# 1 框架 不是 模块 # 2 号称爬虫界的django(你会发现,跟django很多地方一样) # 3 安装 -mac,linux平台:pip3 install scrapy -windows平台:pip3 install scrapy(大部分人可以) - 如果失败: 1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs 3、pip3 install lxml 4、pip3 install pyopenssl 5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/ 6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl 8、pip3 install scrapy # 4 在script文件夹下会有scrapy.exe可执行文件 -创建scrapy项目:scrapy startproject 项目名 (django创建项目) -创建爬虫:scrapy genspider 爬虫名 要爬取的网站地址 # 可以创建多个爬虫 # 5 启动爬虫 -scrapy crawl 爬虫名字 -scrapy crawl 爬虫名字 --nolog # 6 不在命令行下执行爬虫 -在项目路径下创建一个main.py,右键执行即可 from scrapy.cmdline import execute # execute(['scrapy','crawl','chouti','--nolog']) # 不打印log,可以在其他地方设置log execute(['scrapy','crawl','chouti'])
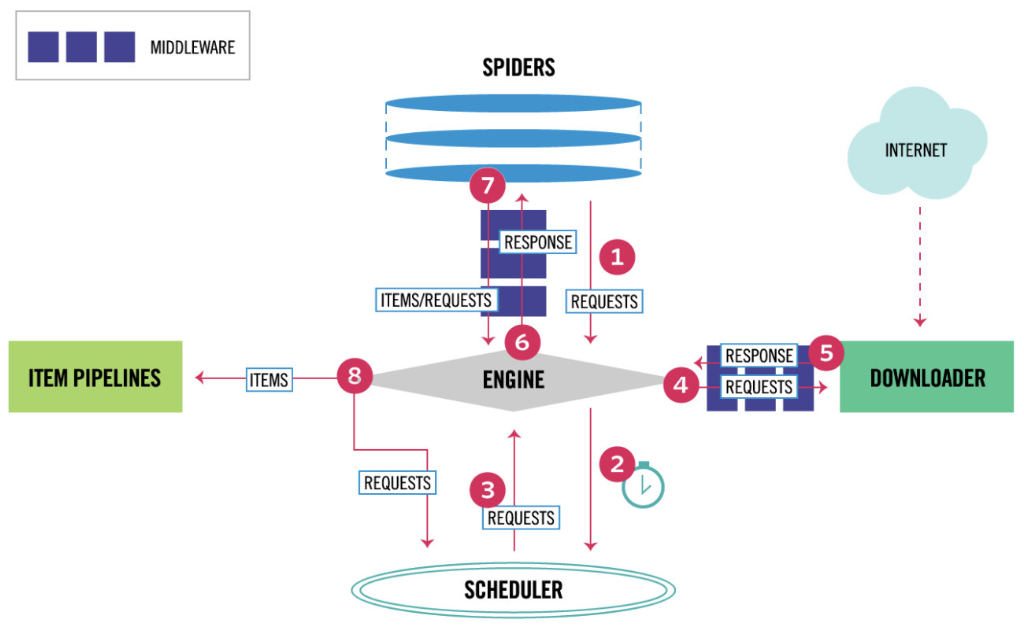
# 1 爬虫起始地址包装成requests发给engine # 2 判断如果是请求,发给SCHEDULER进行调度 # 4 把请求通过下载中间件,发给DOWNLOADER,朝网络发请求(scrapy基于twisted模块io多路复用,同一时刻发送大量请求给网络)[这就是为什么scrapy性能高,因为此处io多路复用模型] # 5 响应回来,穿过下载中间件 # 6 engin吧response通过爬虫中间件返回spiders,就是回调 (这就是为什么spiders类解析parse方法能拿到response) # 7 把解析出items或者requests返回engine # 8 如果是items发给item pipelines保存处理,如果是requests对象,在发给scheduler调度器准备再次爬取(3,4,5,6) # 引擎(EGINE)(大总管) 引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。 # 调度器(SCHEDULER) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 # 下载器(DOWLOADER) 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的 # 爬虫(SPIDERS) SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求 # 项目管道(ITEM PIPLINES) 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 # 两个中间件 -爬虫中间件 -下载中间件(用的最多,加头,加代理,加cookie,集成selenium)
-crawl_chouti # 项目名 -crawl_chouti # 跟项目一个名,文件夹 -spiders # spiders:放着爬虫 genspider生成的爬虫,都放在这下面 -__init__.py -chouti.py # 抽屉爬虫 -cnblogs.py # cnblogs 爬虫 -items.py # 对比django中的models.py文件 ,写一个个的模型类 -middlewares.py # 中间件(爬虫中间件,下载中间件),中间件写在这 -pipelines.py # 写持久化的地方(持久化到文件,mysql,redis,mongodb) -settings.py # 配置文件 -scrapy.cfg # 不用关注,上线相关的 # 配置文件 settings.py ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,强行运行 USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36' # 请求头中的ua LOG_LEVEL='ERROR' # 这样配置,程序错误信息才会打印, 增加字段,必须大写 #启动爬虫直接 scrapy crawl 爬虫名 就没有日志输出 # scrapy crawl 爬虫名 --nolog # 爬虫文件 spiders文件夹下 class ChoutiSpider(scrapy.Spider): name = 'chouti' # 爬虫名字 allowed_domains = ['https://dig.chouti.com/'] # 允许爬取的域 start_urls = ['https://dig.chouti.com/'] # 起始爬取的位置,爬虫一启动,会先向它发请求 def parse(self, response): # 解析,请求回来,自动执行parser,在这个方法中做解析 response为响应对象 print('---------------------------',response)
# 1 解析,可以使用bs4解析 from bs4 import BeautifulSoup soup=BeautifulSoup(response.text,'lxml') soup.find_all() # 2 内置的解析器 # response.css # response.xpath # 解析 # 所有用css或者xpath选择出来的都放在列表中 # 取第一个:extract_first() # 取出所有extract() # css选择器取文本和属性: # .link-title::text # .link-title::attr(href) # xpath选择器取文本和属性 # .//a[contains(@class,"link-title")/text()] #.//a[contains(@class,"link-title")/@href]
css选择器代码示例:
# crawl_chouti/crawl_chouti/spiders/chouti.py import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['https://dig.chouti.com/'] start_urls = ['https://dig.chouti.com//'] def parse(self, response): # print('------------',response) # print(type(response)) # from scrapy.http.response.html import HtmlResponse ## 解析 用css解析 # 所有用css或者xpath选择出来的都放在列表中 # 取第一个:extract_first() # 取所有:extract() # 需要取列表的第一个值 div_list = response.css('div.link-item') for div in div_list: title = div.css('.link-title::text').extract_first() # .link-title::text取出文本 url = div.css('.link-title::attr(href)').extract_first() # .link-title::attr(href)取出href属性 img_url = div.css('.matching::attr(src)').extract_first() # print(title) # print(url) # print(img_url) print(''' 新闻标题:%s 新闻连接:%s 新闻图片:%s '''%(title,url,img_url))
xpath选择器代码示例:
# crawl_chouti/crawl_chouti/spiders/chouti.py import scrapy class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['https://dig.chouti.com/'] start_urls = ['https://dig.chouti.com//'] def parse(self, response): # xpath选择器提取数据 div_list = response.xpath('//div[contains(@class,"link-area")]') for div in div_list: title = div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first() url = div.xpath('.//a[contains(@class,"link-title")]/@href').extract_first() img_url = div.xpath('//*[contains(@class,"matching")]/@src').extract_first() print(''' 新闻标题:%s 新闻连接:%s 新闻图片:%s '''%(title,url,img_url))
# 方式一(讲完就忘了) -1 parser解析函数,return 列表,列表套字典 -2 scrapy crawl chouti -o aa.json (支持:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle') # 得到的aa.json文件可以通过 https://www.json.cn/ 解析 # 方式二 pipline的方式(管道) -1 在items.py中创建模型类 -2 在爬虫中chouti.py,引入,把解析的数据放到item对象中(要用中括号) -3 yield item对象 -4 配置文件配置管道 ITEM_PIPELINES = { # 数字表示优先级(数字越小,优先级越大) 'crawl_chouti.pipelines.CrawlChoutiPipeline': 300, 'crawl_chouti.pipelines.CrawlChoutiRedisPipeline': 301, } -5 pipline.py中写持久化的类 -spider_open # 执行pipeline一开始 (用open_spider和close_spider会加锁,保证数据不丢失) -spider_close # 执行pipeline结束 -process_item(在这写保存到哪)
# crawl_chouti/crawl_chouti/items import scrapy # 写一个模型类,用来存储解析出来的数据 class CrawlChoutiItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field() img_url = scrapy.Field() # crawl_chouti/crawl_chouti/spiders/chouti.py import scrapy from crawl_chouti.items import CrawlChoutiItem class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['https://dig.chouti.com/'] start_urls = ['https://dig.chouti.com//'] def parse(self, response): div_list = response.xpath('//div[contains(@class,"link-area")]') for div in div_list: title = div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first() # .link-title::text取出文本 url = div.xpath('.//a[contains(@class,"link-title")]/@href').extract_first() # .link-title::attr(href)取出href属性 img_url = div.xpath('//*[contains(@class,"matching")]/@src').extract_first() # print(''' # 新闻标题:%s # 新闻连接:%s # 新闻图片:%s # '''%(title,url,img_url)) item = CrawlChoutiItem() # 这种方式不行,必须使用中括号方式 # item.title = title 报错 item['title'] = title item['url'] = url item['img_url'] = img_url # 注意用yield,用return只执行一次 # return item yield item # crawl_chouti/crawl_chouti/settings.py ITEM_PIPELINES = { # 数字表示优先级(数字越小,优先级越大) 'crawl_chouti.pipelines.CrawlChoutiPipeline': 300, # 'crawl_chouti.pipelines.CrawlChoutMysqliPipeline': 301, } # crawl_chouti/crawl_chouti/pipelines.py