train数据集包括x_train和y_train
1、代码不完全按照那四个来处理
没有train.names[0:-1]去除最后一列
model1 = H2ORandomForestEstimator() # 初始化(建立)模型
model1.train(x = train.names,y = 'Catrgory',training_frame = train) # 训练模型
没有test[test.names[0:-1]]删除最后一列
predict=H2ORandomForestEstimator.predict(model1 ,test) # 对测试集进行预测
tmp = predict[predict['predict'] == test['Catrgory']].nrow
accuracy = tmp/test.nrow
accuracy
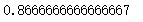
2、代码完全正确,完全按照那四个来处理
train.names[0:-1]去除最后一列
model1 = H2ORandomForestEstimator() # 初始化(建立)模型
model1.train(x = train.names[0:-1],y = 'Catrgory',training_frame = train) # 训练模型 train.names[0:-1]去除最后一列
test[test.names[0:-1]]删除最后一列
predict=H2ORandomForestEstimator.predict(model1 ,test[test.names[0:-1]]) # 对测试集进行预测 test[test.names[0:-1]]删除最后一列
tmp = predict[predict['predict'] == test['Catrgory']].nrow
accuracy = tmp/test.nrow
accuracy
