论文

论文题目:DR-TANet: Dynamic Receptive Temporal Attention Network for Street Scene Change Detection
收录:IEEE Intelligent Vehicles Symposium 2021 (IV2021)
论文地址:https://arxiv.org/abs/2103.00879v2
项目地址:GitHub - Herrccc/DR-TANet
论文思路在于3点,
- 考虑现有采样方式范围的受限,难以捕捉到各种尺寸和形状的目标,提出时间注意力模块(TAM),利用注意力机制在固定的依赖范围内寻找特征间的相似性和依赖性。
- 改进TAM,提出动态接收性时间注意力模块(DRTAM),不再固定依赖范围,而是随着层层深入,依赖范围逐渐减小,从7*7、5*5、3*3到1*1,实现效率和性能间的平衡。
- 考虑到条形实体(行人、树枝、路灯)难以检测,提出并发水平和垂直注意力(CHVA),对条形带形物体进行轮廓的细化。
Abstract
街景变化检测(SCD),旨在识别在不同时间拍摄的成对街景图像的变化区域。基于编码器-解码器体系结构的最先进网络利用两个通道之间相应层级的特征图来获取足够的变化信息。然而,特征提取、特征相关性计算,甚至整个网络的效率都需要进一步提高。
本文提出时间注意力(Temporal Attention Module,TAM),并探讨了时间注意力的依赖范围大小对变化检测性能的影响。在时间注意力模块基础上,更是引入一个高效轻量的动态接受性时间注意力模块(Dynamic Receptive Temporal Attention Module,DRTAM),并提出并发水平和垂直注意力(Concurrent Horizontal and Vertical Attention,CHVA),以提高网络对特定挑战的准确性。
在数据集PCD(GSV和TSUNAMI)和CL-CMU-CD取得优异效果。
Introduction
对于成对图像,常见的有3种特征融合方式:早期融合、晚期融合、关联性融合( early-fusion,late-fusion and correlation-fusion)。

现有局限:
- 现有方法受限于其常规和有限的采样范围,难以处理各种大小和形状的物体。特征图之间的关系有研究空间。考虑引进注意力机制。
- 随着SCD的网络加深,更深层次的网络不可避免地导致更低地效率。因此,SCD网络需要进一步改善效率和性能间的平衡。
- 大多数网络中的变化掩码轮廓都较为粗糙,需要更加细致的变化检测。
解决方法:
- 提出时间注意力模块(Temporal Attention Module,TAM),利用注意力机制在固定的依赖范围内寻找相似性。
- 考虑到条形实体(行人、树枝、路灯)难以检测到,论文提出并发水平和垂直注意力(Concurrent Horizontal and Vertical Attention,CHVA),进行细化。
- 提出动态接受性时间注意力模块(Dynamic Receptive Temporal Attention Module,DRTAM),实现轻量性,使其适用于智能车辆。
论文中,带有基本时间注意模块(TAM)的网络被称为TANet;
带有动态接收时间注意模块(DRTAM)并利用CHVA进行细化的网络,被称为DR-TANet。
Contribution
- 提出一种新的街道场景变化检测网络TANet及其改进版本DR-TANet,它首先将注意机制引入到变化检测任务中。在时间注意模块(TAM)的基础上,通过比较不同的依赖范围大小来探索对性能的影响,然后确定最佳的固定依赖范围大小。此外,由于编码器中特征图的感受野越来越大,论文直观地提出了动态感受性时间注意模块(DRTAM)。DRTAM在公共数据集上表现良好,参数和计算复杂度较低。它提高了整个网络的效率,并被用作DR-TANet的基础。
- 提出并发水平和垂直注意(CHVA),并将其集成到时间注意图中,以改进最终的变化检测。CHVA在需要准确定位以确保安全驾驶的带状实体变化中发挥着重要作用。
- 论文提出的网络在街景数据集PCD(“GSV”和“TSUNAMI”)上的表现取得sota效果。此外,它在数据集“VL-CMU-CD”上表现良好。
Related Work
简单介绍变化检测方法的发展,引出DR-TANet。
简单论述特征间的相关性,引出注意力机制来学习时间通道和空间通道上特征图的关系。
TANet/DR-TANet: Proposed Architecture
Overall Model Architecture

TANet架构如图所示。编码器主干为ResNet-18,支持快速推理。编码器路径分为两条并行支路进行特征提取。提取的特征图被注入到时间注意力模块TAM中,目的是寻找两个时间通道间对应层级的特征图的相似性。最后,在TAM中生成的注意力图被输入解码器。解码器由4个上采样层组成,用于执行上采样以恢复所需变化掩码的大小。
Temporal Attention Module (TAM)

