[一步到位]最全的python爬虫代码教程 环境安装+爬虫编写
本篇文章针对初学爬虫的人,全文教学向
下面先展示下本爬虫教学的最终成果!
先看下我们要爬的网页数据
http://jsj.gzhu.edu.cn/xwzx1/zsksxx.htm
(晚上有时候会打不开)
这是我们爬到的数据写在文件里
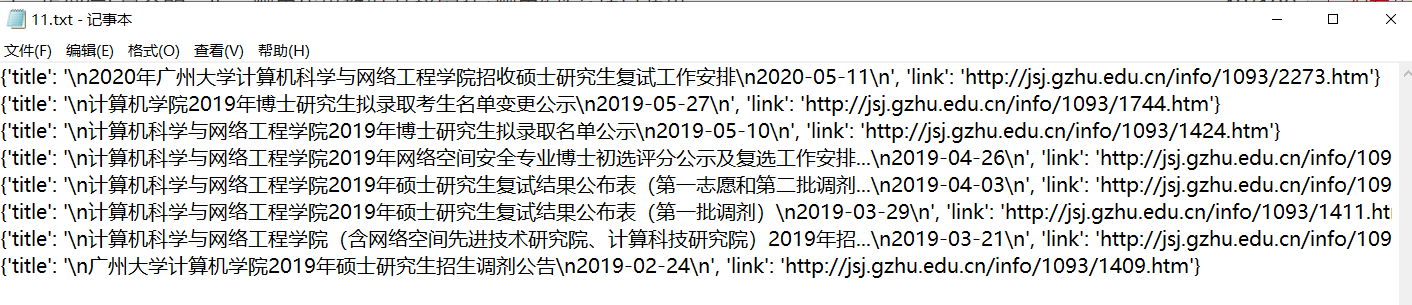
那就开始我们的python爬虫吧(本帖会解决所有初学爬虫遇到的问题)
环境安装
在学习之前,我们需要先安装python的编程环境。(本贴以win10,64位操作系统为例)
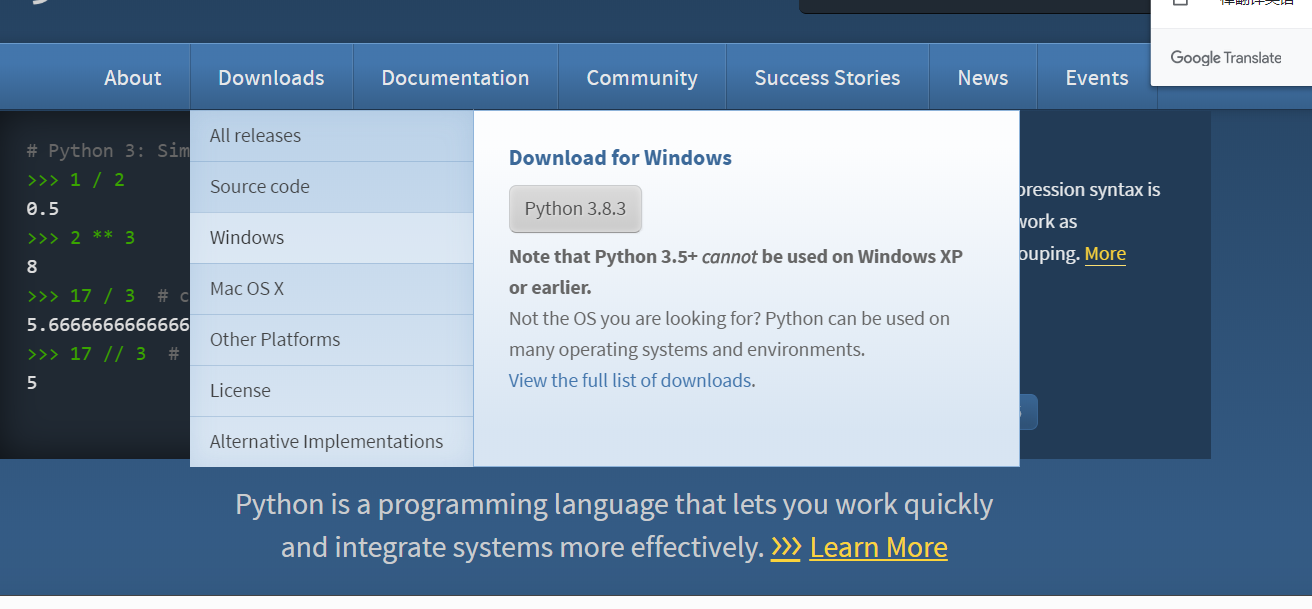
先到http://www.python.org/下载对应的安装包,如果你的电脑跟我一样也是win1064位则下载下图这个
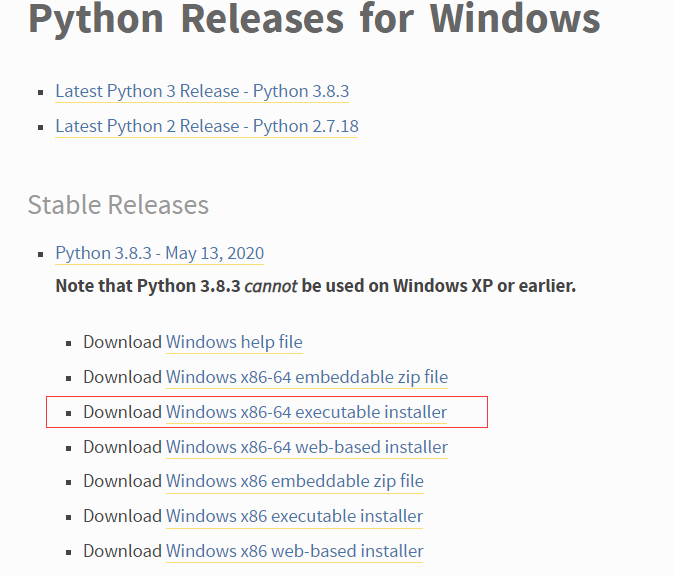
Downloads->Windinows->Download Windows x86-64 executable installer
安装python3
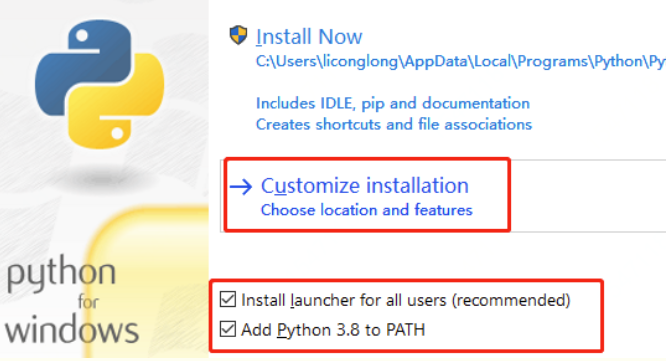
把刚才下好的安装包打开并安装,要勾选环境变量(如果没有勾选,要手动添加,添加教程请百度,或者删了再装一次),自定义安装可以选默认,然后点Install Now 安装
安装成功以后,打开cmd(快捷键win+r),输入python,出现以下字符则安装成功
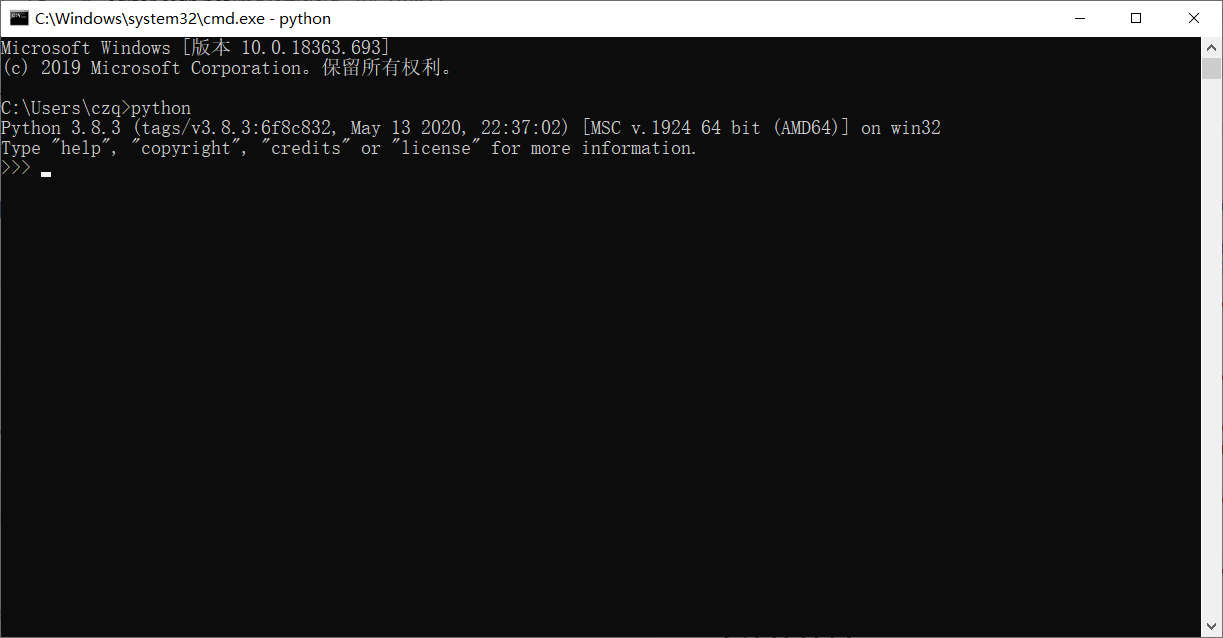
如果输入python 回车后出现的是微软的appstore,那就是由于环境路径中的优先级问题(此问题一定要解决,涉及到之后的库文件安装)
解决方法:
此电脑右键属性->高级系统设置->高级->环境变量->点击上面的path,再点编辑->将结尾是 python38\ 的路径上移到最上方(必须是最上面),另一个python38\Scripts\ 的路径要放在第二个->点击确定
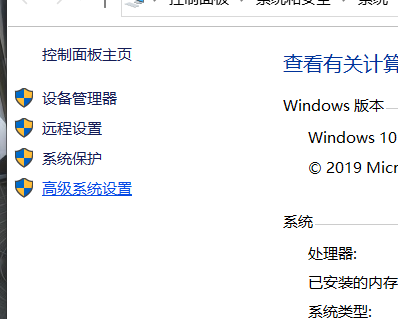
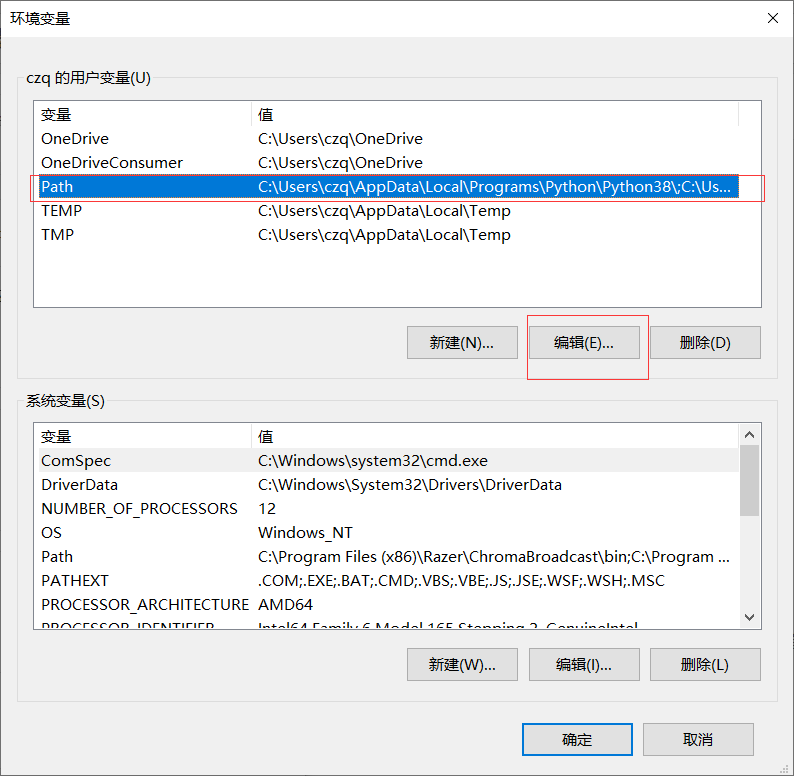
