【In-Context Learning】Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
In-Context Learning(ICL)是最近比较火热的方向,其主要针对超大规模模型(例如1750B参数量的GPT-3模型),在只提供少量标注样本作为提示的前提下,即可以实现很惊艳的效果。本文主要探索In-Context Learning的影响因素有哪些。
一、In-Context Learning介绍
大规模语言模型在一系列下游任务上获得最好效果,虽然fine-tuning可以将预训练知识迁移到下游任务,但其需要调整所有参数。最近in-context learning则只需要给定少量标注样本做演示,即可实现免参数调整。
LM learns a new task via inference alone by conditioning on a concatenation of the training data as demonstrations, without any gradient updates.
ICL的示例如下所示:

最近有一系列工作致力于提升ICL,包括:
- 挑选in-context demonstration example;
- 对in-context learning objective进行meta-training;
- 添加任务的指令并进行微调,即instruction-tuning;
In-context learning has been the focus of significant study since its introduction. Prior work proposes better ways of formulating the problem (Zhao et al., 2021; Holtzman et al., 2021; Min et al., 2021a), better ways of choosing labeled examples for the demonstrations (Liu et al., 2021; Lu et al., 2021; Rubin et al., 2021), meta- training with an explicit in-context learning objective (Chen et al., 2021; Min et al., 2021b), and learning to follow instructions as a variant of in-context learning (Mishra et al., 2021b; Efrat and Levy, 2020; Wei et al., 2022; Sanh et al., 2022). At the same time, some work reports brittleness and over-sensitivity for in-context learning (Lu et al., 2021; Zhao et al., 2021; Mishra et al., 2021a).
然而很少有工作探索为什么in-context learning可以有效。最近有工作尝试通过理论分析。本文则通过经验分析(实验分析)来探索此问题。
This paper is the first that provides an empirical analysis that investigates why in-context learning achieves performance gains over zero-shot inference
二、实验探索ICL的影响因素
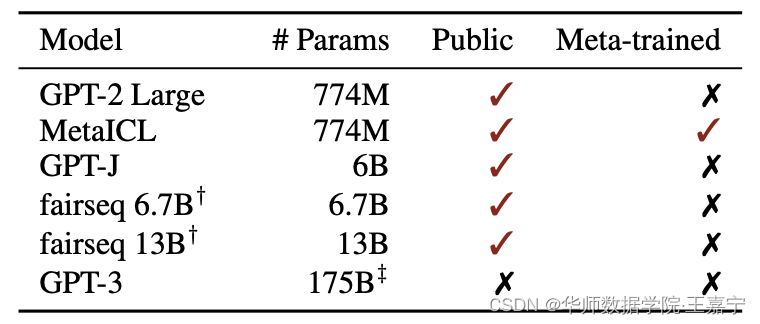
挑选了6个主要的模型进行测试,模型的各种配置如下所示:
实验挑选了26个数据集,如下所示:

本文主要挑选了可能的四个影响因素,如下所示:
- The Input-Output Mapping:即所挑选的In-Context Example的Input x i x_i xi 和Output y i y_i yi 是否一致,换句话说即标签 y i y_i yi 是否正确;
- The Distribution of the Input Text:输入的 k k k 文本 x 1 , ⋯ , x k x_1, \cdots, x_k x1,⋯,xk 是否来自于同一个分布;
- The Label Space:所挑选的 k k k 个In-Context Example中,标签 y i , ⋯ , y k y_i, \cdots, y_k yi,⋯,yk 是否来自同一个标签空间;
- The Format:Input-Output的模式,即模板。
探索1:Gold labels vs. random labels
第一个探索的因素时Input-Output Mapping,即标签是否正确。选择三个对比baseline:
- No demonstration:没有demonstration example;
- Demonstration w/ glod labels:标准的in-context learning;
- Demonstration w/ random labels:in-context example的标签被随机替换为错误的标签;
实验对比如下图:
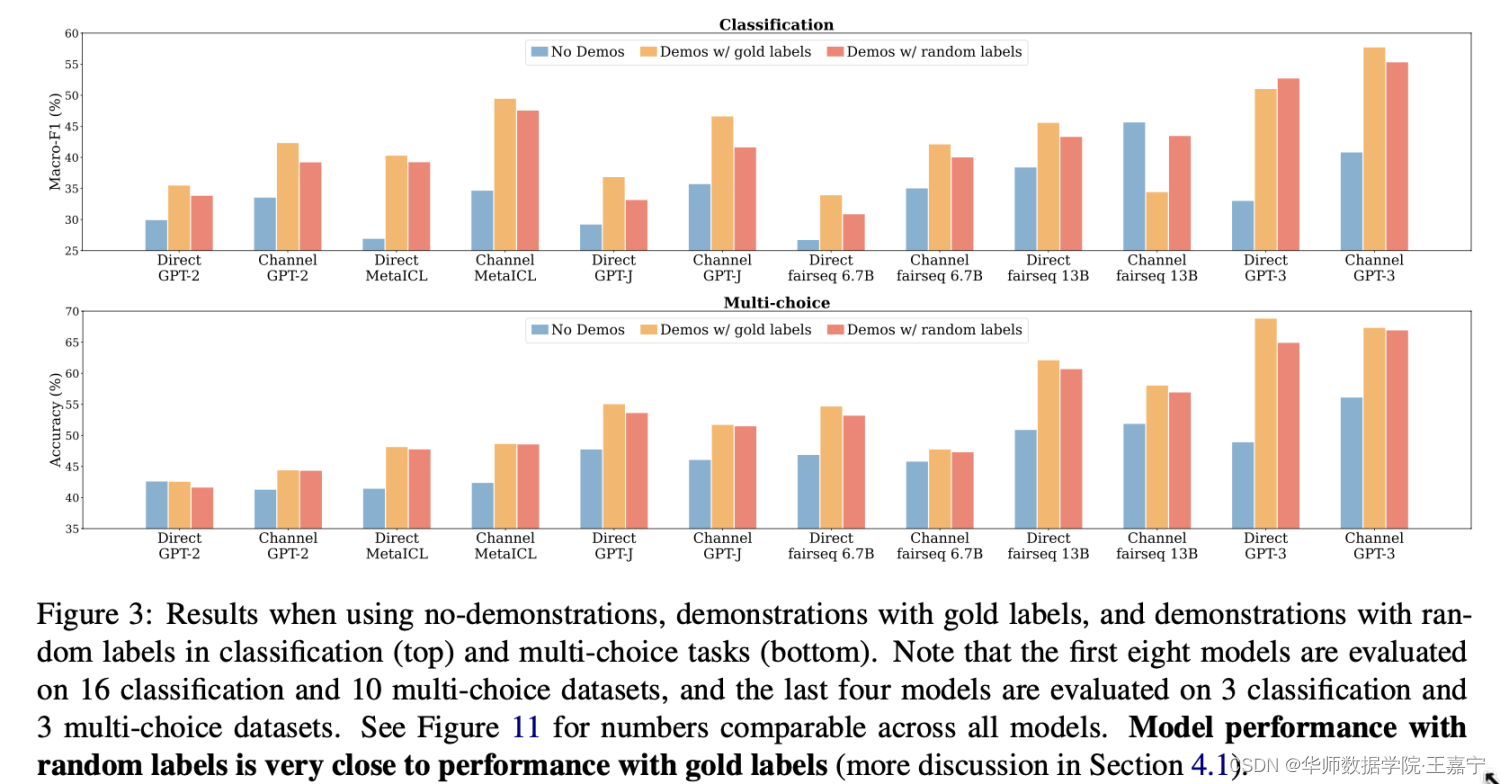
可以发现如下几个现象:
- 使用demonstration比不使用的效果好。说明demonstration example确实可以提升性能;
- random label对模型性能的破坏并不是很大。说明in-context learning更多的是去学习task-specific的format,而不是input-output mapping
- MetaICL是包含对in-context learning objective进行meta-training的方法,但实验结果也表明不论是否在存在模型预热,random label对效果影响很小。说明在meta-training时,模型也不会过多关注demonstration example的input-output mapping,而是关注其他方面。
meta-training with an explicit in-context learning objective actually en- courages the model to essentially ignore the input- label mapping and exploit other components of the demonstrations
下面进一步探索错误标签所占的比重对预测影响的情况(Does the number of correct labels matter?)
To further examine the impact of correctness of la- bels in the demonstrations, we conduct an ablation study by varying the number of correct labels in the demonstrations.
假设有 k k k 个样本,那么正确标签样本占比为 a a a %,则有 k × a / 100 k × a/100 k×a/100 正确样本, k × ( 1 − a / 100 ) k × (1 − a/100) k×(1−a/100) 错误样本,demonstration构建算法如下图:

实验结果如下图所示:

- 正确样本数量对模型性能几乎没有什么影响;
- 宁愿使用错误的标签样本,也比完全不使用demonstration要好;
那么这个结论在其他场景下是否也成立呢?本文进行了下面两个扩展实验。
(1)验证不同 k k k 的选择对上述两个结论的影响情况。下面实验说明不论挑选多少个In-Context Example,Input-Output Mapping的影响都不大。
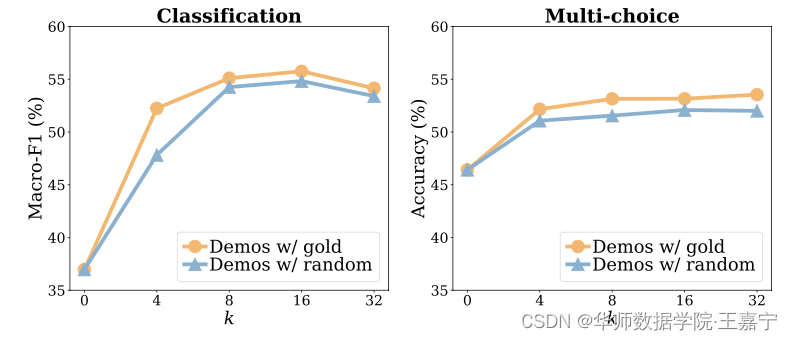
- 使用demonstration example依然比不使用的效果好;
- 使用random label在不同k的条件下效果下降很小;
- 有趣的发现,随着K增大,并非效果也是持续增大的,这与标准fine-tune事实不同。
This is in contrast with typical supervised training where model performance rapidly increases as k increases, especially when k is small.
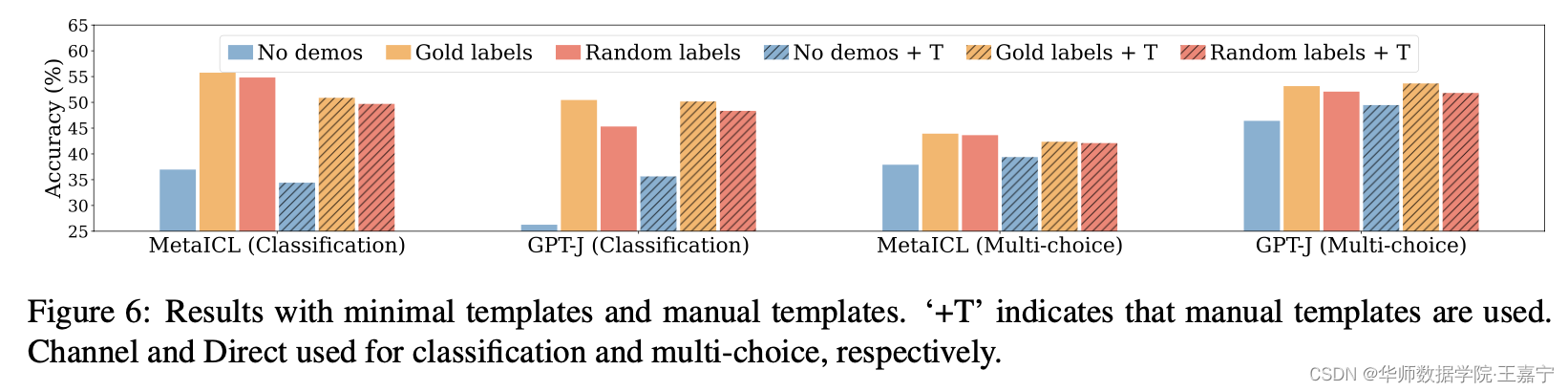
(2)不同的模板对上述两个结论的影响情况。当额外添加template时,部分task效果回提升,有些则下降,但是No demonstration、Glod labels和Random Labels的效果对比现象依然与上面一样,说明不论是什么模板,Input-Output Mapping的影响依然不大。
探索2:Impact of the distribution of the input text
本部分探索In-Context Example中输入部分 x i x_i xi 的分布是否存在影响。即如果挑选的这些In-Context Example来自不同的domain会如何。
给定 k k k 个demonstration sentence,这 k k k 个句子是从别的task的语料(不同于当前task) 随机采样得到的,而标签空间和demonstration的format保持不变。此时,输入句子的分布是与当前task不同的。
例如在对SST-2进行测试时,挑选的In-Context Example来自于MR、CR等任务,但是他们的标签体系都是二分类情感分析体系(Positive和Negative)
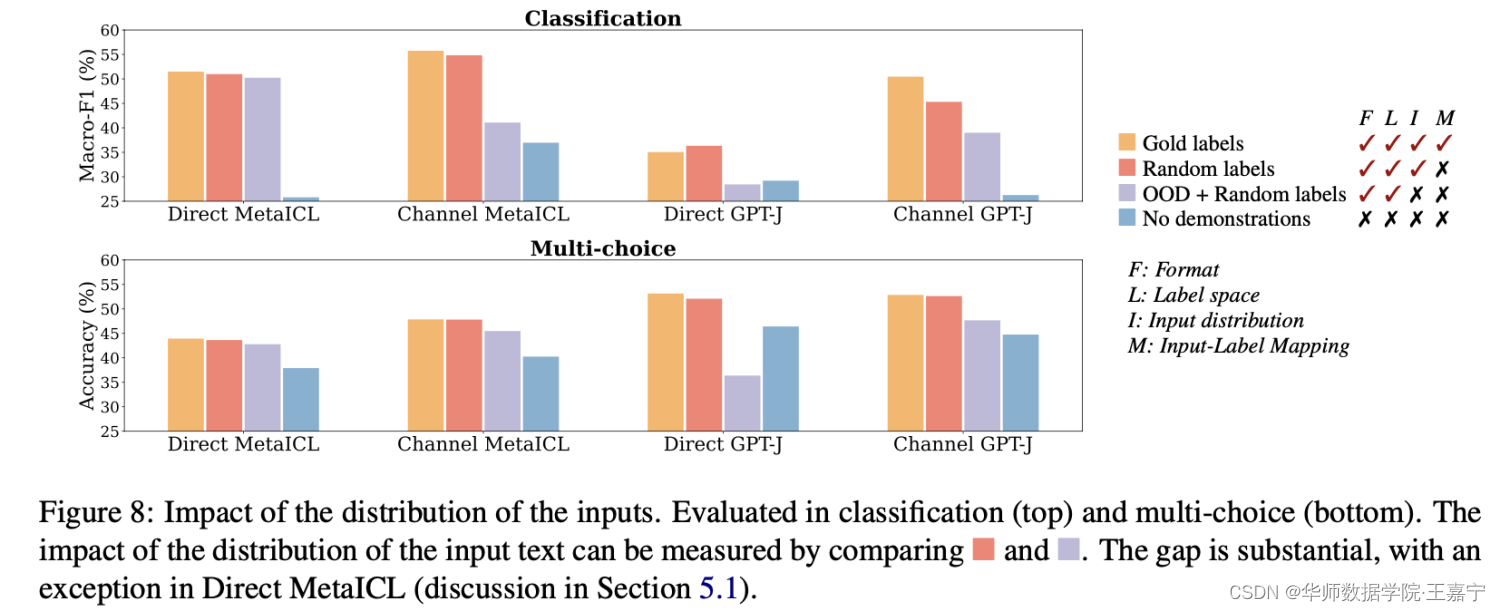
结论:
- 观察红色(Input都是同一个数据集分布的)和紫色(Input来自不同于当前任务的数据集分布)两个图,可以发现大多数任务上差异很大。说明选择不同分布的Input对ICL的性能影响很大。
Using out-of-distribution inputs instead of the inputs from the training data significantly drops the performance when Channel MetaICL, Direct GPT-J or Channel GPT-J are used, both in classification and multi-choice, by 3–16% in absolute.
This suggests that in-distribution inputs in the demonstrations substantially contribute to performance gains
探索3:Impact of the label space
本部分探索标签 y i y_i yi 的分布是否有影响。例如测试样本为SST-2情感分析,但是挑选的In-Context Example的标签来自是其他类型的任务,例如主题分类、QA等。为了方便实验,我们使用Random Labels来表示。
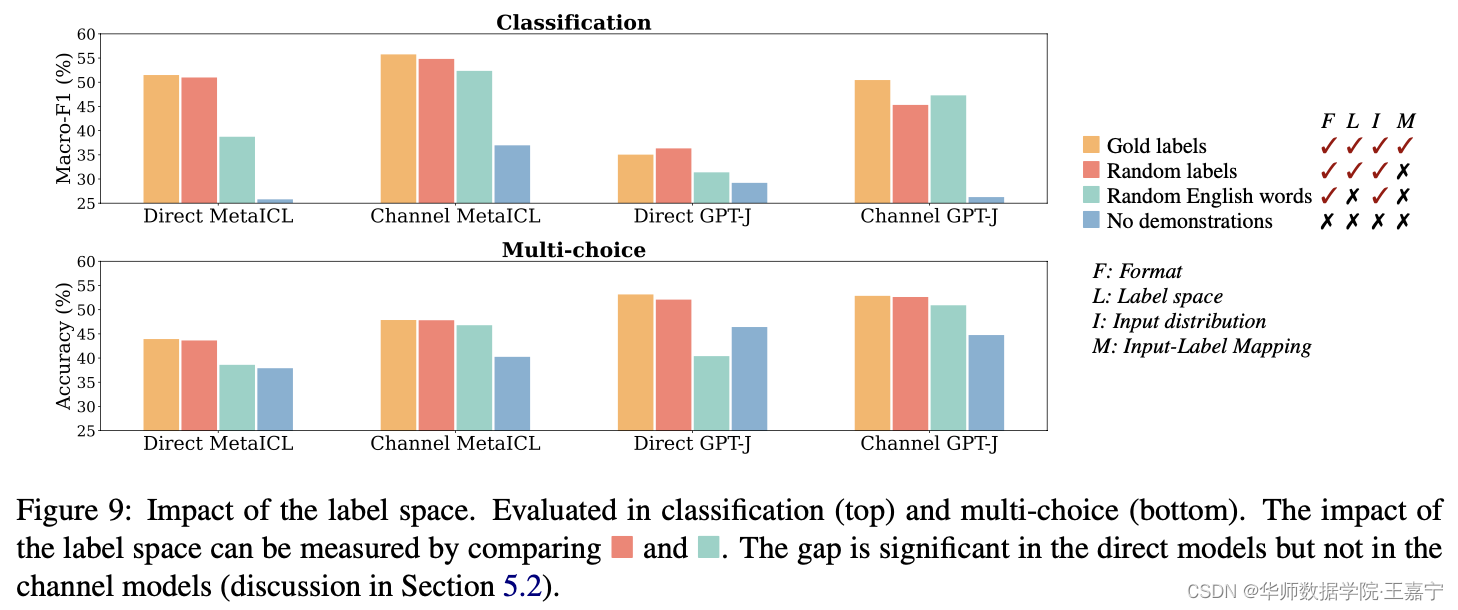
如上图,结论如下:
- Glod labels比Random Labels高,但是差异非常小,说明标签是否来自于同一个分布并不重要;
这一结论比较反直觉,因此遭到另一篇论文的质疑:
Ground-Truth Labels Matter- A Deeper Look into Input-Label Demonstrations(EMNLP 2022)
该论文认为,Input-Output Mapping是很重要的,因此Label的正确与否也会对一些任务存在影响。
博主综合两篇论文,认为Input-Output Mapping(即Label的分布)是存在一定影响的,只是在一些简单的任务上体现不出,这取决于任务的类型,当然也取决于模型本身。
探索4:Impact of the use of input-label pairing
修改demonstration的模式(format),包括:
- 只有input text没有label:此时所有input text进行拼接;
- 只有label没有input text:此时所有label进行拼接;
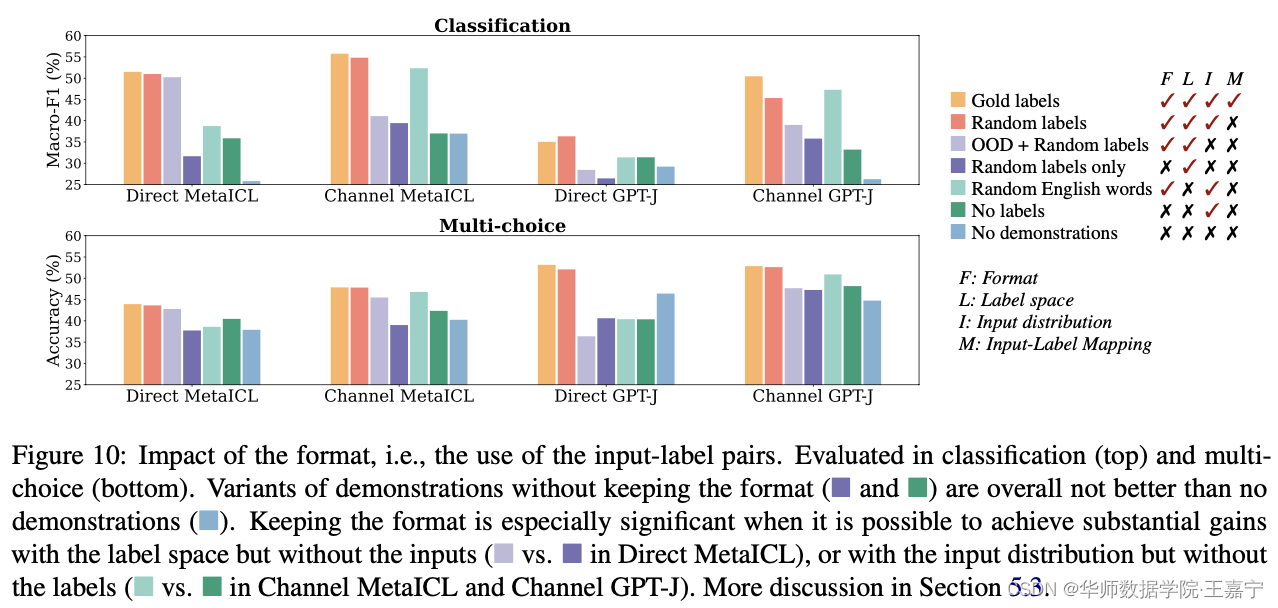
结论:
- 去掉format后,发现与no demonstrate相比没有明显的提升,说明format是很重要的(即label和input text 缺一不可);
- 对比之前的结论,可以推论出,宁愿label是错误的,也不能没有。