时间注意(TA)的计算过程,t1通道的特征图将用于生成查询矩阵(query matrix)。查询矩阵将与密钥矩阵(key matrix)一起操作,以生成t1的每个像素与t0的依赖范围内的相关像素之间的协方差矩阵(covariance matrix)。softmax操作后的协方差矩阵提供像素之间的精确相似性(similarity),然后使用从t0通道的特征图推断出的值矩阵(value matrix)进行操作,以便预测变化区域,如图4所示。生动的是,t1处的图像将从t0处的图像中查询变化的区域。
如果检测到时间通道t0的每个像素和时间通道t1的所有像素之间的依赖性和相似性,可以获得完整信息,但是全局完整图像注意力在计算上是昂贵的,并且不具有代表性。本文,应用一个固定的依赖范围大小。这意味着通道t0处的特征图的示例像素(i,j)将被视为仅依赖于通道t1处的特征图的固定范围的像素,其中心在相同位置(i,j)。固定依赖范围大小可以是(1*1)、(3*3)、(5*5)等。不同依赖范围大小的影响在后面进行了消融实验。
此外,进行多头时间注意。意味着特征图在通道维度上分为N组,以确定通道间的关系。
参考transformer模型结构,引进位置编码PC,不仅对两个时间通道的依赖性和相似性建模,还对局部位置的接近性建模。具体地说,依赖范围中的像素位置将会得到不同的处理。

在时间注意力(TA)的基础上,构建时间注意力模块(TAM)。TAM由4层组成,每层以两个时间通道的特征图作为输入,根据TA机制计算注意力图。由于特征图的大小不同,先前计算的注意力图会先下采样,再与后续的注意力图拼接,每个注意力图将通过跳接(skip connection)再次插入到解码器中,以防止整个上采样特征流中的信息丢失。
Dynamic Receptive Temporal Attention Module (DRTAM)
TAM建立在注意力模块固定的依赖范围大小上。
在视觉模型中,在编码器的下采样路径期间,特征图首先识别低级实体(颜色、边缘等),然后高级实体(纹理、形状、物体等)将获得更多关注。
在保持不断下采样的特征图的依赖范围大小不变时,计算能力没有得到充分利用。

于是,本文提出动态接收时间注意力模块(DRTAM),如图5所示。当特征图收集低级特征是,在初始时间注意层中,依赖范围将设置为7*7。然后,在后面的时间注意力层,依赖范围大小依次为5*5、3*3、1*1。从而使得计算能力得到高度利用,同时收集足够的领域相似性和依赖性。

Refinement: Concurrent Horizontal and Vertical Attention (CHVA)

CNN中的卷积通常会将中心像素周围的以像素为中心的一个正方形定义为相关领域。
本文通过考虑TA中依赖范围的形状,设计并行水平和垂直注意力(CHVA),以获得更多关于细化条带实习变化的两个方向的信息。其中,水平和垂直的长度设置为(2*K+1),K表示时间注意依赖范围的大小。
Experiments
Details
dataset:PCD(‘GSV’ 和‘TSUNAMI’)、 VL-CMU-CD

数据预处理

实验细节

评价指标:precision、recall、F1-Score

Evaluation on ‘PCD’ Dataset
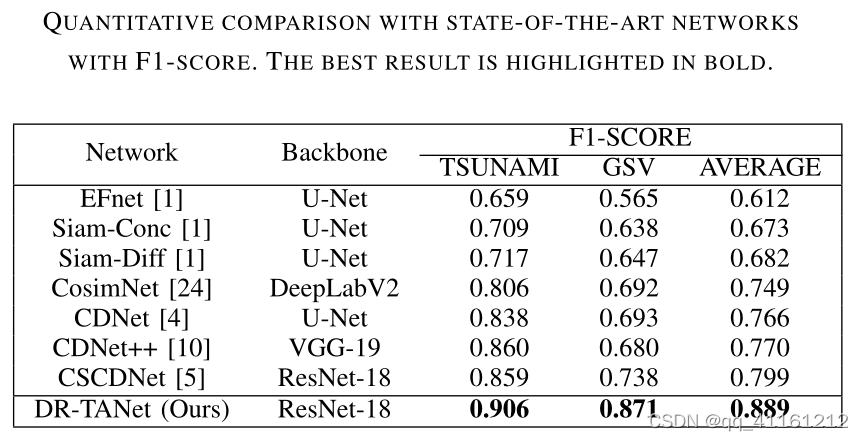
PCD数据集上,DR-TANet取得sota。
Visible


