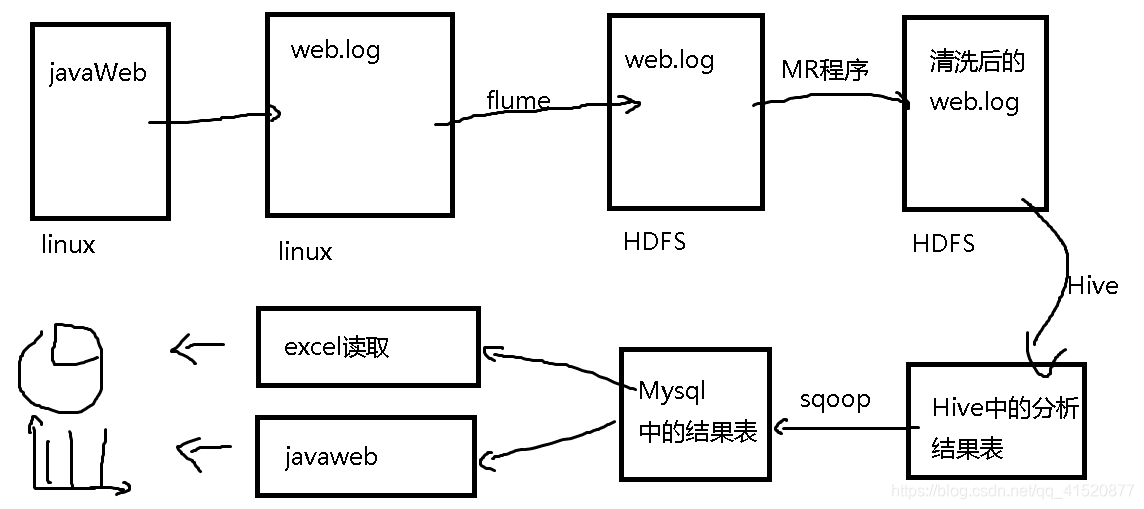
java web 的项目流程:
windows下安装并配置Apache Tomcat:
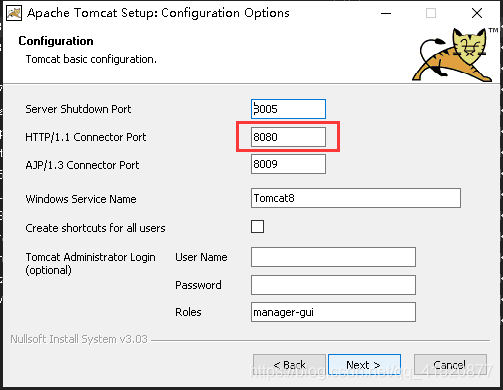
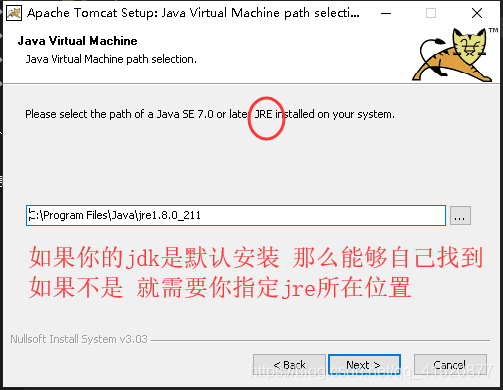
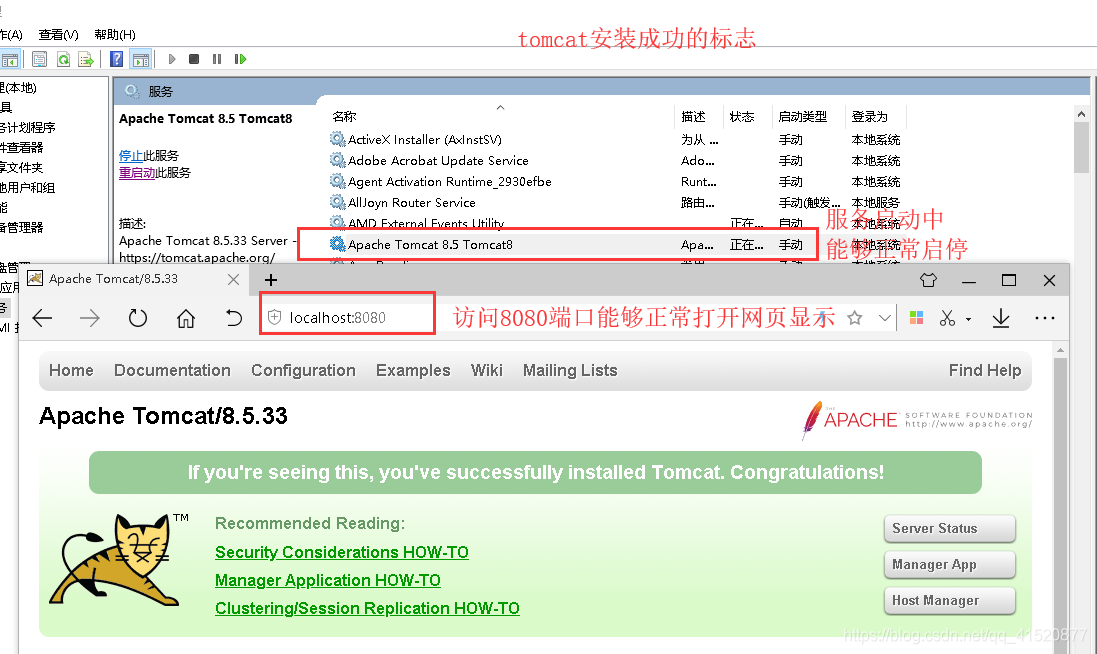
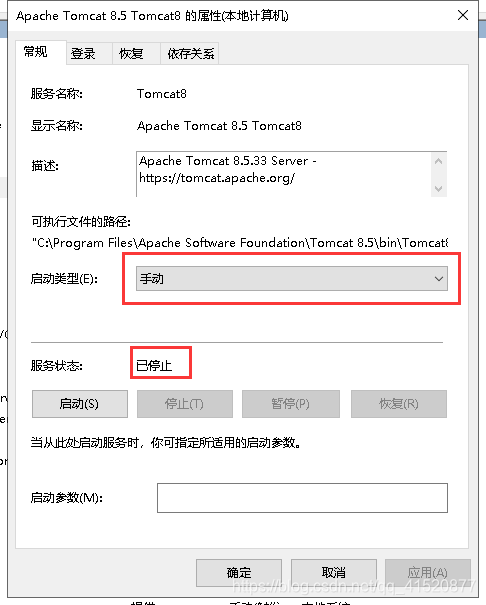
创建新的web项目 并进行相关配置:
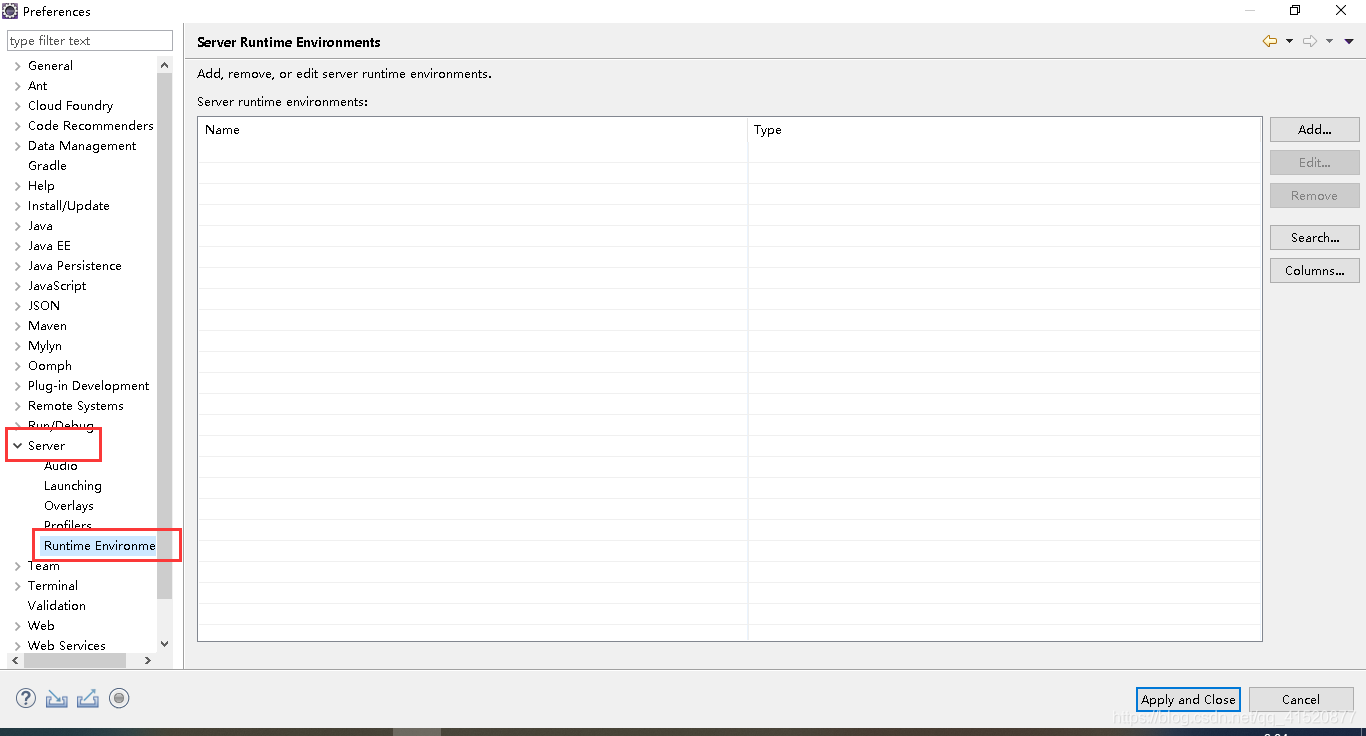
