Self-Cure Net:如何更好地抑制大规模人脸情绪识别的不确定性?
Suppressing Uncertainties for Large-Scale Facial Expression Recognition_arXiv:2002.10392v1 [cs.CV] 24 Feb 2020(本人自译,转载译本需经许可)
文章目录
- Self-Cure Net:如何更好地抑制大规模人脸情绪识别的不确定性?
- Abstract:
- 1.Introduction:
- 2.Related Work:
- 3.Self-Cure Network:
- 3.1. Overview of Self-Cure Network:
- 3.2.Self-Attention Importance Weighting:
- 3.3.RankRegularization :
- 3.4.Relabeling:
- 3.5 Implementation:
- 4.Experiments:
- 4.1.Datasets:
- 4.2.Evaluation of SCN on Synthetic Uncertainties:
- 4.3.Exploring SCN on Real-World Uncertainties:
- 4.4.Ablation Studies:
- Evaluation of the three modules in SCN:
- Evaluation of the ratio γ:
- Evaluation of δ1 and δ2:
- Evaluation of the β:
- 4.5.Comparison to the State of the Art:
- 5.Conclusion:
Abstract:
由于不明确的面部表情,低质量的面部图像以及注释者的主观性,给定性的大规模面部表情数据集添加注释非常困难。 这些不确定性导致深度学习时代大规模面部表情识别(FER)的关键挑战。 为了解决这个问题,本文提出了一种简单而有效的Self-Cure Network(SCN),该网络可以有效地抑制不确定性并防止深度网络过度拟合不确定的面部图像。 具体而言,SCN从两个不同方面抑制了不确定性:1)在小批量生产中采用自我注意机制,以排名正则化对每个训练样本进行加权,2)修改最低排名部分的样本的重新标记机制。 在合成FER数据集和我们收集的WebEmotion数据集上进行的实验验证了我们方法的有效性。 公开基准测试结果表明,我们的SCN优于当前的最新方法,在RAF-DB上为88.14%,在AffectNet上为60.23%,在FERPlus上为89.35%。 该代码将在https://github.com/kaiwang960112/Self-Cure-Network上提供。
1.Introduction:
面部表情是人类传达其情绪状态和意图的最自然,最有力和普遍的信号之一。 自动识别面部表情对于帮助计算机理解人类行为并与之互动也很重要。 在过去的几十年中,研究人员通过算法和大规模数据集在面部表情识别(FER)方面取得了重大进展,可以在实验室或野外收集数据集,例如CK +,MMI,OuluCASIA,SFEW / AFEW ,FERPlus,AffectNet,EmotioNet,RAF-DB等。
然而,对于从互联网收集的大规模FER数据集,由于注释者的主观性以及模糊的野外面部图像所带来的不确定性,很难进行高质量的注释。 如图1所示,不确定性从高质量和明显的面部表情增加到低质量和微表情。 这些不确定性通常会导致标签不一致和标签错误,从而延迟了大规模面部表情识别FER的进展,特别是对于基于数据驱动的深度学习FER之一。通常,不确定的FER训练可能会导致以下问题。 首先,这可能会导致对不确定样品的过度拟合,从而可能会贴错标签。 其次,有害于模型对于有用的面部表情特征的学习。 第三,错误标签的比例很高,甚至会使模型在优化的早期就不合逻辑。
为了解决这些问题,我们提出了一种简单而有效的方法,称为自愈网络(SCN),以抑制大规模面部表情识别的不确定性。SCN包含三个关键模块:自我注意力重要性加权,等级正则化和噪声重新标记。
给定一批图像,首先使用主干CNN提取面部特征。然后自我注意力重要性加权模块为每个图像学习一个权重,以捕获样本重要性以进行加权损失。 可以为不确定的面部图像分配低的重要性权重。 此外,排名正则化模块将这些权重按降序排名,将它们分为两组(高重要性权重和低重要性权重),并通过在两组平均权重之间强制执行边距来对两组进行正则化.。该正则化通过损失函数(称为秩正则化损失(RR-Loss)实现。 排名正则化模块可确保第一个模块学习有意义的权重以突出显示某些样本(例如,可靠的注释)并抑制不确定的样本(例如,含糊的注释)。最后一个模块是一个仔细的重新标记模块,该模块通过将最大预测概率与给定标记的概率进行比较,尝试从最下面的分组重新标记这些样本。 如果最大预测概率高于具有边际阈值的给定标签之一,则将样本分配给伪标签。
此外,由于不确定性的主要证据是不正确/嘈杂的注释问题,因此我们从互联网上收集了一个称为WebEmotion的极端嘈杂的FER数据集,以研究具有极端不确定性的SCN的影响。
总的来说,我们的贡献可以总结如下:
- 我们创新地提出了面部表情识别中的不确定性问题,并提出了一个自愈网络以减少不确定性的影响。
- 我们精心设计了排名正则化,以监督SCN对于有意义的重要性权重的学习,这也为重新标记模块提供了参考。
- 我们对合成FER数据和从互联网上收集的真实不确定情绪数据集(WebEmotion)进行了广泛的验证。 我们的SCN在RAF-DB上的性能也达到88.14%,在AffectNet上达到60.23%,在FERPlus上达到89.35%,创下了新纪录。