可以发现,DR-TANet能够捕捉到更详细和微小的变化。

时间注意力(TA)图的插图(与ground true重叠)。(a)(b)显示TA第1层的第27张TA图;(c)(d)在TA第1层可视化第60张TA图。在TA第1层,生成了64张注意力图。在第27张TA地图中,突出显示的区域代表有人参加的区域。相反,在第60张TA图中,较暗的区域得到了更多的关注。
Ablation Studies
Effect of the TA dependency-scope size in TAM
TAM中TA依赖范围大小的影响。对于0通道特征图中的每个像素,他确定t1通道特征图中以相同像素位置为中心的像素范围。作用域的尺寸越大,推断出的依赖性就越大,包含的信息越详细。
随着依赖范围尺寸的增长,F1值有所增加。

Effect of Concurrent Horizontal and V ertical Attention (CHVA)
并发水平和垂直注意力的影响。 引入CHVA,F1值有些许增长。引入CHVA的动机是在水平和垂直方向纳入更广泛的信息。对特定图像对的估计有所改进,但对整个数据集F1值作用不大。
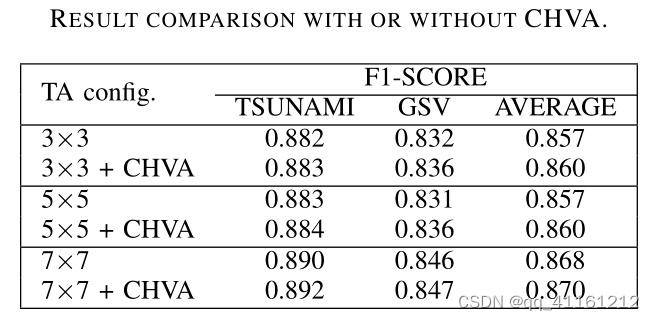
下图有虚线框标注地方可以看出,使用CHVA对条带实体的估计有明显改进。



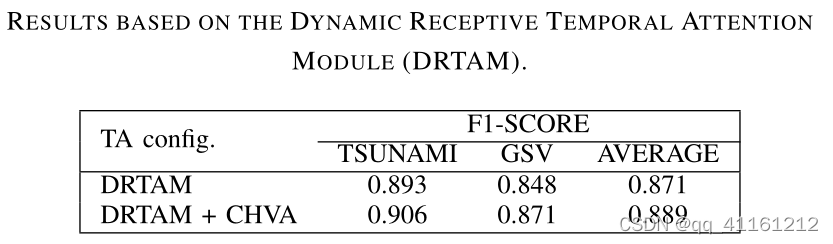
Effect of the Dynamic Receptive Temporal Attention Module (DRTAM)
DRTAM模块的作用。性能方面改进不大,主要体现在降低模型的复杂度。
Parameters and MACs Comparison between Different Configurations and Different Networks
不同配置和不同网络的参数和MAC比较 。
首先,比较了TA的不同配置的参数数(parameters)和乘法累加操作数(mac),以给出面向效率的建议。然后,比较了不同性能良好网络的参数和MAC,以证明从这个角度来看,DR-TANet也有其优势。

注意机制、依赖范围大小和CHVA的规格对网络参数量没有影响。配置DRTAM+CHVA获得了最高效配置的推荐。它实现了与依赖项大小为(7×7)的TAM几乎相同的结果,但其计算资源成本甚至低于范围大小为(3×3)的TAM。

与另外三个性能最好的网络,在计算复杂度上与提出的DR-TANet进行对比。可以看出,DR-TANet在参数和MAC方面的效率显著提高。
Evaluation on ‘VL-CMU-CD’ Dataset