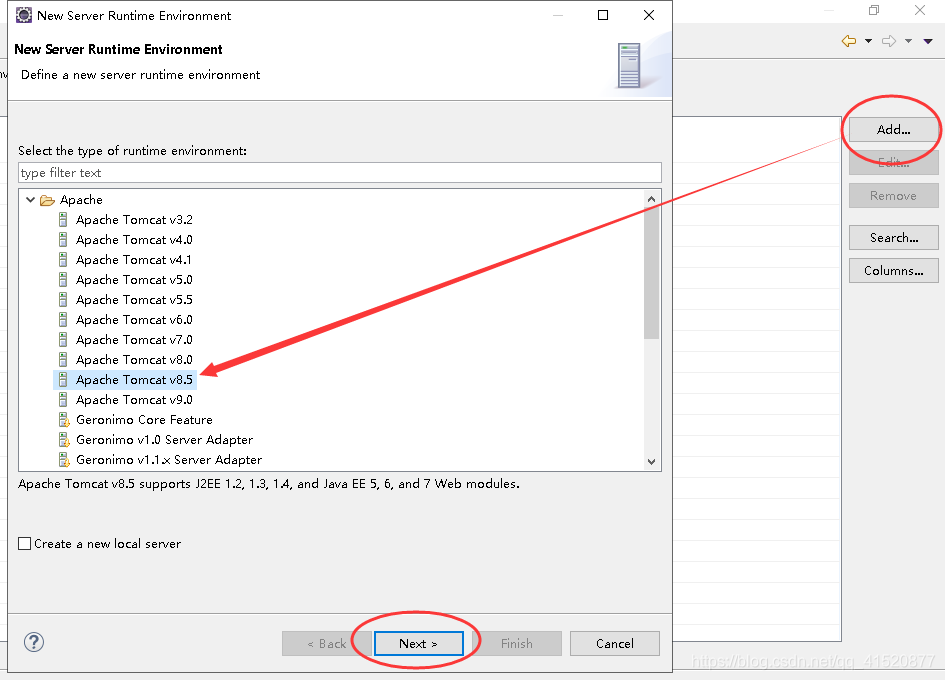
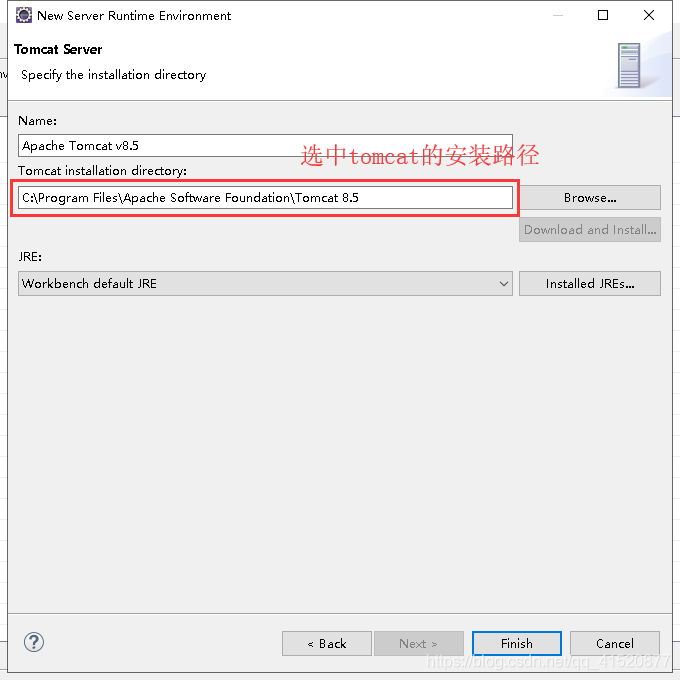
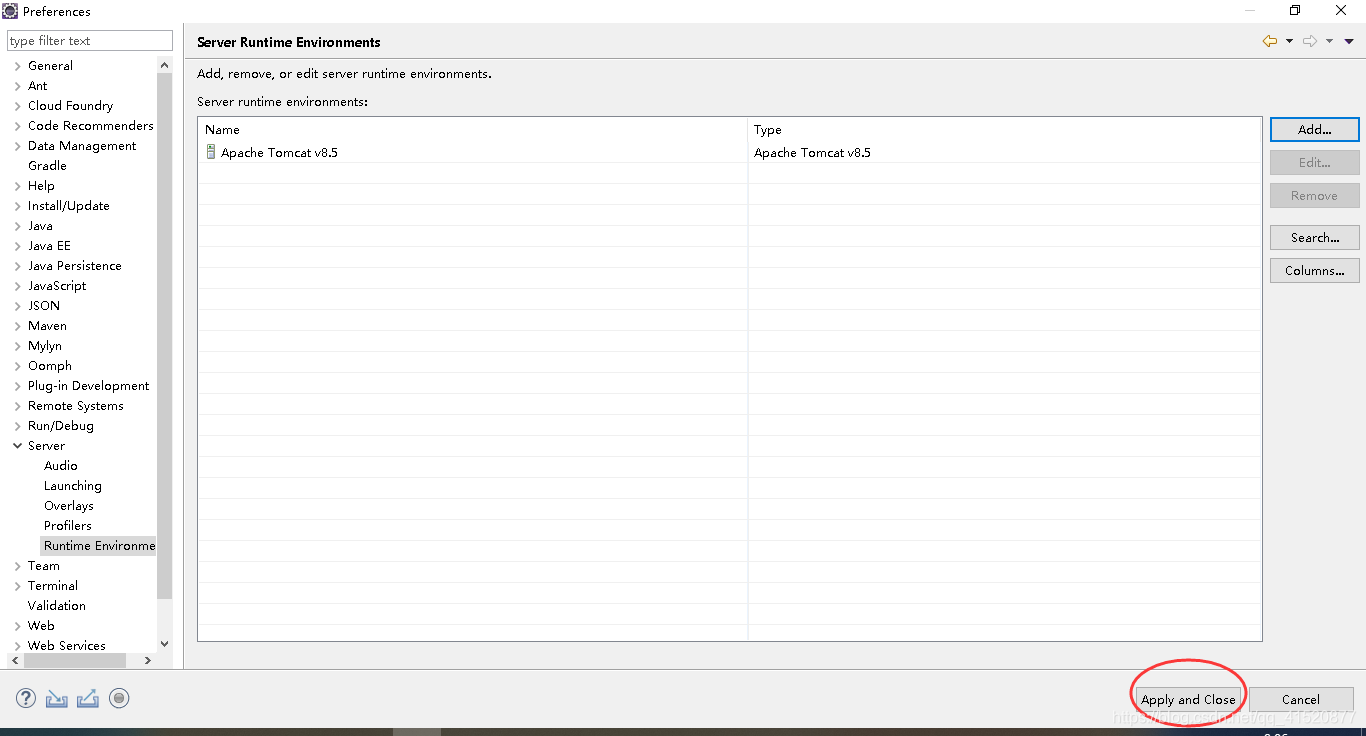
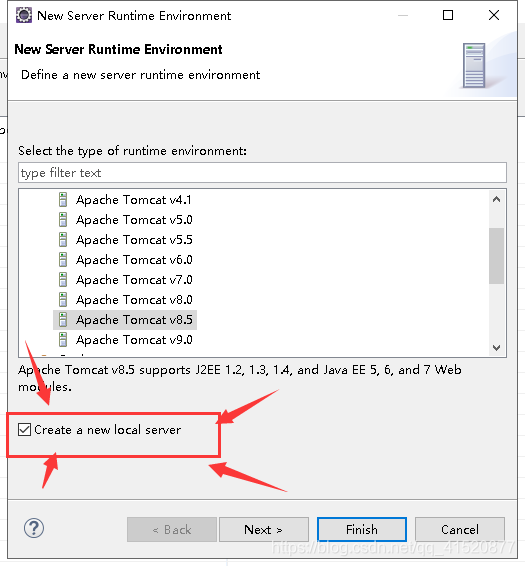

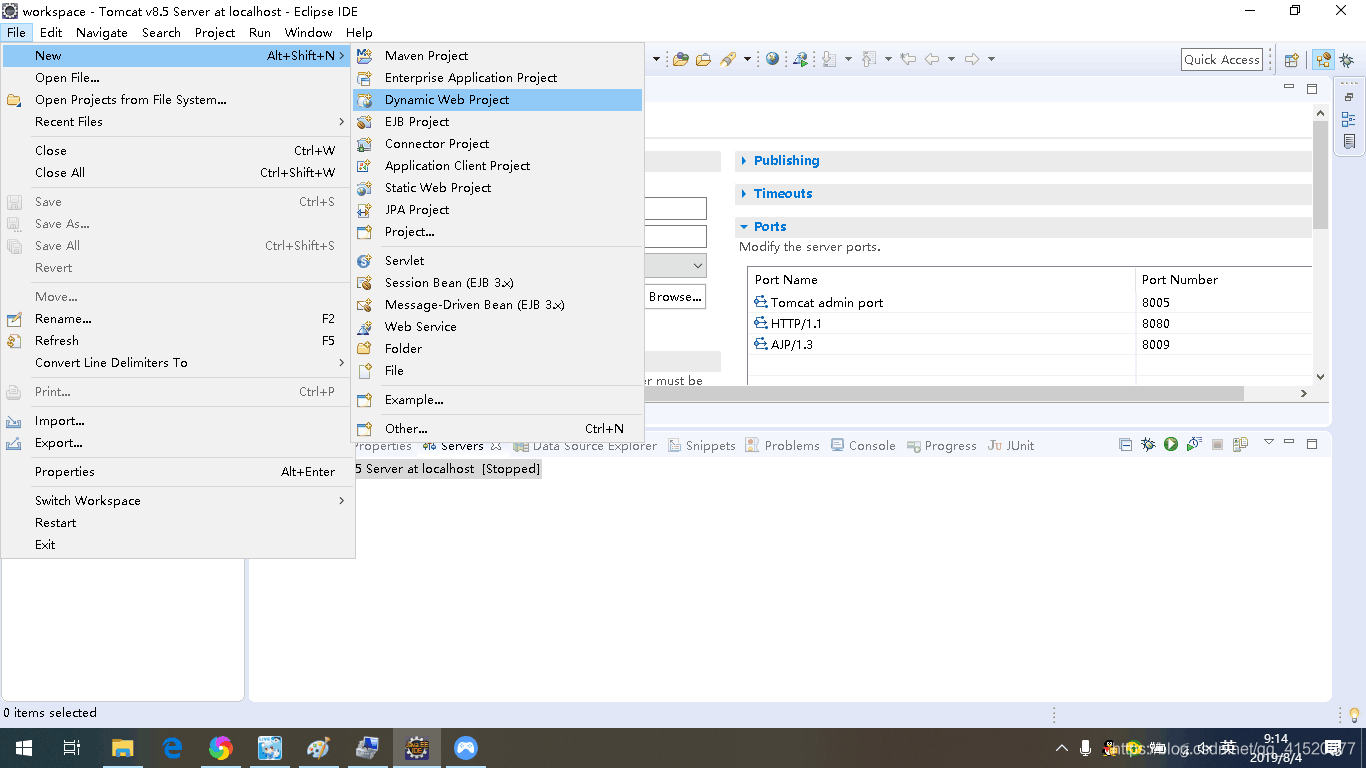
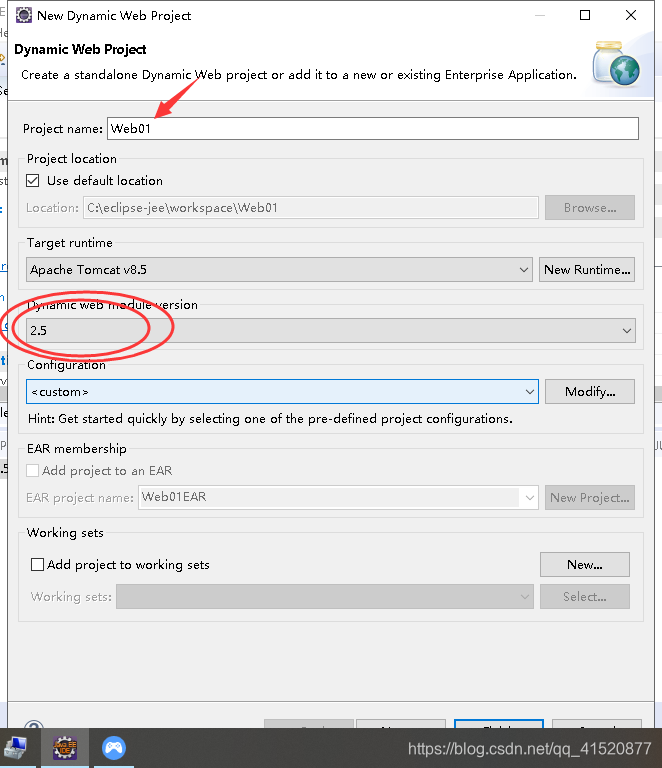
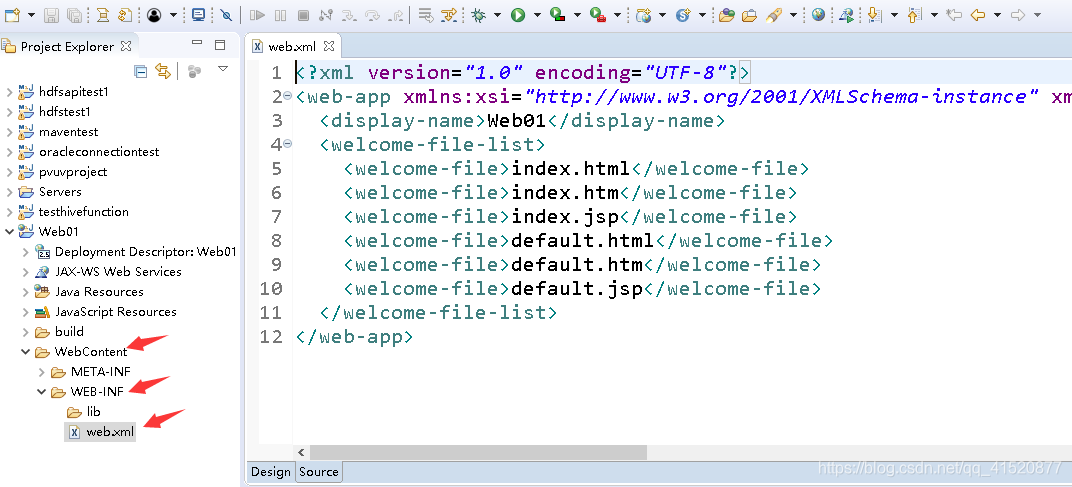
将上述修改如下:
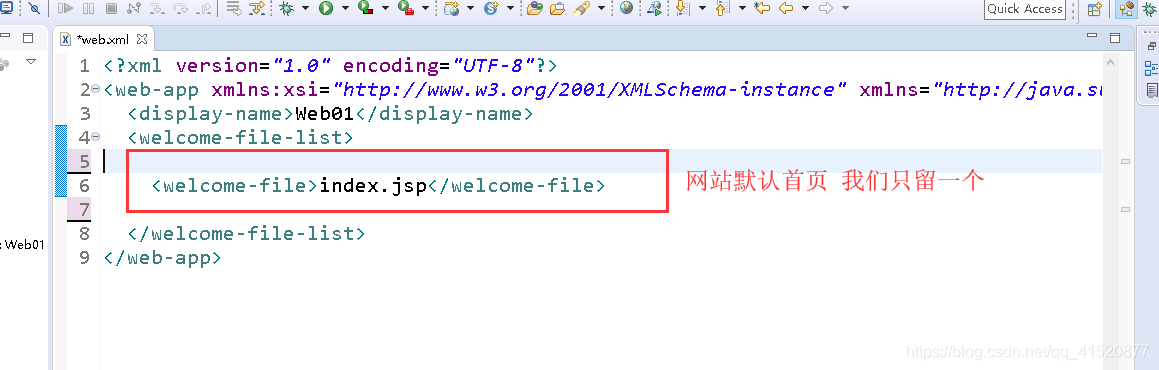
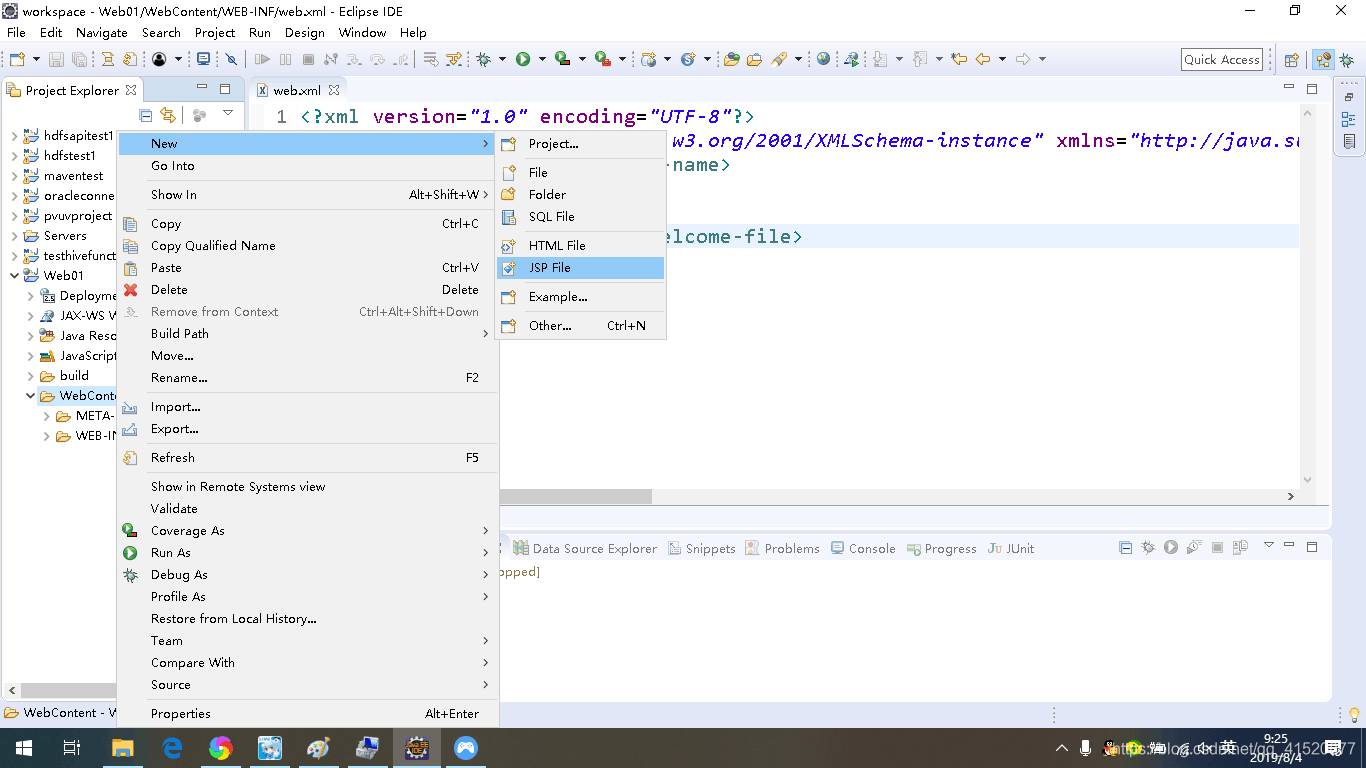
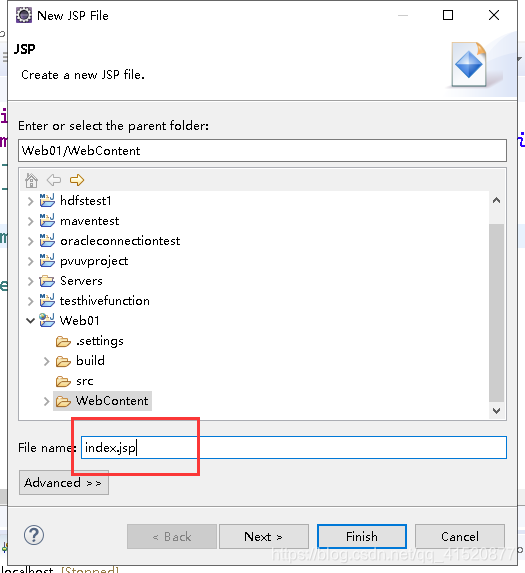
将上述index.jsp文件删除后 新建立一个
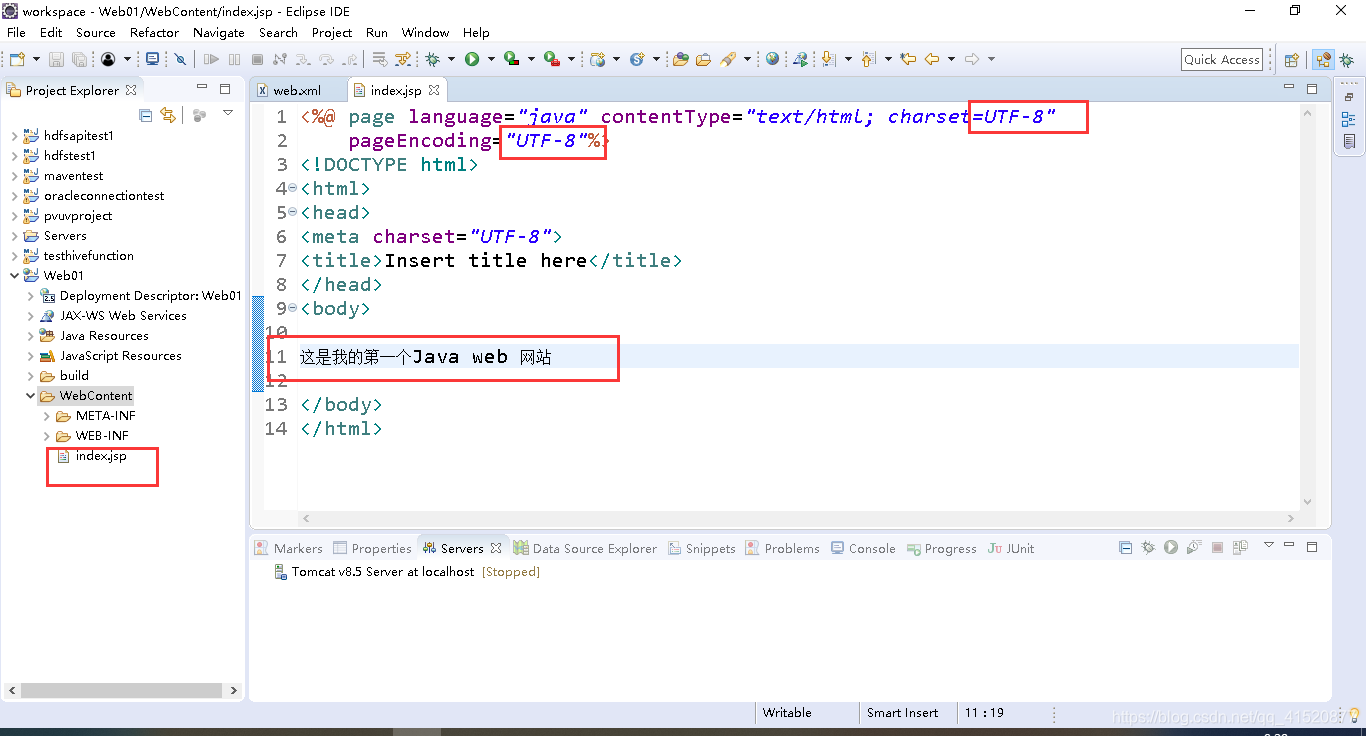
运行:

结果如下:
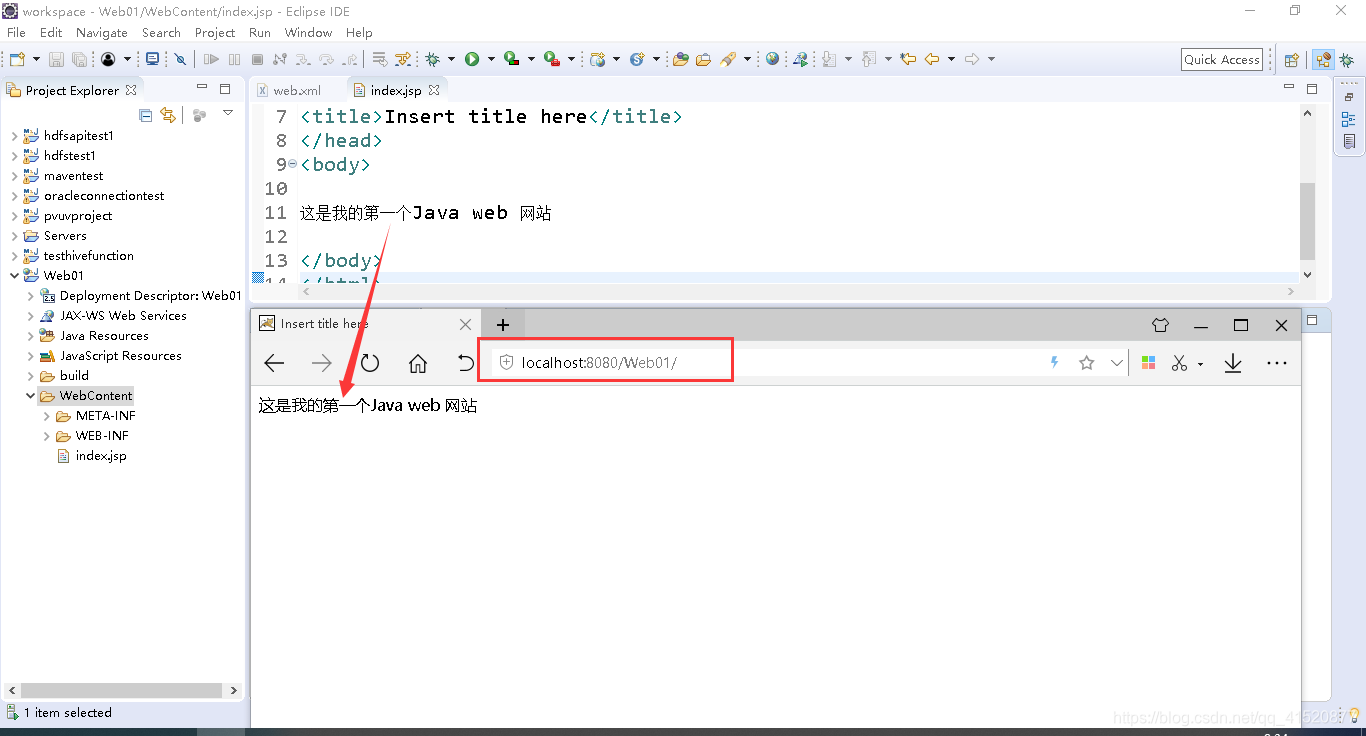
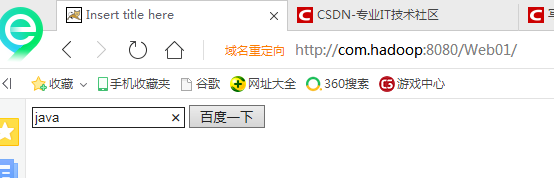
测试小案例:
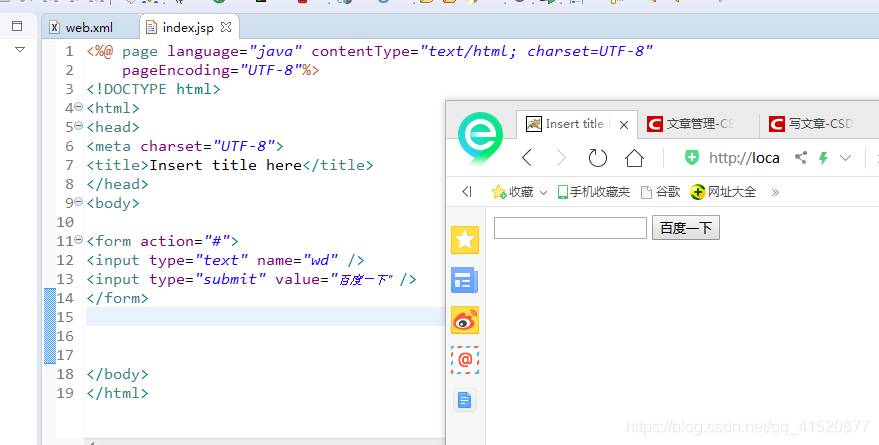
