Abstract
This chapter revisits the key details of the informer, and has a better understanding of the problem background and application data scenarios of the Informer model. According to the author’s expression, it is suitable for periodic data sets and suitable for a long time series prediction. Short-term predictions can not reflect the expected performance of the informer. Continue to start from the three major challenges and propose three corresponding processing methods, from mathematical derivation to the process of actual model verification. And the learning of some small skills that appear in the source code of the paper, such as the principle and usage skills of EarlyStopping.
本章再次重温informer 的重点细节,对Informer模型的问题背景与应用数据场景有了更进一步理解,按作者的表达,适用于具有周期性的数据集,适合做一个较长的时序预测,如果过于短期的预测反而不能很好的体现informer应有的性能。继续从三大挑战出发,提出三点对应的处理方法,从数学推导到实际模型验证的过程。以及论文源码中出现的一些小技巧的学习,比如 EarlyStopping的原理与使用技巧。
Reference:
1.细读informer与项目学习
2. 类Transformer模型的长序列分析预测新方向-周号益
3. Informer论文
4. AAAI最佳论文Informer 解读
5. 时序模型论文分享:informer
一. informer重温讲解PPT简洁【超详细】
1.1 title

1.2 Background
问题背景:国家电网中存在很多的大型电力变压器,这些变压器用于对各个地区电压的调配工作,其资源十分宝贵的,在进行电力调配的过程中,运行一些保守的调整,通常一次调整能够运行两周甚至数周,然后通过这种较长时间的间隙调整可以保持电网的稳定,然而这带来一个问题,需要对未来较长一段时间的变压器负载有一个大体的估计,在此基础之上才能设定一个调整的范围。
序列预测是一个涉及使用历史序列信息来预测序列中的下一个或多个值的问题。 这是一个基本但重要的研究问题。
1.3 LSTF 问题的提出
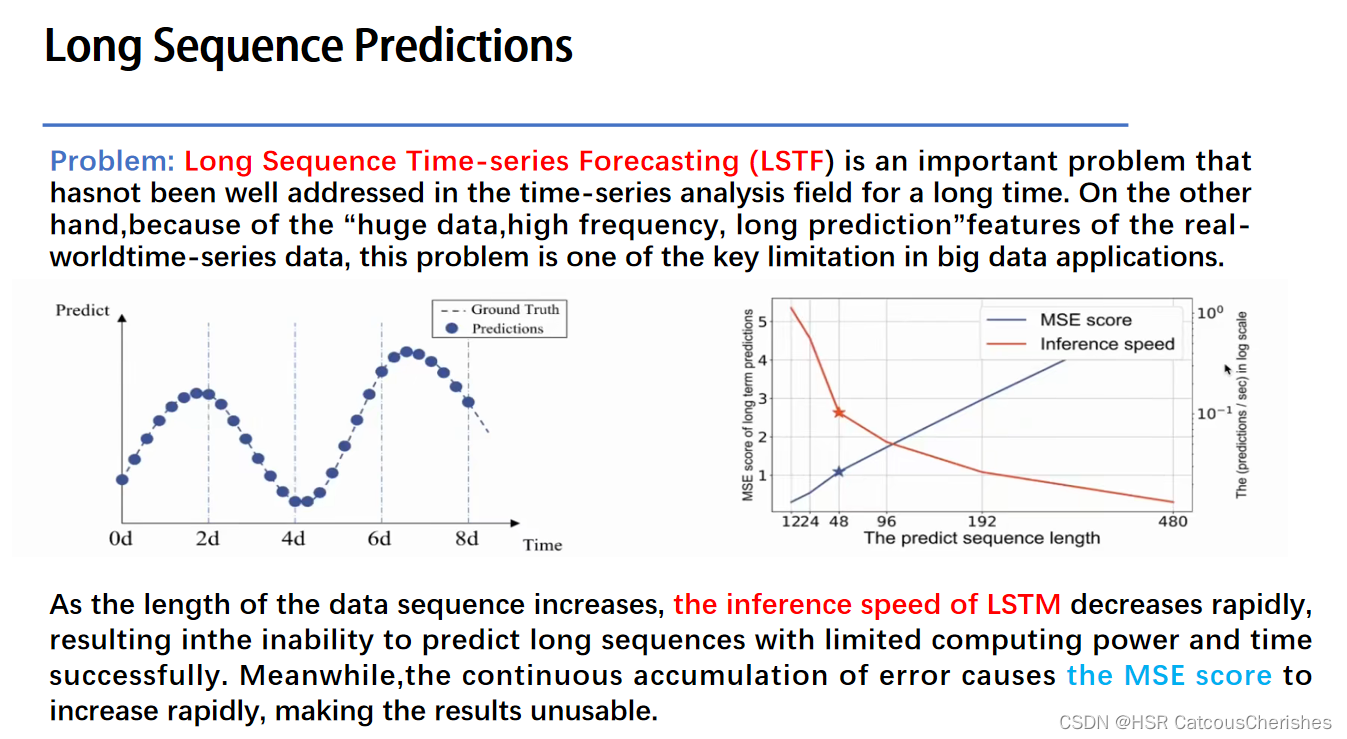
对于传统的循环神经网络在长序列问题上一般都不是很好的效果:比如传统的RNN-based模型不能够用于长时序预测问题。
Long sequence predicion 本文所研究的问题,关注的是LSTF的output的准确性,以及长序列预测中input的统一表征,建立一个Long sequence output 与 Long sequence input 之间的映射关系 。Informer的目标是解决长序列持续预测问题,这个问题与之前LSIL(长序列输入表征)问题很相似。
1.4 Transformer in LSTF problem
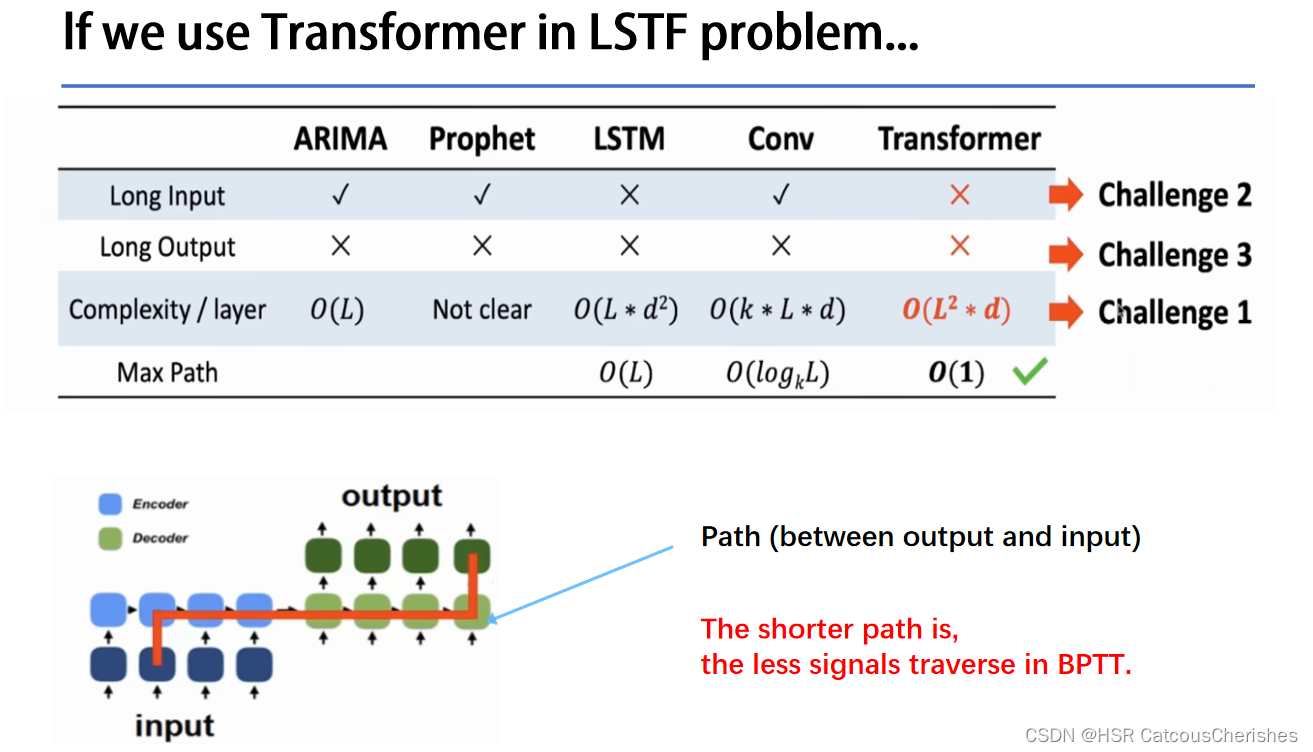
1.每一层的计算复杂度为O(L2):自注意力中(原子操作)的点积运算,每一对Input都要做attention运算。
2. 对于Long Input的问题:Encoder-Decoder的layer堆叠导致内存开销出现瓶颈,层数J过多,导致复杂度进一步增大【计算复杂度为O(J*L2)】.
