摘要 Abstract
- 研究内容: 一次性模仿学习
- 目标: 基于单个演示来执行之前未见过的任务
- 过去研究优点: 模仿学习效果很好
- 过去研究不足: 大多数方法需要几百个元训练任务,限制了方法的可扩展性
- 创新工作: 将一次性模仿学习作为一个伴有符号基础问题的符号规划问题
- 创新意义: 这种形式将策略执行与任务间的泛化分离开来,从而提高数据效率
- 创新难点: 关键挑战是符号基础在训练数据有限的情况下容易出错,导致后续的符号规划失败
- 难点解决方式: 通过提出一个离散符号规划者的连续松弛解决,该离散符号规划者直接计划符号基础模型的概率输出
- 难点解决意义: 在不使用大量训练数据情况下,规划者的持续松弛还可以利用包含在概率符号基础中的信息,并在一次性模仿学习任务中显著提高基线规划者
介绍 Introduction
- 通过单次演示学习一个之前没有执行过的任务,需要大量的数据来进行元训练
- 将长时间任务的一次性模仿学习作为一个规划问题来利用符号定义的结构,使我们可以将策略执行与任务间的泛化分离开来,这大大减少了元训练中所需的任务数量
- 符号基础问题将连续输入状态(例如物体姿态或图像)映射到规划者所要求的符号状态表示
- 任务间的泛化仅由符号基础处理,从策略执行中分离出来
- 符号基础问题比以往论文中使用的黑箱策略网络更容易实现任务间泛化,因为符号基础函数可以在相同或类似的任务之间共享
- 通过提出一种模块化符号基础网络(SGN)来推断给定连续输入的符号状态,进一步改进了符号基础网的泛化
- SGN 的模块化使得符号状态之间能够有效地共享参数,从而进一步提高数据效率
- 主要的技术挑战是,SGN 的输出在低数据区域容易出错,会输出无效的符号状态,从而导致后续的符号规划失败

