一. 异常
1.1.异常的编程模型和基本使用

- 咱得用一用, 解释一下上述的模型
double Div(int a, int b) {
if (b == 0) throw "Zero Div";//抛出一个字符串常量
cout << "要是异常抛出, 自我及其一下全部腰斩, 不会执行" << endl;
return (double)a / (double)b;
}
int main() {
try {
cout << Div(4, 0) << endl;
}
catch (int errid) {
//捕获错误码整形进行处理
cout << "错误编号: " << errid << endl;
}
catch (const char* msg) {
cout << "错误信息" << msg << endl;
}
cout << "异常处理结束了, 继续向后执行呀, 除非异常处理进行了中断" << endl;
return 0;
}
- 分析: 自抛出异常位置开始, 后序代码不再会执行
- 异常处理结束之后, 只要没有终止进程, 继续异常处理完下一条语句执行
1.2. 自定义异常类
class MyException {
public:
MyException(int errid, string errmsg)
: _errid(errid)
, _errmsg(errmsg)
{}
const string& what() const noexcept {
return _errmsg;
}
int GetErrid() const noexcept {
return _errid;
}
private:
int _errid;
string _errmsg;
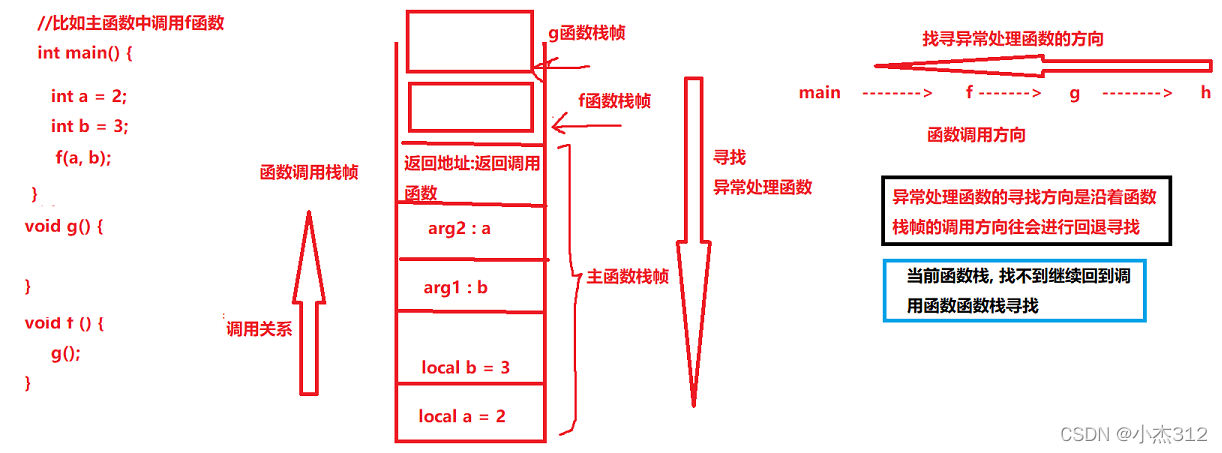
};1.3.异常处理函数的查找过程(沿函数栈往回查找)
class MyException {
public:
MyException(int errid, string errmsg)
: _errid(errid)
, _errmsg(errmsg)
{}
const string& what() const noexcept {
return _errmsg;
}
int GetErrid() const noexcept {
return _errid;
}
private:
int _errid;
string _errmsg;
};
void h() {
throw MyException(0, "沿着函数调用方向往回找异常处理函数");
}
void g() {
try {
h();
}
catch (int errid) {
cout << "g()错误码是: " << errid << endl;
}
}
void f() {
try{
g();
}
catch (const runtime_error& re) {
cout << "f函数中处理函数: " << re.what() << endl;
}
}
int main() {
try {
f();
}
catch (const MyException& e) {
cout << "主函数中处理函数: " << e.what() << endl;
}
catch (...) {// 一般为了异常有个处理会在最后加上他
cout << "主函数中处理函数: " << "捕获到未知异常" << endl;
}
return 0;
}- 结果当然就是沿着函数栈往回找到了主函数中的对应处理函数处理了.....