3. 对于Long Output的问题:预测长序列输出的速度会下降,因为原始的Transformer的decoder在inference的过程中是动态输出的,即上一次的Output是下一次的Input,进而和隐藏层一起再预测下一次的Output,使得Transformer的Inference过程和RNN一样慢。
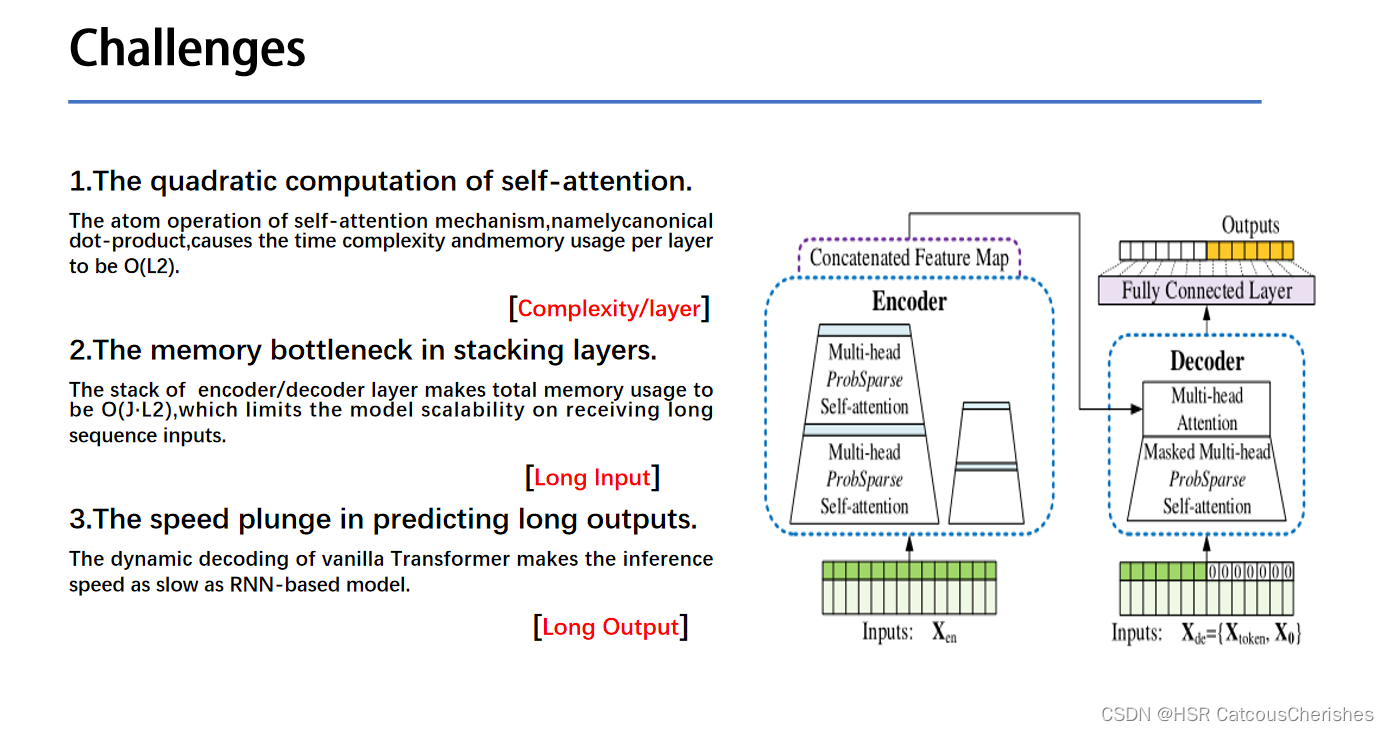

1.5 问题阐述

1.6 三个问题挑战对应的解决方法
1.6.1 Challenge1:——ProbSparse self-attention
最基本的一个思路就是降低Attention的计算量,仅计算一些非常重要的或者说有代表性的Attention即可,一些相近的思路在近期不断的提出,比如Sparse-Attention,这个方法涉及了稀疏化Attention的操作,来减少Attention计算量,然后涉及的呈log分部的稀疏化方法, LogSparse-Attention 更大程度上减小Attention计算量,再比如说Restart+LogSparse。如下图的自注意力机制:
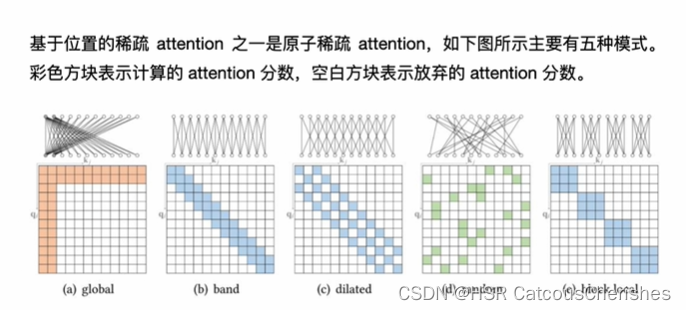
但是它们都具有随机局限性,是一类启发式方法,在多头视角下,这些注意力为每个头生成相同的稀疏的“查询-键对”(query-key pairs),可能会造成严重的信息丢失。

启发式假设也就是说我计算那些attention是用规则决定的,这种方法的缺点就是不能自适应的。
