注意事项
1.AOP实现Redis缓存服务
aop复习,入门案例,实现redis缓存(选择类目) 自定义注解 叶子类目实现缓存
2.关于redis的配置说明
持久化策略:RDB AOF
Redis内存优化:LRU LFU Random TTL
3.Redis 缓存面试题 缓存穿透 击穿 雪崩
4.Redis分片
需求 入门案例 一致性hash算法
1. AOP实现Redis缓存服务
1.1 现有代码的分析
说明:
1). 虽然在业务层service中完成了代码的实现.但是该代码不具有复用性.如果换了其它的业务则需要重新编辑.
2). 由于缓存的代码写在业务层service中,所以代码的耦合性高,不方便以后的扩展.(如:将来用其它的软件代替redis做缓存,则需要更改业务层的代码,如果业务层有很多都做了缓存,那么一个一个修改起来太麻烦。)
需求:
1.能否实现代码的复用.
2.能否降低代码的耦合性.
1.2 AOP
1.2.1 AOP作用
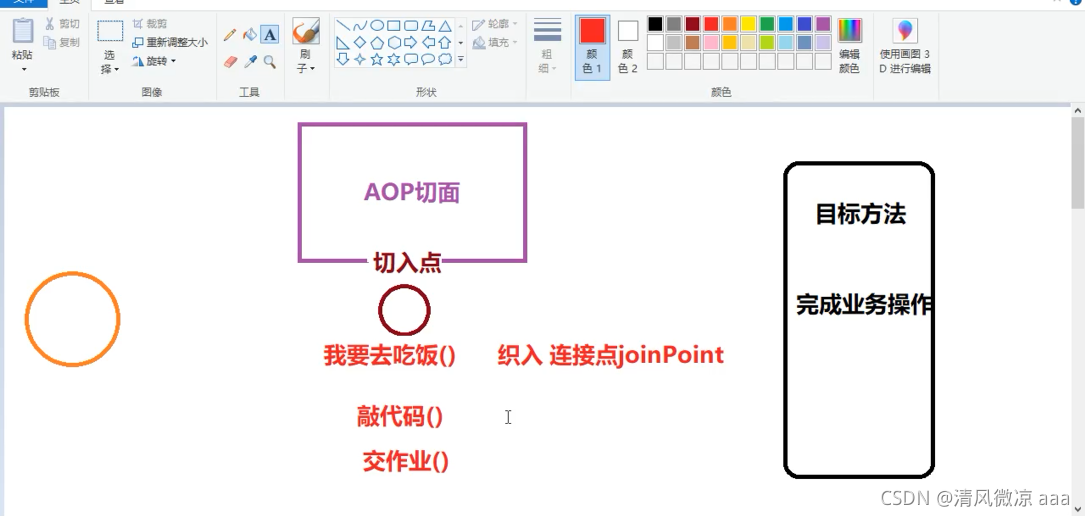
名称:面向切面编程.
一句话总结:降低代码的耦合性,在不改变原有代码的条件下,对功能进行扩展.
公式: AOP = 切入点表达式 + 通知方法.
专业术语:
1.连接点: 在执行正常的业务过程中满足了切入点表达式时进入切面的点.(织入) 多个
2.通知: 在切面中执行的具体的业务(原有业务的扩展) 方法
3.切入点: 能够进入切面(一个类)的一个判断 if判断 一个
4.目标方法: 将要执行的真实的业务逻辑.
举例: 通过特定的条件(切入点表达式) 打雷穿越到女儿国(切面:类),然后再女儿国具体干的事就是通知方法. 切入点只是一个判断条件,真正进行连接的是连接点.

1.2.2 关于通知说明
1.前置通知@Before: 目标方法执行之前执行
2.后置通知@AfterReturning: 目标方法执行之后执行
3.异常通知@AfterThrowing: 目标方法执行之后抛出异常时执行
4.最终通知@After: 不管什么时候都要执行的方法.
说明:上述的四大通知类型不能控制目标方法是否执行(它们都没有拦截的功能,不管是在目标方法之前之后执行完成后都会执行目标方法),一般使用上述的四大通知类型,都是用来记录程序的执行状态。
5.环绕通知@Around: 在目标方法执行前后都要执行的通知方法. 控制目标方法是否执行.并且环绕通知的功能最为强大.
环绕通知,如果调用了.joinPoint.proceed()方法,则执行目标方法

如果没有调用proceed()方法,会转一圈返回.