class CrawlChoutiPipeline(object): def open_spider(self,spider): # 一开始执行 (用open_spider和close_spider会加锁,保证数据不丢失) print('我开始') # 打开文件 self.f = open('a.txt','w') # 存文件 def process_item(self, item, spider): # item为chouti返回的25个item对象 print(item) # with open('a.txt','w') as f: # 此处换a写入,如果不用open/close_spider方法,会存在写入数据丢失情况,因为在不同线程中 # f.write(item['title']) # f.write(item['url']) # f.write(item['img_url']) # f.write('\n') self.f.write(item['title']) self.f.write(item['url']) self.f.write(item['img_url']) self.f.write('\n') return item # 继续往下走,如果没有,后续的pipeline类就无法拿到 def close_spider(self,spider): # 结束时执行 print('我结束') self.f.close()
在文件和redis数据库中保存代码示例
# crawl_chouti/crawl_chouti/items import scrapy # 写一个模型类,用来存储解析出来的数据 class CrawlChoutiItem(scrapy.Item): id = scrapy.Field() title = scrapy.Field() url = scrapy.Field() img_url = scrapy.Field() # crawl_chouti/crawl_chouti/spiders/chouti.py import scrapy from crawl_chouti.items import CrawlChoutiItem class ChoutiSpider(scrapy.Spider): name = 'chouti' allowed_domains = ['https://dig.chouti.com/'] start_urls = ['https://dig.chouti.com//'] def parse(self, response): div_list = response.xpath('//div[contains(@class,"link-area")]') for div in div_list: title = div.xpath('.//a[contains(@class,"link-title")]/text()').extract_first() # .link-title::text取出文本 url = div.xpath('.//a[contains(@class,"link-title")]/@href').extract_first() # .link-title::attr(href)取出href属性 img_url = div.xpath('//*[contains(@class,"matching")]/@src').extract_first() id = div.xpath('.//a[contains(@class,"link-title")]/@data-id').extract_first() # print(''' # 新闻标题:%s # 新闻连接:%s # 新闻图片:%s # '''%(title,url,img_url)) item = CrawlChoutiItem() # 这种方式不行,必须使用中括号方式 # item.title = title 报错 item['title'] = title item['url'] = url item['img_url'] = img_url item['id'] = id # 注意用yield,用return只执行一次 # return item yield item # crawl_chouti/crawl_chouti/settings.py ITEM_PIPELINES = { # 数字表示优先级(数字越小,优先级越大) 'crawl_chouti.pipelines.CrawlChoutiPipeline': 300, 'crawl_chouti.pipelines.CrawlChoutRedisPipeline': 301, } # crawl_chouti/crawl_chouti/pipelines.py from redis import Redis class CrawlChoutiPipeline(object): def open_spider(self,spider): # 一开始 (用open_spider和close_spider会加锁,保证数据不丢失) print('我开始') # 打开文件 self.f = open('a.txt','w') # 存文件 def process_item(self, item, spider): # item为chouti返回的25个item对象 print(item) # with open('a.txt','w') as f: # 此处换a写入,如果不用open/close_spider方法,会存在写入数据丢失情况,因为在不同线程中 # f.write(item['title']) # f.write(item['url']) # f.write(item['img_url']) # f.write('\n') self.f.write(item['title']) self.f.write(item['url']) self.f.write(item['img_url']) self.f.write('\n') return item # 继续往下走,如果没有,后续的pipeline类就无法拿到 def close_spider(self,spider): # 结束 print('我结束') self.f.close() class CrawlChoutRedisPipeline(object): # 存redis数据库 def open_spider(self,spider): # 一开始执行 (用open_spider和close_spider会加锁,保证数据不丢失) self.conn = Redis(password='admin123') def close_spider(self,spider): # 结束时执行 pass def process_item(self, item, spider): import json s = json.dumps({'title': item['title'], 'url': item['url'], 'img_url': item['img_url']}) self.conn.hset('chouti_article',item['id'],s) 存入redis,'chouti_article'为redis的类 return item
# 1 生成一个动作练对象 action=ActionChains(bro) # 2 点击并夯住某个控件 action.click_and_hold(div) # 3 移动(三种方式) # action.move_by_offset() # 通过坐标 # action.move_to_element() # 到另一个标签 # action.move_to_element_with_offset() # 到另一个标签,再偏移一部分 # 4 真正的移动 action.perform() # 5 释放控件(松开鼠标) action.release()
动作链示例代码:
from selenium import webdriver from selenium.webdriver import ActionChains import time bro=webdriver.Chrome(executable_path='./chromedriver') bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') bro.implicitly_wait(10) #切换frame(很少) bro.switch_to.frame('iframeResult') #iframe是在标签内还能创建一个html标签,此处切换到内部的html中 div=bro.find_element_by_xpath('//*[@id="draggable"]') # 使用动作链 #得到一个动作练对象 action=ActionChains(bro) # 使用动作链 #点击并且夯住 action.click_and_hold(div) # 直接把上面的div移动到某个元素上 # action.move_to_element(元素控件) # 移动x坐标,y坐标 # 三种移动方式 # action.move_by_offset() # 通过坐标 # action.move_to_element() # 到另一个标签 # action.move_to_element_with_offset() # 到另一个标签,再偏移一部分 for i in range(5): action.move_by_offset(10,10) # 直接把上面的div移动到某个元素上的某个位置 # action.move_to_element_with_offset() # 调用它,会动起来 action.perform() time.sleep(1) #释放动作链 action.release() time.sleep(5) bro.close()
自动登录12306(先用selenium通过超级鹰识别登录获得cookies,然后通过cookies用requests登录)
# 12306.py # 自动登录12306 # pip3 install pillow from PIL import Image from chaojiying import Chaojiying_Client from selenium import webdriver from selenium.webdriver import ActionChains import time import json import requests bro =webdriver.Chrome(executable_path='./chromedriver') bro.get('https://kyfw.12306.cn/otn/login/init') bro.implicitly_wait(10) # 因为selenium没有直接截取某个元素的功能,现在需要截取全图,然后通过图形软件,再把小图扣出来 # bro.minimize_window() #最小化 # bro.maximize_window() #最大化 # save_screenshot 截取整个屏幕 bro.save_screenshot('main.png') tag_code =bro.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img') # 查看控件的位置和大小 size =tag_code.size location =tag_code.location print(size) print(location) img_tu = (int(location['x']) ,int(location['y']) ,int(location['x' ] +size['width']) ,int(location['y' ] +size['height'])) # # 抠出验证码 # #打开 img =Image.open('./main.png') # 抠图 fram =img.crop(img_tu) # 截出来的小图 fram.save('code.png') # 调用超级鹰,破解 def get_result(): chaojiying = Chaojiying_Client('306334xxx', 'lqzxxx', '903641') # 用户中心>>软件ID 生成一个替换 96001 im = open('code.png', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// print(chaojiying.PostPic(im, 9004)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加() return chaojiying.PostPic(im, 9004)['pic_str'] # 返回结果如果有多个 260,133|123,233,处理这种格式[[260,133],[123,233]] result=get_result() all_list=[] if '|' in result: list_1 = result.split('|') count_1 = len(list_1) for i in range(count_1): xy_list = [] x = int(list_1[i].split(',')[0]) y = int(list_1[i].split(',')[1]) xy_list.append(x) xy_list.append(y) all_list.append(xy_list) else: x = int(result.split(',')[0]) y = int(result.split(',')[1]) xy_list = [] xy_list.append(x) xy_list.append(y) all_list.append(xy_list) print(all_list) # 用动作链,点击图片 # [[260,133],[123,233]] for