前言
自己在网上下载的数据集,或者用自己采集的图片标注的图库亦或是用网上下载图片标注的图库,这些来源不一的数据有可能不能都满足要求,比如有的命名不统一,有的大小不合适,有的类别编码错位,有的标注与图片是分开的,有的图片没有标注,或者标注数量大于图片等,这些问题都可以通过以下脚本解决。
工具
- cmd
- python3
生成train.txt的脚本
train.txt里包含着所有图片相对路径的列表,脚本通过切分路径字符串而得到相对路径,并将相对路径信息以行为单位写入train.txt中。
import os
image_dir = r"G:\YOLO_train\darknet\build\darknet\x64\data\train"
dir_data = image_dir.split("\\")
f_train = open("train.txt", 'w')
for f in os.listdir(image_dir):
if(f.split(".")[1] == "jpg"):
f_train.write(dir_data[len(dir_data)-2]+'\\'+dir_data[len(dir_data)-1]+'\\'+f+'\n')效果图:

文件随机重命名脚本
系统带有重命名方法,我们只需要产生特定长度的随机序列即可。脚本通过循环每次从字符序列中挑选一个元素,最后循环16次,就拼接成了一个16个字符长度的字符串。这样重命名几万张图片基本不会重名,而且图片会随机分布,不会强加任何相关关系。
import os
import random
file_dir = r"G:\Yolo_mark-master\x64\Release\data\new\new\training_set"
seed=('abcdefghijklmnopqrstuvwxyz0123456789')
letter = []
for f in os.listdir(file_dir):
if(f.split(".")[1] == "jpg"):
for i in range(16):
letter.append(random.choice(seed))
newName = ''.join(letter)
os.rename(file_dir+'\\'+f, file_dir+'\\'+newName+'.jpg')
if(os.path.exists(file_dir+'\\'+f.split(".")[0]+ ".txt")) == True:
os.rename(file_dir+'\\'+f.split(".")[0]+'.txt', file_dir+'\\'+newName+'.txt')
print(newName)
letter = []效果图:

图片随机裁剪脚本
脚本的基本思路就是先在图片的特定区域随机生成一个点,然后截取起点为其决定的某个点所画的图像区域,然后保存该图像区域,进而就相当于在图片上进行随机裁剪。个人觉得其比tf上的随机裁剪函数好用一些。
import cv2
import os
import random
in_dir = r"G:\Yolo_mark-master\other"
out1_dir = "G:\\Yolo_mark-master\\out5"
if not os.path.exists(out1_dir):
os.mkdir(out1_dir)
for f in os.listdir(in_dir):
if(f.split(".")[1] == "jpg"):
path = in_dir +'/'+ f
img = cv2.imread(path)
size = img.shape
for n in range(3):
if((size[0]>=300)&(size[1]>=300)):
x = random.randrange(size[0]-299)
y = random.randrange(size[1]-299)
cut_img = img[x:x+300,y:y+300]
cropImg = cv2.resize(cut_img,(608,608),interpolation = cv2.INTER_CUBIC)
cv2.imwrite(out1_dir+'\\'+str(n)+'a_a'+f,cropImg) #写入图像路径
效果图:

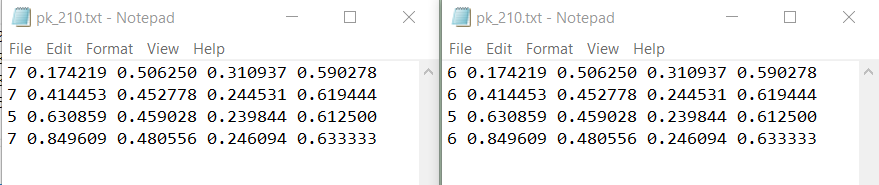
修改文本文档指定行列内容脚本
基本操作的思路就是, 先按照行切分原文本文档。然后再对每行的内容进行分割,这里通过空格分割。接着将某一元素替换成想要的内容,最后将各元素重新组合成一个字符串存放到另一个文本文档中,进而实现对文本文档中某行某列中内容进行修改。