输入如下代码块:
<form action="#">
<input type="text" name="wd" />
<input type="submit" value="百度一下" />
</form>
Linux下安装并配置Apache Tomcat:
切换到tools目录下 将文件上传进去 并查看:
解压:

切换到Apache目录下 进行查看文件:
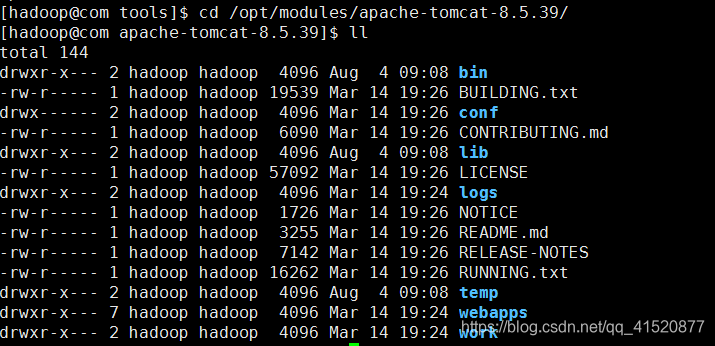
查看bin目录下的文件:

启动Apache Tomcat:

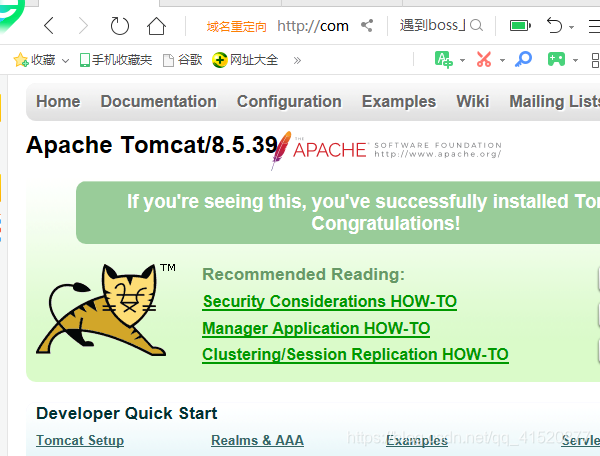
