随着时代的发展,信息以指数形式增长,为了能够从海量信息中迅速找到所需要的信息,就需要对信息进行分类,因此自动文本分类技术应运而生。文本分类其任务是将自然语言文本根据其内容分为预先定义的两类或者多类。文本分类的应用领域极为广泛,垃圾邮件分类就是其中一个很重要的应用。
通常我们将“广告促销”等营销邮件判定成垃圾邮件。例如\垃圾邮件分类任务语料\train\Data\001\路径下的067邮件:
< TEXT >
萬泰商銀特別專案貸款
(非 @指成金信用貸款,即使非上班族也能申貸)
免保人,免擔保品,快速核貸 @日撥款
專案利率最低可達1.48%(由專案行員審核)
~最高金額可達200萬~
由銀行專員為您親自服務,親切可靠
歡迎您回函洽詢相關業務試算您的信貸額度--進入填表
< /TEXT >
1 数据分析及处理
1.1 数据分析
本次共使用有50000封邮件样本,通过对这些样本大致的统计分析,发现约有48000个样本具有类似的格式。
从语言上分类,样本邮件有汉语、英语和俄语三个语种。从分类标签上看,样本邮件存在垃圾邮件和非垃圾邮件两种标签,其中,前者的数量明显小于后者。
从内容上看,垃圾邮件过滤可以看成一个“二类”问题:垃圾邮件类和合法邮件类。因此, 各种分类方法可以用于垃圾邮件的过滤。然而,垃圾邮件过滤是一个特定领域的分类问题,它 至少在以下几个方面与一般的分类存在不同:
一、通常认为,用户宁愿接收更多的垃圾邮件,也不能接受将合法邮件错判成垃圾邮件。 因此,与通常的分类方法相比,垃圾邮件过滤更重视正确率;
二、垃圾邮件过滤实现的环境通常都有较高的性能要求,因此,要求垃圾邮件过滤的方法 不仅要重视实现的效果,也要重视实现的效率;
垃圾邮件过滤中的类别有别于通常分类中的类别,一方面,垃圾邮件、合法邮件在语义 上并不象通常分类中的类别(如体育、军事等等)能够被人理解;另一方面垃圾邮件的类别定义 可能会因人而异,也可能会随着时间而改变。【1】
1.2 数据处理
通过对数据集的分析,我根据其特殊性,进行了一些预处理。
1.2.1清洗数据集
数据决定了模型的上限,在实际应用中对数据进行清洗是非常必要的。常用的清洗数据的方法有:去掉停用词、去掉URL、去掉HTML标签、去掉特殊符号、去掉表情符号、去掉长重复字、将缩写补全、去掉单字、提取词干等等。
在约48000封符合规范的邮件中,正文部分前后会有邮件的属性信息。于是对文本进行了过滤,删去了多余的格式信息。
1.2.2分词
因为样本邮件多为完整的句段,故需要对样本文本进行分词处理。当前在中英文分词领域,已经存在较好且经过多人测试使用过的成果,其中,由百度工程师Sun Junyi开发的开源库jieba就是一款优秀的 Python 第三方中文分词库,可以为中英文及其混合文本提供便携的分词工作。于是这里直接采用jieba库对每一封样本邮件进行分词,在此对Sun Junyi先生表示感谢。
1.3 构造数据集
在对所有邮件进行分词之后,我便使用获得的所有结果构造语料库。考虑到获得的结果过多,构造生成的语料库过大,耗费不必要的时间,我将数据集缩减到2400封,并创建词袋模型(Bag of words),从而避免了大量的的时间开销。
词袋模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。
此时创建的词汇表长度为65732。
1.4 尝试使用其他特征构造数据集
考虑到词袋模型使用中的一些局限性,我尝试使用TF-IDF(词频-逆文档频率)进行构造数据集。逆文档频率的含义是如果某个词或短语具有良好的类别区分能力,并且在其它样本中很少出现,则认为这个词或者短语比较适合用于分类。即如果一个词在某一个文档中出现过,但在其它文章中没有出现过,则将这个词的权重增大。反之如果这个词大量出现在所有样本中,则表示这个词对于分类的贡献不是特别大,所以降低其权重。计算逆文档频率一般采用下图公式:
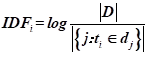
TF-IDF就是词频和逆文档频率的乘积。【2】
实际操作中使用TF-IDF进行构造数据集主要有两种实现方式:
Ⅰ:直接利用TfidfTransformer对词频矩阵进行计算,得出TF-IDF矩阵;
Ⅱ:利用TfidfVectorizer对data_train直接操作,得出TF-IDF矩阵。
两种方法所得出的结果是一样的。但实际操作中发现,引入TF-IDF特征后效果仅仅有一点点波动,与采用词袋模型时并没有显著区别。
2 采用的方法
2.1 机器学习
2.1.1 朴素贝叶斯
朴素贝叶斯法,简称NB算法,是贝叶斯决策理论的一部分,朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。
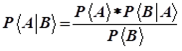
由两个事件推广到无穷多个事件:
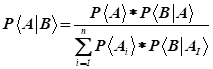
