目录
1. 朴素贝叶斯分类(最小错误率贝叶斯)
首先得清楚:朴素贝叶斯就是最小错误率贝叶斯,同时也是最大后验概率贝叶斯。
朴素贝叶斯是基于贝叶斯定理与特征条件独立假设的分类方法。
对于给定的训练数据集,先假设输入输出的联合概率分布(特征条件独立);然后给定一个输入x,利用贝叶斯顶级求出输出y。
可以简单的认为训练的数据可以得到先验概率分布和条件概率分布,然后输入一个实例,计算这个实例的后验概率,通过后验概率的大小判断输出值y。
1.1 理论:
设训练空间为,是由P(X,Y)独立同分布产生
先验概率分布:,其中
是训练空间的输出标签。
例如一个训练数据的输入是那么
,
。
条件概率分布:,可以理解为在
发生的概率下,x发生的概率,但x又有
,之前说过训练空间是独立同分布,因此
贝叶斯定理:,把条件概率分布带入贝叶斯公式中,可以得到:
。
通过这个贝叶斯定理,输入一个x,我们就可以计算在x的条件概率下y的概率。这是朴素贝叶斯分类算法的基本公式。
因此朴素贝叶斯分类器可以表示为:
1.2 朴素贝叶斯算法流程:
输入:训练数据,其中
,
输出:某个输入x的分类
- 计算先验概率和条件概率
,
- 输入的实例
,计算后验概率:
- 确定输入实例x的类,在输出y:
1.3 举例说明
例如有一个表格,输入是X(),输出是Y。
的取值有1,2,3,
的取值有S,M,L。求给一个输入x=(2,S)的输出标记类y的值。

1.3.1 计算步骤:

1.3.2 程序代码:
from sklearn.naive_bayes import GaussianNB
# x_1 取值1 ,2 ,3
# x_2 取值s,m , l用4, 5, 6代替
X_train = [[1, 4], [1, 5], [1, 5], [1, 4], [1, 4], [2, 4], [2, 5], [2, 5], [2, 6], [2, 6],
[3, 6], [3, 5], [3, 5], [3, 6], [3, 6]]
y_train = [-1, -1, 1, 1, -1, -1, -1, 1, 1, 1, 1, 1, 1, 1, -1]
clf = GaussianNB()
clf.fit(X_train, y_train)
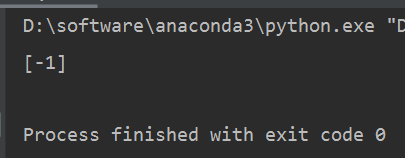
print(clf.predict([[2,4]]))
输出结果为-1,这和手动计算结果一致。
2. 贝叶斯估计
从上面,可以使用朴素贝叶斯完成分类,但是如果出现概率为0的情况时,会影响到后验概率计算的结果,产生偏差,所以引入贝叶斯估计算法,就是在原来的最小错误率贝叶斯的基础上增加一个参数和权重
。
条件概率的贝叶斯估计公式为:,可以看到,在随机变量各个取值的频数上加了一个正数
(
),
时就是极大似然估计,也是朴素贝叶斯,
时称为拉普拉斯平滑。
是每个输入的维度,例如上个例题中,X分为
的输入均是3维的,即
输入是
,所以
先验概率的贝叶斯估计公式为:,其中K是y的种类个数,如
,那么K=2。
2.1 算法流程:
输入:训练数据,其中
,
输出:某个输入x的分类
确定,
=3,K=2
- 计算先验概率和条件概率:
,
- 输入的实例
- 确定输入实例x的类,在输出y:
2.2 举例说明
同样是上一个例题问题,计算过程如下:

3 最小风险贝叶斯
在做决策的时候,我们往往不仅仅关心错误率是否最小。有时,我们更加关心某种决策带来的损失是否可以接受,以及接受的程度是多少。例如,在判断病人是否得传染病时,若把正常人判定为病人,那么患者就需要多承担费用。若把传染病人判定成正常人,那么会带来更多人感染的风险,损失将会是巨大的。
从这可以看出,引入风险后的贝叶斯是一种符合现实生活中的情景的。因此,需要事先做大量的调查,找到损失的分布,计算决策表。
引入风险函数,或者损失函数。假设x取,采用
作为当前风险。那么损失函数定义为:
。按照损失函数的形式求出一个矩阵,称之为决策表。把决策表中的损失和朴素贝叶斯求到的分类概率乘起来,得到条件风险。最后选择最小风险的方式,选出风险最小的分类。
3.1算法流程:
- 计算先验概率和条件概率
- 输入的实例
- 利用决策表计算后验风险:
- 选择最小风险,输出y:
3.2 案例说明
继续 以上面案例为例,通过朴素贝叶斯部分内容,得到
假设决策表如下:
| 1 | -1 | |
| 1 | 0 | 1 |
| -1 | 6 | 0 |
所以得到的后验风险为:
所以,根据最小风险,选择
作为最后的结果输出。
决策表是假设出来的,在现实生活中,决策表是通过大量的样本估计出来的。从决策表中可以看出,把1估计成-1的风险是1,把-1估计成1的风险则是6,因此把-1估计错误的风险代价要大得多。
--------------------------------------------------------------------------------------------------------------------------------------------------------
2020-6-18更新了最小风险贝叶斯部分内容。