三个组成部分:语言(language)、地域(territory)和字符集(charset)。
其中:
language:数据库服务器提示信息的语言。
territory:数据库的日期和数字格式,意义不大。
charset:数据库的字符集。
真正影响数据库字符集的其实是第三部分charset,两个数据库之间的字符集只要第三部分相同,交换数据时中文不会出现乱码。language影响的只是提示信息是中文还是英文。
5.1 服务端的字符集
1.查看服务端字符集
执行以下SQL可以查看服务端的字符集。
select * from NLS_DATABASE_PARAMETERS where parameter like ‘%CHARACTERSET%’;

执行以下SQL也可以查看服务端的字符集。
select userenv(‘language’) from dual;
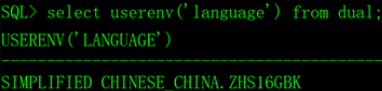
2.修改服务端字符集
Oracle数据库实例创建后,如果没有开始业务运行,可以修改字符集,如果已经业务化运行,不建议修改字符集,会造成数据中的汉字乱码。
用DBA权限,执行以下步骤修改Oracle数据库的字符集(例如修改为ZHS16GBK)。
1)修改服务端操作系统的NLS_LANG环境变量。
export NLS_LANG=‘Simplified Chinese_China.ZHS16GBK’
2)关闭Oracle数据库。
shutdown immediate;
3)把数据库启动到mount状态。
startup mount;
4)把数据库改为restricted模式。
alter system enable restricted session;
alter system set job_queue_processes=0;
alter system set aq_tm_processes=0;
5)打开数据库。
alter database open;
6)修改数据库的字符集。
alter database character set internal_use ZHS16GBK;
7)重启数据库。
shutdown immediate;
startup;
5.2 客户端的字符集
Oracle客户端的字符集必须与服务端相同,否则中文会出现乱码。
1.Linux环境
客户端的字符集由NLS_LANG环境变量控制。
1)查看NLS_LANG环境变量。
env|grep NLS_LANG

2)设置环境变量
修改环境变量参数文件(系统或用户的profile文件)。
export NLS_LANG=‘Simplified Chinese_China.ZHS16GBK’
2.Windows环境
打开注册表( 执行regedit.exe)
HKEY_LOCAL_MACHINE -> SOFTWARE -> ORACLE -> KEY_OraClient11g_home1

应用经验:1)数据库在业务化之前,就应该确定Oracle的字符集,然后不再改变。数据库在业务化后,修改字符集是一件很麻烦的事情,最好别惹这个麻烦。
2)如果项目没有全球化的需求,数据库字符集建议采用ZHS16GBK,操作系统语言建议采用gbk。
3)设置客户端的字符集与服务端相同,就不会有乱码,没什么技术难点。
4)虽然GB18030字符集比GBK更丰富,但是GB18030中有部分汉字是4字节,这一点让程序员很郁闷,所以,程序员更倾向GBK字符集。
5.3 linux文件编码的转换
iconv命令用于文件编码的转换,碰到gbk编码的文件,需要转换成utf8,直接使用该命令即可。
iconv --list :列出iconv支持的编码列表
iconv -f 原编码 -t 新编码 filename -o newfile
-f : from 来源编码
-t : to 转换后新编码
-c: 忽略无效字符
-s: --silent,忽略警告
-o file : 可选,没有的话直接转换当前文件, 使用-o 保留源文件。
# 查看文件
$ file test
test: UTF-8 Unicode text
# 转换
$ iconv -f utf8 -t gbk test -o test.gbk
$ ll
-rw-rw-r-- 1 work work 117 Aug 9 19:29 test
-rw-rw-r-- 1 work work 83 Aug 9 19:31 test.gbk
# 查看文件
$ file test*
test: UTF-8 Unicode text
test.gbk: ISO-8859 text
