机器学习概述
人工智能、机器学习、深度学习之间的关系

机器学习框架
Pytorch
Caffe2
theano
Chainer
Scikit-learn
语言支持

机器学习书籍
《面向机器智能 TensorFlow实践》
《MACHINE LEARNING 机器学习》,周志华
《TensorFlow技术解析与实践》
什么是机器学习
机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测。
应用案例
案例1

案例2

为什么需要机器学习

机器学习应用场景
1、自然语言处理
2、无人驾驶
3、计算机视觉
4、推荐系统
数据来源与类型
1、数据来源
- 企业日益积累的大量数据(互联网公司更为显著)
- 政府掌握的各种数据
- 科研机构的实验数据
2、数据类型
- 离散型数据:由记录不同类别个体的数目所得到的数据,又称计数数据,所有这些数据全部都是整数,而且不能再也不能进一步提高他们的精确度。
- 连续型数据:变量可以在某个范围内取任一数,即变量的取值可以是连续的,如,长度、时间、质量值等,这类整数通常是非整数,含有小数部分。
注:只要记住一点,离散型是区间内不可分,连续型是区间内可分
数据类型的不用应用
数据的类型将是机器学习模型不同问题不同处理的依据?
3、可用的数据集

常用数据集数据的结构组成
结构:特征值 + 目标值
例如:
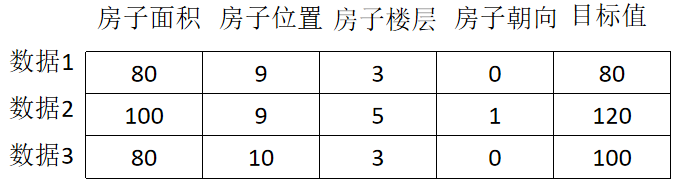
注:有些数据集可以没有目标值
数据的特征工程
1、特征工程是什么
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性
案例:
将下面的文本转换为数字类型的过程。

再如,将一个numpy的数组按照一定规则转成另外一个

2、特征工程的意义
直接影响模型的预测结果
3、scikit-learn库介绍
- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现。
- Scikit-learn文档完善,容易上手,丰富的API,使其在学术界颇受欢迎。
安装参考:https://blog.csdn.net/tototuzuoquan/article/details/105290465
4、数据的特征抽取
阅读:https://blog.csdn.net/tototuzuoquan/article/details/105424709
5、数值的特征处理
阅读:https://blog.csdn.net/tototuzuoquan/article/details/105440244
6、机器学习模型是什么
定义:通过一种映射关系将输入值到输出值

7、机器学习算法分类
机器学习开发流程

监督学习
1、分类 : k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
2、回归:线性回归、岭回归
3、标注:隐马尔可夫模型(不做要求)
无监督学习
1、聚类:k-means

8、监督学习
监督学习 (英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是由
输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)。
无监督学习(英语:Supervised learning),可以由输入数据中学到或建立一个模型,并依此模式推测新的结果。输入数据是
由输入特征值所组成。
分类问题
概念:分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成为分类问题。最基础的便是二分类问题,即判断是非,从两个类别中选择一个作为预测结果;

分类问题的应用
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用:
1、在银行业务中,构建一个客户分类模型,按客户按照贷款风险的大小进行分类
2、 图像处理中,分类可以用来检测图像中是否有人脸出现,动物类别等
3、手写识别中,分类可以用于识别手写的数字
4、文本分类,这里的文本可以是新闻报道、网页、电子邮件、学术论文
…
回归问题:
概念:回归是监督学习的另一个重要问题。回归用于预测输入变量和输出变量之间的关系,输出是连续型的值。

回归在多领域也有广泛的应用
1、房价预测,根据某地历史房价数据,进行一个预测
2、金融信息,每日股票走向
…