验证是否启动:输入 com.hadoop:8080 出现如下界面即可证明启动
关闭Apache Tomcat:

将项目web01 导进去到Linux上 实现:
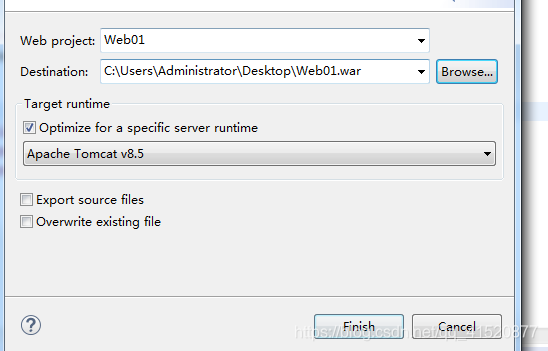
将web01上传进来:
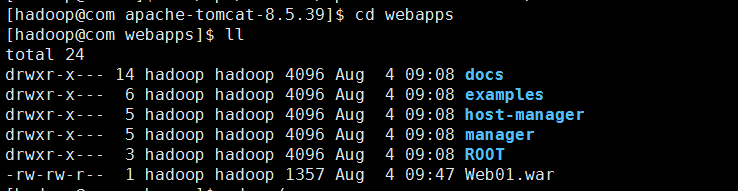
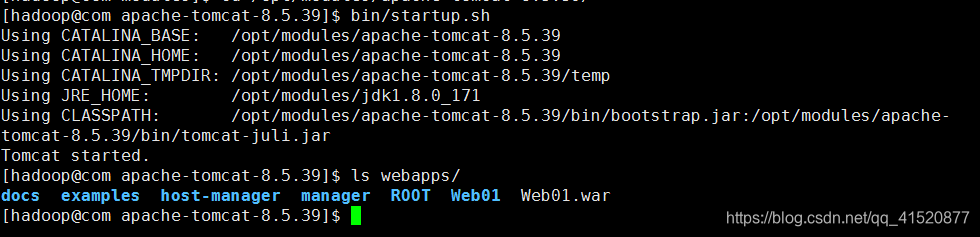
查看如下:
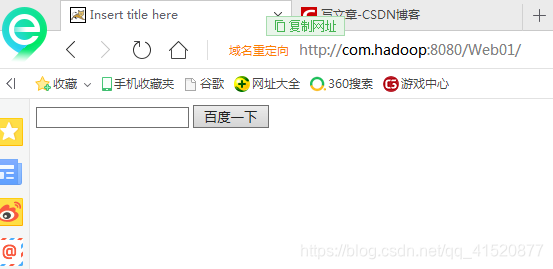
切换到logs下:
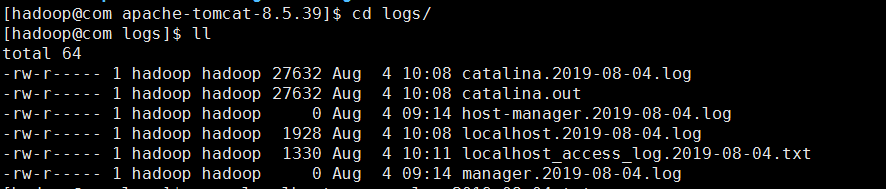