2.Related Work:
2.1Facial Expression Recognition:
通常,FER系统主要包括三个阶段,即面部检测,特征提取和表情识别。 在人脸检测阶段,使用了多个人脸检测器(例如MTCNN和Dlib)来定位复杂场景中的人脸。 所检测的面部可以可替代地进一步对准。 对于特征提取,设计了各种方法来捕获由面部表情引起的面部几何形状和外观特征。 根据功能类型,可以将它们分为工程功能和基于学习的功能。 对于工程特征,它们可以进一步分为基于纹理的局部特征,基于几何的全局特征和混合特征。 基于纹理的特征主要包括SIFT,HOG,LBP直方图,Gabor小波系数等。
基于几何的全局特征主要基于鼻子,眼睛和嘴巴周围的界标点。 组合两个或多个工程特征是指混合特征提取,可以进一步丰富表示。 对于习得的特征,Fasel发现浅层的CNN可以很好地面对姿势和比例。 Tang和Kahou等人利用深层CNN进行特征提取,并分别赢得了FER 2013和Emotiw2013挑战。 Liu等人提出了一种基于面部动作单元的CNN架构,用于表情识别。 最近,Li和Wang等人设计了基于区域的注意网络,用于姿势和遮挡感知FER,其中区域从地标点或固定位置裁剪。
2.2Learning with Uncertainties:
FER任务中的不确定性主要来自模棱两可的面部表情,低质量的面部图像,注释不一致以及注释不正确(即嘈杂的标签)。 特别是,在计算机视觉社区中广泛研究了带有噪音标签的学习,而很少探讨其他两个方面。 为了处理嘈杂的标签,一个直观的想法是利用少量干净的数据,这些数据可用于在训练过程中评估标签的质量或估计噪声分布或训练特征提取器。
Li等提出了一个统一的“蒸馏”框架,该框架使用来自小型干净数据集的“边”信息和知识图中的标签关系,以对冲从嘈杂标签中学习的“风险”。Veit等人使用一个多任务网络,该网络可以共同学习清除嘈杂的注释和对图像进行分类。 Azadi等人通过带有噪点标签的深层CNN的辅助图像正则化选择可靠的图像。 其他方法不需要小的干净数据集,但它们可能会在嘈杂的样本上承担额外的约束或分布,例如随机翻转标签的特定损失,通过MentorNet规范损坏标签上的深层网络。 其他方法通过将潜在的正确标签连接到嘈杂的标签上,从而在softmax层上对噪声建模。 对于FER任务,Zeng等人首先考虑不同FER数据集之间不一致的注释问题,并提出利用这些不确定性来改善FER。 相反,我们的工作重点是抑制这些不确定性,以学习更好的面部表情特征。
3.Self-Cure Network:
为了学习具有不确定性的鲁棒的面部表情特征,我们提出了一个简单而有效的自愈网络(SCN)。 在本节中,我们首先提供SCN的概述,然后介绍其三个模块。 最后,我们介绍SCN的详细实现。
3.1. Overview of Self-Cure Network:
我们的SCN建立在传统CNN的基础上,包括三个关键模块:i)自注意力重要性加权,ii)排名正规化,iii)重新标记,如图2所示。
给定一批带有一些不确定样本的面部图像,我们首先通过骨干网络提取深层特征。 自我关注重要性加权模块使用完全连接(FC)层和sigmoid函数为每个图像分配重要性加权 。将这些权重乘以未经处理的图片,作为一种权重重新分配方案。 为了显着降低不确定样本的重要性,进一步引入了排序正则化模块以对注意力权重进行正则化。 在排序正则化模块中,我们首先对学习到的注意力权重进行排名,然后将其分为两组,即高和低重要性组。 然后,我们在这些组的平均权重之间添加基于边距的损失的约束,这称为排序正则化损失(RR-Loss)。 为了进一步改善我们的SCN,添加了重新标记模块以修改低重要性组中的一些不确定样本。 此重新标记操作旨在收集更多干净的样本,然后增强最终模型。 整个SCN可以从末端到末端的方式进行训练,并且可以轻松地添加到任何CNN主干中。

