注意
1.SOA思想(微服务代码编辑的标准)
2.RPC概念(远程调用的规范)
3.微服务思想
nginx主要做反向代理而不是负载均衡
微服务调用原来
Zookeeper 注册中心介绍 下载 安装 集群说明 数据存储结构
4 Dubbo框架介绍
入门案例 面试题 负载均衡
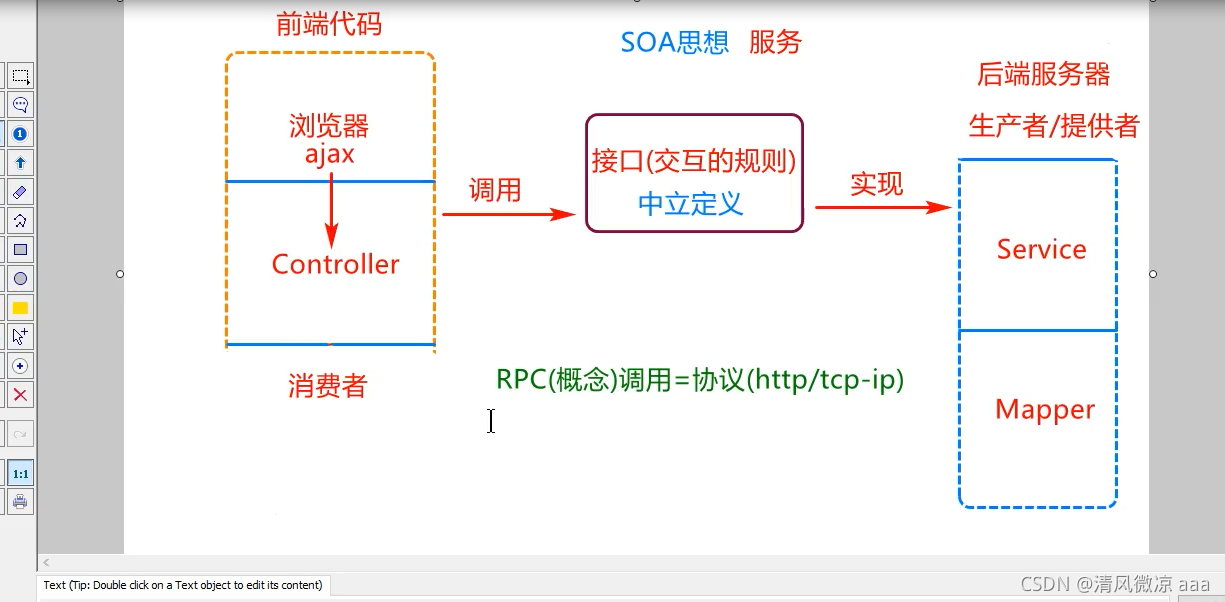
1. SOA思想(微服务代码编辑的标准)
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和协议联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构件在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
概括:SOA思想要求按照业务将服务进行拆分,之后按照统一的中立的接口进行交互.
知识回顾: 面向对象的思想/ 面向接口开发 /面向切面开发 /面向服务开发
注意:这里的接口是一种中立的规则,不单单是public interface.
调用服务的人:消费者。 实现服务的人:生产者/提供者。

2. RPC概念(远程调用的规范)
RPC是远程过程调用(Remote Procedure Call)的缩写形式。SAP系统RPC调用的原理其实很简单,有一些类似于三层构架的C/S系统,第三方的客户程序通过接口调用SAP内部的标准或自定义函数,获得函数返回的数据进行处理后显示或打印。
生活举例:
一个阳光明媚的早晨,老婆又在翻看我订阅的技术杂志。
“老公,什么是RPC呀,为什么你们程序员那么多黑话!”,老婆还是一如既往的好奇。
“RPC,就是Remote Procedure Call的简称呀,翻译成中文就是远程过程调用嘛”,我一边看着书,一边漫不经心的回答着。
“啥?你在说啥?谁不知道翻译成中文是什么意思?你个废柴,快给我滚去洗碗!”
“我去。。。”,我如梦初醒,我对面坐着的可不是一个程序员,为了不去洗碗,我瞬间调动起全部脑细胞,星辰大海在我脑中汇聚,灵感涌现……
“是这样,远程过程调用,自然是相对于本地过程调用来说的嘛。”
“嗯哼,那先给老娘讲讲,本地过程调用是啥子?”
“本地过程调用,就好比你现在在家里,你要想洗碗,那你直接把碗放进洗碗机,打开洗碗机开关就可以洗了。这就叫本地过程调用。”
“哎呦,我可不干,那啥是远程过程调用?”
“远程嘛,那就是你现在不在家,跟姐妹们浪去了,突然发现碗还没洗,打了个电话过来,叫我去洗碗,这就是远程过程调用啦”,多么通俗易懂的解释,我真是天才!
“哦!我明白了”,说着,老婆开始收拾包包。
“你这是干啥去哦”
“我?我要出门浪去呀,待会记得接收我的远程调用哦,哦不,咱们要专业点,应该说,待会记得接收我的RPC哦!”
……
总结:
- 当完成业务时自己没有办法直接完成时,需要通过第三方帮助才能完成的业务.
- 使用RPC时"感觉"上就是在调用自己的方法完成业务.
3. 微服务思想
标准:
1.根据业务拆分的思想 进行了分布式的设计(分布式思想:拆)。
2.当服务发生异常时可以自动的实现故障的迁移 无需人为的干预(自动化)。
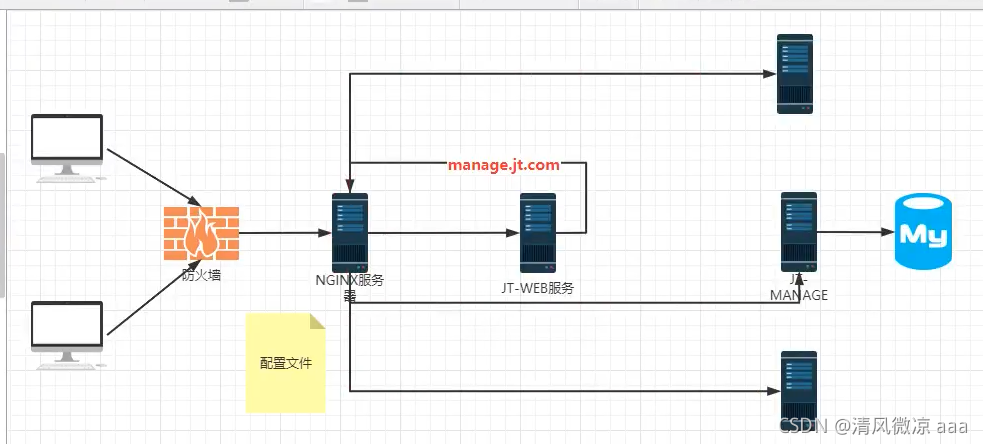
3.1 传统服务调用方式
场景分析:假如到大型活动双11,肯定需要配置多台tomac服务器来进行访问(增加web manage sso等等都要增加),进而通过nginx进行负载均衡(手动修改nginx.conf配置文件)分发请求到不同的服务器。因为nginx需要做反向代理(服务器都需要用域名访问,就要都经过nginx解析),现在又要所有的服务器都需要nginx进行负载均衡的中转,所以会造成nginx访问压力太大很容易出现宕机。
总结:
1.如果采用nginx方式 实现负载均衡,当服务数量改变时,都必须手动的修改nginx.conf配置文件,不够智能。
2.所有的请求都会通过nginx服务器作为中转,如果nginx服务器一旦宕机,则直接影响整个系统,所以nginx最好只做反向代理和简单的负载均衡即可。
3.2 微服务的调用原理介绍
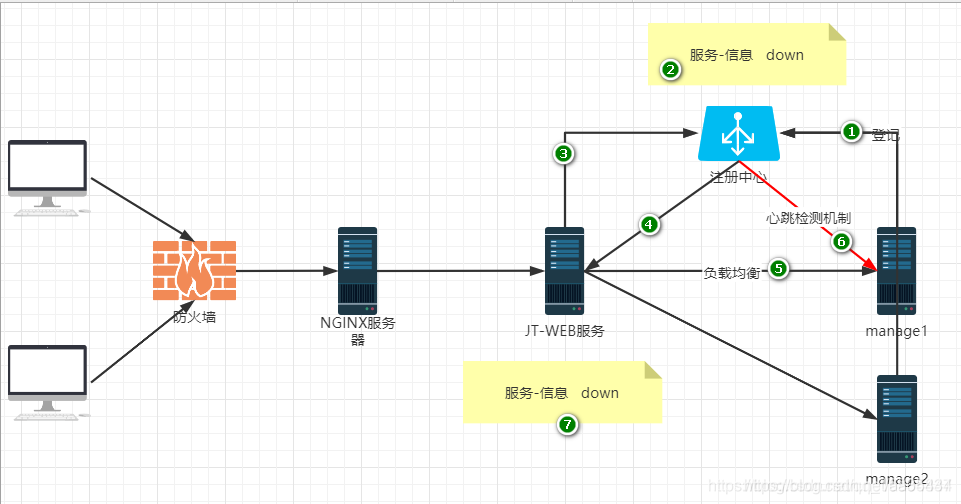
调用步骤:
1.将服务信息写入到注册中心(1.服务名称 2.服务IP地址 3.端口)
2.注册中心接收到服务器信息,会动态的维护服务列表数据.
3.消费者启动时会链接注册中心.目的获取服务列表数据.
4.注册中心会将服务列表数据同步给消费者,并且保存到消费者本地.以后方便调用.
5.当消费者开始业务调用时,会根据已知的服务信息进行负载均衡操作,访问服务提供者.
6.当服务提供者宕机时,由于注册中心有心跳检测机制.所以会动态的维护服务列表.
7.当注册中心的服务列表变化时, 则会全网广播 通知所有的消费者 更新本地服务列表.
注意:Dubble和SpringCloud框架的注册中心的原理是一样的。
3.3 Zookeeper 注册中心介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
概括: ZK主要的任务是服务的调度,提供一致性的功能.
官网:

3.4 Zookeeper下载
Dubbo框架用的注册中心是 Zookeeper. 如果用的是spring cloud 注册中心是Eureka(可能要收费)
下载步骤:


安装包都是.tar.gz说明是LInux版本,所以安装在Linux系统下。
3.5 Zookeeper安装
说明:因为Zookeeper是java语言开发的所以需要安装jdk.
1).上传压缩包到linux工作目录并且检查jdk的环境是否安装。
2).具体步骤查看课前资料文档
因为单台Zookeeper抗压能力差容易宕机,所以安装Zookeeper集群。
3.6 关于Zookeeper集群说明
3.6.1 最小的集群单位几台
公式: 存活节点的数量 > N/2 集群可以创建
1台: 1-1 > 1/2 假的
2台: 2-1> 2/2 假的
3台: 3-1> 3/2 正确
4台: 4-1> 4/2 正确
结论: 搭建集群的最小单位3台.
3.6.2 为什么集群一般都是奇数
3台集群最多宕机几台 集群可以正常工作 最多宕机1台
4台集群最多宕机几台集群可以正常工作 最多宕机1台
说明:如果实现相同的功能 奇数台更优.
3.7 关于zk集群选举规则
原则: myid最大值优先 myid值越大的越容易当主机. 超半数同意即当选主机。
题目: 1,2,3,4,5,6,7依次启动 谁当主机??? 谁永远不能当选主机???
答:4当主机 1 2 3永远不能当主机
原因:
(1).ZK集群有7台所以至少启动4台才能搭建成功(7-3=4>3.5可以搭建,7-4=3<3.5不能搭建),4台集群myid最大的是第4台,所以4位主机。
(2).7台ZK开始出现主机宕机,则myid最大一次当选主机,当掉7则6当选主机,6宕机5当选主机,5宕机4当选主机,4宕机本来应该是3当选主机但是此时只有3台ZK不能维持主节点的数量,集群崩溃所以1 2 3永远不能当选主机。
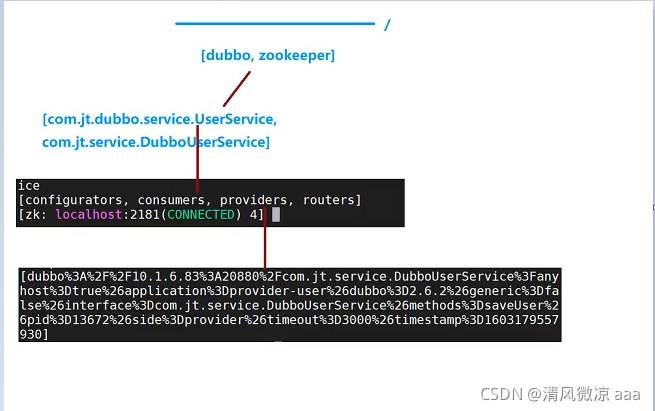
3.8 关于ZK数据存储结构(day18pm 1.41)
说明:在ZK中数据的储存采用树形结构的方式保存
命令:sh zkCli.sh
查询命令:ls/…
4 Dubbo框架介绍
说明:
1).Dubbo框架用的注册中心是Zookeeper,SpringCloud的注册中心用eureka。
2).适合中小型项目。
4.1 官网介绍
阿里巴巴开发的
Apache Dubbo |ˈdʌbəʊ| 是一款高性能、轻量级的开源Java RPC框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
4.2 Dubbo特性

4.3 Dubbo工作原理
类似zookeeper注册中心

4.4 Dubbo入门案例
4.4.1 导入项目
说明:此项目与jt项目平级,将课前资料的dubbo-jt项目复制到idea工作空间,之后在pom文件右键add maven生效即可。

修改springboot版本号:
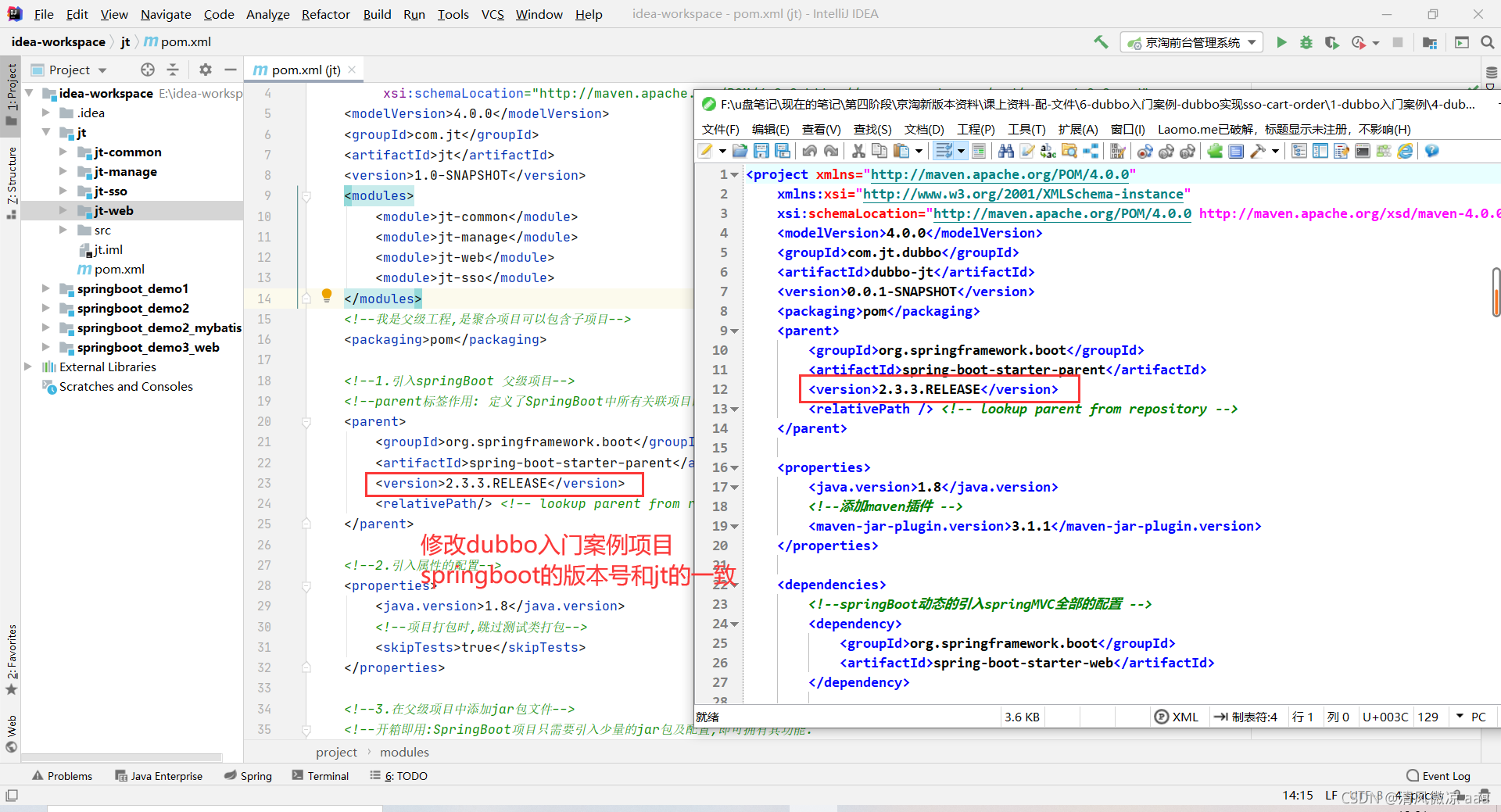
4.4.2 定义公共的第三方接口项目
注意:接口是一种公共的通信规范,不一定是interface。在dubble中接口恰好就是interface ,而在springcloud 接口就不是。
说明:接口项目一般定义公共的部分,并且被第三方依赖。
解释:
1).接口属于中立的第三方公用的。此案例中有一个pojo类:User,一个interface接口:UserService
2).因为User类不止一个项目使用所以放在公共的接口项目,别人想用只需要添加依赖即可。UserService这个中立的接口只做方法的定义不做方法的实现,由提供者实现接口。
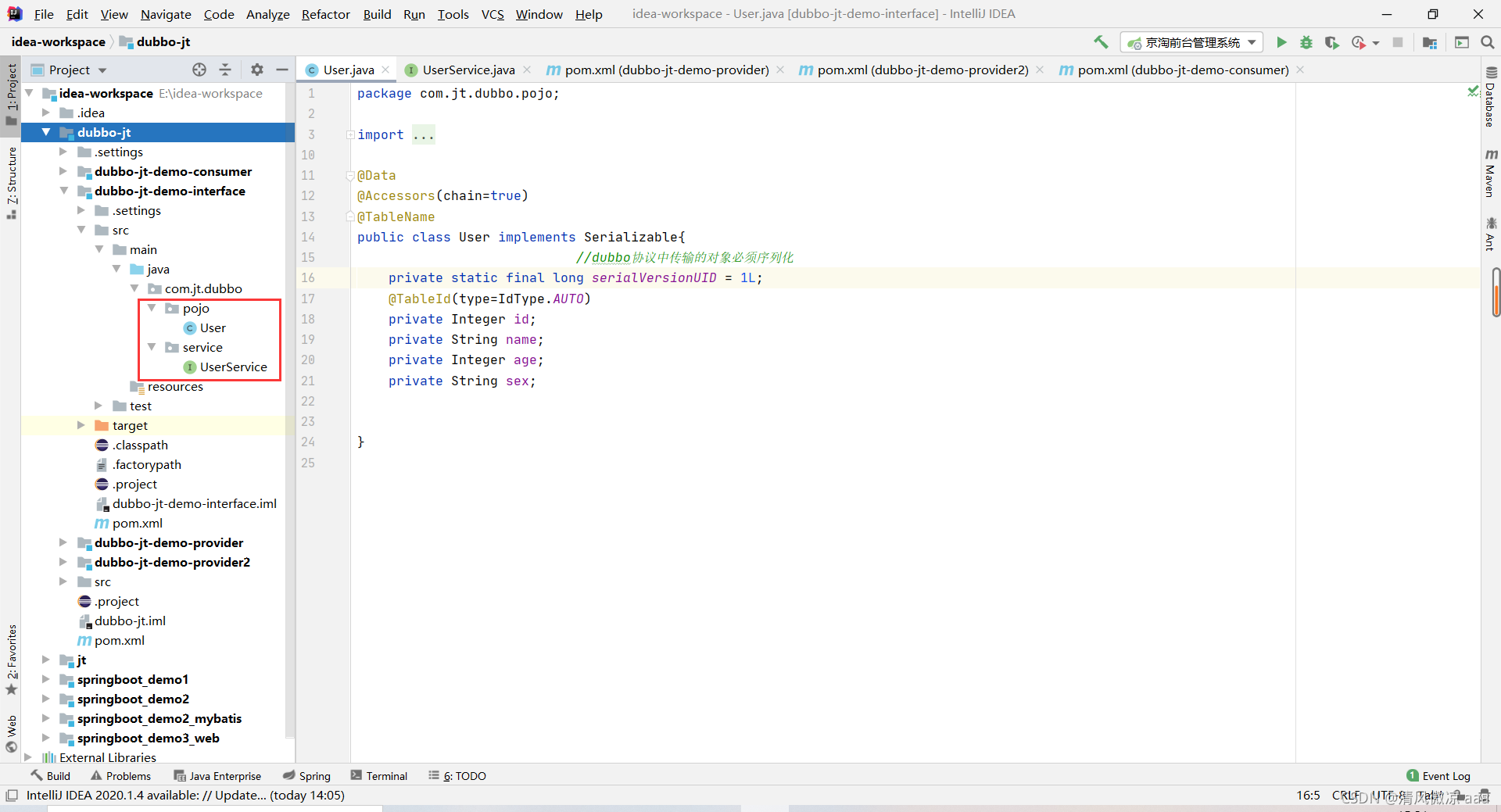
具体代码:
user.
package com.jt.dubbo.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.experimental.Accessors;
import java.io.Serializable;
@Data
@Accessors(chain=true)
@TableName
public class User implements Serializable{
//dubbo协议中传输的对象必须序列化
private static final long serialVersionUID = 1L;
@TableId(type=IdType.AUTO)
private Integer id;
private String name;
private Integer age;
private String sex;
}
UserService.
package com.jt.dubbo.service;
import com.jt.dubbo.pojo.User;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
//service接口只做方法的定义,不做方法的实现,由提供者实现接口。
public interface UserService {
//查询全部的用户信息
List<User> findAll();
//新增用户入库操作.
@Transactional
void saveUser(User user);
}
消费者 提供者都要用这个接口,需要在各自的pom文件中添加依赖。
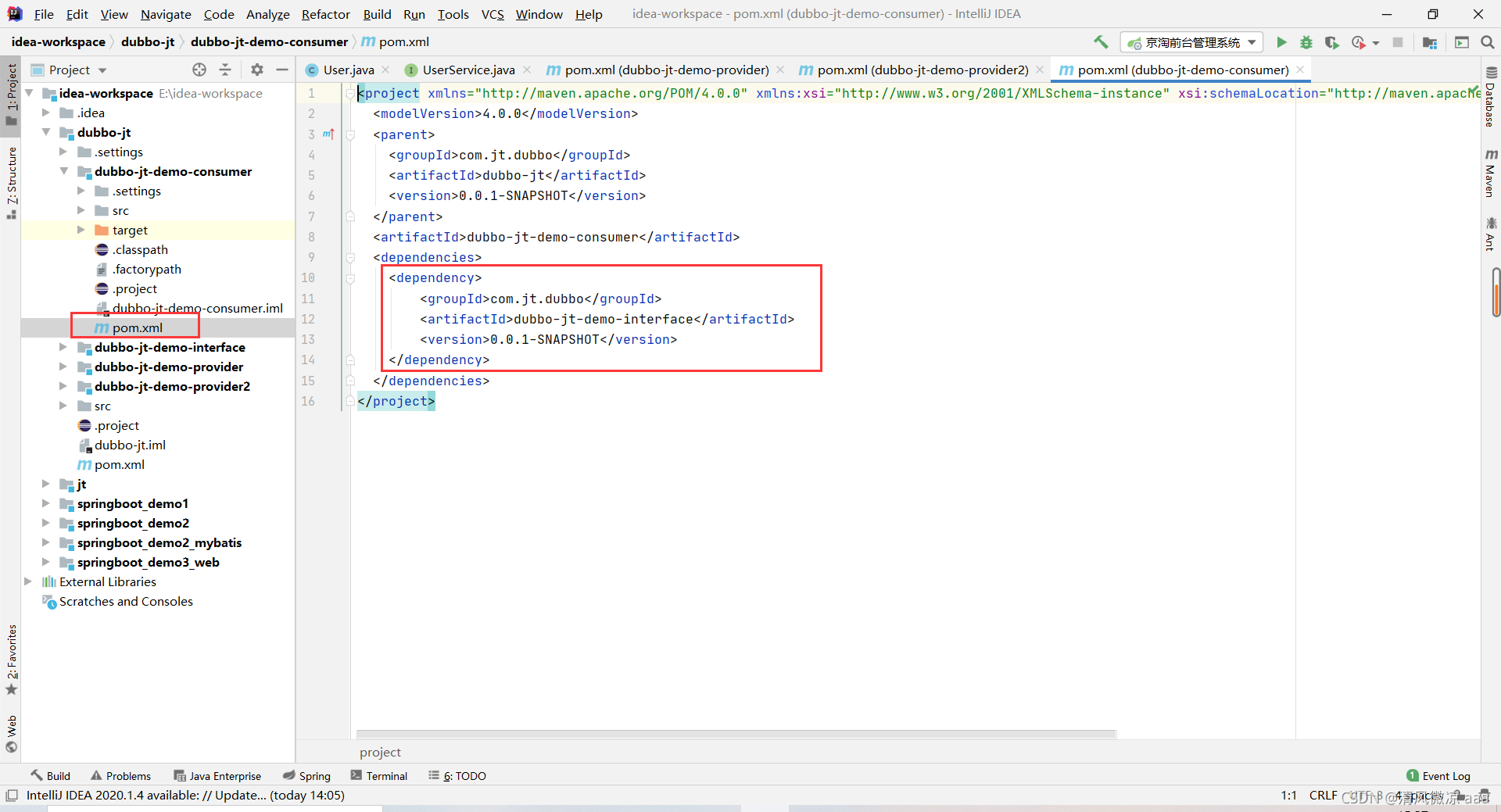
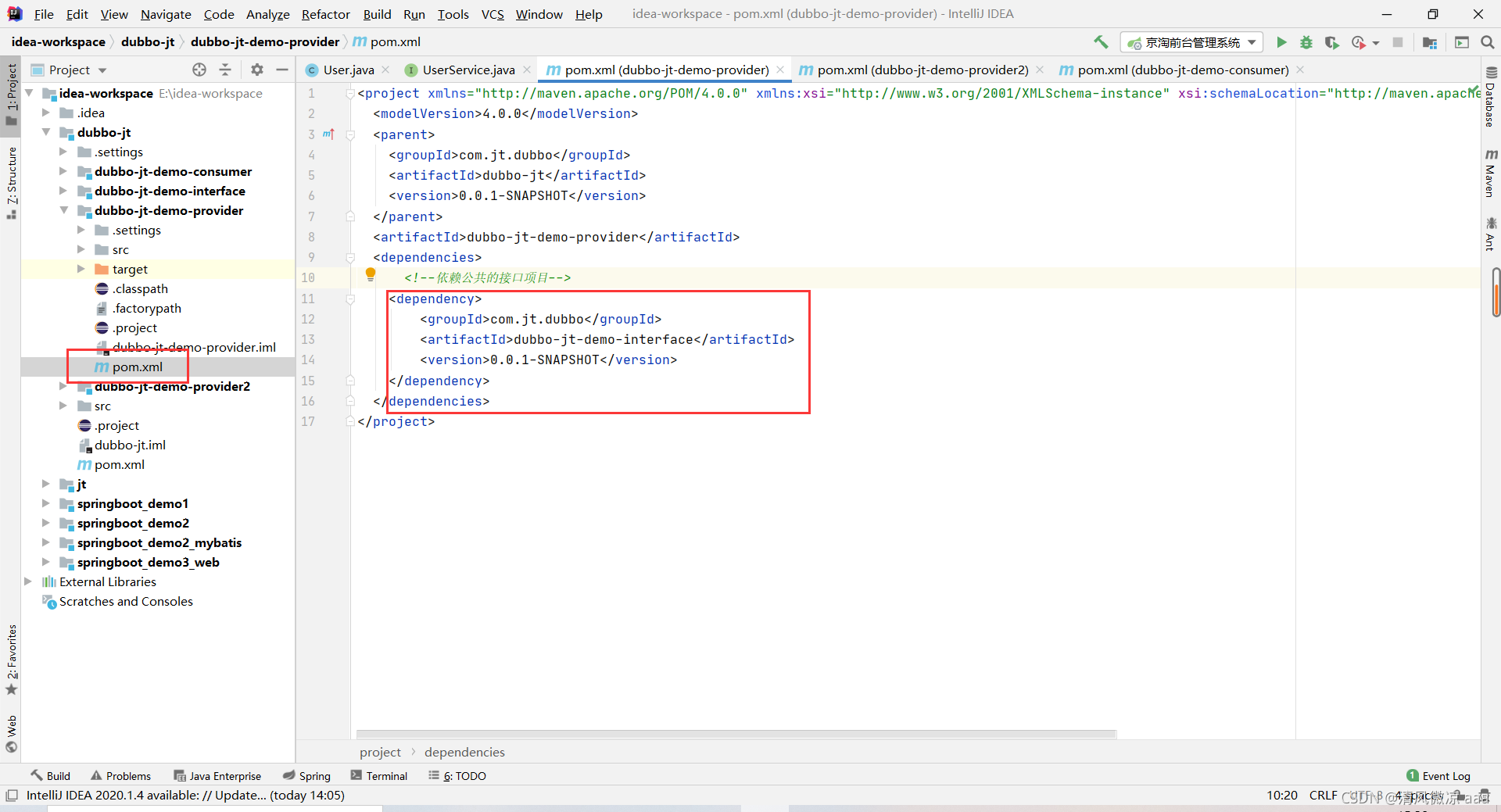
4.4.3 服务提供者1说明(生成者)
4.4.3.1 提供者代码结构
说明:生产者只需要service实现类 mapper
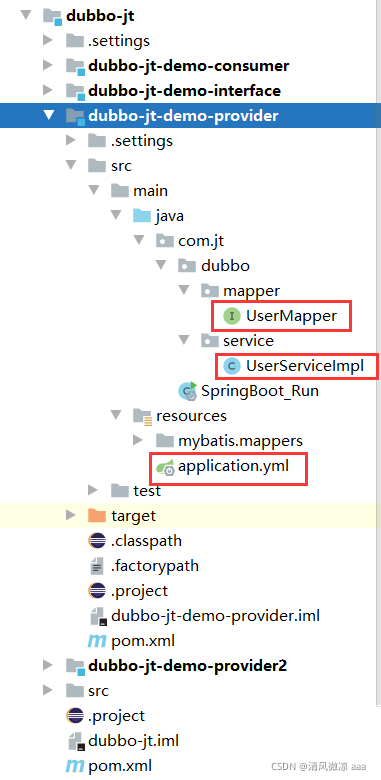
4.4.3.2 编辑主启动类
4.4.3.3 编辑 提供者实现类 mapper接口
具体代码:
UserServiceImpl :注意service注解导包为阿里巴巴家的。
package com.jt.dubbo.service;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import com.alibaba.dubbo.config.annotation.Service;
import com.jt.dubbo.mapper.UserMapper;
import com.jt.dubbo.pojo.User;
@Service(timeout=3000)//消费者调用提供者的超时时间 如果3秒内没有连同则表示超时 内部实现了rpc 注意此注解为阿里巴巴的包
//@org.springframework.stereotype.Service//将对象交给spring容器管理
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public List<User> findAll() {
System.out.println("我是第一个服务的提供者");
return userMapper.selectList(null);
}
@Override
public void saveUser(User user) {
userMapper.insert(user);
}
}
UserMapper .
package com.jt.dubbo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jt.dubbo.pojo.User;
public interface UserMapper extends BaseMapper<User>{
}
4.4.3.4 提供者的YML配置文件说明
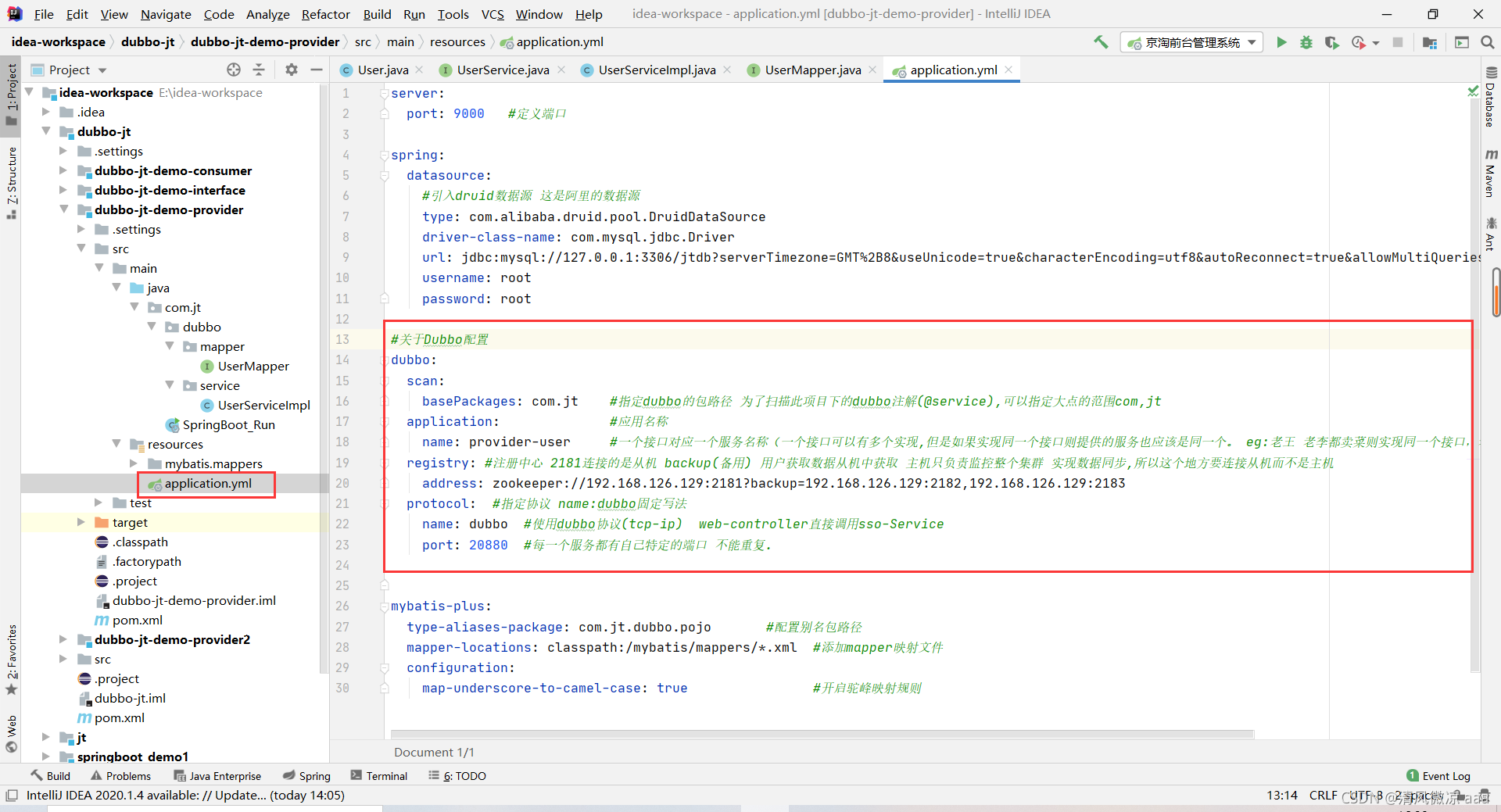
server:
port: 9000 #定义端口
spring:
datasource:
#引入druid数据源 这是阿里的数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/jtdb?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
username: root
password: root
#关于Dubbo配置
dubbo:
scan:
basePackages: com.jt #指定dubbo的包路径 为了扫描此项目下的dubbo注解(@service),可以指定大点的范围com,jt
application: #应用名称
name: provider-user #一个接口对应一个服务名称(一个接口可以有多个实现,但是如果实现同一个接口则提供的服务也应该是同一个。 eg:老王 老李都卖菜则实现同一个接口,老孙卖肉则和老王老李实现不同的借口)
registry: #注册中心 2181连接的是从机 backup(备用) 用户获取数据从机中获取 主机只负责监控整个集群 实现数据同步,所以这个地方要连接从机而不是主机
address: zookeeper://192.168.126.129:2181?backup=192.168.126.129:2182,192.168.126.129:2183
protocol: #指定协议 name:dubbo固定写法
name: dubbo #使用dubbo协议(tcp-ip) web-controller直接调用sso-Service
port: 20880 #每一个服务都有自己特定的端口 不能重复.
mybatis-plus:
type-aliases-package: com.jt.dubbo.pojo #配置别名包路径
mapper-locations: classpath:/mybatis/mappers/*.xml #添加mapper映射文件
configuration:
map-underscore-to-camel-case: true #开启驼峰映射规则
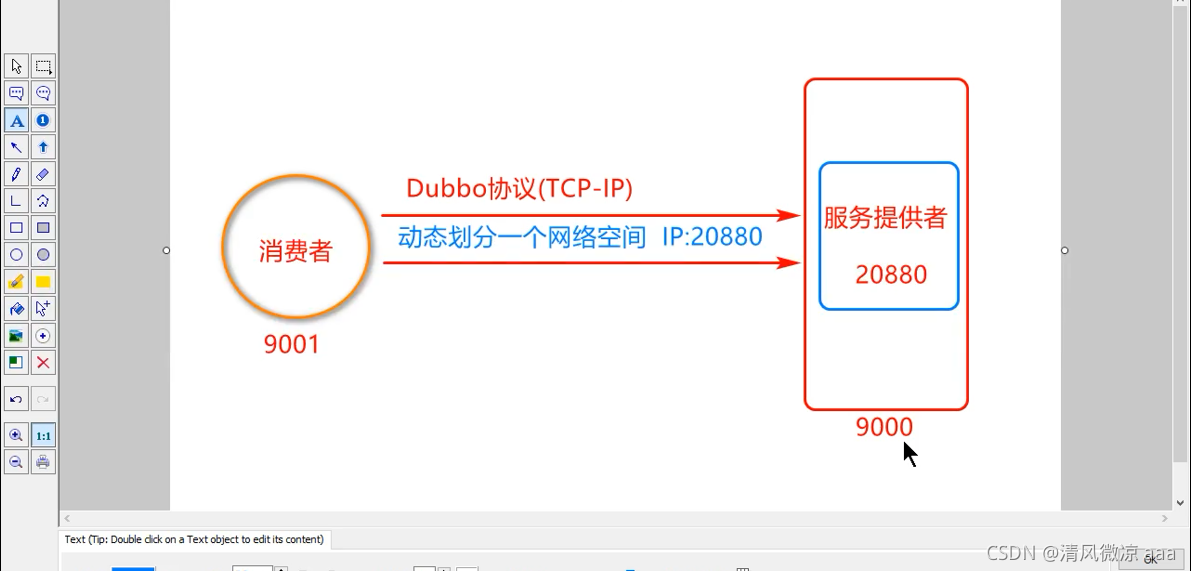
protocol-port=20880端口号说明:
如下图所示,消费者的tomact端口号为9001,生产者的tomact端口号为9000,20880为生产者启动tomact服务器加载Dubbo框架动态生成的一个对外提供服务的端口号。
Dubbo协议只负责消费者和生产者之间的通讯,和浏览器没有关系。
4.4.3.5 启动生产者
4.4.4 服务消费者说明
4.4.4.1 消费者项目结构

4.4.4.2 编辑主启动类
消费者不需要连接数据库.

4.4.4.3 编辑Controller层
注意:
1.远程调用时传递的对象数据必须序列化
2.消费者的对象注入方式应该用dubbo框架提供的注解Reference
package com.jt.dubbo.controller;
import com.alibaba.dubbo.config.annotation.Reference;
import com.jt.dubbo.pojo.User;
import com.jt.dubbo.service.UserService;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class UserController {
//@Reference(loadbalance="leastactive")
@Reference //利用dubbo的方式为接口创建代理对象 利用rpc调用 即dubbo框架通过@Reference注解注入对象
private UserService userService;
/**
* Dubbo框架调用特点:远程RPC调用就像调用自己本地服务一样简单
* @return
*/
@RequestMapping("/findAll")
public List<User> findAll(){
//远程调用时传递的对象数据必须序列化.
return userService.findAll();
}
@RequestMapping("/saveUser/{name}/{age}/{sex}")
public String saveUser(User user) {
userService.saveUser(user);
return "用户入库成功!!!";
}
}

4.4.4.4 编辑消费者的YML配置文件
server:
port: 9001
dubbo:
scan:
basePackages: com.jt #定义扫描注解
application:
name: consumer-user #定义消费者名称
registry: #注册中心地址
address: zookeeper://192.168.126.129:2181?backup=192.168.126.129:2182,192.168.126.129:2183

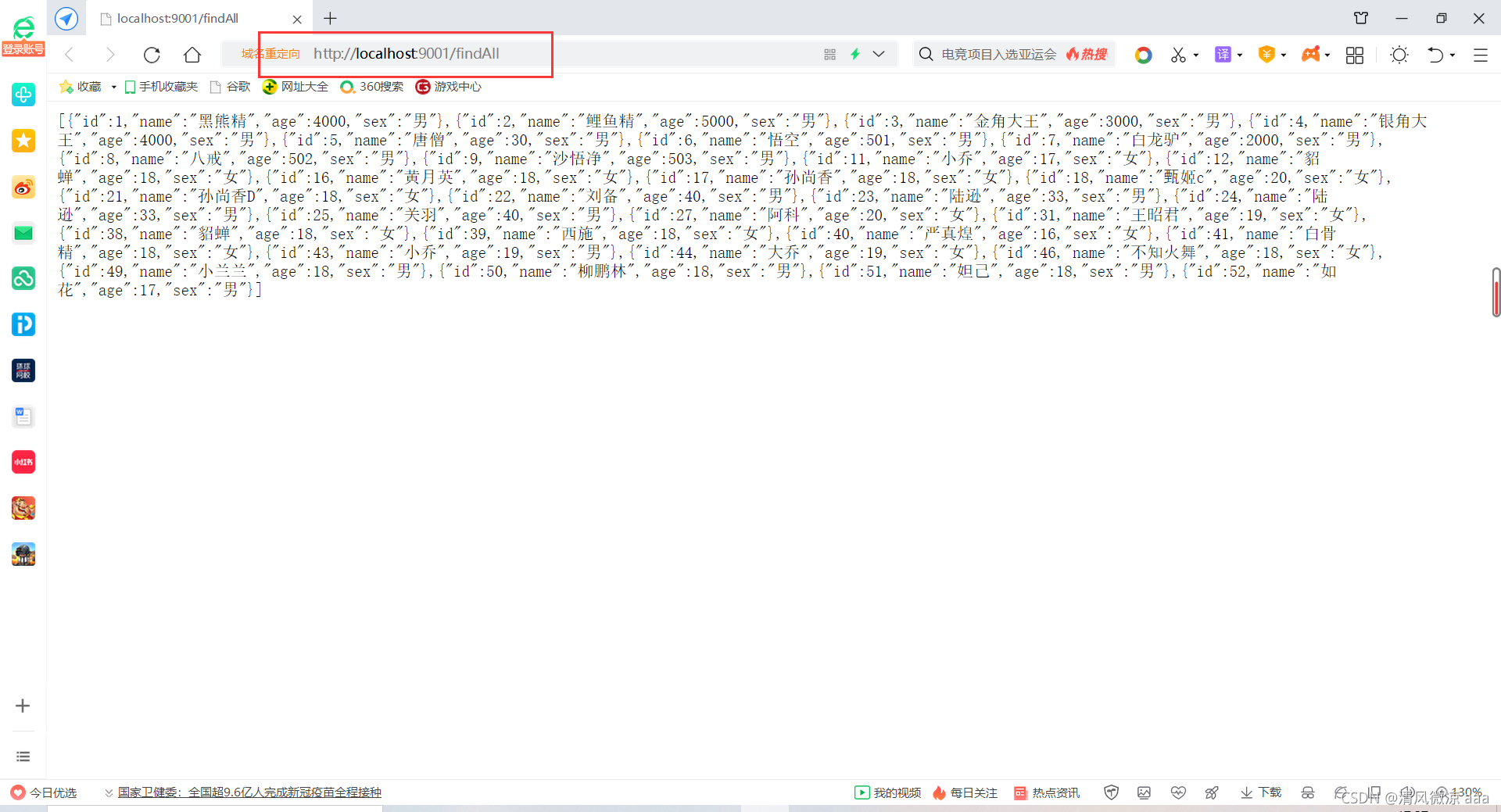
4.4.4.5 启动消费者进行访问测试
说明:先启动生成者1,在启动消费者。
4.4.5 服务提供者2说明
说明:yml文件有些配置不同,service实现类和mapper接口里面的代码相同。
server:
port: 9003
spring:
datasource:
#引入druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/jtdb?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true
username: root
password: root
dubbo:
scan:
basePackages: com.jt
application:
name: provider-user #实现的同一个接口不需要改名
registry:
address: zookeeper://192.168.126.129:2181?backup=192.168.126.129:2182,192.168.126.129:2183
protocol:
name: dubbo
port: 20882 #每个服务都应该有自己独立的端口
mybatis-plus:
type-aliases-package: com.jt.dubbo.pojo #配置别名包路径
mapper-locations: classpath:/mybatis/mappers/*.xml #添加mapper映射文件
configuration:
map-underscore-to-camel-case: true #开启驼峰映射规则

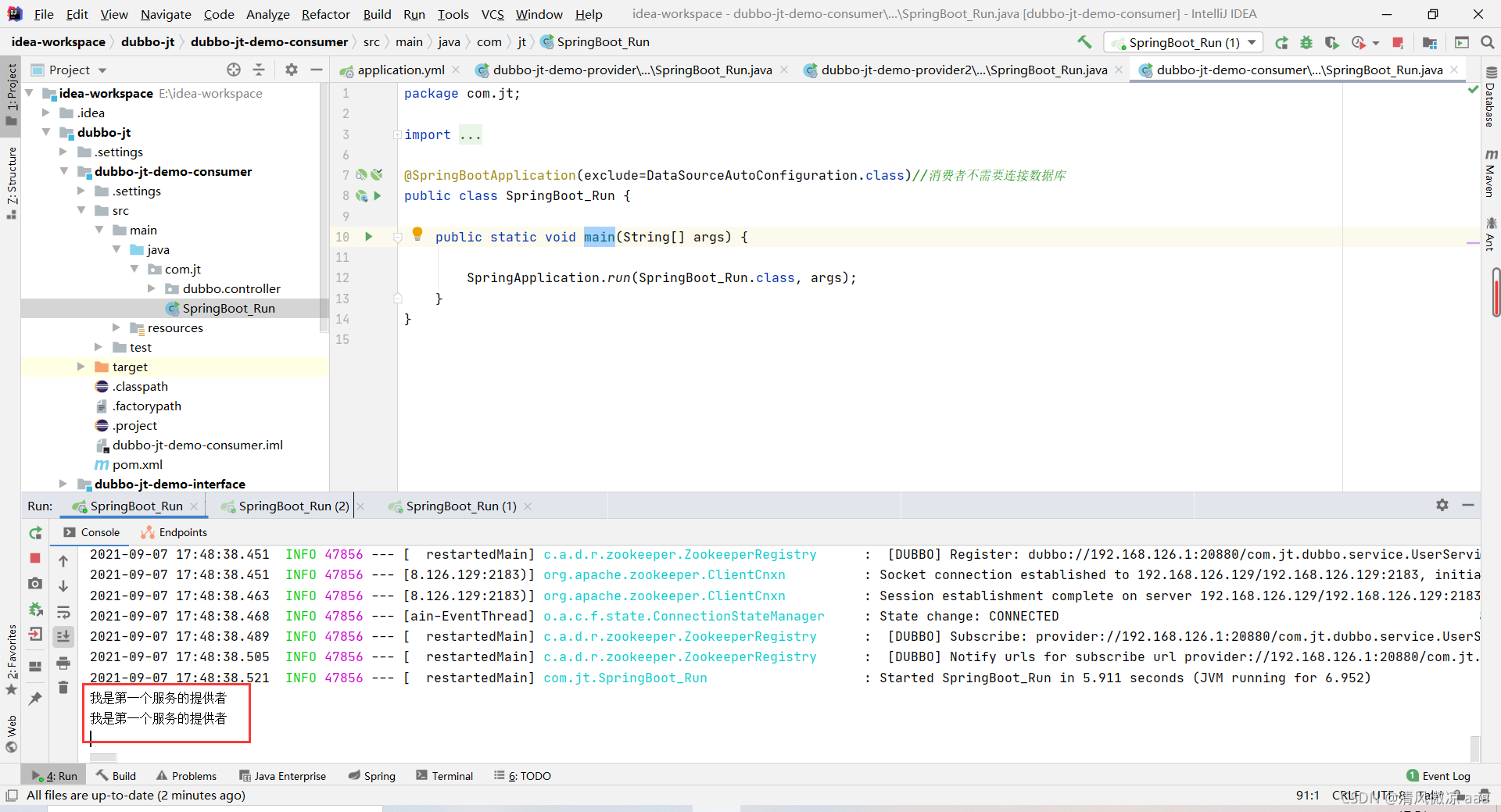
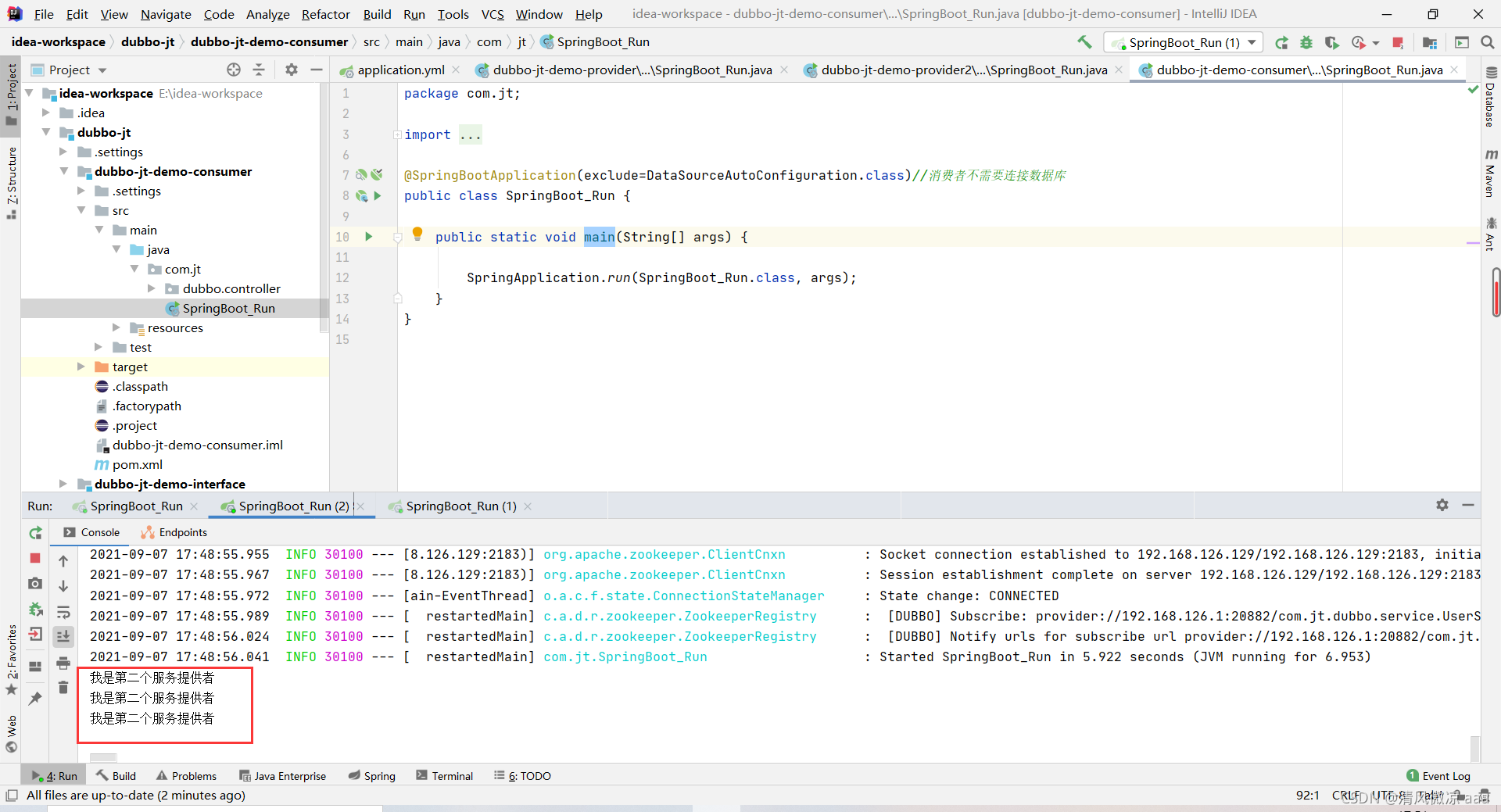
4.4.6 启动生产者1 生成者2 消费者访问测试
说明:先启动2个生产者,在启动消费者。由于生成者代码相同路径也相同,所以都能访问,由下图2个生产者的后台可以看到2个生产者都能进行访问,这是dubbo框架提供的负载均衡。
4.5 关于Dubbo面试题
问题1: 如果其中一个服务器宕机,zk集群正常 用户访问是否受限?
答:不受限,由于zk的帮助,使得程序永远可以访问正确的服务器.并且当服务重启时,duboo有服务的自动发现功能,消费者不需要重启即可以访问新的服务.
问题2: 如果ZK集群短时间宕机,服务器正常 用户访问是否受限?
答: 用户的访问不受影响,由于消费者在本地存储服务列表信息(因为注册中心的信息保存在本地),当访问故障机时,自动的将标识信息改为down属性.
问题3: 如果ZK集群短时间宕机,2台服务器挡掉一台用户访问是否受到影响?
不受影响 如果访问宕掉的一台会在本地信息中更新为down不会再访问这台服务器,2台都挡掉肯定影响。
4.6 关于Dubbo负载均衡的说明
4.6.1 负载均衡种类(从用法上来说)
注意:负载均衡是Dubbo框架提供的而不是Zookeeper,zk只负责一致性服务。
1).客户端的负载均衡:Dubbo/SpringCloud等微服务框架
说明:在微服务调用过程中每个服务的消费者都可以在客户端实现负载均衡的操作,在每次请求之前通过服务列表获取将要访问的服务信息.实现了压力私有化.
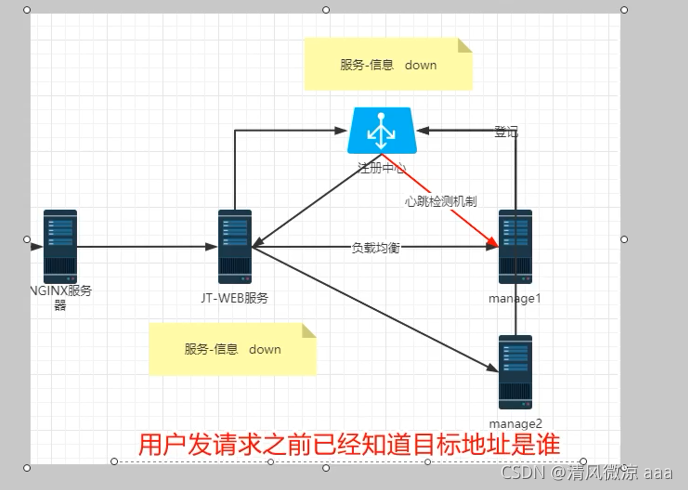
2). 服务端(集中式)的负载均衡:Nginx
说明:由于nginx处于负载均衡的中心,所以什么样的服务都会经过nginx之后转向到不同的服务器中,会造成nginx的负载压力很大.
.

4.6.2 Dubbo负载均衡的方式(4种)
1).默认方式: 随机算法
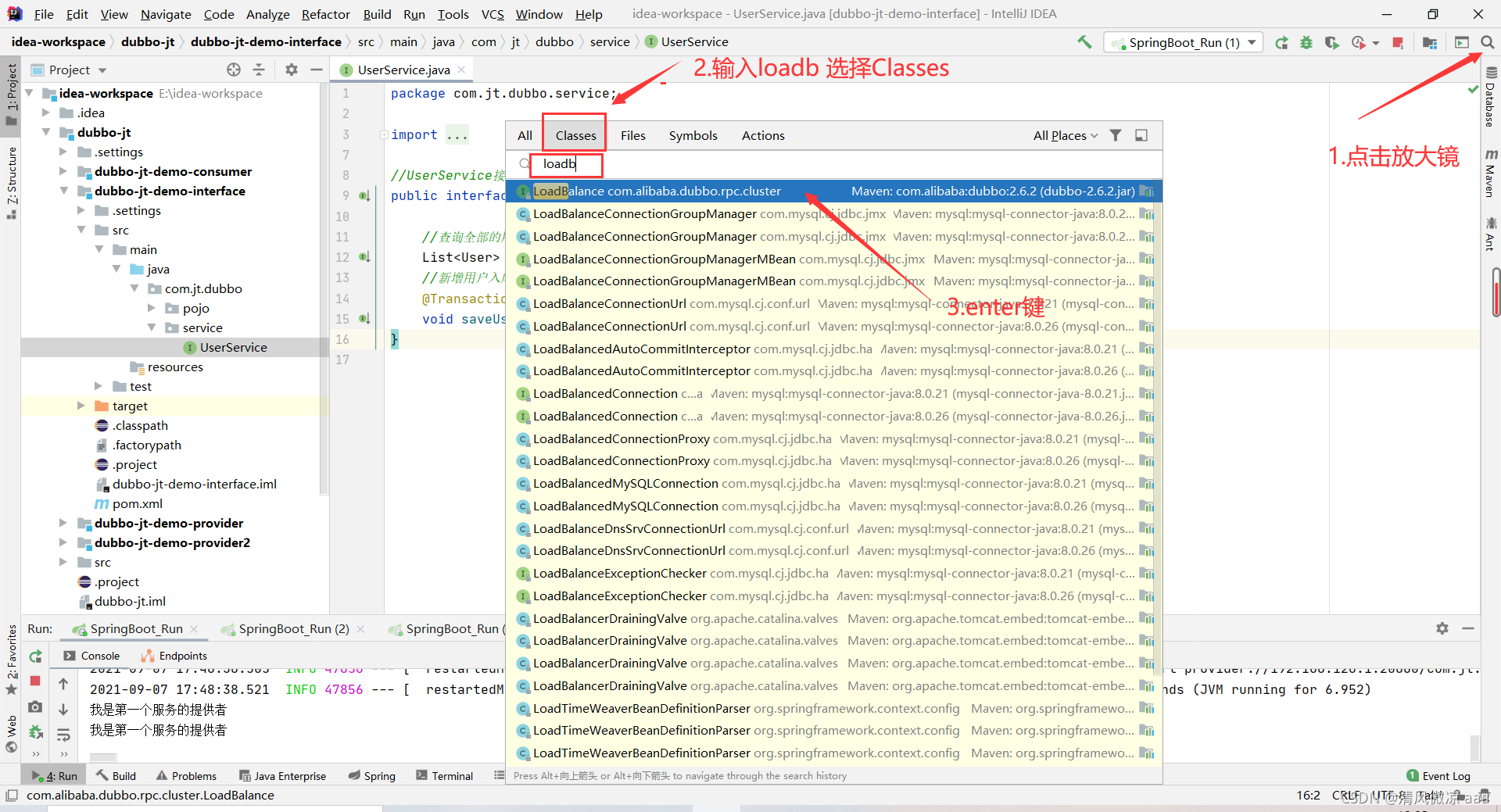
2).如何在代码中查找负载均衡种类:
步骤一:点击放大镜图标输入关键字进行搜索
步骤二:双击选中 ctrl+t查找接口的实现类。
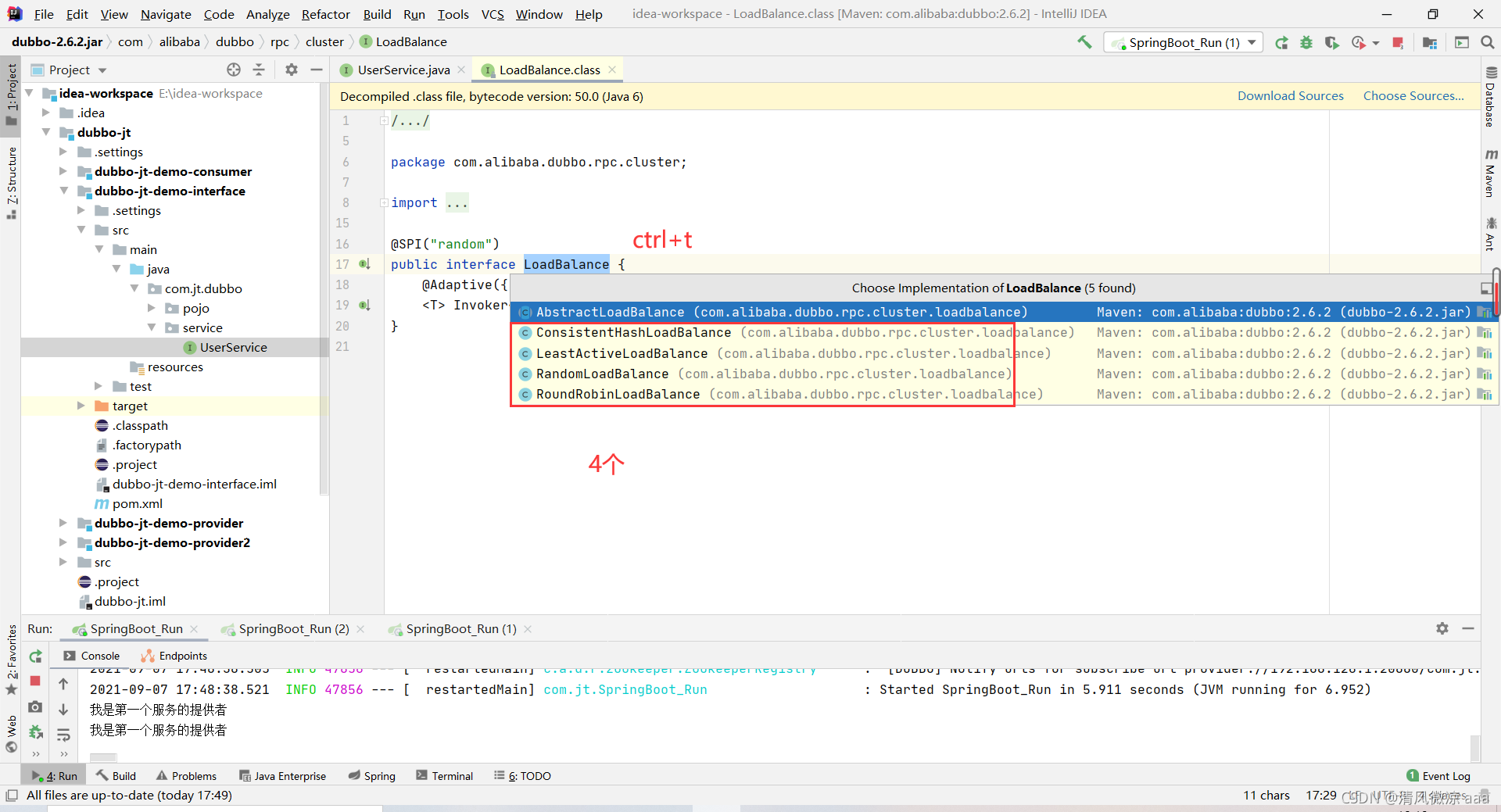
步骤三:进入实现类

3).在项目中如何配置:
说明:客户端负载均衡的方式在消费者当中配置。
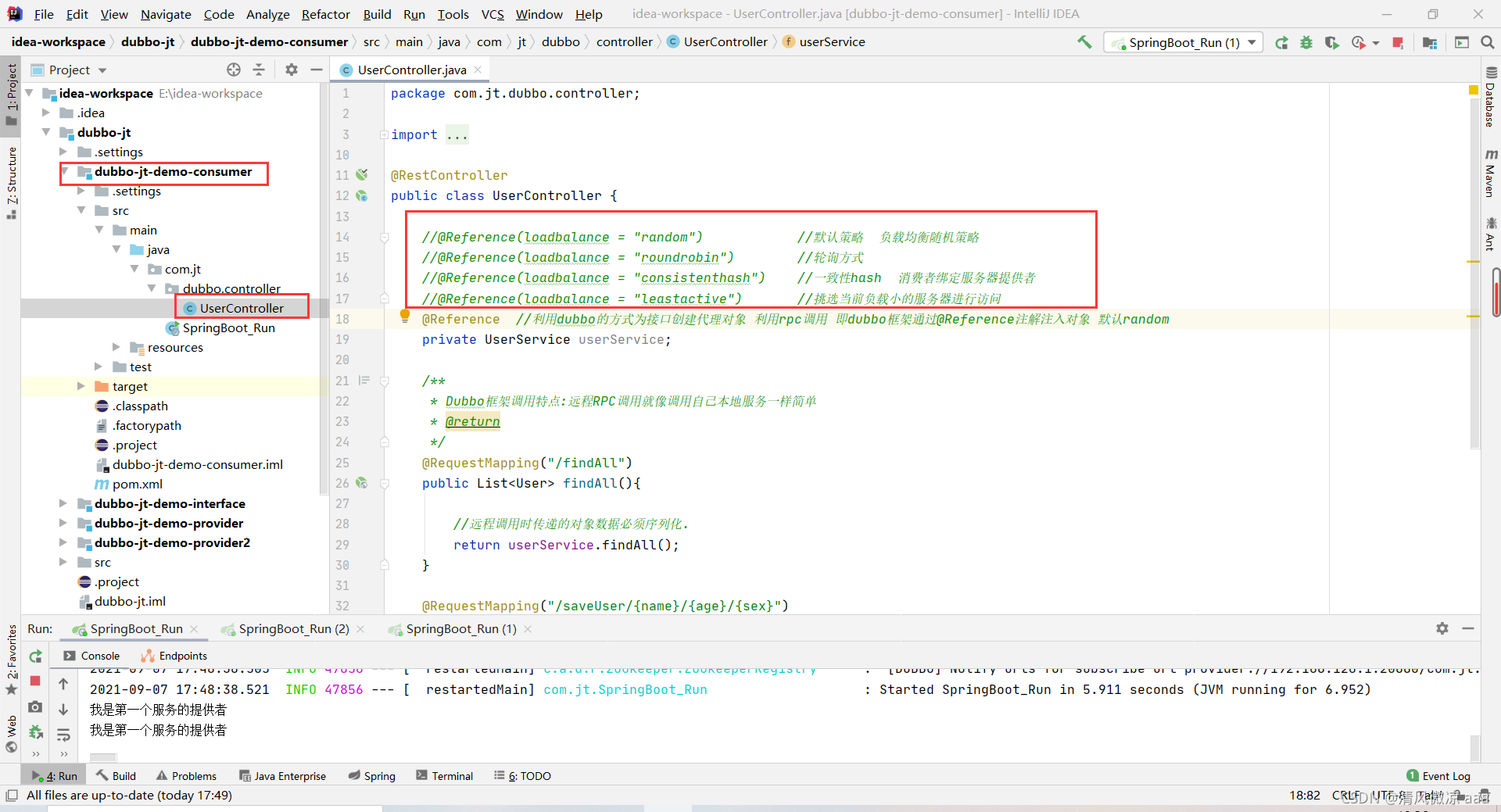
@Reference(loadbalance = "random") //默认策略 负载均衡随机策略
@Reference(loadbalance = "roundrobin") //轮询方式
@Reference(loadbalance = "consistenthash") //一致性hash 消费者绑定服务器提供者
@Reference(loadbalance = "leastactive") //挑选当前负载小的服务器进行访问
}