大家都知道java并发的三大根源性问题:可见性,有序性,原子性。那么java是如何解决的呢?
这里说的是JAVA如何解决其中的可见性和有序性问题。
导致可见性的原因是缓存,导致有序性的原因是编译优化。那么我们只要按需禁用缓存和编译优化就可以了。
JAVA推出了JAVA内存模型,JAVA内存模型规范了JVM提供按需禁用缓存和编译优化的方法。具体来说,就是volatile,synchronized,final三个关键字,以及Happens-Before规则。
Happens-Before规则
happens-before仅仅要求前一个操作的执行结果对后一个操作是可见的,且前一个操作按顺序排在后一个操作之前。
Happens-Before 约束了编译器的优化行为,虽允许编译器优化,但是要求编译器优化后一定遵守 Happens-Before 规则,下面我来介绍这8大规则:A操作happens-before于B操作 == A happens(发生) B before(之前)
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中任意后续操作。
- 监视器锁规则:对于一个锁的解锁,happens-before于随后对于这个锁的加锁。
- volatie变量规则:对于一个volatile变量的写操作,happens-before于后续对该变量的读操作。
- 传递性规则:如果Ahappen-beford B,且B happen-before C,那么A happen-before C;
- 线程start()规则:main主线程启动子线程B后,子线程B能够看到main线程启动子线程B之前的操作。
- 线程join()规则:线程A调用线程B的join()方法,线程A等待线程B执行完join()成功返回后,线程B的任意操作都队线程A中B.join()之后可见。
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程代码检测到中断事件的发生,可以通过Thread.interrupted()检测到是否发生中断。
- 对象终结规则:这个也简单的,就是一个对象的初始化的完成,也就是构造函数执行的结束一定 happens-before它的finalize()方法。
下面分别说说volatile,synchronized,final三个关键字。
volatile关键字
volatile可以保证可见性和有序性。
- volatile如何保证有序性
重排序分为编译器重排序和处理器重排序,为了实现volatile的内存语义,JMM为了限制这两种重排序,对以下情况不能重排序!
1.当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序;
2.当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序;
3.当第一个操作是volatile写,第二个操作是volatile读,不能重排序;
为了实现以上规则(volatile的内存语义),编译器在生成字节码时,会在指令序列中插入内存屏障禁止处理器重排序。但是对于编译器,发现一个最优布置最小化插入内存屏障的数量是不可能的,所以JMM就在每个volatile读写前后都分别插入不同的内存屏障来实现有序性。
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的前面插入一个StoreLoad屏障。
在每个volatile读操作的前面插入一个LoadLoad屏障。
在每个volatile读操作的前面插入一个LoadStore屏障。
如果想了解四种屏障的作用,可以自己查阅资料。
- volatile 如何保证可见性
有volatile修饰的共享变量在进行写操作时,会多出lock的汇编代码,而lock前缀的指令在多核处理器下会进行两个操作

1.将当前缓存行中的数据写回到系统内存中。
LOCK#信号会锁定这块内存区域的缓存,并写回内存,并使用缓存一致性,保证它的原子性。
2.这个写回内存的操作会使其他cup里缓存了该内存地址的缓存行无效。
详情参考volatile原理
final关键字
final域的重排序规则,编译器和处理器要遵循下面两个规则:
首先用java代码展示这两种情况。
public class FinalDemo{
int i;//普通变量
final int j;//final变量
static FinalDemo demo;
public FinalDemo(){//构造函数
i=1;//写普通域
j=2;//写final域
}
public static void writer(){//写线程A执行
demo=new FinalDemo();
}
public static void reader(){//读线程B执行
FilalDemo object=demo;//读对象引用
int a=object.i;//读普通域
int b=object.j;//读final域
}
}
-
A在构造函数中对final域的写入,与B随后把这个 被构造的对象的引用 给一个引用变量,这两个操作不能重排序。
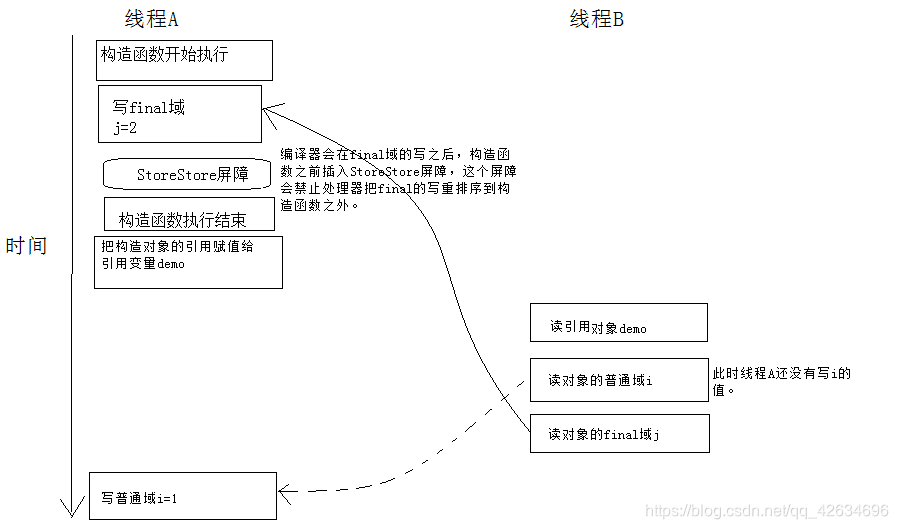
-
初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作不能重排序。
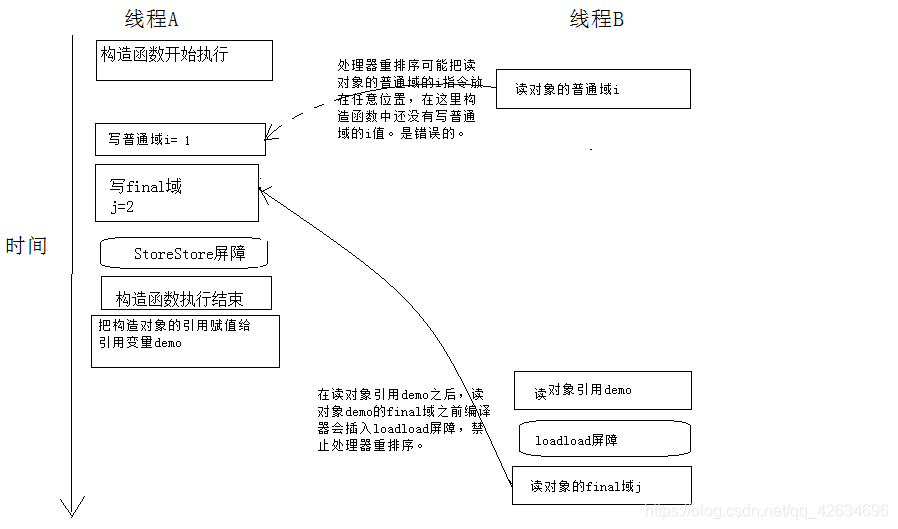
上面我们看到的final域是基础数据类型,那么如果final域是引用类型呢?