查看日志文件:

配置server.xml文件:
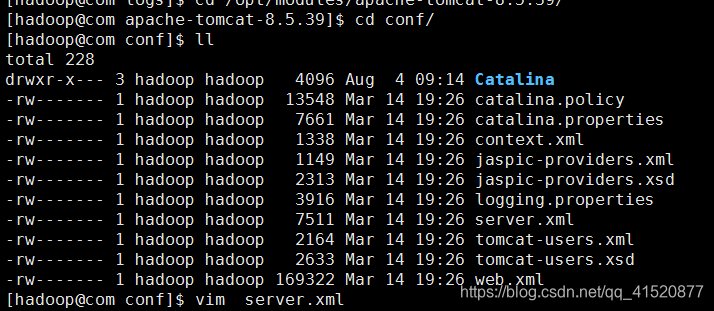
配置后查看:产生字段
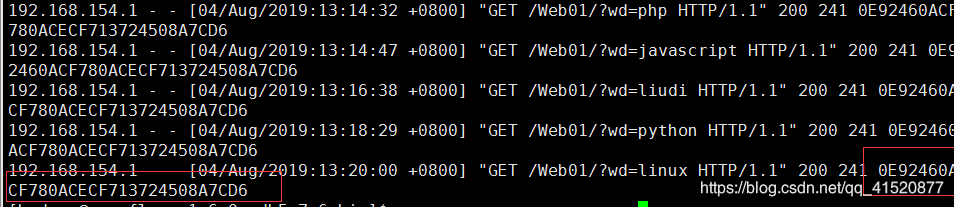
%s 的作用是添加一个让服务器记录sessionid

查看:

然后启动:
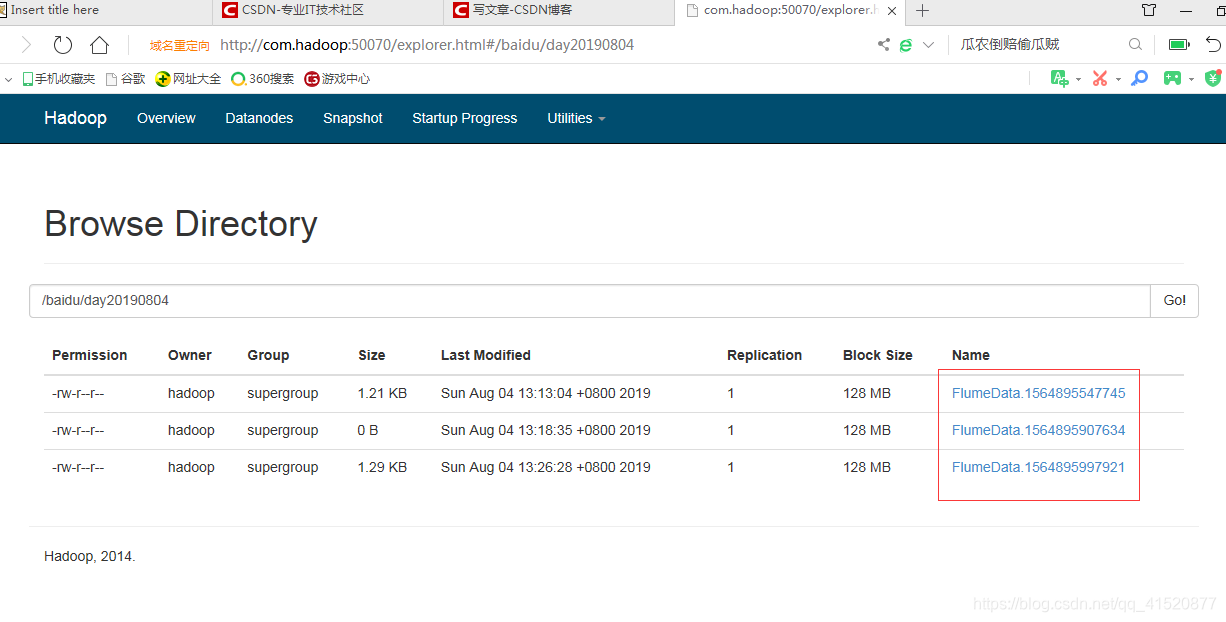
打开不同的浏览器 输入相同的数 发现日志的结果不一样。
三. java web 的日志采集:
在/opt/modules/apache-tomcat-8.5.39/logs/进行操作:

a1.sources=s1
