为什么会有降维和特征选择???
我们知道机器学习的终极目标就是为了预测,当然预测前我们要对数据进行训练。通常我们不会拿原始数据来训练,为什么呢?可能有些人觉得原始信息(original data)包含了样本最丰富的信息,没有经过任何处理的raw data能最完整表达样本,这个观点没有错。但是用raw data来直接训练的话,有一个问题就是我们设计的分类器在训练集上会得到很好的performance,但在测试集上的performance却变得非常差。这就是过拟合(overfitting)的问题。用raw data直接训练还有一个问题就是原始维度太高,耗时长。
概念理解Concept understanding
特征选择feature selection:也被称为variable selection或者attribute selection.
是选取已有属性的子集subset来进行建模的一种方式.进行特征选择的目的主要有: 简化模型,缩短训练时间,避免维数灾难(curse of dimensionality),
增强model的泛化能力.降维dimensionality reduction:
通过对原有的feature进行重新组合,形成新的feature,选取其中的principal components.
常用降维方法有PCA和SVD分解.dimensionality reduction和feature selection差别主要在于:
前者在原有的feature上生成了新的feature, 后者只是选取原有feautre 集合中的子集,而不对原有集合进行修改.
特征选择的方法Feature Selection methods
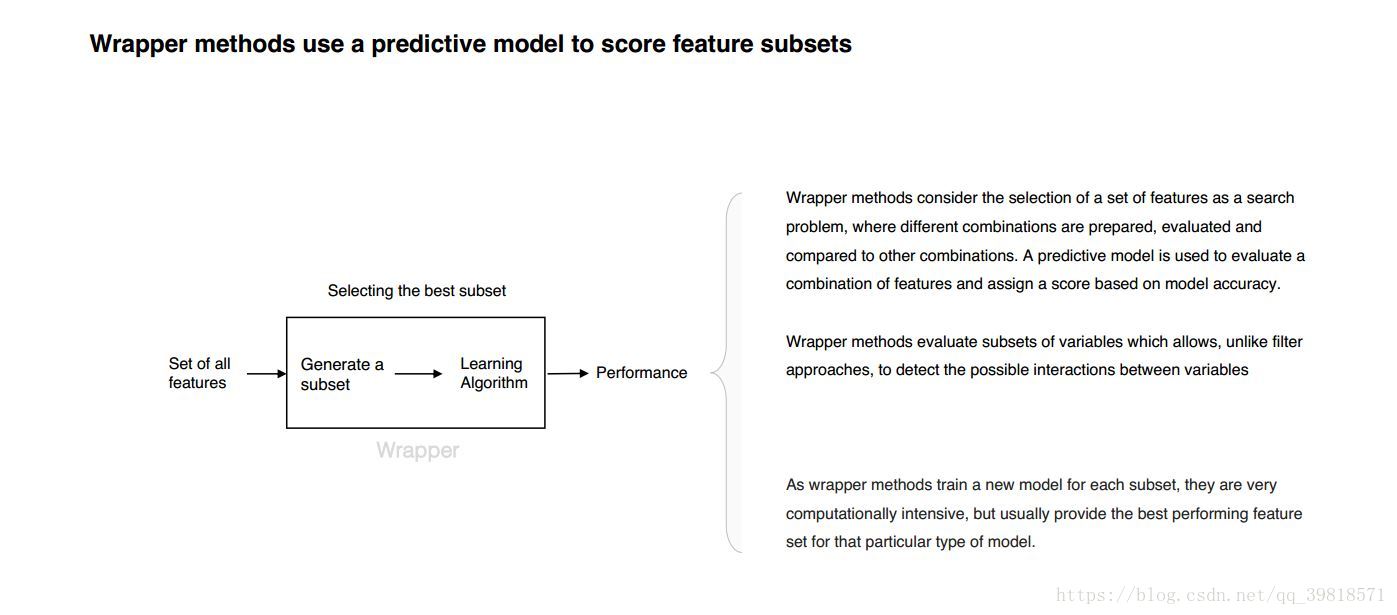
- Feature Selection – Wrapper method
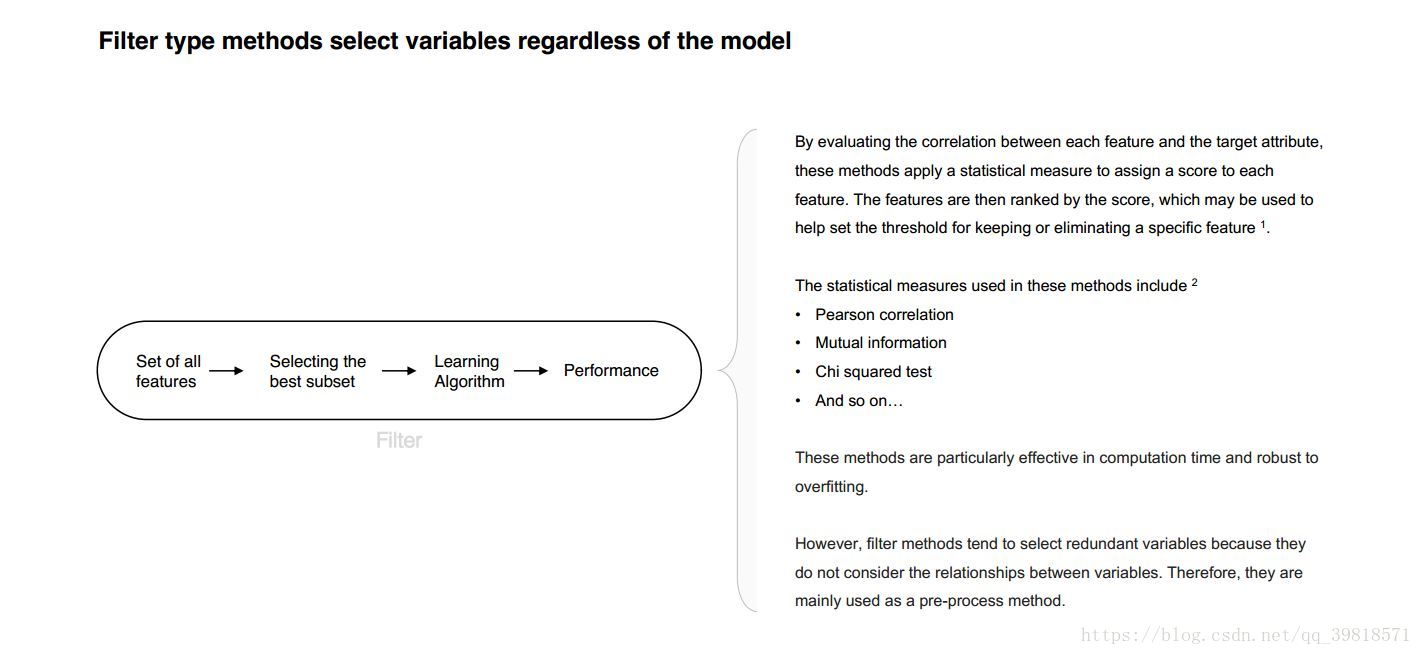
- Feature Selection – Filter method
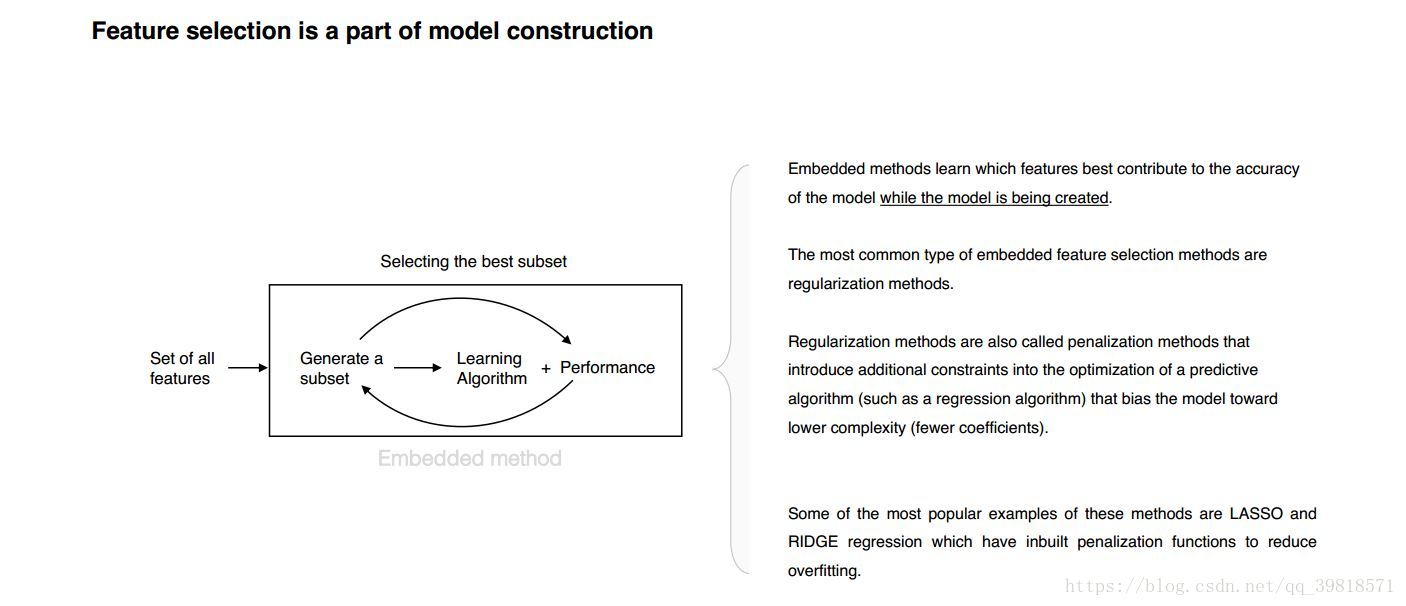
- Approaches for Feature Selection
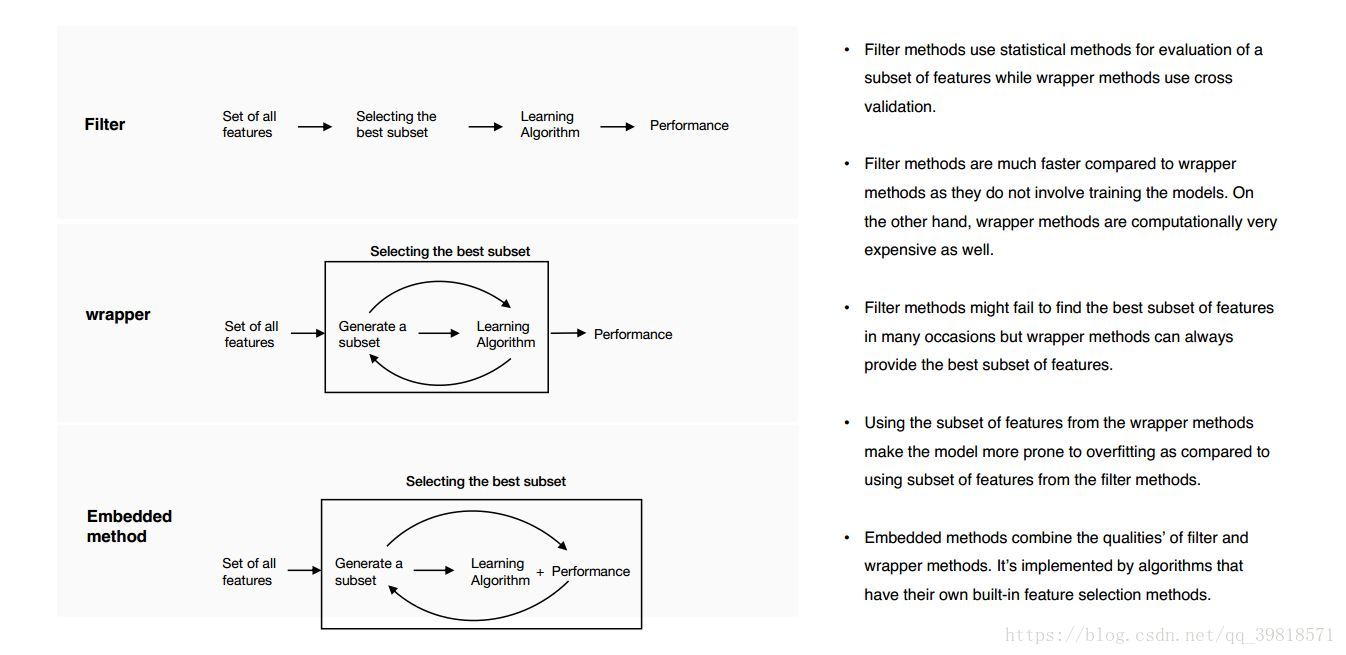
- Summary: the modern approaches for Feature Selection