1.4.异常的重新抛出, 多catch处理(更外层处理)
1.4.1 异常处理过程防止内存泄漏
class Test {
public:
Test() {
//default ctor
}
~Test() {
cout << "dtor" << endl;
}
};
int main() {
try {
//Test t; 栈区对象肯定没问题的
Test* pt = new Test;//堆区呢?
throw 1;
delete pt; //会怎样??? 不会执行, 内存泄漏
}
catch (int errid) {
cout << "我会不会调用析构???" << endl;
cout << errid << endl;
}
return 0;
}
- 结果自然是没有自动调用析构, 咋了???? 说明内存泄漏了,
- 所以内存泄漏也是写异常处理需要特别注意的问题
1.4.2 异常的多catch处理, 内层不处理处理继续 往外throw,
double Div(int a, int b) {
if (b == 0) {
throw MyException(0, "Zero Div");
}
return (double)a / (double)b;
}
void func() {
// 这里可以看到如果发生除0错误抛出异常,另外下面的array没有得到释放。
// 所以这里捕获异常后并不处理异常,异常还是交给外面处理,这里捕获了再
// 重新抛出去。
int* arr = new int[4]{ 0 };
try{
int a, b;
cout << "请输入被除数和除数: " << endl;
cin >> a >> b;
cout << Div(a, b) << endl;
}
catch (...) { //我仅仅处理内存, 至于信息等等继续抛出去其他函数处理
cout << "delete[]" << endl;
delete[] arr;
throw;//继续往外抛出
}
}
int main() {
try {
func();
}
catch (const MyException& e) {
cout << "错误信息: " << e.what() << endl;
}
return 0;
}1.5. 异常类的继承 (多态处理, 基类对象引用子类对象)
- 提出第一个疑问?? 为什么要继承来处理,自己手写不可以吗???
首先自己手写不是不可以, 而是场景不合适, 每个人手写一个异常类, 我们自己是爽了, 可是当需要调用对应的处理函数的时候, 难道每一个地方都需要从新修改一下类名才能调用对应的处理函数吗? 请问你置多态与何地??
可以不可以用基类引用子类对象, 这样调用接口的时候只需要使用基类 调用对应的处理函数就OK了, 我们只需要继承这个基类来进行重写其中需要的处理函数就oK了........
回顾一下多态定义: 传入不同的对象, 调用同一个功能函数会产生不同的效果, 其实也就是子类重写基类虚函数
所以至此, OK了, 其实公司中一般都是会有自己的异常处理机制, 自己的异常处理类, 是有标准的好吧, 我们用的时候就根据情形继承下来重写虚函数就OK了
- eg : 简单的手写一下
class MyException {
public:
MyException(int errid, string errmsg)
: _errid(errid)
, _errmsg(errmsg)
{}
virtual string what() const noexcept {
return _errmsg;
}
virtual int GetErrid() const noexcept {
return _errid;
}
protected:
int _errid;
string _errmsg;
};
//继承的子类
class SqlException : public MyException {
public:
SqlException(int errid = 0, const char* msg = "")
: MyException(errid, msg)
{}
virtual string what() const noexcept {
string tmp("SqlException: ");
tmp += _errmsg;
return tmp;
}
};
class CacheException : public MyException {
public:
CacheException(int errid = 0, const char* msg = "")
: MyException(errid, msg)
{}
virtual string what() const noexcept {
string tmp("CacheException: ");
tmp += _errmsg;
return tmp;
}
};
class HttpServerException : public MyException {
public:
HttpServerException(int errid = 0, const char* msg = "")
: MyException(errid, msg)
{}
virtual string what() const noexcept {
string tmp("HttpServerException: ");
tmp += _errmsg;
return tmp;
}
};二. 介绍部分汇编指令和寄存器, 分析函数调用地汇编过程
2.1. 寄存器 汇编指令基础