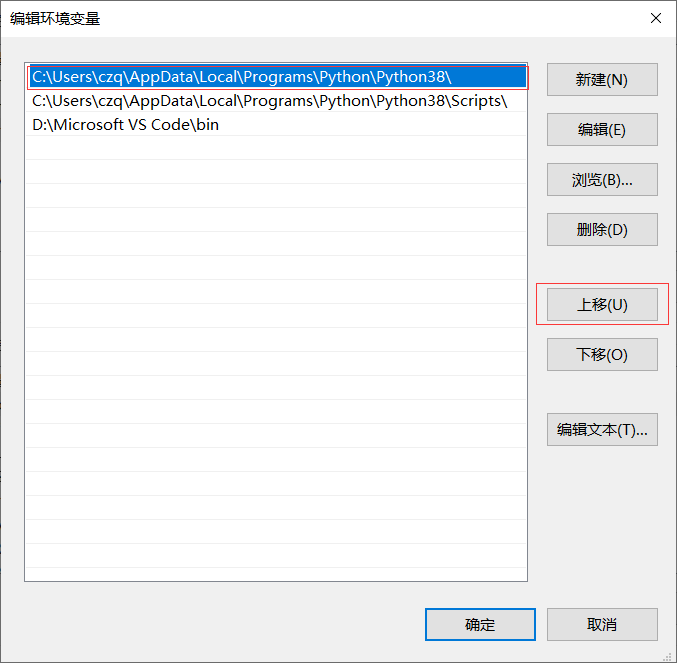
再试一次cmd 下的 输入python命令应该就没有问题了,可以打印出版本信息(如果还不行,就把结尾是appstore的path删掉)
安装vscode
python编辑器有很多可以选择,包括sublime text,集成环境pycharm等等
这里我选择Visual Studio Code(轻量化的编辑器+跨平台)
下载地址: https://code.visualstudio.com/.
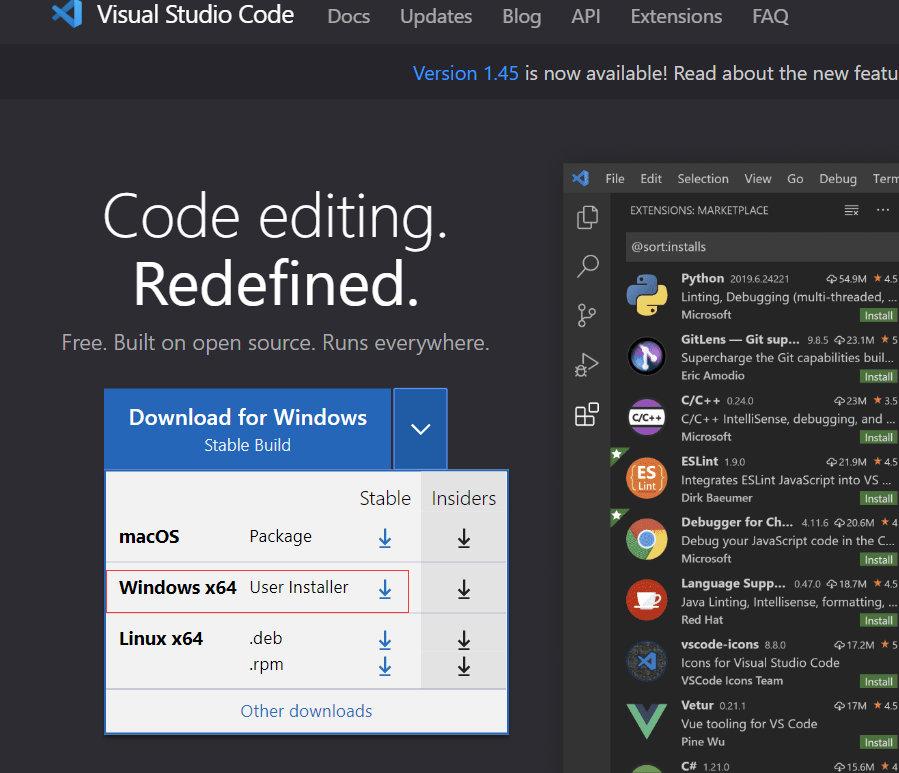
打开后点最后一个,搜索python,安装python插件,如果喜欢用中文,也可以下载安装中文插件(搜chinese)
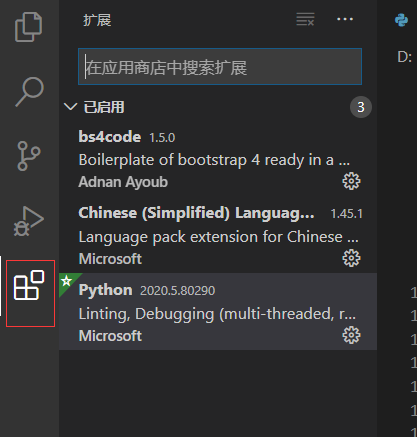
此时你已经可以运行一个最普通的python文件了,新建一个py文件,
输入
print(123)
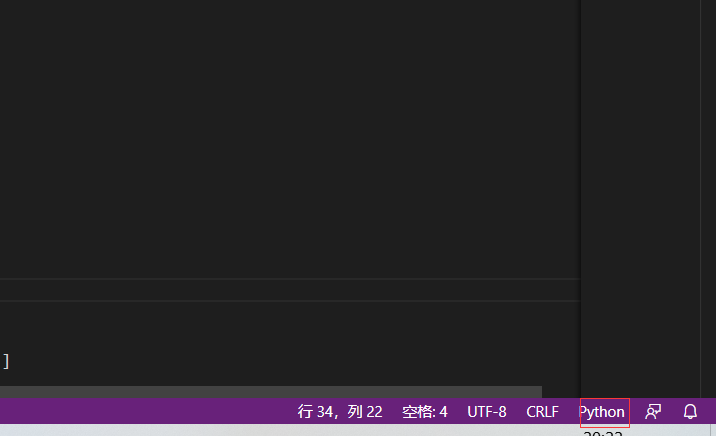
右下角选择python语言(方便编辑器编程的作用)
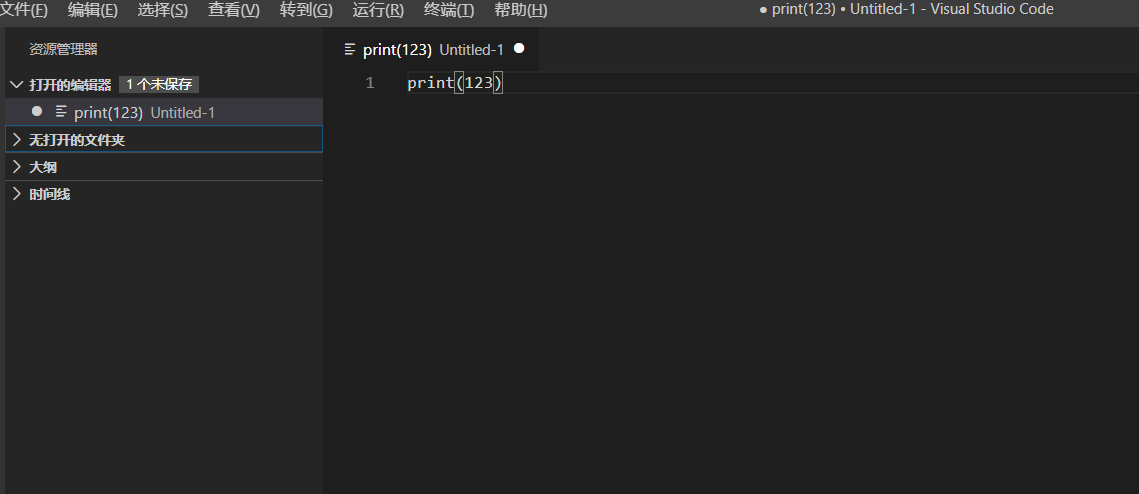
先将文件保存带一个位置,如桌面
然后点上方工具栏:运行->启动调试->选择pythoin file
运行结果如下

此时你的第一个python文件已经成功运行
接下就是开始学习爬虫的编写
入门爬虫
学习爬冲要先了解爬虫的基本知识
然后安装爬虫所需要的python库
最后再编写爬虫,运行爬虫
爬虫基础知识
网页基础知识
我们学习爬虫爬取网页数据,那就先了解web网页的数据结构,如果你已经有web前端的知识,可以跳过此段,对这段不理解的同学,可以自行去百度学习web前端
<html>
<head>
<title> Python 3 爬虫 </title>
</head>
<body>
<div>
<p>爬虫入门</p>
</div>
<div>
<ul>
<li><a href="">爬虫</a></li>
<li>数据</li>
</ul>
</div>
</body>
网页就是由这样一种代码勾成
