主题
Redis和lua整合、Redis消息模式、Redis实现分布式锁、常见缓存问题
目标
- 理解lua概念,能够使用Redis和lua整合使用
- 理解redis消息原理
- 掌握redis分布式锁的原理、本质
- 理解缓存穿透、缓存雪崩、缓存击穿、缓存双写一致性并掌握解决方案
Redis和lua整合
什么是lua
lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
Redis中使用lua的好处
1)减少网络开销,在Lua脚本中可以把多个命令放在同一个脚本中运行
2)原子操作,redis会将整个脚本作为一个整体执行,中间不会被其他命令插入。换句话说,编写脚本的过程中无需担心会出现竞态条件
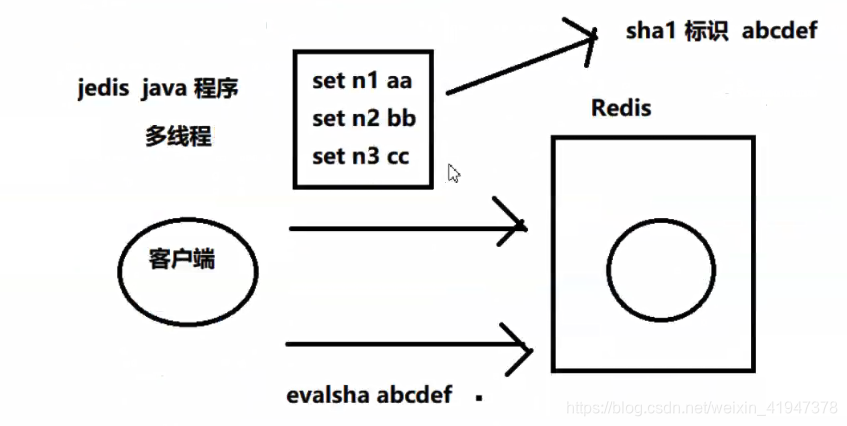
3)复用性,客户端发送的脚本会永远存储在redis中,在内存中生成一个sha1 标识 (script load ) ,这意味着其他客户端可以复用这一脚本来完成同样的逻辑
lua的安装(了解)
下载
地址:http://www.lua.org/download.html
可以本地下载上传到linux,也可以使用curl命令在linux系统中进行在线下载
curl -R -O http://www.lua.org/ftp/lua-5.3.5.tar.gz
安装
yum -y install readline-devel ncurses-devel
tar -zxvf lua-5.3.5.tar.gz
make linux
make install
如果报错,说找不到readline/readline.h, 可以通过yum命令安装
- yum -y install readline-devel ncurses-devel
安装完以后再
- make linux / make install
最后,直接输入 lua命令即可进入lua的控制台
lua常见语法(了解)
详见http://www.runoob.com/lua/lua-tutorial.html

Redis整合lua脚本
从Redis2.6.0版本开始,通过内置的lua编译/解释器,可以使用EVAL命令对lua脚本进行求值。
两种用法,一种在Redis命令行中使用,一种在Linux命令行中用。
Redis命令行
EVAL命令
通过执行redis的eval命令,可以运行一段lua脚本。
EVAL script numkeys key [key ...] arg [arg ...]