根据具体的情况去计算那些attention,经过研究发现attention_map的高激活值,在很多情况下都是较为稀疏的,如果我们把query,key,score,这些pairs排一个序,然后画出一个统计图来(右图所示),然后我们会发现它是服从一个Long-Tail分布的,也就是说大部分的attention仅仅起了一个很微弱的作用。
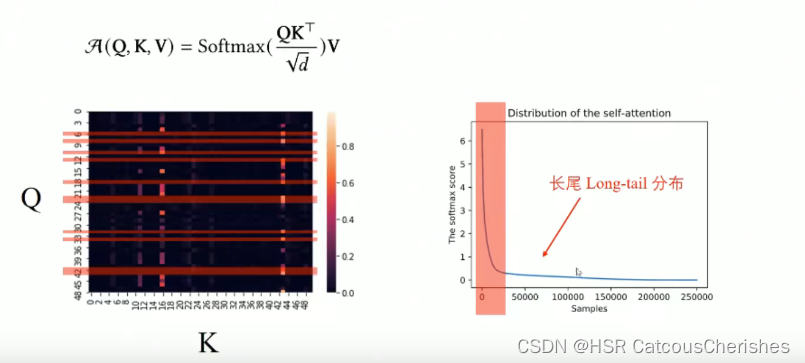
通过对attention_map随机抽取一些Query-wise Score(按行抽取),我们抽象出比较典型的attention score的两种代表,一个是"Active",一个是"Lazy",Active Query 特征是有一个或者多个较大的峰值,而其他的atten_score较小,然后另一种是Lazy Query整个统计曲线没有过大的起伏与均匀分布相差不大,我们称之为Lazy Query,然后希望根据这种发现重新定义一种计算和选取attention的方法——衡量Query稀疏性,即probability sparse – 概率分布稀疏。目的是尽量保证不遗漏重要的attention,又能尽量的较小计算量,降低开销。
度量方法的建立:建议参考回顾之前的细读informer部分,以及基于KL散度的评估概率的公式推导。

上面过程是作者通过KL散度公式,推导定义出稀疏性度量,再进一步缩小计算量,采用近视稀疏性度量,将自注意力机制所产生的空间复杂度 O ( L 2 ) O(L^2) O(L2)减小至 O ( L l n L ) O(LlnL) O(LlnL).