- DR-TANet在CL-CMU-CD上表现很好。
- 未经CHVA细化的DR-TANet的性能甚至比使用CHVA的DR-TANet更好。部分原因是“VL-CMU-CD”数据集中的变化并没有那么详细。在这种情况下,整合水平和垂直条带信息的CHVA不会有显著差异。
Conclusion
- 本文将注意机制引入到街道场景变化检测任务SCD中。引入时间注意力(TA),旨在利用两个时间通道上特征图的相似性和依赖性。
- 在TAM的基础上,提出了动态接受性时间注意模块(DRTAM),在保证高性能的同时降低了计算复杂度。
- 引入并发水平和垂直注意力(CHV A),它对条带实体变化的预测进行了有针对性的细化。
- 在“VL-CMU-CD”和“PCD”数据集上的实验表明,DR-TANet性能优越。且考虑到整个网络的参数和计算需求,网络在精度和效率之间取得了较好的平衡。
核心代码
Temporal_Attention(TA)
class Temporal_Attention(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0,
groups=1, bias=False, refinement=False):
super(Temporal_Attention, self).__init__()
self.outc = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.groups = groups
self.refinement = refinement
print('Attention Layer-kernel size:{0},stride:{1},padding:{2},groups:{3}...'.format(self.kernel_size,self.stride,self.padding,self.groups))
if self.refinement:
print("Attention with refinement...")
assert self.outc % self.groups == 0, 'out_channels should be divided by groups.'
self.w_q = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias)
self.w_k = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias)
self.w_v = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=bias)
#relative positional encoding...
self.rel_h = nn.Parameter(torch.randn(self.outc // 2, 1, 1, self.kernel_size, 1), requires_grad = True)
self.rel_w = nn.Parameter(torch.randn(self.outc // 2, 1, 1, 1, self.kernel_size), requires_grad = True)
init.normal_(self.rel_h, 0, 1)
init.normal_(self.rel_w, 0, 1)
init.kaiming_normal_(self.w_q.weight, mode='fan_out', nonlinearity='relu')
init.kaiming_normal_(self.w_k.weight, mode='fan_out', nonlinearity='relu')
init.kaiming_normal_(self.w_v.weight, mode='fan_out', nonlinearity='relu')
def forward(self, feature_map):
fm_t0, fm_t1 = torch.split(feature_map, feature_map.size()[1]//2, 1)
assert fm_t0.size() == fm_t1.size(), 'The size of feature maps of image t0 and t1 should be same.'
batch, _, h, w = fm_t0.size()
padded_fm_t0 = F.pad(fm_t0, [self.padding, self.padding, self.padding, self.padding])
q_out = self.w_q(fm_t1)
k_out = self.w_k(padded_fm_t0)
v_out = self.w_v(padded_fm_t0)
if self.refinement:
padding = self.kernel_size
padded_fm_col = F.pad(fm_t0, [0, 0, padding, padding])
padded_fm_row = F.pad(fm_t0, [padding, padding, 0, 0])
k_out_col = self.w_k(padded_fm_col)
k_out_row = self.w_k(padded_fm_row)
v_out_col = self.w_v(padded_fm_col)
v_out_row = self.w_v(padded_fm_row)
k_out_col = k_out_col.unfold(2, self.kernel_size * 2 + 1, self.stride)
k_out_row = k_out_row.unfold(3, self.kernel_size * 2 + 1, self.stride)
v_out_col = v_out_col.unfold(2, self.kernel_size * 2 + 1, self.stride)
v_out_row = v_out_row.unfold(3, self.kernel_size * 2 + 1, self.stride)
q_out_base = q_out.view(batch, self.groups, self.outc // self.groups, h, w, 1).repeat(1, 1, 1, 1, 1, self.kernel_size*self.kernel_size)
q_out_ref = q_out.view(batch, self.groups, self.outc // self.groups, h, w, 1).repeat(1, 1, 1, 1, 1, self.kernel_size * 2 + 1)
k_out = k_out.unfold(2, self.kernel_size, self.stride).unfold(3, self.kernel_size, self.stride)
k_out_h, k_out_w = k_out.split(self.outc // 2, dim=1)
k_out = torch.cat((k_out_h + self.rel_h, k_out_w + self.rel_w), dim=1)
k_out = k_out.contiguous().view(batch, self.groups, self.outc // self.groups, h, w, -1)
v_out = v_out.unfold(2, self.kernel_size, self.stride).unfold(3, self.kernel_size, self.stride)
v_out = v_out.contiguous().view(batch, self.groups, self.outc // self.groups, h, w, -1)
inter_out = (q_out_base * k_out).sum(dim=2)
out = F.softmax(inter_out, dim=-1)
out = torch.einsum('bnhwk,bnchwk -> bnchw', out, v_out).contiguous().view(batch, -1, h, w)
if self.refinement:
k_out_row = k_out_row.contiguous().view(batch, self.groups, self.outc // self.groups, h, w, -1)
k_out_col = k_out_col.contiguous().view(batch, self.groups, self.outc // self.groups, h, w, -1)
v_out_row = v_out_row.contiguous().view(batch, self.groups, self.outc // self.groups, h, w, -1)