- 以上图中堆叠的物块为例,SGN 有可能输出: On(A, B) 和 Clear(B) 均为真,但这两种情况不可能同时为真
- 解决方案是提出一个符号规划器的连续松弛,用概率符号代替符号规划器中的集合理论的表示,这允许规划者直接规划符号状态的 概率分布
- 这解决了上述的不一致性,因为符号的基础阶段不再需要离散的结果,只需要提供符号状态的连续估计
- 我们证明了符号规划器的持续松弛仍然可以利用 SGN 的持续输出提供的信息来完成单次演示的任务
- 该图对比了我们借助符号规划器提出的方案与其他神经网络基于单次演示模仿学习的方案,我们将符号规划器的连续松弛称为连续规划器(CP)
- 对比普通的符号规划器,我们的输入可以使连续的状态
- 对比现有的单次模仿学习模型,我们将演示理解模型从策略模型中分离开来,可以提高数据效率
介绍总结
- 以单次模仿为规划,分离了策略执行和任务间的泛化,提高数据效率
- 提出连续规划器,允许规划者直接对符号状态的分布进行计算,解决无效状态问题
- 将模块化引入符号基础神经网络,进一步提高任务间泛化能力
相关工作 Related Work
- 单次模仿学习的结构
- 定义:单次模仿学习的目标是将演示转化为可执行的策略
- 思路:长时间,多步骤的任务可以通过模块化和分层任务结构来实现
- 例子:NTP 用分层程序来分解演示,NTG 将任务结构建模为一个图生成问题
- 缺陷:然而这些工作依赖于函数近似器,为子任务之间的转换建模,限制了它们的泛化能力
- 改进:我们的模型明确地根据每个子任务的前置和后置条件符号通过我们的符号规划公式
- 高级任务计划
- 前人工作:用概率符号的表示方法代替用集合理论的表示方法,从而体现获取符号时的不确定性
- 改进:我们假定了一个确定的范围,在这个范围中,通过动作的符号状态转换是已知的和确定的
- 改进意义:可以推导出规划器的连续松弛(SectionIV-C),大大降低了计算复杂度,既假定了转换的确定性,也考虑了符号基础的不确定性
- 用于操控规划的符号基础
- 工作内容:我们的公式将符号规划器与连续输入关联起来
- 前人工作:操控规划与几何连续状态的符号基础的研究,假定它们得到了从几何状态到符号状态的映射,这些方法要么不考虑对符号的规划,要么不考虑连续规划者在规划中的符号的不确定性
- 改进:符号基础网络不假定一个给定的映射,可以使用任意连续状态作为输入,学习这个符号基础的想法也被用于操控
设置问题和准备工作 Problem Setup and Preliminaries
- 单次模仿学习
- 目标:通过单次演示执行未见过的任务
- 设 T 为一组任务(例如堆叠物块)
- 提供一次演示:
dτ = [dτ1, ..., dτT],其中每一个dτt都是连续的状态 - 目标是找到一个模型
Φ(·)来输出一个策略πτ = Φ(dτ),可以用这个策略来完成新的任务 - 模型
Φ(·)需要理解并学习演示,同时执行任务, 具有挑战性 - 前人工作:将任务
T分割为互斥的一组元任务Tmeta-train和未见过的任务Tmeta-test,用Tmeta-train训练的模型Φ(·)完成Tmeta-test
- 符号规划
- 工作内容:将单次模拟学习作为一个经典符号规划问题
- 规划问题:
(S0, SG, O) S0:初始状态;SG:目标状态;一系列操作符(运算符):O = {o}- 运算符:
o = (name(o), precondition(o), effect(o)) name(o):操作符名称和参数列表;precondition(o):先决条件;effect(o):应用操作符后如何更新状态state:真实基本原子的集合(例如{On(A,B), Clear(A)})- 基本原子:如
On(A,B),由谓词(On(·,·))和参数的对象(A和B)组成 - 操作
a:接地操作符,操作符的所有参数都被对象替换 - 规划问题的解:
π = [a1,…,aN]由一系列操作的ai构成 - 当开始状态为
S0,我们要通过规划达到一个满足SG的状态 - 采用语言:规划域定义语言(PDDL)
- 在PDDL中,规划问题被分为域文件和问题文件
- 域文件:
O = {o}操作符和谓词的集合;问题文件包含初始状态S0和目标SG - 以块堆叠域为例:所有块堆叠任务共享相同的域文件,而每个任务都有自己的问题文件,来指定初始配置/状态和目标配置/状态
- 当我们说 Tunseen 和 Tseen 在同一个域中时,我们假设它们共享相同的域文件,并且在训练中可用
我们的方案 Our Method
A. 将单次模仿学习作为一个规划问题
- 现有的单次模仿学习方法借助演示将
φ(·)参数化策略模型,虽然这些方法已被证明可以推广到Tmeta−test,但训练这样的策略网络需要大量的数据,因为策略网络需要同时解释演示和执行任务 - 我们将单次模仿定义为一个符号规划问题:将复合
φ(·)的建模分解为学习符号接地网络(SGN),进行连续规划(CP):φ(·)= CP(SGN(·)),在这种情况下,任务间的泛化由 SGN 处理,而 CP 可以专注于策略的执行,大大降低了对看不见的任务进行泛化的复杂性 - 我们通过提出符号接地网络 (SGN) 来解决符号接地问题
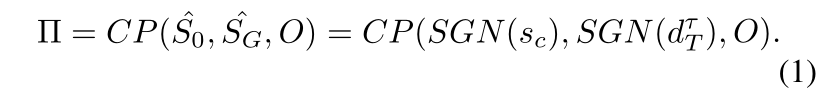
- 单次模仿学习的符号规划制定方案:
SG:目标符号状态S0:当前符号状态sc:当前连续状态O:定义在域文件中的操作符
- 通过观察,通过求解符号接地问题,当前连续状态 s 可以映射到对应的符号状态 S
SG:单次演示最后的状态 dτT 需要满足 SGS0:通过观察当前状态 sc 映射得到
- 原问题的解由
π = [a1,…,aN]表示一系列操作的 ai 构成 - 现在进行连续规划,参数是初始符号状态,目标符号状态,以及操作符
CP(S0, SG, O) - 而初始和目标状态都可以通过求解接地网络来表示,对应着演示初始状态和最终状态:
CP(SGN(sc), SGN(dτT), O)
B. 符号接地网络
- 上述 (1) 式将符号接地和任务规划分开,符号接地网络 (SGN) 主要意义是任务间的泛化
- SGN 比原来的复合问题更容易优化,因为我们希望 SGN 可以符号接地的方法可以在相似的域之间共享
- 为了保证 SGN 数据的效率,我们利用了模块化神经网络,这个之前用于泛化视觉问题回答,以及策略学习,它是通过不同模型组件之间参数共享达到的
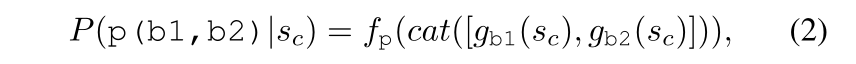
p:谓词fp(·):谓词模块b:对象gb(·):对象模块cat:拼接两部分
- 借助多层感知机,接地的原子部分
p(b1, b2)在初始连续状态sc下的谓词,可以通过两个对象模块的拼接后,再通过谓词模块得到
C. 连续规划