例如打开淘宝网 右键检查源代码,你就看到了组成淘宝页面的网页代码
例如<body></body>组成了网页的内容
<title> Python 3 爬虫 </title>
title 标签的内容会成为网页的标题
通过这样简单的html语法组成我们的网页,而假如我们需要爬取某个网站的标题时,我们只需要利用bs4这个库就可以找到这些代码中这个特点标签里的内容,就可以获取我们需要的数据
F12查看数据请求
在我们要爬取的那个页面中,我们按F12,会跳出网页调试查看器

我们选中network,在里面鼠标往上滑,找到一个xyxw.htm,点击会得到
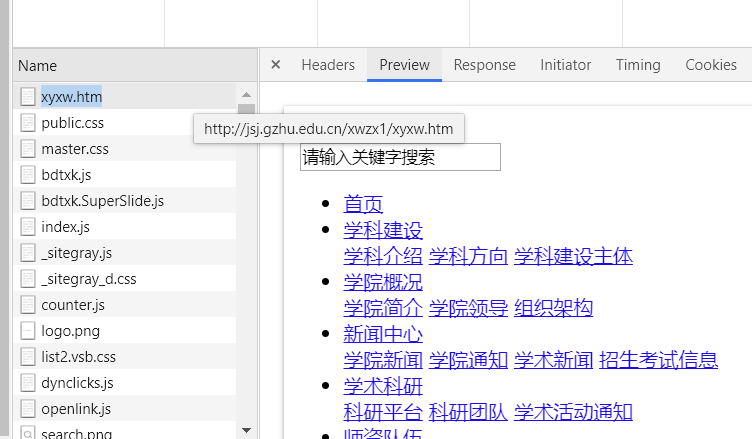
这其实就是为什么我们可以看到网页上的数据的原因,网页会代替我们发送请求到服务器,服务器会返回数据到本地页面上,就让我们在网页上可以看到很多数据内容,这个xyxw.htm请求就是替我们去请求数据的
preview 是预览的意思,Response是返回数据的意思,点击可以看到返回了什么数据,header是请求头数据,相当于发送一个数据告诉服务器是你发的,你要请求什么数据,这样你就可以拿到返回的数据,在返回的数据中找到我峨嵋你需要的,这对于爬虫非常重要,由于反爬虫的存在,我们经常需要伪装header来达成爬虫的合法请求数据
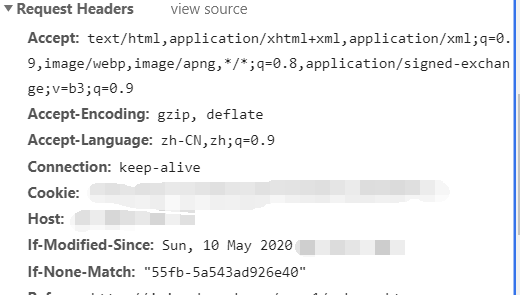
在我们下面的爬虫编写中,会利用到这里的Request Hearders(请求头数据)
爬虫合法性
接着就是如何查看一个网页是否可以爬取数据,需要利用个网站的一个名为 robots.txt 的文档,例如 https://www.taobao.com/robots.txt
在你需要爬取的网站后面加上/robots.txt

Disallow:/
是都不允许的意思, 意思是除了前面提到的百度的爬虫,其他的都不允许,有一些网站则没有/robots.txt这个文件,则我们就可以爬取他的数据。
爬虫所需要用到的python库
本帖的爬虫需要用到五个python库
requests 库 Beautiful Soup库 lxml库 re库 time库
requests 库