import os
txt_dir = "G:\\Yolo_mark-master\\test"
other_dir = "G:\\Yolo_mark-master\\other"
if not os.path.exists(other_dir):
os.mkdir(other_dir)
txt_dirlist = os.listdir(txt_dir)
list = []
for f in txt_dirlist:
if(f.split(".")[1] == "txt"):
f1=open(txt_dir+'/'+f,'r+')
lines=f1.readlines()
f2=open(other_dir+'/'+f,'w+')
for i in range(len(lines)):
data = lines[i].split()
if(data[0] == '7'): #分离出的类别序号
clip_query = '6'+' '+data[1]+' '+data[2]+' '+data[3]+' '+data[4]+'\n'
f2.write(clip_query)
else:
f2.write(lines[i])
效果图:
清除没有标注文件的图片脚本
清除数据集中没有标注文件的图片。如果一幅图片没有标注,对于我们训练来说是没有用的,而且还可能造成错误,用以下脚本可以删除没有标注文件的图片。如果那些图片也是有用的,可以使用shutil.move把图片移动到其他文件夹,重新标注后再移回来即可。
import os
image_dir = "G:\\Yolo_mark-master\\test"
txt_dir = "G:\\Yolo_mark-master\\test"
for f in os.listdir(image_dir):
if(f.split(".")[1] == "jpg"):
if(os.path.exists(txt_dir+'/'+f.split(".")[0]+ ".txt")) == False:
os.remove(image_dir+'/'+f)
清除没有图片的标注文件脚本
清除数据集中没有图片文件的txt文件。与上一个问题类似,这样的文件是没有用的,它的产生主要是因为手动挑选时删除了某些图片,而对应的txt文件没有删除,尤其是图片和标注不在同一个文件夹时,或者下载数据集时出现了问题。用以下脚本即可删除多余的标注文件。
import os
image_dir = "G:\\Yolo_mark-master\\test"
txt_dir = "G:\\Yolo_mark-master\\test"
for f in os.listdir(txt_dir):
if(f.split(".")[1] == "txt"):
if(os.path.exists(image_dir+'/'+f.split(".")[0]+ ".jpg")) == False:
os.remove(txt_dir+'/'+f)
移动标注文件为空的图片与标注文件到指定文件夹脚本
移动数据集中标注文件为空的图片与标注文件到对应文件夹。我们知道标注文件为空的图片是负样本,负样本是训练中不可缺少的。我想到这个主要是便于管理,虽然最后正负样本都是要合在一起的,但是最开始把正负样本可以明了两个样本的个数,就像把每类也分开一样。在用yolo_mark标注过程中,我们也会发现有的图片是我们不想检测的负样本,这时我们是没有给它标注的,但是产生了标注文件,只是为空。也可以有另一个用处:用yolo_mark挑选较好的数据时,可以把不太好的数据的标注用“C”清除掉,处理完成之后用下面脚本就可以把那部分的图片和标注轻松剔除。
import os
import shutil
image_dir = "G:\\Yolo_mark-master\\test"
txt_dir = "G:\\Yolo_mark-master\\test"
other_dir = "G:\\Yolo_mark-master\\other"
if not os.path.exists(other_dir):
os.mkdir(other_dir)
for f in os.listdir(image_dir):
if((f.split(".")[1] == "jpg")&((os.path.exists(txt_dir+'/'+f.split(".")[0]+ ".txt"))==True)):
if(os.path.getsize(txt_dir+'/'+f.split(".")[0]+ ".txt")<1) :
shutil.move(image_dir +'/'+ f,other_dir + '/' + f)
shutil.move(txt_dir+'/'+f.split(".")[0]+ ".txt",other_dir+'/'+f.split(".")[0]+ ".txt")合并图像文件与标注文件所在的文件夹脚本
将标注与图像所在的文件夹合并。这个问题主要是在自己下载的数据集时可能遇到,比如我在open images那篇文章中下载的数据集标注与图片就是分开的,这样无法用yolo_mark清洗。如果用yolo_mark标注的数据图片和标注是在同一目录下的,就没有这个问题。还有从其他数据集的标注文件表中得到标注文件,如后面要写到的brainwash数据集,可能通过了一些过滤的手段,这时就可以通过下面的脚本将对应的图片移动到标注文件的文件夹。
移到其他目录:
import os
import shutil
image_dir = "G:\\Yolo_mark-master\\test"
txt_dir = "G:\\Yolo_mark-master\\test2"
other_dir = "G:\\Yolo_mark-master\\other"
if not os.path.exists(other_dir):
os.mkdir(other_dir)
for f in os.listdir(image_dir):
if(f.split(".")[1] == "jpg"):
if(os.path.exists(txt_dir+'/'+f.split(".")[0]+ ".txt")) == True:
shutil.move(image_dir +'/'+ f,other_dir + '/' + f)
shutil.move(txt_dir+'/'+f.split(".")[0]+ ".txt",other_dir+'/'+f.split(".")[0]+ ".txt")移到图片目录:
import os
import shutil
image_dir = "G:\\Yolo_mark-master\\test"
txt_dir = "G:\\Yolo_mark-master\\test2"
for f in os.listdir(image_dir):
if(f.split(".")[1] == "jpg"):
if(os.path.exists(txt_dir+'/'+f.split(".")[0]+ ".txt")) == True:
shutil.move(txt_dir+'/'+f.split(".")[0]+ ".txt",image_dir+'/'+f.split(".")[0]+ ".txt")移到标注目录:
import os
import shutil
image_dir = "G:\\Yolo_mark-master\\test"
txt_dir = "G:\\Yolo_mark-master\\test2"
for f in os.listdir(txt_dir):
if(f.split(".")[1] == "txt"):
if(os.path.exists(image_dir+'/'+f.split(".")[0]+ ".jpg")) == True:
shutil.move(image_dir+'/'+f.split(".")[0]+ ".jpg",txt_dir+'/'+f.split(".")[0]+ ".jpg")随机抽取文件脚本
随机抽取数据集中图片和标注到指定文件夹,这个主要是因为某一类数据太多而不得不删除一些。我在open images那篇文章中下载的若干类,有的几万张图片,有的却只有一两百张。我们知道,AlexeyAB推荐的是每类优选2000张左右,也就是对他而言用迁移学习训练yolo3,每类2000张就够了。而且如果太多数据训练难度会增大不少,所以写了以下脚本来随机挑选若干张图片和标注。
import os
import shutil
import random
image_dir = "C:\\down_openimages\\JPEGImages\\Laptop"
txt_dir = "C:\\down_openimages\\labels"
other_dir = "G:\\Yolo_mark-master\\other"
if not os.path.exists(other_dir):
os.mkdir(other_dir)
image_dirlist = os.listdir(image_dir)
sample = random.sample(image_dirlist, 400)
for f in sample:
if(f.split(".")[1] == "jpg"):
if(os.path.exists(txt_dir+'/'+f.split(".")[0]+ ".txt")) == True:
shutil.move(image_dir +'/'+ f,other_dir + '/' + f)
shutil.move(txt_dir+'/'+f.split(".")[0]+ ".txt",other_dir+'/'+f.split(".")[0]+ ".txt")结语
这里放置了我在处理数据集过程中用到的一些小脚本,对于我来说这些脚本还是非常有效的,如果你有缘看到,而且又对你产生了一小点的帮助,那真的是荣幸之至。如果你在阅读中发现了问题,欢迎在下方留言讨论,我看到后就会回复。