3.2.Self-Attention Importance Weighting:
我们引入了自我注意重要性加权模块,以捕获训练样本的贡献。 预期某些样本可能具有较高的重要性权重,而不确定的样本则具有较低的重要性。 令F = [x1,x2,…,xN]∈R^(D×N)表示N张图像的面部特征,自注意重要性加权模块将F作为输入,并输出每个特征的重要性加权。
具体而言,自我注意重要性加权模块由线性完全连接(FC)层和Sigmoid激活函数组成,可以将其表示为,其中αi是第i个样本的重要性权重,Wa是用于注意力的系数, σ是Sigmoid函数。 该模块还为其他两个模块提供参考。
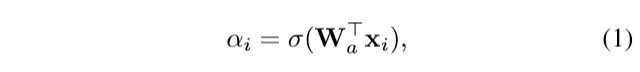
Logit-Weighted Cross-Entropy Loss:
有了注意力权重,我们有两个简单的选择,可以]进行损失加权。 第一个选择是将每个样品的重量乘以样品损失。 在我们的案例中,由于权重以端到端的方式进行了优化,并且是从CNN功能中获悉的,因此,由于这种三重性解决方案的损失为零,因此一定为零。 MentorNet 和其他自定进度的学习方法通过交替最小化来解决此问题,即一次优化一个,而另一种则固定。 在本文中,我们选择的对数加权方法,它被证明是更有效的。 对于多类交叉熵损失,我们将加权损失称为对数加权交叉熵损失(WCE-Loss),其公式为:
其中Wj是第j个分类器,乚WCE与α呈正相关。
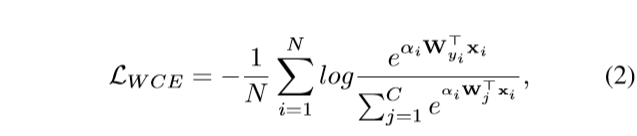
3.3.RankRegularization :
上述模块中的自注意力权重在(0,1)中可以是任意的。 为了明确限制不确定样本的重要性,我们精心设计了一个排序正则化模块以对注意力权重进行正则化。 在排序正则化模块中,我们首先以降序对学习的注意力权重进行排名,然后将它们分为比率为β的两组。 排序正则化确保高重要性组的平均注意力权重高于边界低重要性组。 正式地,我们为此定义了排序正则化损失(RR-Loss),如下所示:
其中δ1是可以作为固定的超参数或可学习参数的余量,αH和αL分别是高重要性组(β N = M个样本)和低重要性组(N -M个样本)的平均值。 在训练中,总损失函数为乚all =γ乚RR+(1-γ)LWCE,其中γ是一个权衡比。*

