上一篇:【深入理解JVM】5、运行时数据区(Run-time data areas)+常用指令【面试必备】

1、GC的基本知识
1、JAVA和C++ GC的区别
1、java
-
GC处理垃圾
-
开发效率高,执行效率低
2、C++
-
手工处理垃圾
-
忘记回收垃圾
-
内存泄漏
-
-
回收多次
-
非法访问
-
-
开发效率低,执行效率高
2、如何定位垃圾。
1、RC:reference count 引用计数
- 算法原理:给对象添加一个引用计数器,每当一个地方引用它时,计数器值就加1;每当一个引用时效时,计数器值就减1;当引用计数为0时,表示该对象不再使用,可以回收。
- 应用:微软COM/ActionScript3/Python
- 优势:实现简单,判定效率高,通常情况下是个不错的算法。
- 不足:很难解决循环引用的问题。循环体为垃圾是但是他们的引用都不为0
2、RS:Root Searching 根可达算法
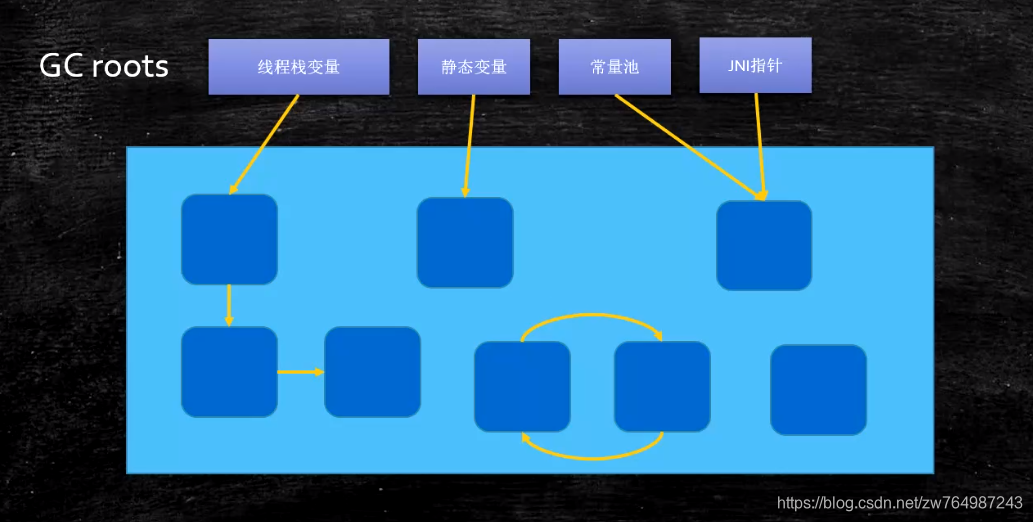
- 算法原理:以称作“GC Roots”的对象作为起点向下搜索,搜索所走过的路径成为引用链,当一个对象到GC Roots不可达时,表示该对象不再使用,可以回收。
- 应用:Java/C#/Lisp
- 优势:可以解决循环引用的问题
- 不足:算法略复杂
- 根对象:GC roots(记住很重要)
- 线程栈变量
- 静态变量
- 常量池
- JNI指针:调用的C/C++引用的对象
3、清除垃圾的算法 GC Algorithms
-
Mark-Sweep(标记清除)
-
Copying(拷贝)
-
Mark-Compact(标记压缩)
1、Mark-Sweep(标记清除)


-
先找到有用,再找到没有用的,然后标记,再清除
-
特点:
-
1、算法相对简单,存活对象比较多的情况下效率较高。
-
2、需要两遍扫描(第一遍找到那些有用的对象,第二遍找到没有用的对象并清除),所以效率比较低,容易产生碎片(清掉的也不压缩也不清理,所以会有很多空的)
-
2、Copying(拷贝)


-
把内存一分为2,把有用的拷贝到一半的内存,都拷贝完了之后,另一半的没有用的对象全部清除。
-
找到一些有用的,然后将有用的复制拷贝到的别的地方去,然后拷贝完了再将这块没有用的对象全部删掉
-
特点:
-
1、适用于存活对象较少的情况,只扫描一次,效率提高,没有碎片
-
2、空间浪费,移动复制对象,需要调整对象的引用。
-
3、Mark-Compact(标记压缩)


-
先找到有用的对象然后移到前面去,让有用的对象全部到一个角落去,剩下的就是没有用的对象,全部清除
-
特点:
-
1、扫描两次,需要移动对象,效率偏低。
-
2、不会产生碎片,方便对象分配,不会产生内存减半。
-
4.JVM内存分代模型(用于分代垃圾回收算法)

一个对象先栈上,装不下再往Eden区,垃圾回收一次进入survivor1区(幸存区域或者叫from)再回收一次进入survivor2区,经过多次垃圾回收之后进入Old区。
注释:GC:
- MinorGC/YGC:年轻代空间耗尽时触发
- MajorGC/FullGC:在老年代无法继续分配空间时触发,新生代,老年代同事进行回收
- -Xmn: -X:非标参数。 m:Memory n:new
- -Xms:s:最小值
- -Xmx:x:最大值

-
部分垃圾回收器使用的模型
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型
G1是逻辑分代,物理不分代
除此之外不仅逻辑分代,而且物理分代
-
堆内空间(新生代 + 老年代) + 永久代(1.7)Perm Generation/ 元数据区(1.8) Metaspace
- 永久代 元数据 保存:- Class,方法编译完的信息,代码编译完的信息以及字节码等。
- 永久代必须指定大小限制(很容易溢出,这个还改不了) ,元数据可以设置,也可以不设置,无上限(受限于物理内存)
- 字符串常量 1.7 - 永久代,-->1.8 - 堆
- MethodArea(具体实现1.7 Perm Generation/ 元数据区(1.8) Metaspace)逻辑概念 - 永久代、元数据
-
新生代 = Eden + 2个suvivor区
- YGC回收之后,大多数的对象会被回收,活着的进入s0
- 再次YGC,活着的对象eden + s0 -> s1
- 再次YGC,eden + s1 -> s0
- 年龄足够 -> 老年代 (15 CMS 6)
- s区装不下 -> 老年代
-
老年代
- 顽固分子
- 老年代满了FGC Full GC
-
GC Tuning (Generation)
- 尽量减少FGC
- MinorGC = YGC
- MajorGC = FGC
-
动态年龄:(不重要) https://www.jianshu.com/p/989d3b06a49d
-
分配担保:(不重要) YGC期间(young gc) survivor区空间不够了 空间担保直接进入老年代 参考:https://cloud.tencent.com/developer/article/1082730
-
对象分配过程图:垃圾回收执行顺序:TLAB:线程本地分配。
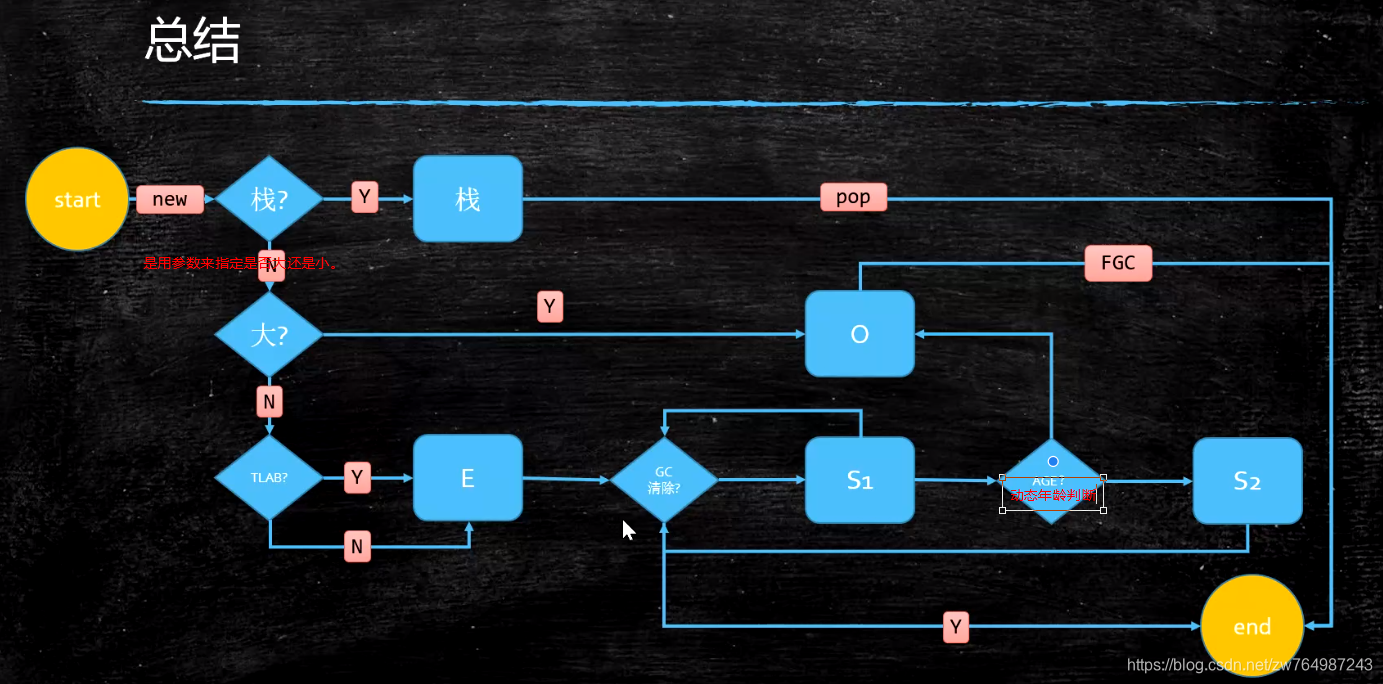
了解即可:

代码验证效率:
/**
* 减号代表去掉属性
* -XX:-DoEscapeAnalysis 去掉逃逸分析
* -XX:-EliminateAllocations 去掉标量替换
* -XX:-UseTLAB 去掉线程本地分配TLAB
* -Xlog:c5_gc*
* 逃逸分析 标量替换 线程专有对象分配
*/
public class TestTLAB {
//User u;
class User {
int id;
String name;
public User(int id, String name) {
this.id = id;
this.name = name;
}
}
void alloc(int i) {
// 无逃逸
new User(i, "name " + i);
}
public static void main(String[] args) {
TestTLAB t = new TestTLAB();
long start = System.currentTimeMillis();
for (int i = 0; i < 1000_0000; i++) t.alloc(i);
long end = System.currentTimeMillis();
System.out.println(end - start);
//for(;;);
}
}正常运行:400

修改参数运行:800

注释:
- Eden区+S1-->S2超过50%就会丢到Old区如上图。
论证:(了解即可参考: https://www.jianshu.com/p/989d3b06a49d)
uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
//survivor_capacity是survivor空间的大小
size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
size_t total = 0;
uint age = 1;
while (age < table_size) {
total += sizes[age];//sizes数组是每个年龄段对象大小
if (total > desired_survivor_size) break;
age++;
}
uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
...
}我把晋升年龄计算的代码摘出。我们来看看动态年龄的计算。代码中有一个TargetSurvivorRatio的值。
-XX:TargetSurvivorRatio
目标存活率,默认为50%
- 通过这个比率来计算一个期望值,desired_survivor_size 。
- 然后用一个total计数器,累加每个年龄段对象大小的总和。
- 当total大于desired_survivor_size 停止。
- 然后用当前age和MaxTenuringThreshold 对比找出最小值作为结果
总体表征就是,年龄从小到大进行累加,当加入某个年龄段后,累加和超过survivor区域*TargetSurvivorRatio的时候,就从这个年龄段网上的年龄的对象进行晋升。
5、常见的垃圾回收器

注释:
- 1-4:在逻辑上都是分代的,
- 5-6:在逻辑上都不分代了。
- 10:debug用的。
- Serial指的是单线程系列,
- Parallel指的是多线程。
- 常见组合:Serial+Serial Old;Parallel Scavenge+Parallel Old(如果现在很多线上没有做调优默认就是这个);ParNew+CMS组合见上面虚线。
-

CMS
- JDK诞生 Serial追随 提高效率,诞生了PS,为了配合CMS,诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病较多,因此目前任何一个JDK版本默认是CMS 并发垃圾回收是因为无法忍受STW
- Serial 年轻代 串行回收 单CPU效率最高,虚拟机是Client模式的默认的垃圾回收器。 safe point(安全点) stop-the-world(STW)(线程停止)在safe point上STW.现在用的极少

Serial - PS(Parallel Scavenge) 年轻代 并行回收 Parallel Scavenge的变种,是为了配合CMS使用

Parallel Scavenge - ParNew 年轻代 配合CMS的并行回收 PN响应时间优先,配合CMS,PS吞吐量优先。

Parallel New - SerialOld

Serial Old - ParallelOld
- ConcurrentMarkSweep 老年代 并发的, 垃圾回收和应用程序同时运行,降低STW的时间(200ms) CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定 CMS既然是MarkSweep,就一定会有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,使用SerialOld 进行老年代回收 想象一下: PS + PO -> 加内存 换垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW) 几十个G的内存,单线程回收 -> G1 + FGC 几十个G -> 上T内存的服务器 ZGC 算法:三色标记 + Incremental Update
- G1(10ms) 算法:三色标记 + SATB
- ZGC (1ms) PK C++ 算法:ColoredPointers + LoadBarrier
- Shenandoah 算法:ColoredPointers + WriteBarrier
- Eplison
- PS 和 PN区别的延伸阅读: ▪https://docs.oracle.com/en/java/javase/13/gctuning/ergonomics.html#GUID-3D0BB91E-9BFF-4EBB-B523-14493A860E73
- 垃圾收集器跟内存大小的关系
- Serial 几十兆
- PS 上百兆 - 几个G
- CMS - 20G
- G1 - 上百G
- ZGC - 4T - 16T(JDK13)
- CMS
- 缺点:
1.8默认的垃圾回收:PS + ParallelOld
常见垃圾回收器组合参数设定:(1.8)
-
-XX:+UseSerialGC = Serial New (DefNew) + Serial Old
- 小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
-
-XX:+UseParNewGC = ParNew + SerialOld
-
-XX:+UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old
-
-XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】
-
-XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
-
-XX:+UseG1GC = G1
-
Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC
- java +XX:+PrintCommandLineFlags -version
- 通过GC的日志来分辨
-
Linux下1.8版本默认的垃圾回收器到底是什么?
- 1.8.0_181 默认(看不出来)Copy MarkCompact
- 1.8.0_222 默认 PS + PO
下一篇:【深入理解JVM】8、JVM实战调优+arthas实战使用+jvisualvm实战使用+GC算法+JVM调优如何定位问题+线上排查+针对小BUG不停止服务修改bug+CMS+G1+常用参数【面试必备】