命令说明:
- script参数:字符串,是一段Lua脚本程序,它会被运行在Redis服务器上下文中,这段脚本不必(也不应该)定义为一个Lua函数。
- numkeys参数:用于指定键名参数的个数。
- key [key …]参数: 从EVAL的第三个参数开始算起,使用了numkeys个键(key),表示在脚本中所用到的那些Redis键(key),这些键名参数可以在Lua中通过全局变量KEYS数组,用1为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推)。
- arg [arg …]参数:key对应的value,可以在Lua中通过全局变量ARGV数组访问,访问的形式和KEYS变量类似(ARGV[1] 、 ARGV[2] ,诸如此类)。
举例:
eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second

lua脚本中调用Redis命令
redis.call():
- 返回值就是redis命令执行的返回值
- 如果出错,则返回错误信息,不继续执行
redis.pcall():
- 返回值就是redis命令执行的返回值
- 如果出错,则记录错误信息,继续执行
注意事项:
在脚本中,使用return语句将返回值返回给客户端,如果没有return,则返回nil
举例:
eval "return redis.call('set',KEYS[1],ARGV[1])" 1 n1 zhaoyun

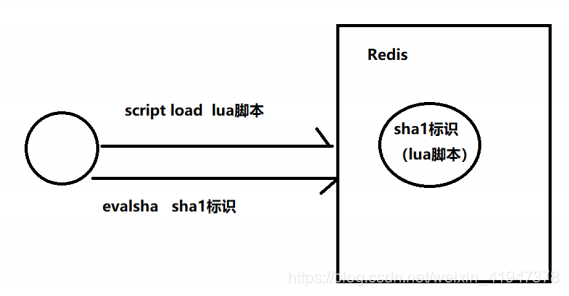
SCRIPT命令
SCRIPT FLUSH :清除所有脚本缓存
SCRIPT EXISTS :根据给定的脚本校验和,检查指定的脚本是否存在于脚本缓存
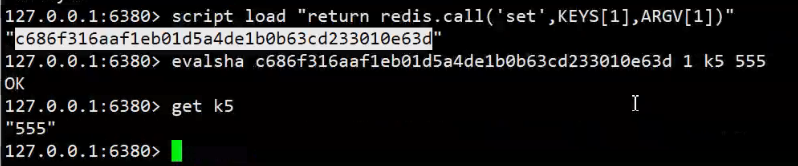
SCRIPT LOAD :将一个脚本装入脚本缓存,返回SHA1摘要,但并不立即运行它
192.168.24.131:6380> script load "return
redis.call('set',KEYS[1],ARGV[1])"
"c686f316aaf1eb01d5a4de1b0b63cd233010e63d"
192.168.24.131:6380> evalsha c686f316aaf1eb01d5a4de1b0b63cd233010e63d 1
n2 zhangfei
OK
192.168.24.131:6380> get n2
SCRIPT KILL :杀死当前正在运行的脚本
EVALSHA
EVAL 命令要求你在每次执行脚本的时候都发送一次脚本主体(script body)。
Redis 有一个内部的缓存机制,因此它不会每次都重新编译脚本,不过在很多场合,付出无谓的带宽来传送脚本主体并不是最佳选择。
为了减少带宽的消耗, Redis 实现了 EVALSHA 命令,它的作用和 EVAL 一样,都用于对脚本求值,但它接受的第一个参数不是脚本,而是脚本的 SHA1 校验和(sum)
Linux命令行
可以通过下面命令直接执行lua脚本:
redis-cli --eval
举例:
test.lua文件
-
return redis.call('set',KEYS[1],ARGV[1]) - 执行命令
./redis-cli -h 192.168.24.131 -p 6380 --eval test.lua n3 , 'liubei'
list.lua文件
- 先去创建list集合
127.0.0.1:6380> lpush list 1 2 3 4 5 (integer) 5 127.0.0.1:6380> - list.lua
local key=KEYS[1] local list=redis.call("lrange",key,0,-1); return list;./redis-cli --eval list.lua list
利用Redis整合Lua,主要是为了性能以及事务的原子性。因为redis帮我们提供的事务功能太差。
Redis消息模式
队列模式(1v1)
使用list类型的lpush和rpop实现消息队列

注意事项:
- 消息接收方如果不知道队列中是否有消息,会一直发送rpop命令,如果这样的话,会每一次都建立一次连接,这样显然不好。
- 可以使用brpop命令,它如果从队列中取不出来数据,会一直阻塞,在一定范围内没有取出则返回null、
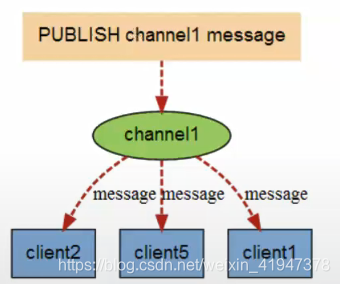
发布订阅模式(1vN)
-
订阅消息(subscribe)
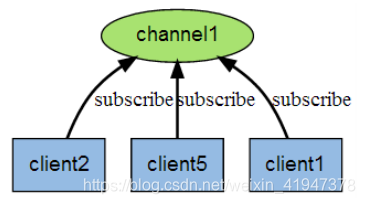
示例:subscribe kkb-channel -
Redis发布订阅命令
publish kkb-channel “消息1” -
Redis发布订阅命令
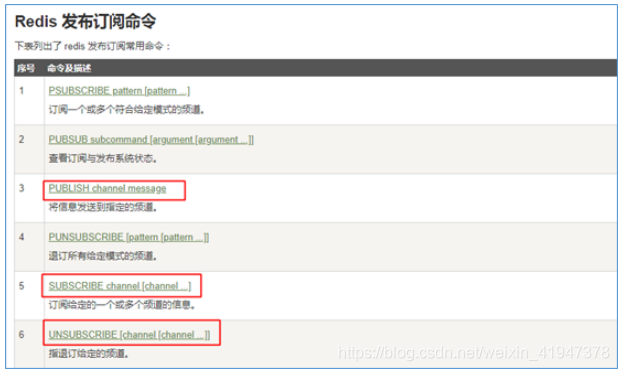
-
业务场景
- 量小的站内信
Redis实现分布式锁
CAP:最多只能满足其二。
P:分区容错性,只要是分布式架构,那么必然会满足P
C:一致性
A:可用性
Redis是AP结构,不适合做严格的分布式锁。如果共享资源是钱,订单,金融等敏感数据,不能用AP结构,要用CP结构。因为AP结构,锁资源是存在分布式集群的机器中的,AP为了保证高可用,可以损失一致性的。
例如主从的Redis,JVM1在主Redis上set值获取锁后,还没有同步给从Redis就挂了,通过哨兵机制把从Redis变为主Redis,JVM2在去现在的主Redis竞争,也能获取到锁,所以就有问题。
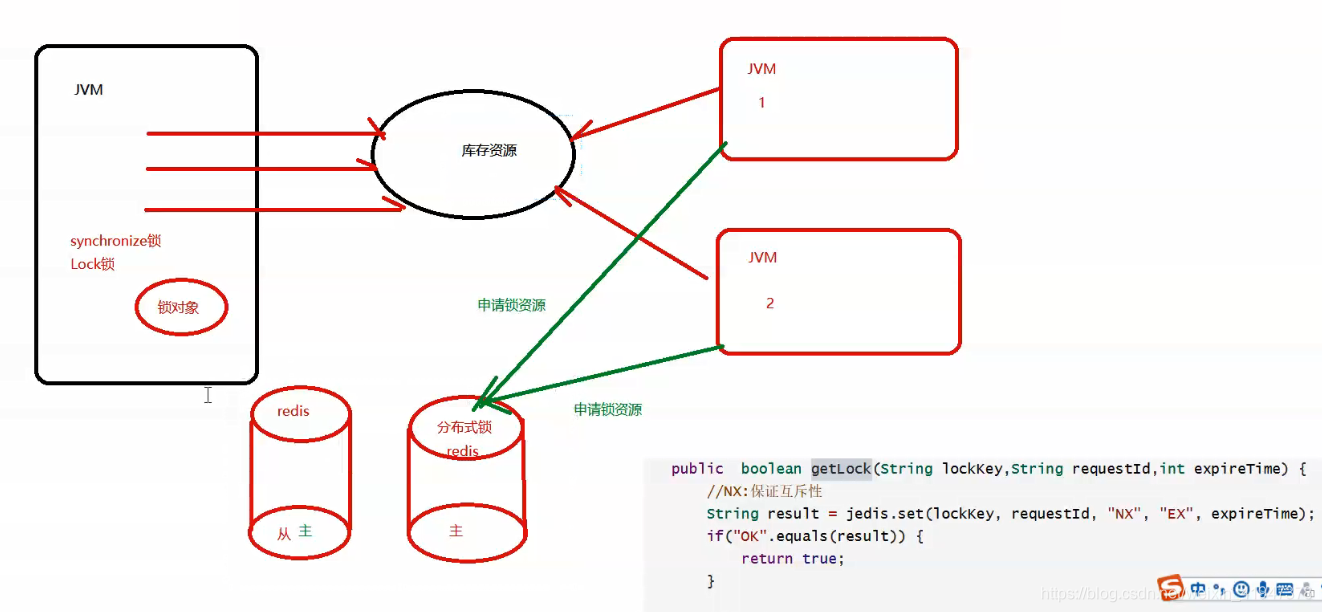
根本原因就是没有处理强一致性!只保证了高可用。
锁的处理
- 单应用中使用锁:(单进程多线程)
- synchronize、ReentrantLock
- 分布式应用中使用锁:(多进程多线程)
- 分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
分布式锁的实现方式
- 基于数据库的乐观锁实现分布式锁
- 基于 zookeeper 临时节点的分布式锁(
支持CP)
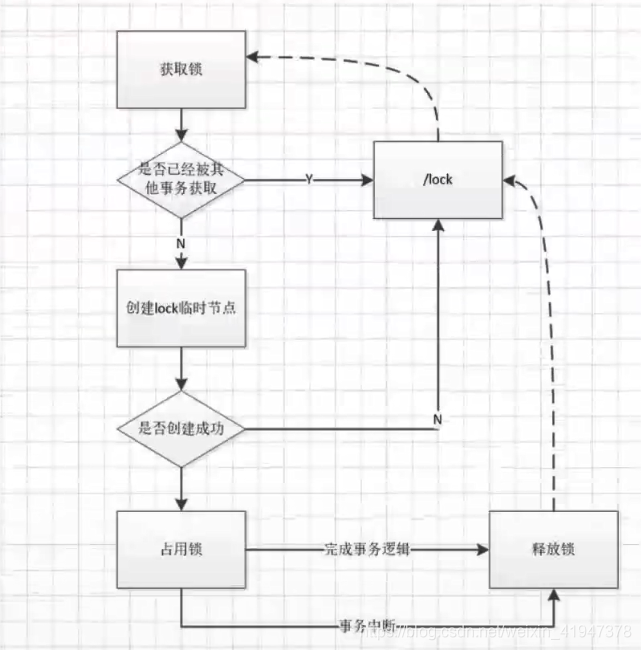
- 能保证高效锁竞争都可以做分布式锁。
- 基于 Redis 的分布式锁
- 基于ETCD(
最好)
分布式锁的注意事项
分布式锁特性:
- 互斥性:在任意时刻,只有一个客户端能持有锁
- 同一性:加锁和解锁必须是同一个客户端,客户端自己不能把别人加的锁给解了。
- 可重入性:即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
实现分布式锁
原理:利用Redis的单线程特性对共享资源进行串行化处理
获取锁
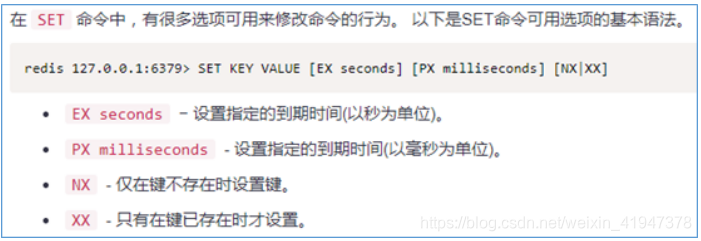
方式1(使用set命令实现)–推荐
/**
* 使用redis的set命令实现获取分布式锁
* @param lockKey 可以就是锁
* @param requestId 请求ID,保证同一性 uuid+threadId+随机
* @param expireTime 过期时间,避免死锁
* @return
*/
public boolean getLock(String lockKey,String requestId,int expireTime){
//NX:保证互斥性
//hset 原子性操作
String result = jedis.set(lockKey, requestId, "NX", "EX",expireTime);
if("OK".equals(result)) {
return true;
}
return false;
}
方式2(使用setnx命令实现) – 并发会产生问题
public boolean getLock(String lockKey,String requestId,int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
if(result == 1) {
jedis.expire(lockKey, expireTime);
return true;
}
return false;
}
由于这是两条Redis命令,不具有原子性,如果程序在执行完setnx()之后突然崩溃,导致锁没有设置过期时间。那么将会发生死锁。。。。还可以用lua脚本
释放锁
方式1(del命令实现)
/**
* 释放分布式锁
* @param lockKey
* @param requestId
*/
public static void releaseLock(String lockKey,String requestId) {
if (requestId.equals(jedis.get(lockKey))) {
jedis.del(lockKey);
}
}
并发会产生问题:
问题在于如果调用jedis.del()方法的时候,这把锁已经不属于当前客户端的时候会解除他人加的锁。那么是否真的有这种场景?答案是肯定的,比如客户端A加锁,一段时间之后客户端A解锁,在执行jedis.del()之前,锁突然过期了,此时客户端B尝试加锁成功,然后客户端A再执行del()方法,则将客户端B的锁给解除了。
方式2(redis+lua脚本实现)–推荐
public static boolean releaseLock(String lockKey, String requestId) {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script,Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (result.equals(1L)) {
return true;
}
return false;
}
常见缓存问题
缓存使用流程:
先查询缓存,缓存没有,再查数据库
查完数据库,将查询结果放入缓存
缓存穿透
什么叫缓存穿透?