3.4.Relabeling:
在排序正则化模块中,每个小批量被分为两组,即 高重要性和低重要性的群体。 我们通过实验发现,不确定样本通常具有较低的重要性权重,因此直观地想到了重新设计这些样本的策略。 修改这些注释的主要挑战是知道哪个注释不正确。 具体来说,我们的重新标记模块仅考虑低重要性组中的样本,并根据Softmax概率执行。 对于每个样本,我们将最大预测概率与给定标签的概率进行比较。 如果最大预测概率高于具有阈值的给定标签之一,则将样本分配给新的伪标签。 正式地,重新标记模块可以定义为:
其中y’表示新标签,δ2是阈值,Pmax是最大预测概率,PgtInd是给定标签的预测概率。 lorg和lmax分别是原始给定标签和最大预测的索引。
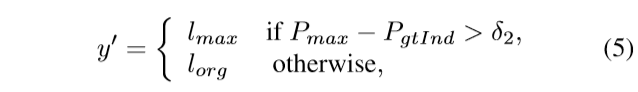
3.5 Implementation:
Pre-processing and facial features:
在我们的SCN中,通过MTCNN 检测并对齐人脸图像,然后将其尺寸调整为224×224像素。 SCN通过Pytorch工具箱实现,主干网络为ResNet18。 默认情况下,ResNet-18在MS-Celeb-1M人脸识别数据集上进行了预训练,并且从其最后的合并层提取了人脸特征。
Training:
我们使用8个Nvidia Titan 2080ti GPU端对端地训练SCN,并将批大小设置为1024。在每次迭代中,训练图像分为两组,包括70%高重要性样本和30%低重要性 默认情况下为样本。 高重要性组和低重要性组的平均值之间的边距δ1可以默认设置为0.15或设计为可学习的参数。 两种策略都将在随后的实验中进行评估。 整个网络与RR-Loss和WCE-Loss共同优化。 这两个损耗的比值经验设定为1:1,其影响将在随后的Experiments消融研究中进行研究。 倾斜率初始化为0.1,然后分别在15次epoch和30次epoch后再除以10。 训练在40次epoch停止。 包含重新标记模块,从第10次epoch开始进行优化,默认情况下,重新标记边距δ2设置为0.2。
4.Experiments:
在本节中,我们将描述三个公开数据集和WebEmotion数据集。 然后,我们在合成噪声和现实噪声面部表情注释都存在不确定性的情况下证明了SCN的鲁棒性。 此外,我们进行了具有定性和定量结果的消融研究,以显示SCN中每个模块的有效性。 最后,我们将SCN与公共数据集上的最新方法进行了比较。
4.1.Datasets:
RAF-DB包含30,000张由40名受过训练的人类编码员用基本或复合表情标注的面部图像。 在我们的实验中,仅使用具有六个基本表情(中性,幸福,惊奇,悲伤,愤怒,厌恶,恐惧)和中性表情的图像,这导致了12,271张图像用于训练而3,068张图像用于测试。 总体样品精度用于测量。
FERPlus 是FER2013的扩展,用于ICML 2013挑战赛。 它是Google搜索引擎收集的大规模数据集。 它包含28,709个训练图像,3,589个验证图像和3,589个测试图像,所有这些图像均被调整为48×48像素。 包括蔑视,导致该数据集中有8个类。 总体样本准确性用于测量。
AffectNet 是迄今为止提供分类注释的最大数据集。 通过在三个搜索引擎中查询与表达相关的关键字,它包含来自Internet的一百万个图像,其中有40,000个图像是用FERPlus中的八个表达标签手动注释的。 它具有不均衡的训练和测试集以及均衡的验证集。 验证集上的平均分类准确度用于测量。
收集的WebEmotion。 由于不确定性的主要证据是不正确/嘈杂的注释问题,因此我们从Internet收集了一个称为WebEmotion的极端嘈杂的FER数据集,以研究具有极端不确定性的SCN的影响。 WebEmotion是从YouTube下载的视频数据集(尽管我们通过为帧分配标签将其用作图像数据),并带有一组关键字,其中包括40个与情感相关的单词,来自亚洲,欧洲,非洲,美国和6个年龄段的45个国家/地区 相关词(例如,婴儿,女士,女人,男人,老人,老女人)。 它由FERPlus相同的8个类组成,每个类都与与情绪相关的关键字相连,例如:快乐,有趣,狂喜,得意和可爱相关。 为了在关键字和搜索到的视频之间获得有意义的关联,仅会选择不到4分钟的前20个抓取视频。 这导致大约41,000个视频进一步细分为200,000个带有约束面(由MTCNN检测到)的视频片段(至少5秒钟)。 对于评估,我们仅使用WebEmotion进行预训练,因为注释非常困难。 表1显示了WebEmotion的统计信息。 源视频和视频片段将对研究社区公开。