爬虫是怎么自己去找到我们需要爬的网站的呢,那当然是需要们去指定了
import requests #导入requests包
url = 'http://jsj.gzhu.edu.cn/xwzx1/zsksxx.htm'
strhtml = requests.get(url) #Get方式获取网页数据
print(strhtml)
import requests 就是引进我们的requests 库,所以再你没有安装requests 库而运行这段代码的时候,你就会发现这段代码报错了,所以我们就要安装它了
鼠标右键我们的python3 图标 ,打开文件安装位置,如图,再进入Scripts 文件夹


按住shift+鼠标右键,选中再此处打开powershell窗口
输入
pip list
会发现你的python库中没有requests 库,这时你输入以下命令
pip install requests
安装成功之后,再pip list 一次, 会发现已经有了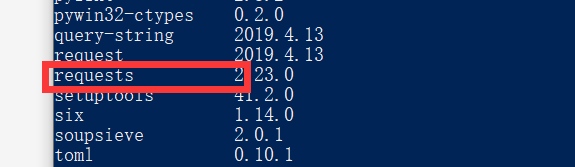
此时你再运行一次刚才的代码,发现已经可以跑起来了
Beautiful Soup库 lxml库
Beautiful Soup 是 python 的一个库,其最主要的功能是从网页中抓取数据。Beautiful Soup 目前已经被移植到 bs4 库中,也就是说在导入 Beautiful Soup 时需要先安装 bs4 库
再刚才的powershell窗口下继续执行以下命令
pip3 install Beautifulsoup4
安装好 bs4 库以后,还需安装 lxml 库, lxml 库用来解析网页数据
pip install lxml
re库 time库
re库是关于正则表达式的一个库。这里面包含了多种字符串匹配的方法,用来从爬到额数据中找到我们需要的字符串(如标题,某一行等等)
time库是时间库(内置再python 里了,故不需要单独安装),我们要让我们的带代码有间隔的跑下去,就需要用到sheep()函数让程序休眠,该函数就在time库里面
安装re库,同样在刚才的powershell窗口下
pip install re
一个简单爬虫例子
在完成了前面的准备工作后我们就可以进行爬虫爬取了
其中我们还用到了文件操作
result=111
w=open("D:/11.txt",'w+') #开启文件写入流 w+是写入的意思write的缩写
print(result,file=w) #开启文件写入流 将result写入文件 w+是写入的意思write的缩写
w.close() #关闭文件写入流
运行上面的代码可以看到在D盘下有个11.txt的文件夹
我们利用文件操作可以将爬到的数据放到我们本地的文件里保存起来,
最后上我们的本次爬虫的完整源码
爬虫源码
import requests #导入requests包
from bs4 import BeautifulSoup #导入bs4 包的BeautifulSoup模块
import re #导入re包
import time #导入time包
url = 'http://jsj.gzhu.edu.cn/xwzx1/zsksxx.htm'
headers={
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding":"gzip, deflate",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"max-age=0",
"Connection": "keep-alive",
"Cookie": "JSESSIONID=D43B18D738ABE4DF3B7E768CE1FCF8B7",
"Host":"jsj.gzhu.edu.cn",
"If-Modified-Since":"Fri, 15 May 2020 01:31:40 GMT",
"If-None-Match":"526c-5a5a5c6613700",
"Referer":"http://jsj.gzhu.edu.cn/xwzx1/xytz.htm",
"Upgrade-Insecure-Requests":"1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
while True: #以下的程序一直循环操作
strhtml = requests.get(url,headers=headers) #Get方式获取网页数据
strhtml.encoding='utf-8' #对获取到的数据编码,不然中文数据都是乱码
soup=BeautifulSoup(strhtml.text,'lxml')
data = soup.select('h2.cleafix') #下面会解释这段代码的意思
w=open("D:/11.txt",'w+') #打开对应文件,开启写入流
for item in data: #对每条爬到的data数据进行循环操作,用法自行百度
result={ #构建一个reslut 数据对象,这是我们要写入文件的对象
'title':item.get_text(),
'link':"http://jsj.gzhu.edu.cn/"+item.select('a')[0].get('href')[3:]#[3:]的意思是截取数据从第3个字符开始的所有字符
}
print(result) #注意这句带代码前要空2格,使得这个函数在循环里执行,print是输出函数
print(result,file=w) #同上,file=w写入文件操作
w.close()#关掉文件
time.sleep(180)#线程睡眠180秒,换句话说就是每隔180秒到网站去爬一次数据
上面的代码中有行代码
data = soup.select('h2.cleafix')
从上面的代码中我们知道,soup是我们爬取网站,并经过清洗得到的html数据
其中就有类似这样的html代码
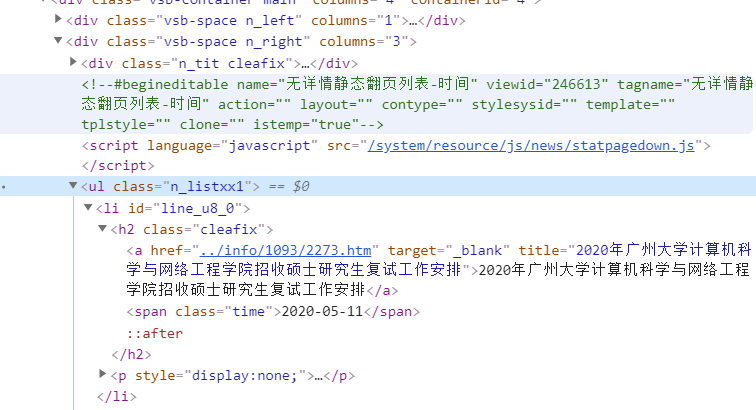
(小伙伴这段不懂的可以先百度以下html标签 class)h2是一个html标签,而cleafix是这个某个h2标签的class名字,而这个h2标签里包含的东西就是我们想要爬到的,所以我要在某个网站爬取某个数据时,我们需要通过查看代码的方式,知道数据在哪个标签里,通过select(‘h2.cleafix’)来筛选出上面的代码内容,筛选完就会得到下面的数据
[<h2 class="cleafix"> <a href="../info/1093/2273.htm" target="_blank"