在对垃圾邮件的分类中,根据邮件中出现的词语判定是否为垃圾邮件;特征条件独立就是指邮件中不同的词出现的概率相互之间是不受影响的,样本的属性之间是相互独立的,即某一个词的出现不会影响另一个词的出现。
通过计算词向量分布对应各类别的条件概率,可以计算出该分布的最大可能性对应的类别从而进行估计。
2.1.2 高斯贝叶斯
对于连续变量,可使用高斯朴素贝叶斯。设在yi的条件下,x服从正态分布。根据正态分布的概率密度函数即可计算出P(x|yi),公式如下:
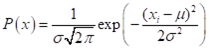
如果x是多维的数据,那么我们可以假设P(x1|yi),P(x2|yi)…P(xn|yi)对应的事件是彼此独立的,这些值连乘在一起得到P(x|yi)。【3】该实验的词向量虽然不是连续变量,但仍可尝试使用高斯贝叶斯。
2.1.3 支持向量机
支持向量机(SVM)是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,分割的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。即求解样本中:
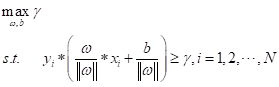
在SVM中,还有软间隔的概念。这是由于数据集中离群点的出现而导致模型泛化性差的问题,于是需要一个松弛变量的引入来提高泛化性能。即将原最优化问题转换成:
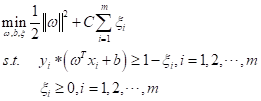
其中C>0为惩罚参数,即对误差的容忍度,是软间隔非常重要的参数。C越大,对离群点的容忍度越小,只有较少的点能跨过间隔边界,趋向于过拟合的模型会变得复杂。反之,C越小,则对离群点的容忍度越大,较多的点会跨过间隔边界,最终形成的模型较为平滑。[4]
在该次实验中,会对C的不同取值进行测试。
当使用TF-IDF构造的数据集运用SVM时,加权向量机给训练样本加以类别权值,体现不同类别的重要性,例如通过增加邮件常用词类别权重,可以有效地减少该类别中被错分的样本数.提高了每封邮件被正确分类可能性,从而提高了分类精度。
2.1.4 随机森林
随机森林(RF)由多棵决策树构成,且森林中的每一棵决策树之间没有关联,模型的最终输出由森林中的每一棵决策树共同决定。
处理分类问题时,对于测试样本,森林中每棵决策树会给出最终类别,最后综合考虑森林内每一棵决策树的输出类别,以投票方式来决定测试样本的类别。
随机森林的随机性体现在两个方面:
Ⅰ:样本的随机性,从训练集中随机抽取一定数量的样本,作为每颗决策树的根节点样本;
Ⅱ:属性的随机性,在建立每颗决策树时,随机抽取一定数量的候选属性,从中选择最合适的属性作为分裂节点。
2. 2 深度学习
2.2.1 GloVe和LSTM
GloVe(Global Vectors)模型是将基于奇异值分解(SVD)的LSA算法和word2vec算法这两种算法的特征合并到一起的而产生的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征。GloVe会考虑全局特征。相比Word2Vec考虑上下文来看,似乎效果会更好一点
为了简化操作,采用顺序方式Sequential来搭建模型。利用Sequential搭建模型的优点是便捷,但受限于网络类型,不支持自定义网络层。
3 数据分析
3.1 所采用的模型
分别对词袋模型和TF-IDF构造生成的数据集采用以下几种方法进行分类处理:
Ⅰ: 多项式朴素贝叶斯分类器;高斯朴素贝叶斯分类器
Ⅱ: C=0.1到C=0.9的线性SVM分类器
Ⅲ: 随机森林
Ⅳ: GloVe和LSTM
3.2 实验数据分析
3.2.1词袋模型数据集训练结果
表1:词袋模型分类准确率
| 分类器类型 | 准确率/% |
|---|---|
| 多项式朴素贝叶斯 | 92.27 |
| 高斯朴素贝叶斯 | 96.46 |
| 线性SVM C=0.1 | 96.18 |
| 线性SVM C=0.2 | 95.54 |
| 线性SVM C=0.3 | 95.35 |
| 线性SVM C=0.4 | 95.23 |
| 线性SVM C=0.5 | 95.10 |
| 线性SVM C=0.6 | 95.10 |
| 线性SVM C=0.7 | 94.96 |
| 线性SVM C=0.8 | 94.96 |
| 线性SVM C=0.9 | 94.96 |
| 随机森林 | 77.07 |
| GloVe和LSTM | 95.17 |
图1:词袋模型分类准确率对比图

3.2.2 TF-IDF数据集训练结果
表2:TF-IDF数据集分类准确率
| 分类器类型 | 准确率/% |
|---|---|
| 多项式朴素贝叶斯 | 92.24 |
| 高斯朴素贝叶斯 | 96.48 |
| 线性SVM C=0.1 | 96.21 |
| 线性SVM C=0.2 | 95.58 |
| 线性SVM C=0.3 | 95.42 |
| 线性SVM C=0.4 | 95.29 |
| 线性SVM C=0.5 | 95.16 |
| 线性SVM C=0.6 | 95.16 |
| 线性SVM C=0.7 | 94.99 |
| 线性SVM C=0.8 | 94.99 |
| 线性SVM C=0.9 | 94.99 |
| 随机森林 | 77.05 |
| GloVe和LSTM | 95.25 |
图2:TF-IDF数据集分类准确率对比图

4 实验总结
4.1 数据集获取
该次实验中,数据集的建立在一开始选用了经典的离散性词向量——词袋模型。是文本表示中非常经典的一个模型,在词嵌入这个后浪出现之前,词袋模型一直是文本处理里最常用到的一种表示方式,优点在于简单易读。但不可避免的,词袋模型还有着很多缺陷:
Ⅰ:词袋模型人为地打乱了不同语言元素之间的顺序,并且忽略词间的相关关系,认为词与词之间是独立存在的。忽略了词在文本中的位置信息,而这些信息在现实中往往起决定性作用。
Ⅱ:词袋模型生成的向量是非常稀疏的。对于一个数据集,词袋模型需要考虑成千上万甚至十几万的词,同时把特征空间的每个维度对应一个词。这个特征空间的维度是非常庞大臃肿的。虽然词袋模型形成的向量维度很大,但很难很好地利用这种高维度。
Ⅲ:普通的词袋模型会耗费大量的资源在记录一些对分类不怎么起作用的常用词上,例如: “的”、“是”、“and”等,这些词汇大量出现在所有样本中,对于分类的贡献不是特别大,占用了不必要的资源和权重。
对于缺陷Ⅲ,我启用了TF-IDF进行构造数据集。通过词频和逆文档频率的乘积,对词进行权重的分配,增强非常用词对样本分类的贡献度,实践结果中发现,引入TF-IDF特征后效果仅仅有一点点波动,部分分类方法得到了少量的优化。
对于缺陷Ⅰ和Ⅱ,相比之下词嵌入往往有更加优越的表现。词嵌入的算法很多,其中Word2Vec是比较常用的一种算法。
该模型主要有两种具体的方法,一是在固定窗El空间中,通过窗口中上下文的词语来预测目标词语的方法,称为连续词袋模型(continuous bag—of-words model,CBOW), 也就是说,看到一个上下文,希望大概能猜出这个词和它的意思;另一种方法则刚好相反,通过目标词来预测周围邻近词语的模型,称为skip—gram模型,也就是说,给出一个词,希望预测可能出现的上下文的词。【5】
还有另一种在词嵌入基础上发展出来的方法Fuzzy Bag-of-Words Model(FBOW)。其思路是,首先将词袋中的所有词按照频率从高到低排序然后在某处截断,得到前边的词作为词袋模型的特征词。然后不同于词袋模型直接摒弃掉其后的所有词,FBOW考虑了其他词与特征词之间的相似度。并通过预训练的词嵌入向量中查询各个词以获取相似度来转变为特征值,这就很好的解决了词袋模型向量稀疏的问题。【6】
4.2 机器学习模型选取
在该次实验中,使用了多种机器学习模型。但仍有很多效果可能很好的方法没有使用。例如:逻辑回归(LR)、XGBoost、LightGBM等方法。对于模型本身,也没有很好地调整参数和进行模型融合操作。而对于数据集,也没有做引入额外信息和特征的尝试。这些都是可以改进的地方
4.2 深度学习模型选取
在该次实验中,使用了GloVe和LSTM进行深度学习方面的尝试。也可以在改变词向量、添加 更深更复杂的网络、融合多个模型的预测结果和调整训练的超参数这几个方面做出改进。
4.3 模型训练
在训练中,我只对训练集进行了简单的清洗和分词处理,但本次数据集的特点是正样本数量明显多于负样本数量,导致了正负样本比例的失调,这对模型训练不利,导致了模型对正样本有了一种不健康的选择倾向。
4.4 总体
文本分类,其首要任务是分析特征,去掉干扰词和特征;其次是将文本信息向量化,这里可以考虑的词向量有GloVe、Word2vec、FBOW等;最后就是使用合理的训练方法来对数据进行拟合,在机器学习和深度学习方法的对比上,往往数据量大的任务深度学习的表现会好一点。
参考文献
[1] 王斌, 潘文锋. 基于内容的垃圾邮件过滤技术综述[J]. 中文信息学报, 2005, 19(5):3-12.
[2] 陈琦, 伍朝辉, 姚芳,等. 基于TF*IDF的垃圾邮件过滤特征选择改进算法[J]. 计算机应用研究, 2009(06):2165-2167.
[3] 李文斌, 刘椿年, 陈嶷瑛. 基于混合高斯模型的电子邮件多过滤器融合方法[J]. 电子学报, 2006, 34(002):247-251.
[4] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
[5] 吴禀雅, 魏苗. 从深度学习回顾自然语言处理词嵌入方法[J]. 电脑知识与技术, 2016, 12(036):184-185.
[6] R. Zhao and K. Mao, “Fuzzy Bag-of-Words Model for Document Representation,” in IEEE Transactions on Fuzzy Systems, vol. 26, no. 2, pp. 794-804, April 2018, doi: 10.1109/TFUZZ.2017.2690222.