【代码实现】基于tensorflow2.2实现,直接运行在goole colab,见github仓库.
【参考文献】
1. Deep Biaffine Attention for Neural Dependency Parsing - 中文笔记
2. DEEP BIAFFINE ATTENTION FOR NEURAL DEPENDENCY PARSING
Introduction
使用基于图的方法解析依存句法,对句中每次词找到head以及其到head的依存标签,因此针对图的依存句法解析需解决两个问题:
- 不定类别分类,哪两个节点连接弧?
- 固定类别分类,弧的标签是什么?
本文使用 双仿射分类器 分别预测依存关系(arc)和依存标签(label),在英语PTB数据集中0.957 UAS, 0.941 UAS,使之成为graph-based依存句法解析的基准模型,文中也介绍模型一些超参数对模型效果的影响。
模型的以下特点:
- 使用双仿射注意力机制,而不是使用传统基于MLP注意力机制的单仿射分类器,或双线性分类器;
- 第一次尝试使用MLP对LSTM的输出进行降维,再输入至仿射层;
Deep Biaffine Attention

双仿射层的作用
本文提出的双仿射注意力机制可看作为传统的单仿射分类器,即使用stacked LSTM输出的MLP线性变换 替换权重矩阵 ,线性变换 替换偏置项 ,arc双仿射分类器如下所示:
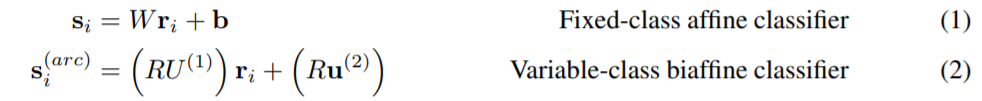
双仿射分类器使用双线性层,比传统使用两层线性层和一个非线性激活单元的MLP网络更简单,同时,arc双仿射分离器对两种概率直接建模:
- ,结点 接受任意依赖的先验概率;
- ,结点 接受单词 依赖的概率;
同样地,使用另一个label双仿射分类器预测单词与其头结点(glod or predicted,训练时来自于真实头结点,预测时来源于arc分类器输出的最可能头结点)间的依赖标签:
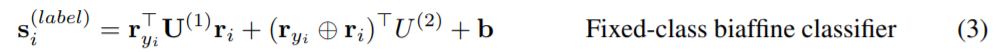
式中 是维度为 的高阶张量(m是标签个数,d是biaffine输入维度),label双仿射分类器对以下概率建模:
- 结点 被贴上特定依存标签的可能性;
- 结点 头结点 被贴上特定依存标签的可能性;
- 给定特定头结点 下,结点 被贴上特定依存标签的可能性;
arc分类器是不定类别分类器,类别数与序列长度有关,label分类器是固定类别分类器,类别数等于所有可能的依存关系数。
MLP层的作用
MLP层使用较小维度输出,可对LSTM输出降维后再输入至仿射层,避免过拟合。
LSTM层的输出状态需要携带足够的信息,如识别其头结点,找到其依赖项,排除非依赖项,分配自身及其所有依赖的依存标签,而且还需要把其它任何相关信息传递至前或后单元。对这些不必要的信息进行训练会降低训练速度,而且还有过拟合的风险。
使用MLP对LSTM输出降维,并使用双仿射变换,可解决这一问题!具体地说,使用两个独立的MLP网络对stacked BiLSTM输出重新编码,分别得到单词的dep和head向量。

我们称以上网络结构为深层双仿射注意力机制。在预测依存树时,与其它基于图的依存句法解析模型一样,将每个单词在arc分类器输出分数最高的单词作为其头结点(本文也验证了MST算法)。
理解Attention
式6得到的arc分数向量可理解为,单词
自身dep向量对句中其它任意单词head向量的注意力分数,酷似attention!
矩阵乘法等价形式
若将偏置项
放入参数矩阵
,并同时考虑所有单词的arc,则arc分类器的等价形式为
若序列长度为d(包含root节点后的长度),则 ,可用于可变类别分类。
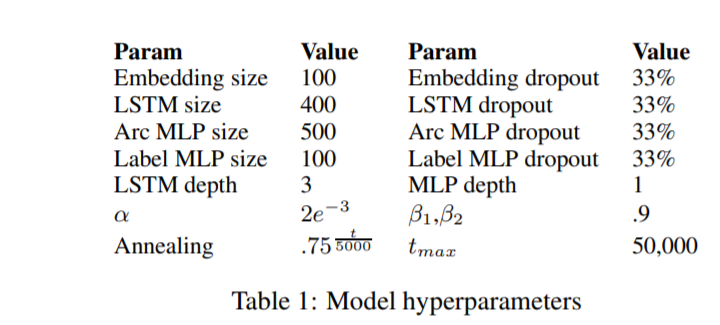
模型超参数