- epi : 指令寄存器, 存储的是下一条指令的地址
- esp 和 ebp 都是指针寄存器
- esp : 栈顶寄存器, 指向函数栈栈顶, 栈指针
- ebp : 栈底寄存器, 指向栈底, 帧指针
- push : 数据入函数栈, 修改 esp
- pop : 数据出函数栈, 修改 esp
- sub : 减法操作
- add : 加法操作
- call : 函数调用
- jump : 进入调用函数
- ret : 函数调用结束后的返回地址, 返回外层调用函数
- move : 数据转移, 栈顶和栈底改变


2.2. 函数调用栈的汇编指令部分刨析 (VS2019)
- 参数反向push入栈
- call 调用函数, 进去的时候自动push ret地址 (进入被调用函数)
- 函数调用结束的时候ret 之前push的ret地址 (返回调用函数)
- 清理参数, 看处理机制, 有些是被调用函数自己清理, 有些是调用函数清理

三. 智能指针由浅到深的实现
3.1智能指针 RAII技术简介
- 首先搞清楚第一件事情, 为什么我们需要 智能指针, 智能指针是一个针对指针所指向的资源回收和使用管理的一个类。
- 内存泄漏: 什么叫做内存泄漏,内存泄漏指的是我们失去了对于一段内存的掌控, 但是在失去掌控之前并未将其释放掉..... 操作系统将内存从堆区分配我们的进程, 如果我们不主动将其delete掉, 在进程运行过程中,操作系统便无法将其分配给其他进程使用, 然后原本分配到这个内存的主人在使用完后没有将其delete, 这块内存也没办法分配出去, 于是就相当于是内存泄漏了
- 内存泄漏的危害:长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现内存泄漏会 导致响应越来越慢,最终卡死。
- RAII思想:RAII(Resource Acquisition Is Initialization)是一种利用对象生命周期来控制程序资源(如内存、文件句 柄、网络连接、互斥量等等)的简单技术。
- 于是智能指针便出现了, 利用智能指针定义对象的生命周期是有限的, 智能指针定义成栈区对象, 函数结束时候自动会调用析构函数, 自然就会释放资源了.... (向避免死锁的unique_lock 此处的智能指针都是这个思想)
3.2 智能指针最基本框架模型
存在构造析构和基本的指针操作就OK了, 这个是一个大体的框架模型, 是全部都不需要具有的
template<class T >
class SmartPtr {
public:
SmartPtr(T* ptr)
: _ptr(ptr)
{}
~SmartPtr() {
if (_ptr)
delete _ptr;
}
T& operator() {
return *_ptr;
}
T* operator() {
return _ptr;
}
private:
T* _ptr;
};3.3 4种智能指针特性分析
- auto_ptr : 四种智能指针之一, 问题所在是进行拷贝构造, 赋值之后会出现指针悬空的问题, 如果对于悬空指针进行操作会报错
- unique_ptr : 为了解决auto拷贝和赋值之后的指针悬空的问题, 直接的将拷贝构造和赋值重载进行了一个禁止掉了
- shared_ptr : 还是解决auto拷贝和赋值之后的指针悬空的问题, 只不过它不是通过禁止拷贝和赋值重载的禁止实现的, 而是通过一种叫做引用技术的方式来避免指针的悬空, 不论是赋值, 还是拷贝, 只是将引用计数 + 1 操作, 这样拷贝之后, 原有的指针就不会因为转移给拷贝本被悬空, 而是和拷贝本一起共享同一地址, 同一内存资源。
- 注意: 针对共享的资源的操作一定要注意保护, 避免函数的重入的问题, 利用互斥锁来保证一次只有一个线程对于共享的临界资源进行写入的操作. 所以向引用计数的 + 和 - 操作全部都是需要使用锁保护的
- weak_ptr : 为了解决循环引用的问题, 循环引用, 也就是相互之间都有引用计数关系, 相互之间的释放真正的delete 受到了限制。。。
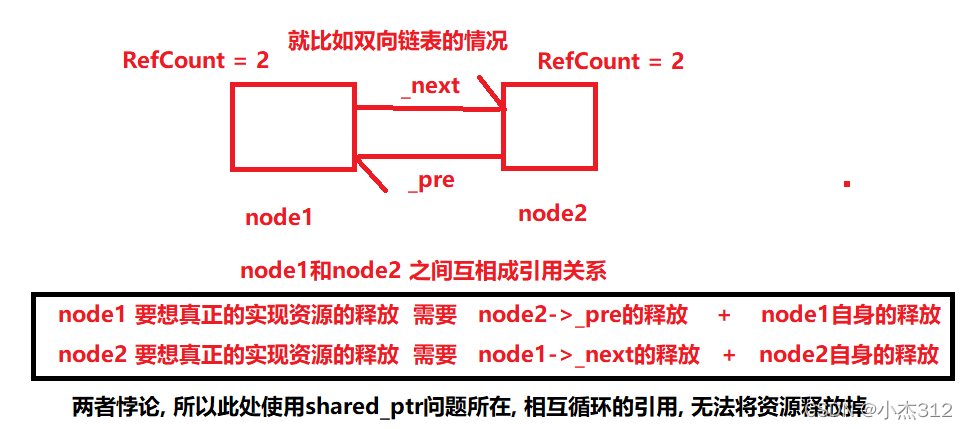
- shared_ptr解决循环引用的原理: 在引用计数的时候将 _pre 和 _next指针修改成weak_ptr智能指针即可
- 原理就是,node1->_next = node2;和node2->_prev = node1;时weak_ptr的_next和_prev不会增加 node1和node2的引用计数。
struct ListNode
{
int _data;
weak_ptr<ListNode> _prev;
weak_ptr<ListNode> _next;
~ListNode() { cout << "~ListNode()" << endl; }
};3.4 3种智能指针模拟实现代码
auto_ptr
namespace tyj {
template<class T>
class auto_ptr {
public:
auto_ptr(T* ptr)
: _ptr(ptr)
{}
auto_ptr(auto_ptr<T>& ap) {
_ptr = ap._ptr;//转移资源
ap._ptr = nullptr;//原指针悬空
}
auto_ptr<T>& operator=(auto_ptr<T>& ap) {
if (this != &ap) {
if (_ptr)
delete _ptr;//清理现有资源
_ptr = ap._ptr;
ap._ptr = nullptr;
}
}
~auto_ptr() {
if (_ptr)
