来源:
声明:如果我侵犯了任何人的权利,请联系我,我会删除
欢迎高手来喷我
文章目录
MySQL中distinct的使用方法
测试表:
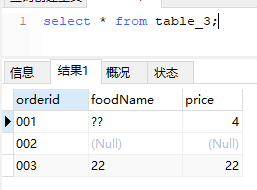
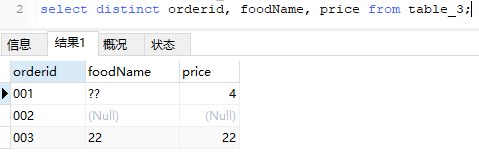
- 对多列进行操作
select distinct orderid, foodName, price from table_3;
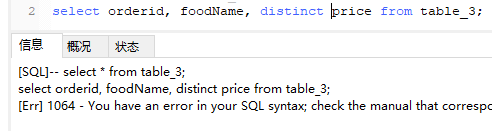
当distinct应用到多个字段的时候,其应用的范围是其后面的所有字段,而不只是紧挨着它的一个字段,而且distinct只能放到所有字段的前面,如下语句是错误的:
select orderid, foodName, distinct price from table_3;
- distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的。
619. 只出现一次的最大数字
题目描述
链接:https://leetcode-cn.com/problems/biggest-single-number
表 my_numbers 的 num 字段包含很多数字,其中包括很多重复的数字。
你能写一个 SQL 查询语句,找到只出现过一次的数字中,最大的一个数字吗?
±–+
|num|
±–+
| 8 |
| 8 |
| 3 |
| 3 |
| 1 |
| 4 |
| 5 |
| 6 |
对于上面给出的样例数据,你的查询语句应该返回如下结果:
±–+
|num|
±–+
| 6 |
注意:
如果没有只出现一次的数字,输出 null 。
题解
# Write your MySQL query statement below
select max(num) as num from
(
select num from my_numbers group by num having count(num)=1
)as template_table
select
ifnull(
(
select num from
(
select num from my_numbers group by num having count(*)=1 order by num desc
)as template_table
limit 1)
,null) as num;
1076. 项目员工II
链接:https://leetcode-cn.com/problems/project-employees-ii
题目描述
Table: Project
±------------±--------+
| Column Name | Type |
±------------±--------+
| project_id | int |
| employee_id | int |
±------------±--------+
主键为 (project_id, employee_id)。
employee_id 是员工表 Employee 表的外键。
Table: Employee
±-----------------±--------+
| Column Name | Type |
±-----------------±--------+
| employee_id | int |
| name | varchar |
| experience_years | int |
±-----------------±--------+
主键是 employee_id。
编写一个SQL查询,报告所有雇员最多的项目。
查询结果格式如下所示:
Project table:
±------------±------------+
| project_id | employee_id |
±------------±------------+
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
| 2 | 4 |
±------------±------------+
Employee table:
±------------±-------±-----------------+
| employee_id | name | experience_years |
±------------±-------±-----------------+
| 1 | Khaled | 3 |
| 2 | Ali | 2 |
| 3 | John | 1 |
| 4 | Doe | 2 |
±------------±-------±-----------------+
Result table:
±------------+
| project_id |
±------------+
| 1 |
±------------+
第一个项目有3名员工,第二个项目有2名员工。
题解
# Write your MySQL query statement below
select project_id
from Project
group by project_id
having count(distinct employee_id) >= all
(
select count(distinct employee_id) from Project group by project_id
)
SELECT PROJECT_ID
FROM PROJECT
GROUP BY 1
HAVING COUNT(*) >= ALL (SELECT COUNT(*)
FROM PROJECT
GROUP BY PROJECT_ID);
178. 分数排名
链接:https://leetcode-cn.com/problems/rank-scores
题目描述
编写一个 SQL 查询来实现分数排名。
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
±—±------+
| Id | Score |
±—±------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
±—±------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
±------±-----+
| Score | Rank |
±------±-----+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
±------±-----+
重要提示:对于 MySQL 解决方案,如果要转义用作列名的保留字,可以在关键字之前和之后使用撇号。例如 Rank
题解
SELECT SCORE, DENSE_RANK() OVER(ORDER BY SCORE DESC) AS 'RANK'
FROM SCORES;
select a.Score as Score,
(select count(distinct b.Score) from Scores b where b.Score >= a.Score) as "Rank"
from Scores a order by a.Score desc
mysql中没有rank函数!!!!
参考http://fellowtuts.com/mysql/query-to-obtain-rank-function-in-mysql/如何在mysql中实现rank函数