pytorch中自带的数据集由两个上层api提供,分别是torchvision和torchtext
其中:
torchvision提供了对图片数据处理相关的api和数据- 数据位置:
torchvision.datasets,例如:torchvision.datasets.MNIST(手写数字图片数据)
- 数据位置:
torchtext提供了对文本数据处理相关的API和数据- 数据位置:
torchtext.datasets,例如:torchtext.datasets.IMDB(电影评论文本数据)
- 数据位置:
下面我们以Mnist手写数字为例,来看看pytorch如何加载其中自带的数据集
使用方法和之前一样:
- 准备好Dataset实例
- 把dataset交给dataloder 打乱顺序,组成batch
4.1 torchversion.datasets
torchversoin.datasets中的数据集类(比如torchvision.datasets.MNIST),都是继承自Dataset
意味着:直接对torchvision.datasets.MNIST进行实例化就可以得到Dataset的实例
但是MNIST API中的参数需要注意一下:
torchvision.datasets.MNIST(root='/files/', train=True, download=True, transform=)
root参数表示数据存放的位置train:bool类型,表示是使用训练集的数据还是测试集的数据download:bool类型,表示是否需要下载数据到root目录transform:实现的对图片的处理函数
4.2 MNIST数据集的介绍
数据集的原始地址:http://yann.lecun.com/exdb/mnist/
MNIST是由Yann LeCun等人提供的免费的图像识别的数据集,其中包括60000个训练样本和10000个测试样本,其中图拍了的尺寸已经进行的标准化的处理,都是黑白的图像,大小为28X28
执行代码,下载数据,观察数据类型:
import torchvision
dataset = torchvision.datasets.MNIST(root="./data",train=True,download=True,transform=None)
print(dataset[0])
下载的数据如下:

代码输出结果如下:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Processing...
Done!
(<PIL.Image.Image image mode=L size=28x28 at 0x18D303B9C18>, tensor(5))
可以其中数据集返回了两条数据,可以猜测为图片的数据和目标值
返回值的第0个为Image类型,可以调用show() 方法打开,发现为手写数字5
import torchvision
dataset = torchvision.datasets.MNIST(root="./data",train=True,download=True,transform=None)
print(dataset[0])
img = dataset[0][0]
img.show() #打开图片
图片如下:
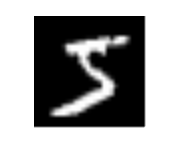
由上可知:返回值为(图片,目标值),这个结果也可以通过观察源码得到