文章摘要提出要解决Video representation learning问题现存的方法存在两个局限:
1)仅仅局限在一个任务,忽视了不同任务特征的补充,因此导致了结果的次优。
2)高额的计算和记忆消耗阻碍了在现实情境的应用。
而本篇文章提出了一个基于图形的提取框架来处理这些问题:
1)提出了 logits graph、 representation graph 来从多个自我监督任务中迁移知识
a)logits graph 通过解决多分布联合匹配问题来提取 classifier-level knowledge
b)representation graph 解决不同特征的异质性挑战 从成对集成的(ensembled)representation(这个词没想好怎么翻 译)中提取内部特征知识
2)采用 teacher-student的框架可以有效地减少从teachers学习到的知识冗余,让更轻量级的student模型更有效的解决分类任务。
总结:文章的方法不仅学到更好的video representation而且模型更加简洁。
self-supervised task
self-supervised methods in video需要掌握的方法:
1.frame sorting(帧排序) π S
2. learning from egomotion (运动学习?) π M
3.tracking(跟踪)π T
4. learning from frame predicting(学习帧预测) π P
作者使用PredNet作为视觉编码器
(这部分感觉还涉及到一些GAN的思想,作者将π P(预测video的随后帧)称为生成的部分,剩余三部分叫做判别部分)
下面是文章的框架图:
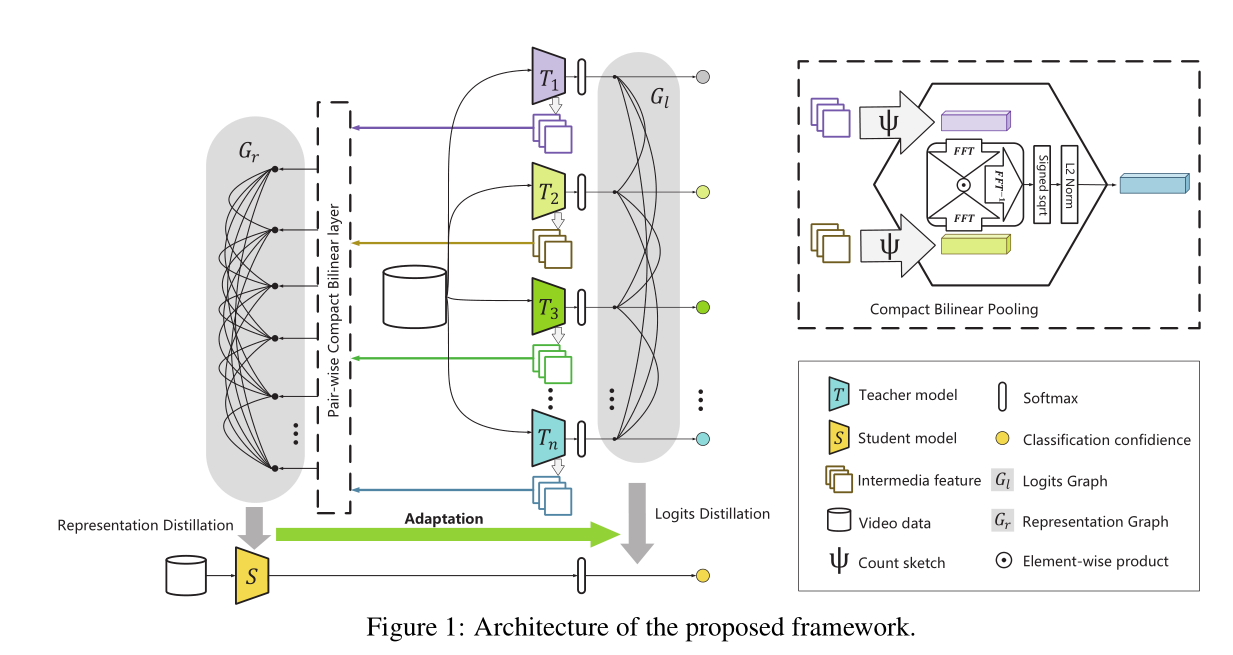
具体的算法公式内容这里就不表了,直接进入文章的#5 experiment部分。
本文使用了VGG-19作为基础来训练π S 、π M 、 π T ,使用PredNet作为监督模型来从 π P学习。
为了使得模型更符合文章的需求,作者将vgg-19中的conv1的通道扩展到96,conv2的通道扩展到128,并将conv1中的filter尺寸改到11*11
T S 模型根据在第一个全连接层排序的成对的所有帧 连接卷积特征
T M由base-CNN(BCNN)和top-CNN(TCNN)组成,在两帧之间TCNN利用BCNN的输出对进行转移分析。
T T 来判断一个三元组的相似度。
T P 是一个convLSTM模型,每层包括 representation module (R), target module (A), prediction module ( ˆ A) 、error term (E)
模型是使用pytorch跑的,具体的模型参数设置就不贴了,原文#5.2这一节都有。
最终的结果:


结果显示:本文的效果是最好的。
最终结论:
1)logits distribution knowledge 作为一个多分布联合匹配问题被证明比之前的方法更有效
2)internal feature knowledge 通过紧凑的双线性pooling来成对集成不同的特征
懒得总结了,把最后一段贴上来算了,