具体计算步骤详情如下:参考之前的博客!下面简单回顾:

1.6.2 Challenge2:——Distilling self-attention
Encoder 处理长序列输入:
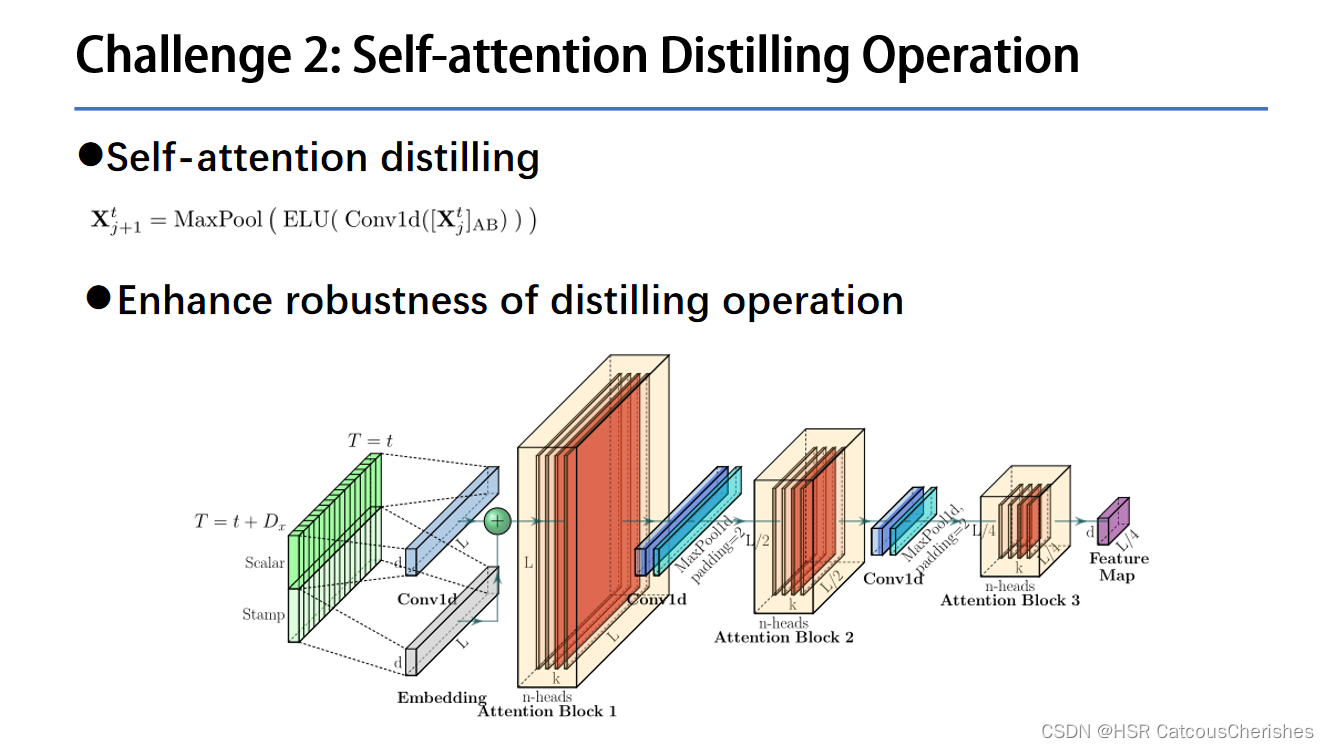
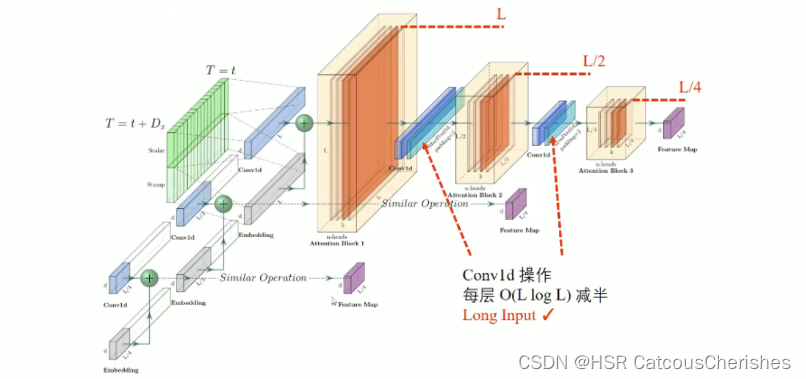
注意这个蒸馏操作:之前的理解上好像都有一点点不足。
作者说前面我们是在计算复杂度和空间复杂度上做了缩小,进一步对attention 做简化操作,由于每一层的输入输出,不同的head都存在一定的规律性,还有更重要的一点是ProbSparse self-attention有很多都是用mean填充的,所以天然就存在冗余的attention sorce ,因此应用卷积与池化来进行减半操作,是一个合情合理的过程(逐层减半,参数融合,feature map 融合)。
如果你觉得这样做还不够,我们再采用多个encoder,即Encoder Stack 时,再对输入也进行减半,Attention Block 结构一样,也就是同(这样操作实验证明对一些短周期的数据集可能会更有效)
1.6.3 Challenge3:——Generative Style Decoder
Long output, 原始的transformer没办法去解决,都是动态输出的跟rnn-based model一样的级联输出,无法handle 长序列的inference。Start token是个很不错的技巧在Nlp的动态解码过程中,尤其对于预训练模型阶段,在informer中针对长序列预测问题扩展了这个概念,对于长序列的output问题提出了一个生成式的Decoder,也就是一次性生成所有的预测数据。

第一个 Mask attention层中的query、key、value都是根据Decoder输入的embedding乘上权重矩阵得到的,而第二个attention层中的query是根据前面attention层的输出乘上权重矩阵得到的,key和value是根据Encoder的输出乘上权重矩阵得到的。
二. 复现原始inforemr代码出现的问题
2.1 环境配置
name: regional_pmm
channels:
- conda-forge
- defaults
dependencies:
- python=3.6
- pip
- matplotlib==3.1.1
- numpy==1.19.4
- pandas==0.25.1
- scikit-learn==0.21.3
- pytorch==1.8.0
2.2 pytorch EarlyStopping
早停机制原理:
EarlyStopping的原理是提前结束训练轮次来达到“早停“的目的,故训练轮次需要设置的大一点以求更好的早停(比如可以设置100epoch)。
首先,我们需要一个一个标识,可以采用**'val_acc’(测试集准确率)或者’val_loss’(测试集损失值)等等,这些量在每一个轮次中都会不断更新自己的值,也和模型的参数息息相关**,所以我们想通过他们间接操作模型参数。以val_loss举例,当模型训练时可能会出现当val_loss到一定值的时候会出现回弹的情况,所以我们希望在loss值回弹之前结束模型的训练。
最简单的一种的早停方法:
参数有5个:
第一个patience:这个是当有连续的patience个轮次数值没有继续下降,反而上升的时候结束训练的条件(以val_loss为例)
第二个verbose:这个其实就是是否print一些值,可也不传参,因为他有默认值
第三个delta:这个就是控制对比是的”标准线“
第四个path:这个是权重保存路径,早停法会在每一轮次次产生最优解(就是val_loss继续减少)的时候保存当前的模型参数。注:只要保存路径不变,每一次保存在文件里面的参数都会覆盖上一次保存在文件里面的参数。
第五个trace_func:这个就是显示每一个轮次变化的数值的方式,默认print,也可以改成进度条显示(进度条库 tqdm的对象)
原始论文中早停机制函数如下:
class EarlyStopping:
def __init__(self, patience=7, verbose=False, delta=0):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
def __call__(self, val_loss, model, path):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model, path)
elif score < self.best_score + self.delta: //与最好的loss对比
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience: //当超过耐心值时就会停止模型训练,以防止过拟合了
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model, path)
self.counter = 0
def save_checkpoint(self, val_loss, model, path):
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), path+'/'+'checkpoint.pth')
self.val_loss_min = val_loss
重点就在中间那个__call__方法里面,比较的是这一轮的val_loss和之前最好的val_loss(可以加上一个数实现‘标准线’的‘上移’或者‘下移’)
2.3 实际模型应用
设置了patience为7,epoch为200。
# 训练步数
train_steps = len(train_loader)
# 提前停止
early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)
# 模型优化器
model_optim = self._select_optimizer()
# 损失函数
criterion = self._select_criterion()
for epoch in range(self.args.train_epochs):
epoch_count += 1
iter_count = 0
# 存储当前epoch下的每个迭代步的训练损失
train_loss = []
-------------------
# 完成每个epoch的训练就打印一次
print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(
epoch + 1, train_steps, train_loss, vali_loss, test_loss))
# 判断是否提前停止
early_stopping(vali_loss, self.model, path)
if early_stopping.early_stop:
print("Early stopping")
break
以上就是Informer论文中所使用的早停机制了,注意是需要去修改执行函数main_informer.py里面:
parser.add_argument('--train_epochs', type=int, default=200, help='train epochs------------')
parser.add_argument('--batch_size', type=int, default=64, help='训练输入数据的批大小-------------'
'batch size of train input data')
parser.add_argument('--patience', type=int, default=7, help='提前停止的连续轮数'
'early stopping patience')