- 符号规划器需要离散输入,这里的概率是连续的,一种简单思路是设置阈值,比如概率大于 0.5 才生效,上述 SGN 输出就是两种:
Clear(A):A 上没东西On(A, B): A 在 B 上面
- 两种输出是冲突的,不适用于规划
- 利用可满足性 (SAT) 问题可以找到不满足的状态,但是对神经网络的每个输出都判定一次是不合理的
- 我们提出了符号规划的连续松弛,直接用概率值进行规划,这让我们的连续规划器根据 SGN 的输出可以输出一个动作列表
- 经典符号规划如下:
- 定义当前符号状态
- 找到可适用的操作
- 选取一个可适用的操作
- 应用该操作,达到新状态
- 达到目标时停止
- 连续松弛的提出,需要将上面的符号状态改为符号概率或状态分布
- 更重要的是,由于规划问题的离散性和确定性,我们可以根据 SGN 的输出推导出所有这些步骤的有效迭代公式,而不必边缘化一个大的状态空间(看不懂)
- 状态表示:
- 可应用的操作:
- 给定概率
Z(s),应用操作a的概率
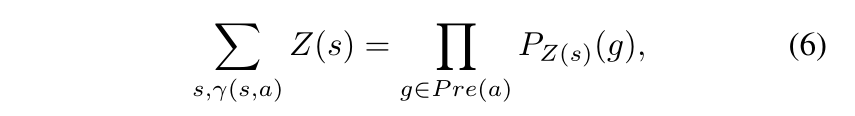
Z(s):表示符号s对应的概率分布Pz(s)(g):表示选择接地原子g应对概率Z(s),g选择正确的概率Pre(a):预处理集合γ(s,a):s满足预处理集合中的a- 由于条件独立性,这个求和可以用预处理集合中的基态原子的概率来表示
- 给定概率
- 操作选取:
- 没有操作列表,每个操作有一个概率值,只有操作排序
- 应用操作:
- 尝试应用状态
a,当前状态概率分布Z(s),可以变成新状态分布Z'(s')
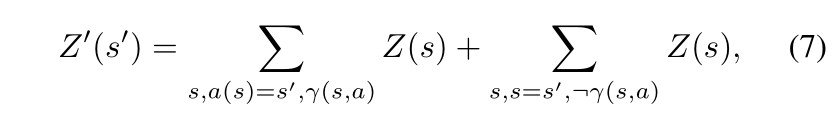
- 第一项:成功应用操作;第二项:失败应用操作;
- 此时接地原子
g正确的概率
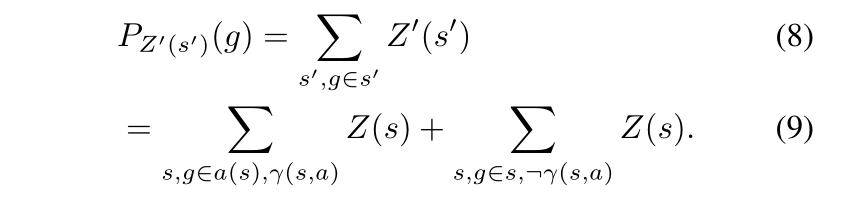
- 考虑接地原子
g的三种类型:
g在a的正影响操作集合中,式子可以改写成:

g在a的负影响操作集合中,式子可以改写成:

g不受a影响,改写成:
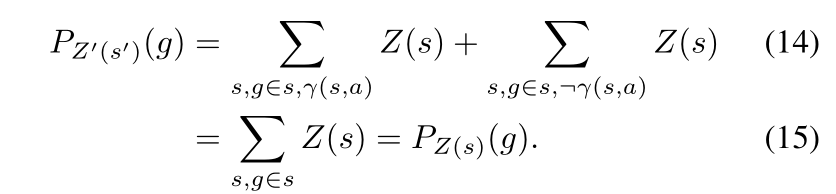
- 尝试应用状态
- 目标满足:
- 目标满足条件不再由符号状态的基态原子的存在来定义,因为目标和当前状态都不是符号状态
- 我们有符号状态的当前分布和目标分布,因此,我们搜索的目标是为了匹配这两个分布
- 通过这些连续的松弛,我们根据状态的分布定义了符号状态上的所有操作(i)到(v)
- 中间省去几十字
- 因此,连续规划器是将符号规划器推广到处理状态分布的方法
D. 学习和推断
- 学习:
- 我们的连续规划器是对符号规划器的连续松弛,不需要训练
- 在完全监督学习下,通过 (2) 训练 SGN
SymbolicState(·):对每一个基于之前用过的行为标注aτ的演示dτt,计算对齐的符号Sτ

- 推断:
- 由于预测
S0和SG只是在状态上的简单分布,有可能在执行行动后模型未能达到目标,在这种情况下,我们更新初始符号化状态S0 = SGN(sc)并重新规划

- 由于预测
- 配图2

- 配图4

结果展示

- 成功率高