加油!
不要停止奔跑,
不要回顾来路,
来路无可眷顾,
值得期待的只有远方。
关系数据理论是关系数据库的理论基础,
为数据库设计提供了判别标准,
是设计关系数据库的指南。
数据存储异常(因为存在数据依赖)——数据冗余、不一致性、插入异常、删除异常
S(NO, NAME, SEX, COUR, DEGR);
学生表(学号,姓名,性别,课程,成绩);
数据冗余:―个学生选修多门课程,这样导致学生姓名(NAME)和性别(SEX)多次重复存储;
不一致性:由于数据存储冗余,当更新某些数据项时,就有可能一部分字段修改了,而另一部分字段未修改,造成存储数据的不一致性;
插入异常:如果某个学生未选修课程,则他的(NO,NAME,SEX)信息无法插入,因为COUR为空,关系数据模式规定主关键字不能为空或部分为空,这便是插入异常;
删除异常:当要删除所有学生成绩时,将所有(NO,NAME,SEX)也都删除了,这便是删除异常。
数据存储异常是因为存在数据依赖,而绝大多数的数据依赖是函数依赖!!!
函数依赖:X函数决定Y,或Y函数依赖于X,则记为X→Y;
完全函数依赖:Y函数依赖于整个X,记为X--f-->Y
部分函数依赖:Y函数依赖于X的某个真子集,记为X--p-->Y;
传递函数依赖:X→Y,Y→Z,且Y—\→X,Z-Y≠∅,Y-X≠∅,则称为Z传递依赖于X,记为X--t-->Z。
函数依赖公理——Armstrong公理;
自反性:若Y⊆X ,则X→Y;
增广性:若X→Y,则XZ→YZ;
传递性:若X→Y,Y→Z,则X→Z;
合成规则:若X→Y,X→Z,则X→YZ;
分解规则:若X→YZ,则X→Y,X→Z;
伪传递规则:若X→Y,YW→Z,则XW→Z。
属性之间有三种关系,但并不是每一种关系中都存在函数依赖。
如果X和Y之间是"1 :1"关系(如学校和校长),则存在函数依赖: X→Y和Y→X如果X和Y之间是"m :1"关系(如学号和姓名),则存在函数依赖:X→Y。(学号 决定 名字)
如果X和Y之间是"m :n"关系(如学生和课程),则X和Y之间不存在函数依赖。
有一个关系模式R(U),F为其函数依赖集,则所有用Armstrong公理从F中推出的函数依赖X→Ai中Ai的属性集合为X的属性闭包,记为X+。

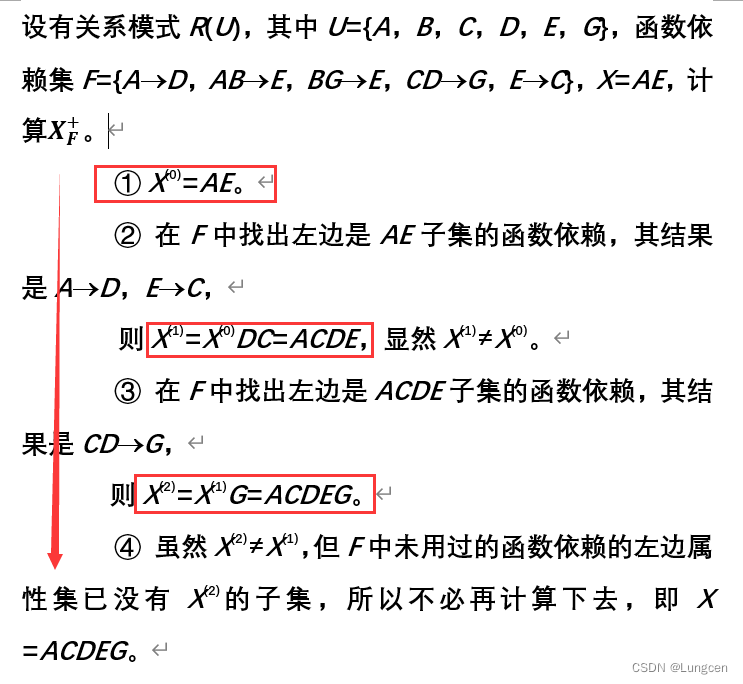
函数依赖的最小集:对于给定的函数依赖F,当满足下列条件时,称为F的最小集,记作 F';
(1)F的每个依赖的右部都是单个属性;
(2)对于F中的任何一个函数依赖X→A,F'-{X一A}与F'都不等价;
(3)对于F中的任何一个X→A和X的真子集Z(F'-{X→A})U{Z→A}与F'都不等价。条件(2)保证了在F中不存在多余的函数依赖;
条件(3)保证了F中每个函数依赖的左边没有多余的属性;


第一范式(1NF):设R是一个关系模式,R属于第一范式当且仅当R中每一个属性A的值域只包含原子项,即不可分割的数据项。第一范式不能排除数据冗余和更新异常等问题,因为其中可能存在部分函数依赖。
第二范式(2NF):设R是一个关系模式,R属于第二范式当且仅当R是1NF,且每个非主属性都完全函数依赖于主关键字。第二范式也可能存在数据冗余和更新异常等问题,因为其中可能存在传递函数依赖。
第三范式(3NF):设R是一个关系模式,R属于第三范式当且仅当R是2NF,且每个非主属性都非传递函数依赖于主关键字。
BC范式(BCNF):设R是一个关系模式,F是它的依赖集,R属于BCNF当且仅当其F中每个依赖的决定因素必定包含R的某个候选关键字。
第四范式(4NF):给定关系模式R及其属性A和B,对于一给定的A值,就有一组B属性值与之对应,而与其他的属性(R-A-B)没有关系,则称“B多值依赖于A”或“A多值决定B",记作A→→B。
关系模式的分解:无损连接性、函数依赖保持性
无损连接性:指的是对关系模式分解时,原关系模式下的任一合法的关系实例在分解之后应能通过自然连接运算恢复起来。
函数依赖保持性:设关系模式R的一个分解p={R1,R2,....Rk},F是R的依赖集,如果F等价于ПR1(F)U ПR2(F)U ...U ПRk(F),则称分解p具有依赖保持性。
一个无损连接分解不一定具有依赖保持性;同样,一个依赖保持性分解不一定具有无损连接性。
关系模式的分解和范式组合在一起也是一个很复杂的问题 ! ! !
是真的复杂 ! ! !