a in all_list: x = a[0] y = a[1] ActionChains(bro).move_to_element_with_offset(tag_code, x, y).click().perform() time.sleep(1) username=bro.find_element_by_id('username') username.send_keys("") # 用户名 pwd=bro.find_element_by_id('password') pwd.send_keys('') # 密码 submit=bro.find_element_by_id('loginSub') submit.click() #获取cookie # 使用requests模块,携带cookie朝某个接口发请求 time.sleep(3) c = bro.get_cookies() print(c) with open('xxx.json', 'w') as f: json.dump(c, f) # cookies = {} # # 获取cookie中的name和value,转化成requests可以使用的形式 # for cookie in c: # cookies[cookie['name']] = cookie['value'] # # print(cookies) # with open('xxx.json', 'r') as f: di = json.load(f) cookies = {} # 获取cookie中的name和value,转化成requests可以使用的形式 for cookie in di: cookies[cookie['name']] = cookie['value'] print('---------') print(cookies) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36', 'Referer': 'https://kyfw.12306.cn/otn/view/information.html', 'Origin': 'https://kyfw.12306.cn', 'Host': 'kyfw.12306.cn', 'Sec-Fetch-Dest': 'empty', 'Sec-Fetch-Mode': 'cors', 'Sec-Fetch-Site': 'same-origin', 'X-Requested-With': 'XMLHttpRequest', # 'Cookie':'JSESSIONID=5E0ADB0562F67D12821C1031B4C0D6C5; tk=h8F7smXhBU8PH3aIYHxCu5fR86HnywJ7BNF8sAets1s0; route=9036359bb8a8a461c164a04f8f50b252; BIGipServerpool_passport=233636362.50215.0000; RAIL_EXPIRATION=1586657272770; RAIL_DEVICEID=mWh29ziIiHHcSeSRm2Lp4kpamkdA3c6Cpi9gDQQN_rTcgI5UPn_FyMY8mdO5Vinhk4vyn_zW-rP2bmqeO8WKSzsuhOMhGru6qIQCIVDIYPEJtIF7PfoQkSD8koFHdQ9pLaUH5jwoYeYqxM6bA0GRghJELkd2zvHs; BIGipServerpassport=971505930.50215.0000; BIGipServerotn=1105723658.24610.0000' # 'Cookie':json.dumps(cookies) } #https://kyfw.12306.cn/otn/modifyUser/initQueryUserInfoApi res = requests.post('https://kyfw.12306.cn/otn/modifyUser/initQueryUserInfoApi',headers=headers, cookies=cookies ) print(res.cookies.get_dict()) print(res.text)
超级鹰代码(就是网上的测试代码改了bug,同上篇爬虫博客)


# chaojiying.py import requests from hashlib import md5 class Chaojiying_Client(object): def __init__(self, username, password, soft_id): self.username = username password = password.encode('utf8') self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { 'user': self.username, 'pass2': self.password, 'softid': self.soft_id, } self.headers = { 'Connection': 'Keep-Alive', 'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)', } def PostPic(self, im, codetype): """ im: 图片字节 codetype: 题目类型 参考 http://www.chaojiying.com/price.html """ params = { 'codetype': codetype, } params.update(self.base_params) files = {'userfile': ('ccc.jpg', im)} r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers) return r.json() def ReportError(self, im_id): """ im_id:报错题目的图片ID """ params = { 'id': im_id, } params.update(self.base_params) r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers) return r.json() if __name__ == '__main__': chaojiying = Chaojiying_Client('306334xxx', 'lqzxxx', '903641') # 用户中心>>软件ID 生成一个替换 96001 im = open('a.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要// print(chaojiying.PostPic(im, 1902)) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()