delete _ptr;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
private:
T* _ptr;
};
}
int main() {
int* pint = new int[4]{ 0 };
tyj::auto_ptr<int> smartp(pint);
*smartp = 1;
cout << *smartp << endl;
tyj::auto_ptr<int> smartp2(smartp);
//*smartp = 1;
//cout << *smartp << endl;
//smartp 不可以再进行写入了, 已经悬空了
return 0;
}
unique_ptr : 直接禁止掉拷贝构造和赋值重载
namespace tyj {
template<class T>
class unique_ptr {
public:
unique_ptr(T* ptr = nullptr)
: _ptr(ptr)
{}
~unique_ptr() {
if (_ptr)
delete _ptr;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
private:
T* _ptr;
unique_ptr(unique_ptr<T>& up) = delete; //禁止掉构造函数
unique_ptr<T>& operator=(unique_ptr<T>& up) = delete;//禁止掉复制重载
};
}
shared_ptr : 利用引用计数的方式: 因为引用计数算是临界资源, 所以对其的操作必须通过互斥量进行保护, 进行原子操作。。。 (保护临界资源)
namespace tyj {
template <class T>
class shared_ptr {
public:
shared_ptr(T* ptr = nullptr)
: _ptr(ptr)
, _pmtx(new mutex)
, _pRefCount(new int(1))
{}
~shared_ptr() {
Release(); //释放资源
}
//增加引用计数, 赋值拷贝
shared_ptr(const shared_ptr<T>& sp)
: _ptr(sp._ptr)
, _pRefCount(sp._pRefCount)
, _pmtx(sp._pmtx) {
AddRefCount();//增加引用计数
}
shared_ptr<T>& operator=(shared_ptr<T>& sp) {
if (this != &sp) {
Release();//先释放可能持有的资源
_ptr = sp._ptr;
_pmtx = sp._pmtx;
_pRefCount = sp._pRefCount;
AddRefCount();//增加引用计数
}
return *this;
}
int UseCount() {
return *_pRefCount;
}
T* Get() {
return _ptr;
}
T& operator*() {
return *_ptr;
}
T* operator->() {
return _ptr;
}
private:
void AddRefCount() {//增加引用计数
_pmtx->lock();
++(*_pRefCount);
_pmtx->unlock();
}
void Release() {//释放资源, 减去一次引用计数
bool deleteFlag = 0;//判断是否需要释放资源, 真正的delete
_pmtx->lock();
if (--(*_pRefCount) == 0) {
delete _ptr;
delete _pRefCount;
deleteFlag = 1;
}
_pmtx->unlock();
if (deleteFlag) {
delete _pmtx;//最后释放锁
}
}
private:
T* _ptr;//指向管理资源的指针
int* _pRefCount;//引用计数指针
mutex* _pmtx;//互斥锁
};
}
四. 总结
- 本文先介绍了异常的基本模型, 然后提出了异常学习的重点
- 1. try {保护代码}catch(捕获类型) {异常处理逻辑块}
- 2,可以自定义异常类, 可以继承标准类然后重写其中的处理函数, 和异常信息函数
- 3, 异常的处理函数是沿着函数栈往回寻找的, 是沿着函数调用的反方向往回找的, 在被调用函数中找不到处理函数就回到调用函数中寻找处理函数
- 4. 异常类的继承本质原因: 为了利用基类接收所有的派生类对象, 然后调用相同的函数接口, 实现不同的调用结果和不同的处理机制.... 统一使用者的调用接口和类 (使用者只需要使用基类对象引用接收, 掉函数就OK了, 至于具体传入的是什么对象不需要管)
- 5.寄存器和 汇编指令的学习, esp : 栈顶寄存器 ebp : 栈底寄存器 epi : 指令寄存器等等
- 6. 四种智能指针, 智能指针的迭代进化是有原因的:
- auto_ptr 问题是 拷贝或者赋值之后,本体指针会被悬空掉. unique_ptr为了解决指针悬空的问题, 直接的禁止掉了赋值重载和拷贝构造, shared_ptr 解决悬空的方式是加入引用计数, weak_ptr 针对 shared_ptr 的 循环引用 , 相互之间引用, 相互制约, 无法完全释放资源的问题而产生了, 相比shared_ptr 底层原理就是在循环相互引用的时候不进行引用计数的 ++ 来实现的