1.2.3 切入点表达式说明
作用: 当程序运行过程中 ,满足了切入点表达式时才会去执行通知方法,实现业务的扩展.
理解: 切入点表达式就是一个程序是否进入通知的一个判断(if)
种类(写法):
- bean(bean的名称 bean的ID:类的对象名) 只能拦截具体的某个bean对象 粗粒度的匹配原则 只能匹配一个对象
eg:bean("itemServiceImpl”) - within(包名.类名) 可以匹配多个对象 粗粒度的匹配原则 按类匹配
eg:within(“com.jt.service.*”) - execution(返回值类型 包名.类名.方法名(参数列表)) 细粒度的匹配原则 最为强大的用法
eg :execution(* com.jt.service..*.*(..))
..*代表这个包下的所有以及子包下的所有。.*代表扫描当前包下的一级目录
返回值类型任意 com.jt.service包下的所有的类所有的方法都会被拦截。 - @annotation(包名.注解名称) 细粒度的匹配原则 按照注解匹配.
1.2.4 解释连接点
说明:满足切入点表达式的方法叫做连接点。
解释:比如一个方法正常执行要调用目标方法,在执行过程中满足切入点进入到切面,那么此时这个正常执行的方法就叫做连接点。
1.2.5 AOPDemo复习(common中)
package com.jt.aop;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
import java.util.Arrays;
@Aspect //我是一个AOP切面类
@Component //将类交给spring容器管理
public class CacheAOP {
//公式 = 切入点表达式 + 通知方法
/**
* 关于切入点表达式的使用说明
* 粗粒度:
* 1.bean(bean的Id) 一个类
* 2.within(包名.类名) 多个类
* 细粒度
*/
@Pointcut("bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service..*)") //匹配多级目录
//@Pointcut("within(com.jt.service.*)") //匹配一级目录
//@Pointcut("execution(* com.jt.service..*.*(..))") //方法参数级别
public void pointCut(){
//定义切入点表达式 只为了占位
}
/**
* 定义前置通知,与切入点表达式进行绑定. 注意绑定的是方法
* 区别: @Before("pointCut()") 表示切入点表达式的引用 适用于多个通知 共用切入点的情况
* @Before("bean(itemCatServiceImpl)") 适用于单个通知.不需要复用的.即单个可以合并一起写。
*
* 需求:获取目标对象的相关信息.
* 1.获取目标方法的路径 包名.类名.方法名
* 2.获取目标方法的类型 class
* 3.获取传递的参数
* 4.记录当前的执行时间
* joinPoint:连接点对象
*/
@Before("pointCut()")
//@Before("bean(itemCatServiceImpl)")
public void before(JoinPoint joinPoint){
String className = joinPoint.getSignature().getDeclaringTypeName();//获取目标方法路径
String methodName = joinPoint.getSignature().getName();//获取目标方法名
Class targetClass = joinPoint.getTarget().getClass();//获取目标对象类型
Object[] args = joinPoint.getArgs();//获取传递的参数
Long runTime = System.currentTimeMillis();
System.out.println("我是前置通知");
System.out.println("方法路径:" +className+"."+methodName);
System.out.println("目标对象类型:" + targetClass);
System.out.println("参数:" + Arrays.toString(args));
System.out.println("执行时间:" + runTime+"毫秒");
}
/* @AfterReturning("pointCut()")
public void afterReturn(){
System.out.println("我是后置通知");
}
@After("pointCut()")
public void after(){
System.out.println("我是最终通知");
}*/
/**
* 环绕通知说明
* 注意事项:
* 1.环绕通知中必须添加参数ProceedingJoinPoint(它是JoinPoint的子类)
* 2.ProceedingJoinPoint只能环绕通知使用
* 3.ProceedingJoinPoint如果当做参数 则必须位于参数的第一位
*/
@Around("pointCut()")
public Object around(ProceedingJoinPoint joinPoint){
System.out.println("环绕通知开始!!!");
Object result = null;//接收目标方法执行的结果
try {
//执行目标方法有可能会报错,需要处理异常
result = joinPoint.proceed(); //执行下一个通知或者目标方法
} catch (Throwable throwable) {
throwable.printStackTrace();
}
System.out.println("环绕通知结束");
return result;
}
}
1.2.6 测试
运行: 先执行前置通知,在执行目标方法.

1.3 实现Redis缓存(选择类目)
1.3.1 需求分析
问题: 如何控制 哪些方法需要使用缓存? cacheFind()
解决方案: 采用自定义注解的形式 进行定义,如果 方法执行需要使用缓存,则标识注解即可.
关于注解的说明:
1.注解名称 : cacheFind
2.属性参数 :
2.1 key: 应该由用户自己手动添加 一般添加业务名称 之后动态拼接形成唯一的key
2.2 seconds: 用户可以指定数据的超时的时间
关于属性参数的说明:
key的前缀应该有客户自己输入,客户执行什么样的流程有必要告诉后台一声,根据客户输入的前缀动态拼接key.
数据的超时时间也应该由客户自己指定。
1.3.2 自定义注解(common)
将来还可能被别人用所以放在common中
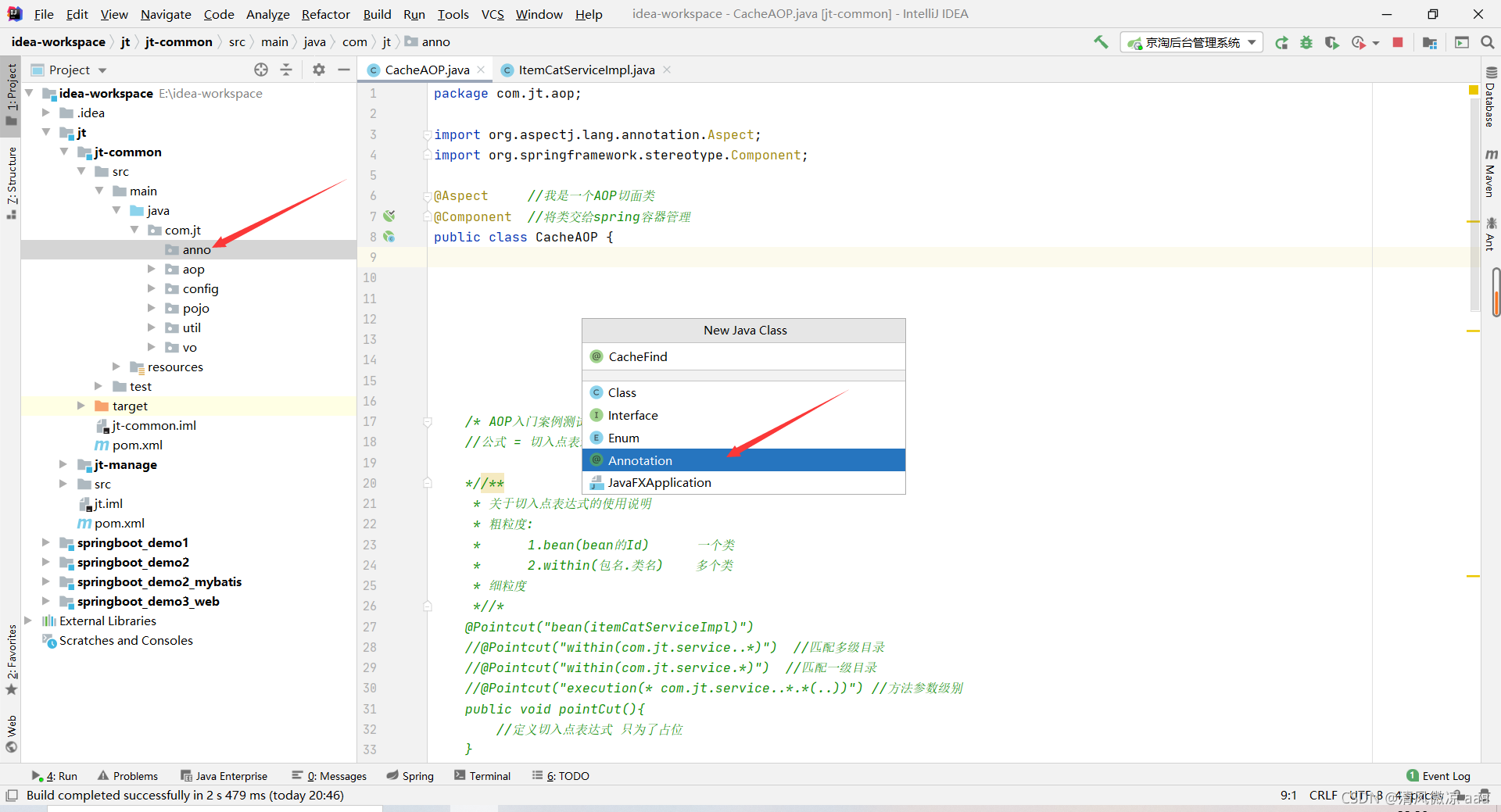
package com.jt.anno;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
//元注解:标示注解的注解
@Retention(RetentionPolicy.RUNTIME) //该注解什么时候有效 运行期有效
@Target({
ElementType.METHOD}) //对方法有效 加个{}表示可以写多个,只有一个可以不写{},注解里的数组用{}表示.
public @interface CacheFind {
//注意接口里的修饰符默认为 public
public String preKey(); //该属性为必须添加 用户标识key的前缀.
//注意不能使用包装类型
public int seconds() default 0; //设定超时时间 默认为0不超时 如果用户不写表示不需要超时,如果写了以用户为准.
}
1.3.3 使用注解
1).首先把控制层的代码还原。

2).在业务层使用注解
1.3.4 编辑CacheAOP
因为都写在一个类中,所以把测试Aop的Demo方法注释掉。
package com.jt.aop;
import com.jt.anno.CacheFind;
import com.jt.util.ObjectMapperUtil;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import java.util.Arrays;
@Aspect //我是一个AOP切面类
@Component //将类交给spring容器管理
public class CacheAOP {
@Autowired
private Jedis jedis;
/**
* 切面 = 切入点 + 通知方法
* 注解相关 + 环绕通知 控制目标方法是否执行(redis中有数据就不用执行目标方法,没数据才会执行目标方法)
* 目标方法:查询数据库
* 难点:
* 1.如何获取注解对象
* 2.动态生成key prekey + 用户参数数组(传什么接什么)
* 3.如何获取方法的返回值类型
*
*/
/**解释难点1:@Around("@annotation(cacheFind)")
* 本来这个地方为包名.注解名:@Around("@annotation(com.jt.anno.CacheFind)"),
* 但是这样写想要获取这个注解的属性,需要先通过反射获取类 方法 注解对象一步步的获取比较
* 麻烦。
* 优化:把直接直接当做参数传进方法里面(spring提供的)。
*/
//@Around("@annotation(com.jt.anno.CacheFind)")
//public Object around(ProceedingJoinPoint joinPoint){
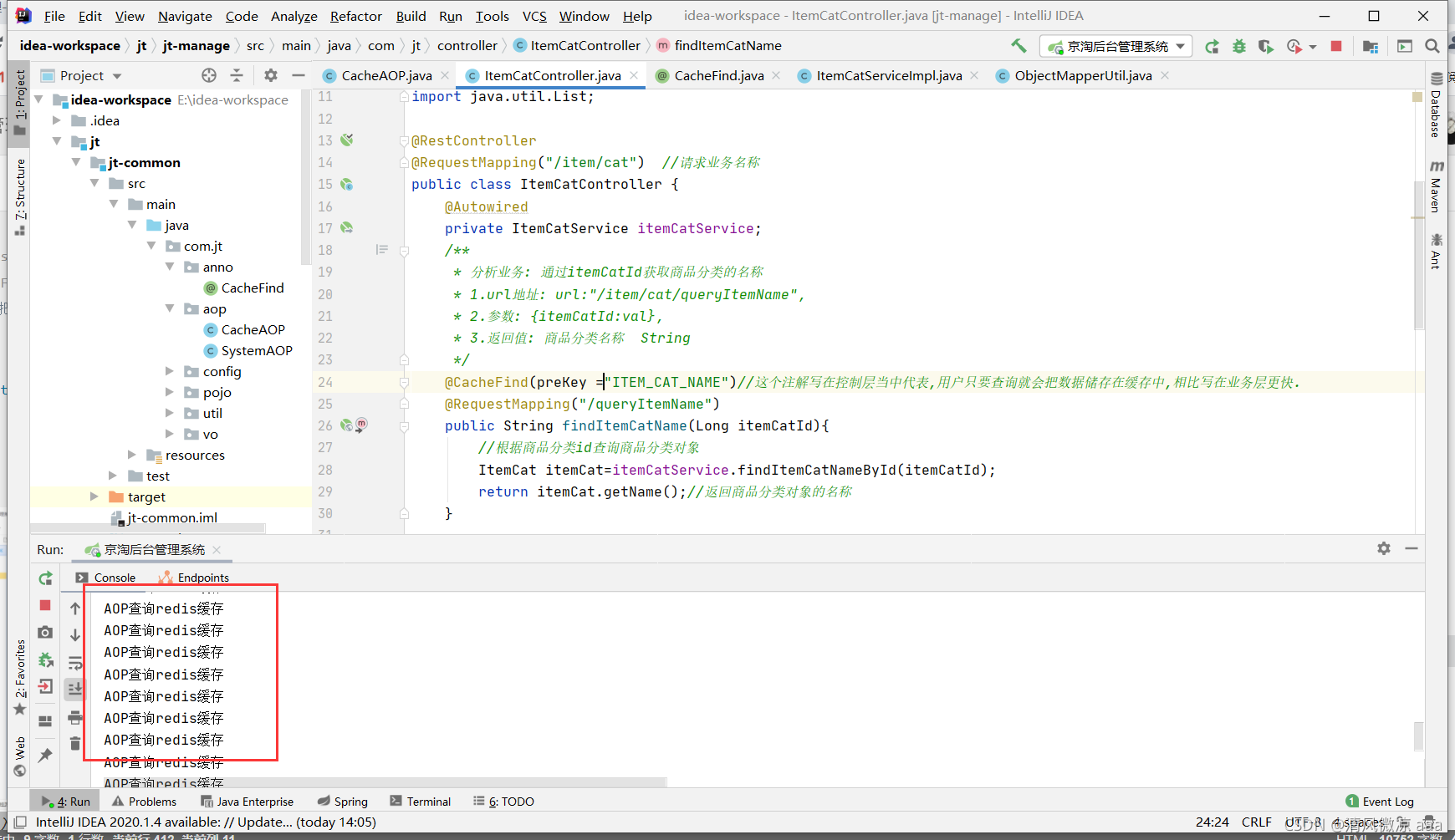
@Around("@annotation(cacheFind)")
public Object around(ProceedingJoinPoint joinPoint, CacheFind cacheFind){
Object result = null;
try {
//1.拼接redis存储数据的key
Object[] args = joinPoint.getArgs();//获取目标方法的参数,有可能传递的参数是多个用Object
String key = cacheFind.preKey() +"::" + Arrays.toString(args);
//2. 查询redis 之后判断是否有数据
if(jedis.exists(key)){
//redis中有记录,无需执行目标方法
String json = jedis.get(key);
/**
* 将json转化为对象返回:
* 这个地方转化的对象类型如果直接写:object.class只能转化一些简单地
* 数据(数组 集合 对象),对于一些嵌套的数据eg:Map<k,map<k,v>>这些一级甚至多级嵌套的数据
* 在转换时回报转换异常。
* 解决:直接获取方法的返回值类型,是啥就直接转化啥对象
* 动态获取方法的返回值类型(也可以通过反射,这里通过Aop提供的api通过签名获取)
* 向上造型 :父类引用指向子类对象
* 向下造型 :子类引用指向父类对象(父类需要强转赋值给子类,)
* getReturnType()为joinPoint的子类MethodSignature特有的方法,需要强转。
*/
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();//注意导包为反射的而不是spring的包
Class returnType = methodSignature.getReturnType();//根据签名获取返回值类型
result = ObjectMapperUtil.toObject(json, returnType);//不要写Object.class
System.out.println("AOP查询redis缓存");
}else{
//表示数据不存在,需要查询数据库
result = joinPoint.proceed(); //执行目标方法及通知(目标方法:查询数据库)
//将查询的结果保存到redis中去
String json = ObjectMapperUtil.toJSON(result);
//判断数据是否需要超时时间
if(cacheFind.seconds()>0){
//通过对象获取seconds属性
jedis.setex(key,cacheFind.seconds(),json);//大于0保存时间
}else {
jedis.set(key, json);
}
System.out.println("aop执行目标方法查询数据库");
}
} catch (Throwable throwable) {
throwable.printStackTrace();
}
return result;
}
/* AOP入门案例测试:以下都注释掉了
//公式 = 切入点表达式 + 通知方法
*//**
* 关于切入点表达式的使用说明
* 粗粒度:
* 1.bean(bean的Id) 一个类
* 2.within(包名.类名) 多个类
* 细粒度
*//*
@Pointcut("bean(itemCatServiceImpl)")
//@Pointcut("within(com.jt.service..*)") //匹配多级目录
//@Pointcut("within(com.jt.service.*)") //匹配一级目录
//@Pointcut("execution(* com.jt.service..*.*(..))") //方法参数级别
public void pointCut(){
//定义切入点表达式 只为了占位
}
*//**
* 定义前置通知,与切入点表达式进行绑定. 注意绑定的是方法
* 区别: @Before("pointCut()") 表示切入点表达式的引用 适用于多个通知 共用切入点的情况
* @Before("bean(itemCatServiceImpl)") 适用于单个通知.不需要复用的.即单个可以合并一起写。
*
* 需求:获取目标对象的相关信息.
* 1.获取目标方法的路径 包名.类名.方法名
* 2.获取目标方法的类型 class
* 3.获取传递的参数
* 4.记录当前的执行时间
* joinPoint:连接点对象
*//*
@Before("pointCut()")
//@Before("bean(itemCatServiceImpl)")
public void before(JoinPoint joinPoint){
String className = joinPoint.getSignature().getDeclaringTypeName();//获取目标方法路径
String methodName = joinPoint.getSignature().getName();//获取目标方法名
Class targetClass = joinPoint.getTarget().getClass();//获取目标对象类型
Object[] args = joinPoint.getArgs();//获取传递的参数
Long runTime = System.currentTimeMillis();
System.out.println("我是前置通知");
System.out.println("方法路径:" +className+"."+methodName);
System.out.println("目标对象类型:" + targetClass);
System.out.println("参数:" + Arrays.toString(args));
System.out.println("执行时间:" + runTime+"毫秒");
}
*//* @AfterReturning("pointCut()")
public void afterReturn(){
System.out.println("我是后置通知");
}
@After("pointCut()")
public void after(){
System.out.println("我是最终通知");
}*//*
*//**
* 环绕通知说明
* 注意事项:
* 1.环绕通知中必须添加参数ProceedingJoinPoint(它是JoinPoint的子类)
* 2.ProceedingJoinPoint只能环绕通知使用
* 3.ProceedingJoinPoint如果当做参数 则必须位于参数的第一位
*//*
@Around("pointCut()")
public Object around(ProceedingJoinPoint joinPoint){
System.out.println("环绕通知开始!!!");
Object result = null;//接收目标方法执行的结果
try {
//执行目标方法有可能会报错,需要处理异常
result = joinPoint.proceed(); //执行下一个通知或者目标方法
} catch (Throwable throwable) {
throwable.printStackTrace();
}
System.out.println("环绕通知结束");
return result;
}*/
}
访问测试:

1.3.5 关于环绕通知参数的说明
问题一:连接点必须位于通知的参数的第一位. 规范

否则报错信息如下:

问题二: 其他四大通知了类型是否可以添加ProceedingJoinPoint对象
答案: ProceedingJoinPoint 只能添加到环绕通知中.
报错如下:

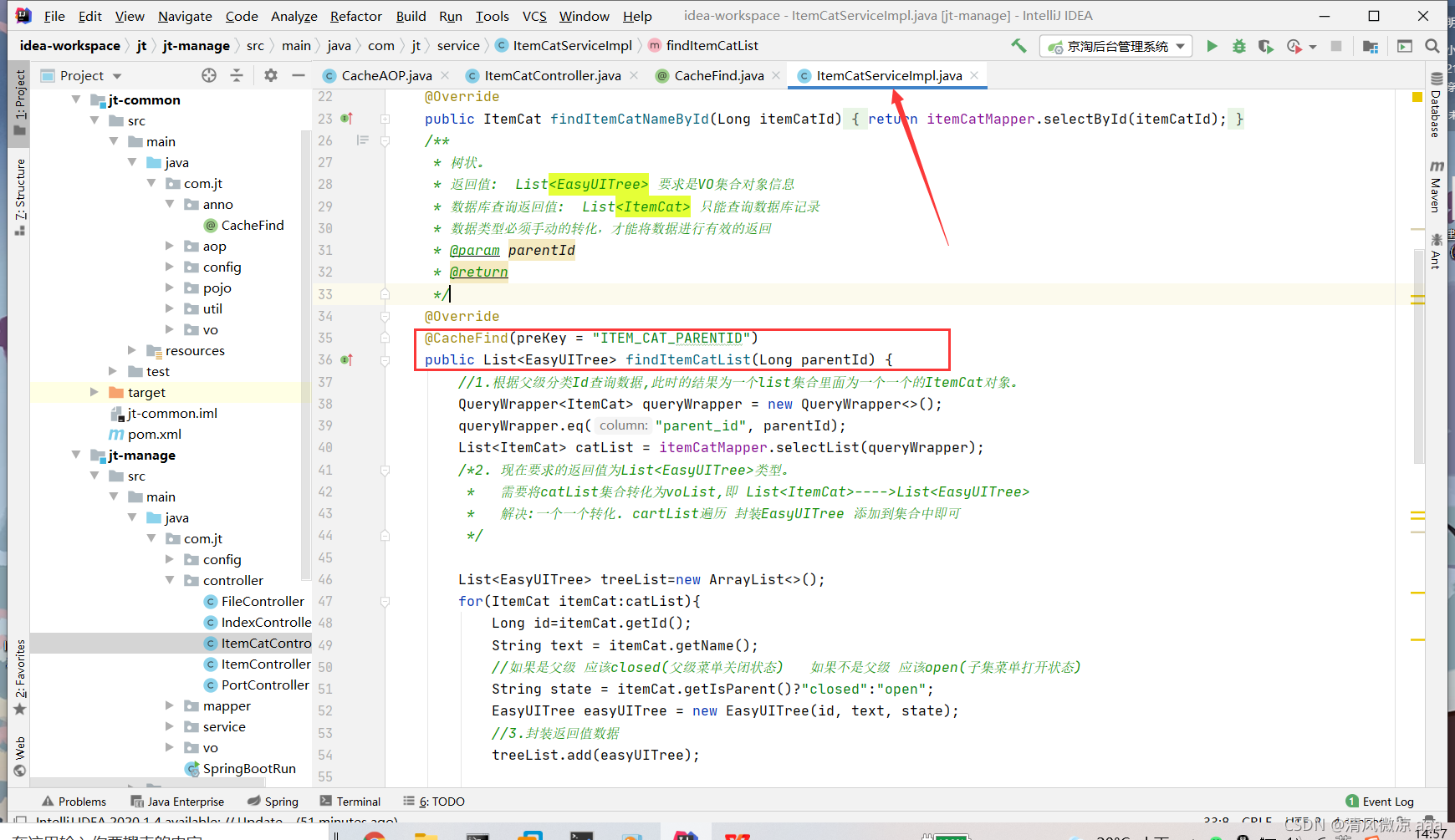
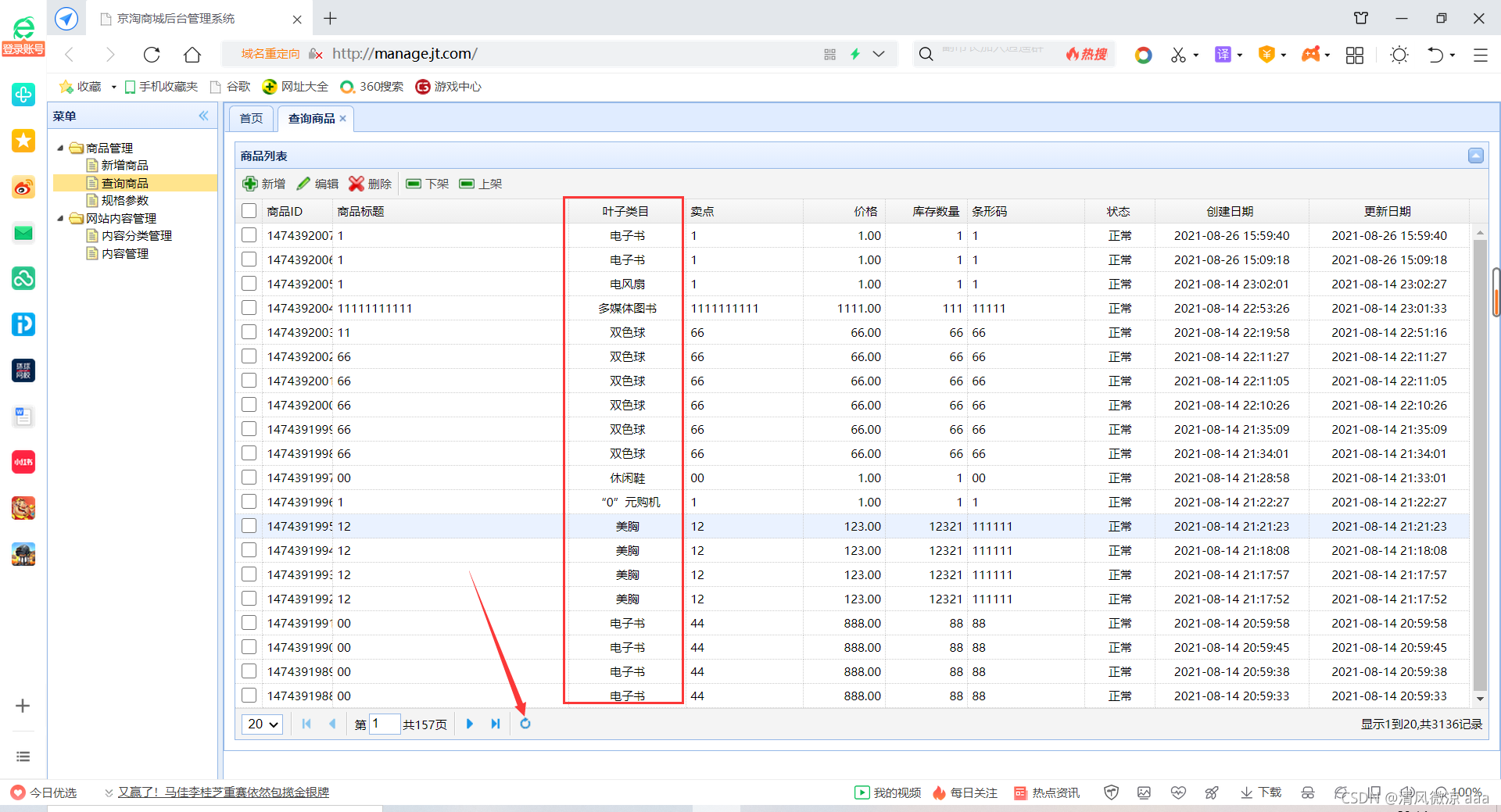
1.4 商品列表分类实现缓存处理(叶子类目)
直接使用即可,都写在common里了可以通用。

/**
* 分析业务: 通过itemCatId获取商品分类的名称
* 1.url地址: url:"/item/cat/queryItemName",
* 2.参数: {itemCatId:val},
* 3.返回值: 商品分类名称 String
*/
@RequestMapping("/queryItemName")
@CacheFind(preKey="ITEM_CAT_NAME")//这个注解写在控制层当中,代表用户只要查询就会把数据储存在缓存中,相比写在业务层更快.
public String findItemCatName(Long itemCatId){
return itemCatService.findItemCatNameById(itemCatId);
}
测试:
2. 关于redis的配置说明
2.1 Redis持久化策略说明
2.1.1 持久化需求说明
问题:Redis数据都保存在内存中,如果内存断电则导致数据的丢失.为了保证用户的内存数据不丢失,需要开启持久化机制.
说明:redis默认条件下支持数据的持久化操作, 当redis中有数据时会定期将数据保存到磁盘中。当Redis服务器重启时 ,会根据配置文件读取指定的持久化文件,实现内存数据的恢复.
什么是持久化: 定期将内存中的数据保存到磁盘中.
2.1.2 Redis中持久化介绍
说明:Redis中的持久化方式主要有2种.
方式1: RDB模式 dump.rdb(持久化文件) 默认的持久化方式
方式2: AOF模式 appendonly.aof 默认关闭需要手动的开启.
2.1.3 RDB模式
特点:
1. RDB模式是Redis中默认的持久化策略.
2. RDB模式可以实现定期的持久化,但是可能导致数据丢失.
3. RDB模式作的是内存数据的快照,并且后拍摄的快照会覆盖之前的快照,所以持久化文件较小,恢复数据的速度较快,工作的效率较高。
命令:
用户可以通过命令要求redis进行持久化操作.(前提是进入到redis客户端)
1). save 是同步操作 ,要求redis立即执行持久化操作. 用户可能会陷入阻塞状态.
2). bgsave 是异步操作,开启单独的线程执行持久化操作. 持久化时不会影响用户的使用. 不能保证立即马上执行.
如:

配置:
1). 进入redis的配置文件。

2).显示行号:set nu

3).默认的持久化文件名叫:dump.rdb可以改名。
:/rdb可以在配置文件中查找关键字。

4).持久化文件的位置。
dir ./ 相对路径的写法,代表当前工作的目录。
dir /usr/local/src/redis 绝对路径写法

5).默认的规则。
解释:
900秒内如果执行了1次更新,那么持久化1次
300秒内执行10次更新,持久化1次。
60秒内执行10000次更新,持久化1次。
问题:save 1 1,一秒内持久化一次行吗???
答:不行,因为save是阻塞的,操作一次持久化一次会大大降低访问速度性能太低。

2.1.4 AOF模式(就是追加)
特点:
- AOF模式默认的条件下是关闭状态,需要手动的开启.
- AOF模式是异步操作,记录的是用户操作的过程,可以保证用户的数据尽可能不丢失。
解释用户操作的过程:即在持久化文件在记录的是操作步骤如:set aa , set b b这些操作步骤。 - 由于AOP记录的是持久化文件的状态,所以持久化文件占用空间相对较大,恢复数据的速度较慢效率较低,需要人为的优化持久化文件(eg:存的数据越多越卡,把5个g的日志文件优化为100M这样速度就快了)。
配置:
1 .开启AOF配置(同样先进入到redis.conf配置文件中)
快数查找关键字命令 :/appendonly
注意:如果开启AOF模式,这时Rdb和AOF模式共存,此时以AOF模式为主。

2 .配置好后需要先关闭在重启生效:

3 .AOF模式的持久化策略(728行)
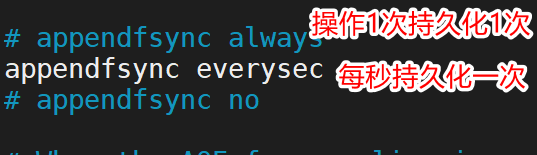
appendfsync always 如果用户执行的了一次set操作则持久化一次
appendfsync everysec 每秒持久化一次
appendfsync no 不主动持久化.
2.1.5 总结:何时使用RDB/AOF
1.如果用户可以允许少量的数据丢失可以选用RDB模式(快).
2.如果用户不允许数据丢失则选用AOF模式.
3.如果既要保证效率又要保证数据,则应该配置redis的集群 ,一般主机开启RDB模式,从机开启AOF模式,可以保证数据的有效性。
2.2 关于Redis内存优化的说明
2.2.1 背景说明
说明:Redis数据的存储都在内存中,如果一直向内存中存储数据必然会导致内存数据的溢出。
解决方式:
- 尽可能为保存在redis中的数据添加超时时间.
- 利用算法优化旧的数据.
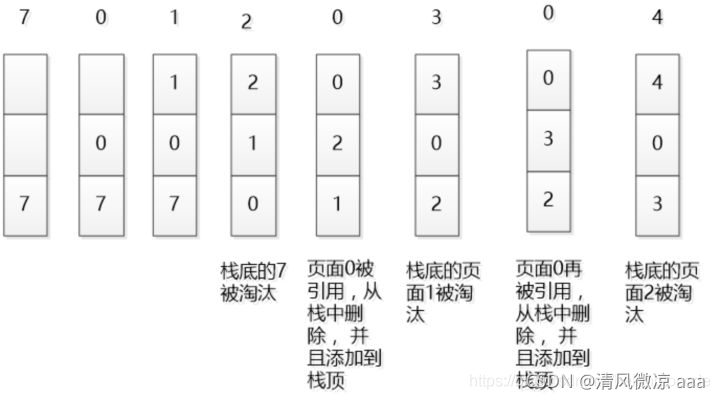
2.2.2 LRU算法
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
维度:时间T
LRU算法是当下实现内存清理的最优算法.
2.2.3 LFU算法
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
维度: 引用次数
2.2.4 Random算法
随机删除数据。
2.2.5 TTL算法
说明:监控剩余的存活时间,将存活时间少的数据提前删除.
2.2.6 Redis内存优化策略

1.volatile-lru 在设定了超时时间的数据中,采用lru算法.
2.allkeys-lru 所有数据采用lru算法
3.volatile-lfu 在超时的数据中采用lfu算法
4.allkeys-lfu -> 所有数据采用lfu算法
5.volatile-random -> 设定超时时间的数据采用随机算法
6.allkeys-random -> 所有数据随机删除
7.volatile-ttl -> 删除存活时间少的数据
8.noeviction -> 不会删除数据,如果内存溢出报错返回.

3. 关于Redis 缓存面试题
问题描述: 由于海量的用户的请求 如果这时redis服务器出现问题 则可能导致整个系统崩溃.
运行速度:
- tomcat服务器 150-250 之间 JVM调优 1000/秒
- NGINX 3-5万/秒
- REDIS 读 11.2万/秒 写 8.6万/秒 平均 10万/秒
3.1 缓存穿透
问题描述: 由于用户高并发环境下访问 数据库中不存在的数据时,容易导致缓存穿透。
如何解决: 设定IP限流的操作,在nginx中或者微软服务机制通过API网关实现。
3.2 缓存击穿
问题描述: 由于用户高并发环境下, 由于某个数据之前存在于内存中,但是由于特殊原因(数据超时/数据意外删除)导致redis缓存失效. 而使大量的用户的请求直接访问数据库.
俗语: 趁他病 要他命
如何解决:
1.设定超时时间时,不要设定相同的时间。
2.设定多级缓存。
3.3 缓存雪崩
说明: 由于高并发条件下,有大量的数据失效.导致redis的命中率太低.而使得用户直接访问数据库(服务器)导致崩溃,称之为缓存雪崩.
解决方案:
1.不要设定相同的超时时间+随机数
2.设定多级缓存.
3.提高redis缓存的命中率 调整redis内存优化策略 采用LRU等算法.
4. Redis分片机制
4.1 为什么需要分片机制
说明:
如果需要在redis中进行海量的数据存储,只有一台redis显然不能实现该功能。而通过一味的扩大redis的内存的方式也不能达到要求,因为时间都浪费在寻址中(即:内存越大寻找数据越慢)。
问题:如何有效的存储海量的数据呢???
答:分片机制.
4.2 补充:如何增大redis的内存


4.3 Redis分片说明
说明:一般采用多台redis,分别保存用户的数据,从而实现内存数据的扩容.
对于用户而言:将redis分片当做一个整体,用户不在乎数据到底存储到哪里,只在乎能不能存.
总结:
1).分片主要的作用: 实现内存扩容.
2).三台redis存的是不同的数据.
4.4 Redis分片搭建
4.4.1 搭建注意事项
说明:由于Redis启动是根据配置文件运行的,所以如果需要准备3台redis,则需要准备3份配置文件redis.conf.
端口号依次为:6379/6380/6381
4.4.2 搭建步骤
1). 把原来的redis关闭掉

2).创建分片目录方便管理:mkdir shards

3).复制3个配置文件到分片的目录

4).修改配置文件的端口号:6380 6381


5). 启动redis:
redis-server 6379.conf
redis-server 6380.conf
redis-server 6381.conf
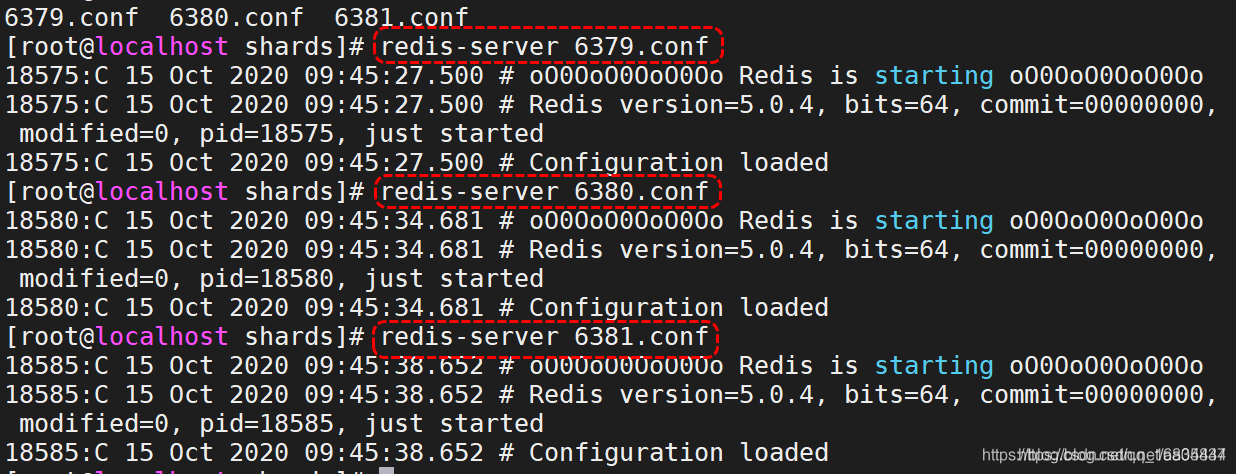
6). 校验服务器是否正常运行ps -ef |grep redis

7).说明:现在3个redis的持久化文件名字相同,启动时都会把持久化操作写到同一个文件里面。如果重新启动3台redis则由于持久化文件相同,都会读取同一个文件,这样会导致3台redis的节点数据都相同。真实条件下需要修改这3个持久化文件名,因为最后学的是缓存,这个地方的学习只是过渡,所以少改点东西节约时间,只要不重启就行。
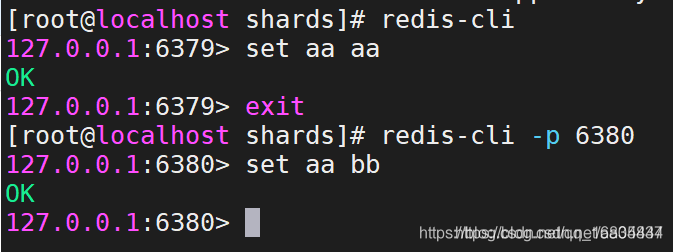
4.4.3 关于分片的注意事项
1.问题描述:
当启动多台redis服务器之后,多台redis暂时没有必然的联系,各自都是独立的实体.可以独立的进行数据的存储(即每台redis服务器可以储存相同的数据).如图所示:
2.如果将分片通过程序的方式进行操作,要把3台redis当做一个整体,所以与上述的操作完全不同,不会出现一个key同时保存到多个redis的现象。
4.4.4 Redis分片入门案例

/**
* 测试Redis分片机制
* 业务思路:
* 用户需要通过API来操作3台redis.用户无需关心数据如何存储,
* 只需要了解数据能否存储即可.
* 思考: 2005的数据存储到哪台redis中 (开发的人需要知道)
* redis分片是如何实现数据存储的!
*/
@Test
public void testShards(){
//把3台redis节点存到list集合
List<JedisShardInfo> list = new ArrayList<>();
list.add(new JedisShardInfo("192.168.126.129", 6379));//ip+redis的端口号
list.add(new JedisShardInfo("192.168.126.129", 6380));
list.add(new JedisShardInfo("192.168.126.129", 6381));
//准备分片对象
ShardedJedis shardedJedis = new ShardedJedis(list);
shardedJedis.set("2005", "redis分片学习");
System.out.println(shardedJedis.get("2005"));
}
思考:数据到底储存到redis分片中具体的那台redis服务器中呢?
通过后台查看数据储存在6381里面,那么这是如何控制的呢? 通过一致性hash算法。
注意:分片用的是一致性hash算法。

4.5 一致性hash算法
4.5.1 算法介绍
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,目的是解决分布式缓存的问题。 [1] 在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题 [2] 。
4.5.2 常识介绍
常识1: 一般的hash是8位16进制数.共有多少可能性: 0-9 A-F (24)8 = 2^32
常识2: 如果对相同的数据进行hash运算 结果必然相同的.
常识3: 一个数据1M 与数据1G的hash运算的速度一致.
4.5.3 一致性hash说明
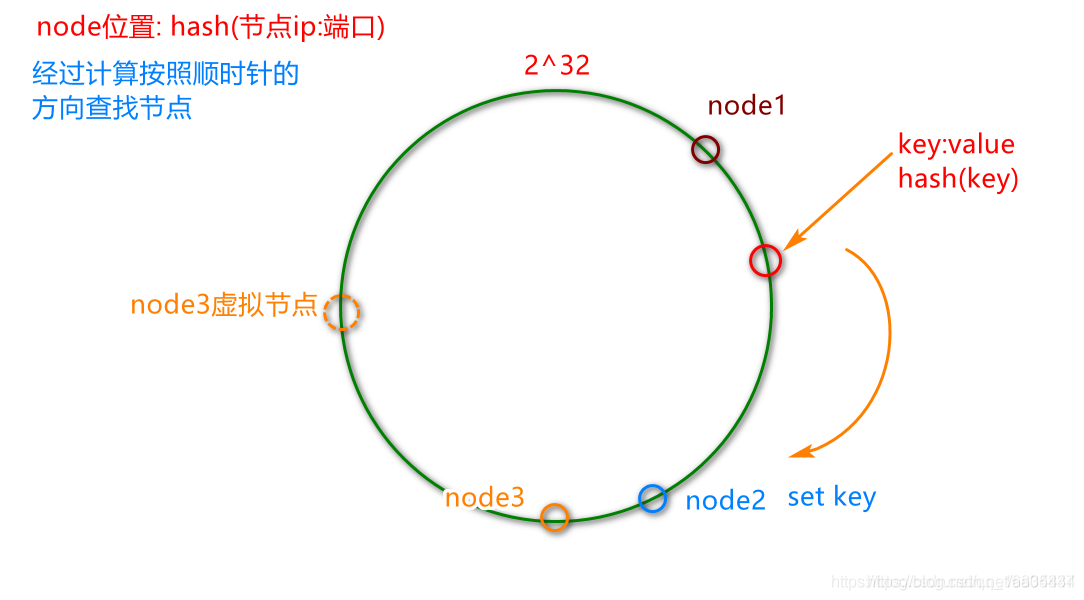
步骤:
1.首先计算node节点(通过ip+port计算3台redis的hash节点)
2.将用户的key进行hash计算,之后按照顺时针的方向找到最近的node节点之后链接,执行set操作.

4.5.4 特性一 平衡性
概念:平衡性是指hash的结果应该平均分配到各个节点,这样从算法上解决了负载均衡问题 [4] 。(大致平均)
问题描述: 由于节点都是通过hash方式进行算计.所以可能出现如图中的现象.,导致负载严重不平衡

解决方法: 引入虚拟节点
4.5.5 特性二 单调性
单调性是指在新增或者删减节点时,不影响系统正常运行 因为可以实现自动的数据迁移.。
原则: 在进行数据迁移时 应该尽可能少的改变原有的数据.

4.5.6 特性三 分散性
谚语: 鸡蛋不要放到一个篮子里.
分散性是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据