a1.channels=c1
a1.sinks = k1
a1.sources.s1.type=exec
a1.sources.s1.command=tail -f /opt/modules/apache-tomcat-8.5.39/logs/localhost_access_log.2019-08-04.txt
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=hdfs
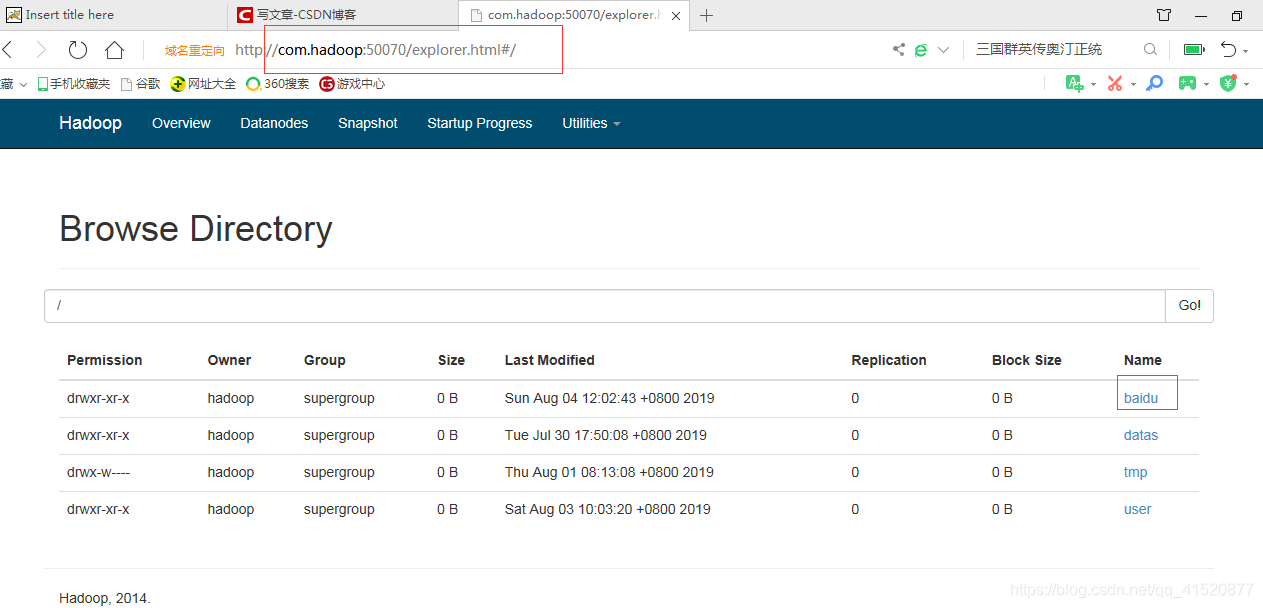
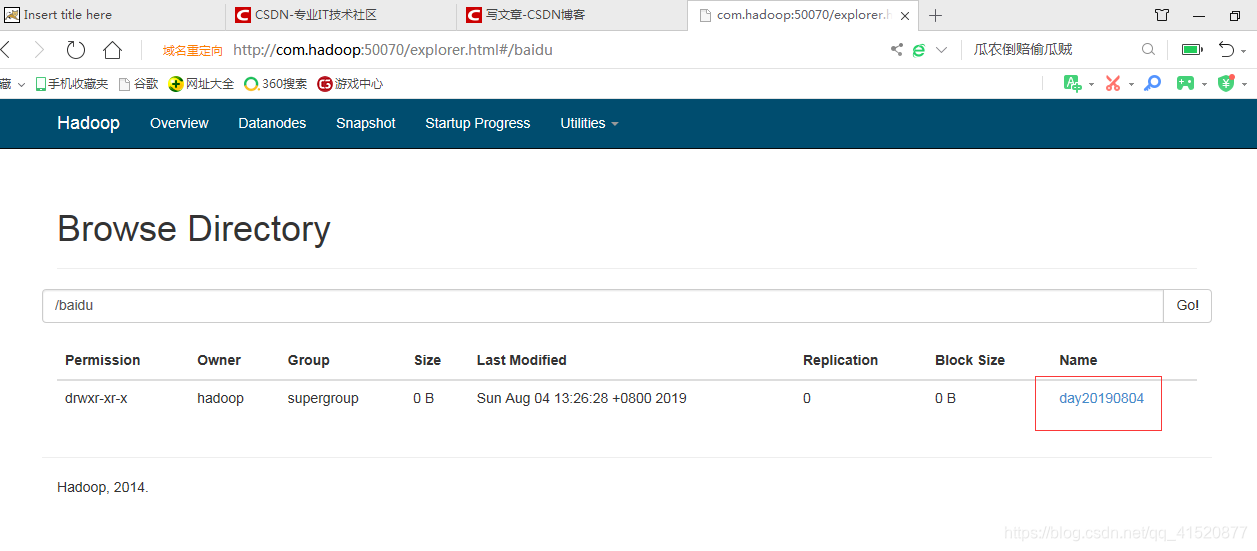
a1.sinks.k1.hdfs.path=/baidu/day20190804
a1.sinks.k1.hdfs.rollSize=10240
a1.sinks.k1.hdfs.rollInterval=0
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=Text
a1.sources.s1.channels=c1
a1.sinks.k1.channel=c1
将文件移动到flume下的conf下:

查看文件:
将hdfs解压后的文件夹里面的内容上传到lib文件下:
新开一个窗口 启动集群:

创建文件夹:

重启 Apache:

回到第一个窗口运行: