
先来总结一下
可以看到上一节我们说了机器学习,有一种情况就是过拟合,就是说我们做的模型,可以匹配所有的,已知的训练数据,但是对于未知的数据来的时候,我们的模型却不能很好的预测,这个就是过拟合.
然后解决过拟合可以给我们的,模型函数的,损失函数添加,惩罚项对吧,也就是把我们的损失函数,进行正则化.正则化的方式,有很多,其中L1,L2是两种,可以看到L1就是把n个维度的w,也就是权重的绝对值都加和.
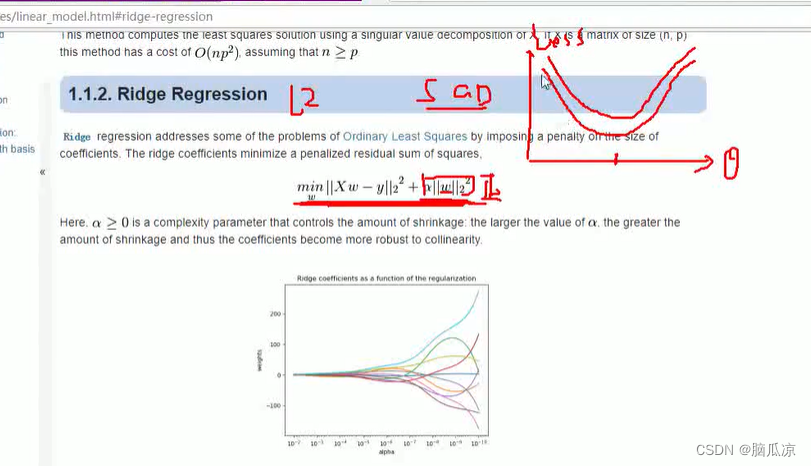
然后我们再来看,我们说,我们的SGD,也就是随机梯度下降,如果要防止过拟合,可以进行正则化,那么正则化来说,其实就是在,原来的损失函数上,用L1,或者L2正则方法,进行正则化对吧,可以看到上面
其实就是用L2正则,加上了一个,所有的W权重的的平方和,这样的话,就相当于改变了原来的损失函数对吧,因为这个w的平方和是正数,所以对应的函数曲线就会往上移动,可以看到右上角
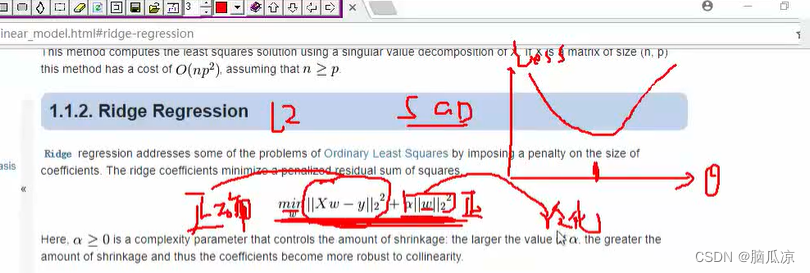
然后我们这里,可以看到,如果只用损失函数的话,那么,做出来的最优解肯定是,正确性比较高的,那么
如果我们再给它加上一个w的平方和的话,这时候,我们的损失函数,也就是模型,就会具有一定的泛化能力,