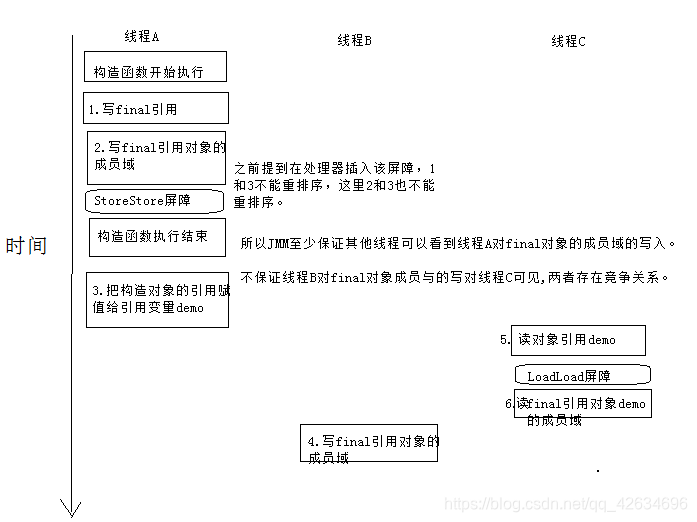
对于引用类型,写final域的重排序规则对编译器和处理器做了如下约束。 -
在构造函数中对一个final引用对象的成员域的写入,与随后在构造函数外读这个final域引用对象的成员域,这两个操作不能发生重排序。
请看下面实例代码。
public class FinalReferenceDemo {
final int[] arrays; //final是引用类型
static FinalReferenceDemo demo;
public FinalReferenceDemo() {//构造函数
arrays = new int[1];//1
arrays[0]=1;//2
}
public static void writeOne(){//写线程A执行
demo=new FinalReferenceDemo();//3
}
public static void writeTwo(){//写线程B执行
demo.arrays[0]=2;//4
}
public static void reader(){//读线程C执行
if(demo!=null){
int temp=demo.arrays[0];
}
}
}
- 构造函数溢出问题
看如下代码
public class FinalReferenceEscapeDemo {
final int i;
static FinalReferenceEscapeDemo obj;
public FinalReferenceEscapeDemo() {// 构造函数
i = 1;
obj = this;
}
public static void writer() {
new FinalReferenceEscapeDemo();
}
public static void reader() {// 读线程C执行
if (obj != null) {
int temp = obj.i;
}
}
}
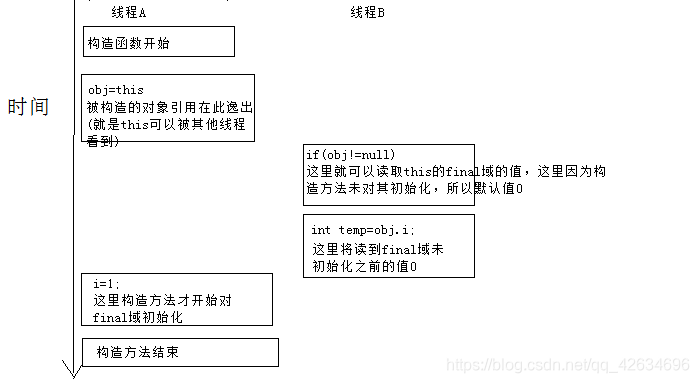
如果上面这个例子太复杂,你可以结合下面这个例子再理解下
我们通常new一个对象时,有三步
我们想象的是这样的
- 分配一块内存 M;
- 在内存 M 上初始化 Singleton 对象;
- 然后 M 的地址赋值给 instance 变量。
其实编译器优化后是这样的
- 分配一块内存 M;
- 然后 M 的地址赋值给 instance 变量;
- 在内存 M 上初始化 Singleton 对象;
这样在第2步之后,instance其实已经有了内存M的引用,但是值没有初始化,这样在另一个线程中可以获取到该对象,但是时没有初始化的,比如该对象中有 int i ; i没有初始化,调用会出错。
synchronized关键字
在其他文章中有讲到,这里就不多说了。
参考书籍:java并发编程的艺术