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。如果key对应的value是一定不存在的,并且对该key并发请求量很大,就会对后端系统造成很大的压力。
也就是说,对不存在的key进行高并发访问,导致数据库压力瞬间增大,这就叫做【缓存穿透】。
产生的原因
(1)自身业务代码或者数据出现问题
(2)一些恶意攻击,爬虫等造成大量空命中
如何解决?
-
1)缓存空对象:
将null值也存入缓存,同时设置有效期。(一般几秒就OK了,因为并发一般都集中在单表,平摊几秒压力就不是很大了)String get(String key){ //从缓存中获取数据 String cacheValue=cache.get(key); //缓存为空 if(StringUtils.isBlank(cacheValue)){ //从存储中获取 String storageValue=storage.get(key); cache.set(key,storageValue); //如果存储数据为空,需要设置一个过期时间(300秒) if(storageValue==null){ cache.expire(key,60*5); } return storageValue; }else{ //缓存非空 return cacheValue; } } -
2):布隆过滤器。主要用来判断该数据是否【
不存在】。
将存在的key放入布隆过滤器中。当一个查询请求过来时,先经过此过滤器,如果此过滤器认为该数据不存在,就直接丢弃,不再继续访问缓存层和存储层。布隆过滤器长度越短判断越不准确

缓存击穿
什么叫缓存击穿?
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题,这个和缓存雪崩的区别在于这里针对某一key缓存,前者则是很多key。
缓存在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
如何解决?
- 对于热点数据,慎重考虑过期时间,确保热点期间key不会过期,甚至有些可以设置永不过期。
- 用分布式锁控制访问的线程,使用redis的setnx互斥锁先进行判断,这样其他线程就处于等待状态,保证不会有大并发操作去操作数据库。
if(redis.sexnx()==1){ //先查询缓存 //查询数据库 //加入缓存 }
缓存雪崩
什么叫缓存雪崩?
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
如何解决?
- 1):在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
- 2):不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
- 3):做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
- 4):使用高可用的分布式缓存集群,确保缓存的高可用性,比如redis-cluster。
- 5):如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
- 6):设置热点数据永远不过期。
缓存双写一致性
产生的原因
在使用数据库缓存的时候,读和写的流程往往是这样的:
- 读取的时候,先读取缓存,如果缓存中没有,就直接从数据库中读取,然后取出数据后放入缓存
- 但是,在更新缓存方面,我们是需要先更新缓存,再更新数据库?还是先更新数据库,再更新缓存?还是说有其他的方案?
演示一些问题:
- 先更新数据库再更新缓存
- 操作步骤(线程A和线程B都对同一数据进行更新操作):
1、 线程A更新了数据库
2、 线程B更新了数据库
3、 线程B更新了缓存
4、 线程A更新了缓存 - 可以看到会产生脏读
- 操作步骤(线程A和线程B都对同一数据进行更新操作):
- 先更新数据库再删除缓存
- 操作步骤(线程A更新、线程B读)
请求B查询发现缓存不存在
请求B去数据库查询得到旧值(还没有写入缓存)
请求A进行写操作,将新值写入数据库,删除缓存
请求B将旧值写入缓存 - 可以看到也会出现不一致性问题
- 操作步骤(线程A更新、线程B读)
如何解决
要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,比较推荐降低概率的玩法,因为2PC太慢,而Paxos太复杂。,当然,最好还是为缓存设置上过期时间。
由于数据不一致的根源是因为数据源不一样,所以想追求强一致性很难,还是追求最终一致性
解决方案:延时双删策略,伪代码如下:
public** **void** write(**String** key, **Object** data){``
db.updateData(data);
redis.delKey(key);
Thread.sleep(1000);
redis.deleKey(key);
}
保证数据的最终一致性(延时双删)
- 1、先更新数据库同时删除缓存项(key),等读的时候再填充缓存
- 2、2秒后再删除一次缓存项(key)
- 3、设置缓存过期时间 Expired Time 比如 10秒 或1小时
- 4、将缓存删除失败记录到日志中,利用脚本提取失败记录再次删除(缓存失效期过长 7*24)
升级方案
- 通过数据库的binlog来异步淘汰key,利用工具(canal)将binlog日志采集发送到MQ中,然后通过ACK机制确认处理删除缓存。
关于缓存一致性的题外话
推荐一篇缓存更新的文章:《缓存更新的套路》
如果你对IO模型,mysql数据库,Redis持久化底层原理有了解的话,你会发现宏观系统架构中的很多设计都来源于这些微观的东西,例如mysql中innodb存储引擎的内存池、linux中系统空间和用户空间…