v_out_col = v_out_col.contiguous().view(batch, self.groups, self.outc // self.groups, h, w, -1)
out_row = F.softmax((q_out_ref * k_out_row).sum(dim=2),dim=-1)
out_col = F.softmax((q_out_ref * k_out_col).sum(dim=2),dim=-1)
out += torch.einsum('bnhwk,bnchwk -> bnchw', out_row, v_out_row).contiguous().view(batch, -1, h, w)
out += torch.einsum('bnhwk,bnchwk -> bnchw', out_col, v_out_col).contiguous().view(batch, -1, h, w)
return out
TANet
class TANet(nn.Module):
def __init__(self, encoder_arch, local_kernel_size, stride, padding, groups, drtam, refinement):
super(TANet, self).__init__()
self.encoder1, channels = get_encoder(encoder_arch,pretrained=True)
self.encoder2, _ = get_encoder(encoder_arch,pretrained=True)
self.attention_module = get_attentionmodule(local_kernel_size, stride, padding, groups, drtam, refinement, channels)
self.decoder = get_decoder(channels=channels)
self.classifier = nn.Conv2d(channels[0], 2, 1, padding=0, stride=1)
self.bn = nn.BatchNorm2d(channels[0])
self.relu = nn.ReLU(inplace=True)
def forward(self, img):
img_t0,img_t1 = torch.split(img,3,1)
features_t0 = self.encoder1(img_t0)
features_t1 = self.encoder2(img_t1)
features = features_t0 + features_t1
features_map = self.attention_module(features)
pred_ = self.decoder(features_map)
pred_ = upsample(pred_,[pred_.size()[2]*2, pred_.size()[3]*2])
pred_ = self.bn(pred_)
pred_ = upsample(pred_,[pred_.size()[2]*2, pred_.size()[3]*2])
pred_ = self.relu(pred_)
pred = self.classifier(pred_)
return pred
AttentionModule
class AttentionModule(nn.Module):
def __init__(self, local_kernel_size = 1, stride = 1, padding = 0, groups = 1,
drtam = False, refinement = False, channels = [64,128,256,512]):
super(AttentionModule, self).__init__()
if not drtam:
self.attention_layer1 = Temporal_Attention(channels[0], channels[0], local_kernel_size, stride, padding, groups, refinement=refinement)
self.attention_layer2 = Temporal_Attention(channels[1], channels[1], local_kernel_size, stride, padding, groups, refinement=refinement)
self.attention_layer3 = Temporal_Attention(channels[2], channels[2], local_kernel_size, stride, padding, groups, refinement=refinement)
self.attention_layer4 = Temporal_Attention(channels[3], channels[3], local_kernel_size, stride, padding, groups, refinement=refinement)
else:
self.attention_layer1 = Temporal_Attention(channels[0], channels[0], 7, 1, 3, groups, refinement=refinement)
self.attention_layer2 = Temporal_Attention(channels[1], channels[1], 5, 1, 2, groups, refinement=refinement)
self.attention_layer3 = Temporal_Attention(channels[2], channels[2], 3, 1, 1, groups, refinement=refinement)
self.attention_layer4 = Temporal_Attention(channels[3], channels[3], 1, 1, 0, groups, refinement=refinement)
self.downsample1 = conv3x3(channels[0], channels[1], stride=2)
self.downsample2 = conv3x3(channels[1]*2, channels[2], stride=2)
self.downsample3 = conv3x3(channels[2]*2, channels[3], stride=2)
def forward(self, features):
features_t0, features_t1 = features[:4], features[4:]
fm1 = torch.cat([features_t0[0],features_t1[0]], 1)
attention1 = self.attention_layer1(fm1)
fm2 = torch.cat([features_t0[1], features_t1[1]], 1)
attention2 = self.attention_layer2(fm2)
fm3 = torch.cat([features_t0[2], features_t1[2]], 1)
attention3 = self.attention_layer3(fm3)
fm4 = torch.cat([features_t0[3], features_t1[3]], 1)
attention4 = self.attention_layer4(fm4)
downsampled_attention1 = self.downsample1(attention1)
cat_attention2 = torch.cat([downsampled_attention1,attention2], 1)
downsampled_attention2 = self.downsample2(cat_attention2)
cat_attention3 = torch.cat([downsampled_attention2,attention3], 1)
downsampled_attention3 = self.downsample3(cat_attention3)
final_attention_map = torch.cat([downsampled_attention3,attention4], 1)
features_map = [final_attention_map,attention4,attention3,attention2,attention1]
return features_map