title="2020年广州大学计算机科学与网络工程学院招收硕士研究生复试工作安
排">2020年广州大学计算机科学与网络工程学院招收硕 士研究生复试工作安排</a>
<span class="time">2020-05-11</span> </h2>, <h2 class="cleafix"> <a
href="../info/1093/1744.htm" target="_blank" title="计算机学院2019年博士
研究生拟录取考生名单变更公示">计算机学院2019年博士研究生拟录取考生名单变更
公示</a> <span class="time">2019-05-27</span> </h2>, <h2
class="cleafix"> <a href="../info/1093/1424.htm" target="_blank"
title="计算机科学与网络工程学院2019年博士研究生拟录取名单公示">计算机科学
与网络工程学院2019年博士研究生拟录取名单公示</a> <span class="time">2019-
05-10</span> </h2>, <h2 class="cleafix"> <a href="../info/1093/1413.htm"
target="_blank" title="计算机科学与网络工程学院2019年网络空间安全专业博士
初选评分公示及复选工作安排通知">计算机科学与网络工程学院2019 年网络空间安
全专业博士初选评分公示及复选工作安排...</a> <span class="time">2019-04-
26</span> </h2>, <h2 class="cleafix"> <a href="../info/1093/1412.htm"
target="_blank" title="计算机科学与网络工程学院2019年硕士研究生复试结果公
布表(第一志愿和第二批调剂)">计算机科学与网络工程学院2019年 硕士研究生复
试结果公布表(第一志愿和第二批调剂...</a> <span class="time">2019-04-
03</span> </h2>, <h2 class="cleafix"> <a href="../info/1093/1411.htm"