4.2.Evaluation of SCN on Synthetic Uncertainties:
FER的不确定性主要来自模棱两可的面部表情,低质量的面部图像,注释不一致以及注释不正确(即嘈杂的标签)。 考虑到只能对嘈杂的标签进行定量分析,我们利用三种标签噪声水平(包括与RAF-DB,FERPLus和AffectNet数据集的比率分别为10%,20%和30%)来探索SCN的鲁棒性。 具体来说,我们为每个类别随机选择训练数据的10%,20%和30%,并随机将其标签更改为其他标签。
在表2中,我们使用ResNet-18作为CNN骨干,并通过两种训练方案将SCN与基线(不考虑标签噪声的传统CNN训练)进行比较:
i)从头开始训练;
ii)使用Ms-Celeb-1M上的预训练模型进行精细调整。我们还将SCN与RAF-DB上的两种最先进的噪声容忍方法进行比较,即CurriculumNet 和MetaCleaner。
如表2所示,我们的SCN始终大幅改善了基线。 对于噪声比率为30%的方案:i),我们的SCN在RAF-DB,FERPLus和AffectNet上的性能分别比基线高13.80%,1.07%和1.91%。 对于噪声比率为30%的方案
ii),尽管它们的性能相对较高,但它们在这些数据集上的SCN仍获得了2.20%,2.47%和3.12%的改进。对于这两种方案,随着噪声比率的增加,SCN的收益变得更加明显。 课程网络通过使用簇密度测量数据复杂性来设计训练课程,这可以避免在早期阶段训练带有噪声的标签数据。 MetaCleaner将每个类别中几个样本的特征汇总为加权均值特征以进行分类,这也可以减弱带有噪点的样本。 CurriculumNet和MetaCleaner都在很大程度上改善了基线,但仍然不如SCN(后者更简单)。 另一个有趣的发现是,RAF-DB上SCN的改进远高于其他数据集。 可能由以下原因解释。 一方面,RAF-DB包含复合面部表情,并由40个人进行众包注释,这使得数据注释更加不一致。 因此,我们的SCN也可以在原始RAFDB上获得改进,而不会产生合成标签噪音。 另一方面,AffectNet和FERPlus由专家注释,因此涉及的标签较少,导致对RAF-DB的改进较少。

Visualization of α in SCN:
为了进一步研究带有噪声注释的SCN的有效性,我们将SCN在RAF-DB上训练阶段的重要权重α可视化,噪声比为10%。
在图3中,第一行表示使用原始标签训练SCN时的重要权重。 第二行的图像带有合成损坏的标签标注,我们使用SCN(不带Relabel模块)来训练合成噪音数据集。 实际上,SCN会将那些标签损坏的图像视为噪声,并自动抑制它们的权重。 经过足够的训练时间后,将重新标记模块添加到SCN中,并对这些经过噪声标记的图像进行重新标记(当然,由于我们有重新标记的约束,因此可能无法重新标记许多其他图像)。 在其他几个时期之后,重要的权重变高了(第三行),这表明我们的SCN可以“自我修复”损坏的标签。 值得注意的是,重新贴标签模块中的新标签可能与“ground-truth”标签不一致(请参见第1、4和6列),但在可视化方面也很合理。

4.3.Exploring SCN on Real-World Uncertainties:
合成噪声数据证明了SCN的“self-cure”能力的有效性。 在本节中,我们将SCN应用于可以包括所有类型不确定性的实际FER数据库。
SCN on WebEmotion for pretraining:
由于将搜索关键字视为标签,因此我们收集的WebEmotion数据集包含大量噪声。 为了更好地验证SCN对现实噪声数据的影响,我们将SCN应用于WebEmotion进行预训练,然后在目标数据集上进行模型固定化。
我们在表3中显示了比较实验。从第一行和第二行,我们可以看到,在没有SCN的情况下对WebEmotion进行预训练分别使RAFDB,FERPlus和AffectNet的基线分别提高了6.97%,9.85%和1.80%。 在目标数据集上使用SCN进行微调可获得1%至2%的增益。 使用SCN对WebEmotion进行预培训可进一步将RAF-DB上的性能从80.42%提高到82.45%。这表明SCN在WebEmotion上学习了强大的功能,可以更好地进行细调。

SCN on Original FER datasets:
我们进一步在原始FER数据集上进行实验以评估我们的SCN,因为这些数据集不可避免地会遇到不确定性,例如模糊的面部表情,低质量的面部图像等。结果如表4所示。
从头开始进行训练时,我们建议的SCN会一致地改善基线,分别获得6.31%,0.7%和1.02的收益。 分别在RADDB,AffectNet和FERPlus上为%。 MetaCleaner还增强了RAF-DB的基线,但比我们的SCN稍差一点。通过预训练,这些数据集的Westillobtain改进为2.83%,1.73%和1.21%。 SCN和MetaCleaner的改进表明,这些数据集确实存在不确定性。
为了验证我们的推测,我们对RAF-DB的重要性权重进行排名,并在图4中显示一些重要性低的示例。从左上到右下的真实标签是惊讶,中立,中立,悲伤,惊讶 ,惊喜,中立,惊喜,中立,惊喜。我们发现,具有低质量和遮挡的图像难以注释,并且在SCN中的重要性较低。


4.4.Ablation Studies:
Evaluation of the three modules in SCN:
为了评估SCN各个模块的效果,我们设计了一个消融研究,以研究RAF-DB中的WCE-Loss,RR-Loss和Relabel模块。我们在表5中显示了实验结果。
以下可以得出一些结论。 首先,对于这两种训练方案,在基线(第一行)中添加一个天真的重新标记模块(第二行)可能会稍微降低性能。 这可能是由于基线模型中的许多重新标记操作是错误的。它间接表明,在经过精心设计的低重要性组中使用排序正则化进行重新标记更为有效。 其次,当添加一个模块时,我们通过WCE-Loss获得了最高的改进,它将RAF-DB上的基准从72%提高到76.26%。 这表明重新加权是SCN贡献最大的模块。 第三,RR-Loss和重新标记模块可以使RAFDB的WCE-Loss进一步提高2.15%。

Evaluation of the ratio γ:
在表6中,我们评估了RR-Loss和WCELoss之间不同比率的影响。 我们发现,为每次损失设置相等的权重可获得最佳结果。 将RR-Loss的重量从0.5增加到0.8会极大地降低性能,这表明WCE-Loss更重要。

Evaluation of δ1 and δ2:
δ1是一个余量参数,用于控制高重要性组和低重要性组之间的平均余量。 对于固定设置,我们将其评估为0到0.30。 图5(左)显示了固定和学习的δ1的结果。 默认值δ1= 0.15可获得最佳性能,这表明裕量应为适当的值。 我们还设计了一个可学习的δ1范式,并将其初始化为0.15。 在原始和噪声RAF-DB数据集中,可学习的δ1收敛到0.142±0.05,性能分别为77.76%和69.45%。
δ2是确定何时重新标记样品的余量。 默认值δ2为0.2。 我们在原始RAF-DB上将δ2从0评估为0.5,并将结果显示在图5(中)中。δ2= 0意味着如果最大预测概率大于给定标签的概率,则我们将重新标记样本。 较小的δ2会导致许多错误的重新标记操作,从而可能严重损害性能。 较大的δ2导致很少的重新标记操作,最终收敛为没有重新标记。 我们在0.2中获得最佳性能。

Evaluation of the β:
β是小批量中高重要性样本的比率。 我们研究了从0.9到0.5的不同比率的合成RAIS-DB数据集。 结果显示在图5(右)中。 我们的默认比率是0.7,可实现最佳性能。大的β会降低SCN的能力,因为它认为很少的数据是不确定的。 小β导致不确定性的过度考虑,从而不合理地减少了训练损失。
4.5.Comparison to the State of the Art:
表7将我们的方法与RAF-DB,AffectNet和FERPlus上的几种最新方法进行了比较。 IPA2LT [43]引入了潜在的真实性思想,用于在不同FER数据集之间使用不一致的注释进行训练。 gaCNN 利用基于补丁的注意力网络和全局网络。 RAN 利用人脸区域和原始人脸并具有级联注意力网络。 由于裁剪了补丁和区域,因此gaCNN和RAN非常耗时。 我们建议的SCN不会增加任何推理成本。 在RAF-DB,AffectNet和FERPlus上,我们的SCN分别以88.14%,60.23%和89.35%(使用IR50)优于这些最新方法。

5.Conclusion:
本文提出了一种自治愈网络(SCN),以抑制面部表情数据的不确定性,从而了解FER的鲁棒性。 SCN由三个新模块组成,包括自我注意重要性加权,等级调整和重新标记。 第一个模块通过自我关注来学习每个面部图像的权重,以捕获样本对训练的重要性,并用于损失加权。 排序正则化确保第一个模块学习有意义的权重以突出显示某些样本并抑制不确定的样本。 重新标记模块会尝试识别未标记的样本并修改其标记。 在三个公开数据集上进行的大量实验以及我们收集到的WebEmotion表明,我们的SCN具有最先进的结果,可以有效地处理综合和现实中的不确定性。