target="_blank" title="计算机科学与网络工程学院2019年硕士研究生复试结果公
布表(第一批调剂)">计算机科学与网络工程学院2019年硕士研究生 复试结果公布
表(第一批调剂)</a> <span class="time">2019-03-29</span> </h2>, <h2
class="cleafix"> <a href="../info/1093/1410.htm" target="_blank"
title="计算机科学与网络工程学院(含网络空间先进技术研究院、计算科技研究
院)2019年招收硕士复试工作安排">计算机科学与网 络工程学院(含网络空间先进
技术研究院、计算科技研究院)2019年招...</a> <span class="time">2019-03-
21</span> </h2>, <h2 class="cleafix"> <a href="../info/1093/1409.htm"
target="_blank" title="广州大学计算机学院2019年硕士研究生招生调剂公告">广
州大学计算机学院2019年硕士研究生招生调剂公告</a> <span class="time">2019-
02-24</span> </h2>]
到这里你就会发现,h2这个标签里有我们想要的所有数据,所以哦我们选择它,它这个标签的内容拿出来,这个时候你会发现它们其实是一个数组,里面一共有多行数据,所以就需要使用一次循环,将里面的内容循环遍历出来
item.get_text()的意思就是就是在循环中取data的标签里的内容,比如<a>123</a>
item.get_text()得到的内容就是123
.select(‘a’)则是把里面的a标签的内容拿出来
最后你再把所有的知识点结合到上面给出的爬虫代码好好理解一下,在vscode上自己跑一遍,你就能理解了。
到这里,你就能在你的电脑D盘看到那个11.txt文件夹,那么你的爬虫就已经入门,就可以开始你的各种爬虫操作了 。
最后感谢一下陈jl给我赞助的这个博客头像哈哈哈哈
如果这篇文章对你有帮助,点个赞吧点个赞吧!点个赞吧!点个赞吧!!