本文从5个方面进行说明:
1、 物理/虚拟/总线地址概念说明。
2、 MMU是什么,为什么,怎么做。
3、 内存分区和内存映射区。
4、 Buddy算法是个什么鬼。
5、 CMA的工作原理。
物理/虚拟/总线地址概念说明
所谓一花一世界,一叶一菩提,相同的事物在不同的角度可能会有不同的看法,对于物理地址,虚拟地址,总线地址的概念也是如此。
物理地址是MMU的视角所看到的内存地址。
虚拟地址是存在MMU的前提下CPU所看到的内存地址,当然我们实际编程的时候操作的也是虚拟地址。
总线地址是设备的视角所看到的内存地址。
MMU可以把虚拟地址转换为物理地址,而IOMMU可以把设备的总线地址转换为物理地址。
比如一块内存,物理地址是0,在设备端看起来是0x80000000,而物理地址0又通常被映射为虚拟地址0xc0000000,从而同一地址就具备了三个身份,但他们在物理上指的是同一片区域。
归根结底,不论是MMU,CPU或程序员,还是设备,他们的终极目的是操作内存,至于怎么操作,它们又都有各自的比较舒服的操作方式,就是所谓的物理地址,虚拟地址和总线地址,至于为什么要通过这种方式操作内存,请参考下一节,MMU是什么,为什么,怎么做。
MMU是什么,为什么,怎么做
通常情况下,应用程序并不需要关心内存实际的物理地址,从应用程序的角度,“我需要的时候你就要给我,至于你是如何分配的,还有多少空闲,我不管”,MMU使这种需求成为可能。
我们知道应用程序的每一个进程都有自己的一张页表,通常0-3G为用户空间,3-4G为内核空间,每一个进程都傻傻的以为自己独自拥有4G的内存空间,从而使得程序员在写程序时不需要考虑计算机中物理内存的实际容量,但是我们真的没有这么大的内存啊,怎么办?没关系,MMU可以解决。
MMU提供了虚拟地址和物理地址的映射功能,这个功能使每个进程都拥有“4G独立的内存空间”成为可能。另外MMU还提供内存权限保护,用户权限保护和Cache缓存控制等功能。
我们使用C语言定义一个const常量,MMU会标记该常量所在的内存区间为readonly(此处有错误,MMU应该改为内核,参考文末校正1),其实就是在对应的页表中标记该片物理内存的权限为readonly,当另外一个文件单元通过虚拟地址尝试写这个变量,MMU在把虚拟地址转换为物理地址的过程中发现,这段内存区域是readonly的,那么,不好意思,你无权写入,并产生一个fault,内核收到这个fault向应用程序发送一个SIGSEGV,应用程序产生段错误并结束。
用户权限保护,同理,内核在创建页表的时候也会对内存区域的用户权限做标记,当一个用户程序通过MMU尝试访问内核空间内存,也会被拒绝。
另外,MMU还提供Cache缓存控制功能。我们知道设备可通过DMA直接访问内存,而不需要CPU;另一方面读写内存是非常耗时的(相对cache来说),如果我们的CPU存在高速缓存,把最近经常使用的内存缓冲到Cache可以大大的提高程序的效率。但是这时出现了一个问题,如何保证DMA和Cache的一致性问题?MMU提供了Cache是否命中的检查,从而进一步可以保证DMA与Cache的一致性。
那么MMU是如何实现物理地址到虚拟地址的映射的呢,请看下图:
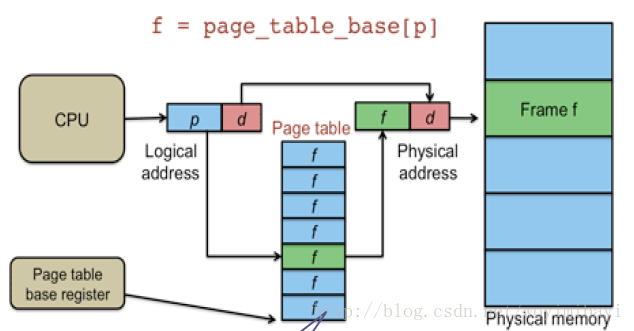
对于一个虚拟地址,0x12345670,地址的高20位表示页表的物理地址,也就是0x12345(对应图中的p),通过这个地址找到页表所在位置,读取该位置中的数据,这个数据指向物理地址页的索引。虚拟地址的低12位表示物理地址页索引的偏移值,也就是0x670(对应图中的d),我们现在有了物理地址页的索引值和偏移值,自然就可以找到所对应的物理内存位置。
另外MMU比较重要的一个组成部分需要介绍一下,TLB(Translation Lookaside Buffer)转换旁路缓存,顾名思义,他是一个物理地址和虚拟地址转换关系的高速缓存,是上图中Page table的cache,也被称为快表。
最后,附上宋老师的总结:http://mp.weixin.qq.com/s/SdsT6Is0VG84WlzcAkNCJA
内存分区和内存映射区
首先明确内存分区和内存映射区的区别,内存分区指的是实际的物理内存的分区,内存映射区指的是每一个进程所拥有的虚拟地址空间的分区情况。
对于一个运行了linux的设备,通常存在如下分区:DMAzone、Normal zone、HighMem zone。
DMAzone存在的原因是有些设备存在硬件缺陷,无法通过DMA访问全部的内存空间,为了让这些设备在需要内存的时候能够每次都申请到访问能力范围内的内存空间,内核规定了一个DMA zone,当这些设备申请内存的时候,指定分配flag为GFP_DMA,它就可以拿到DMA zone的内存。也就是说如果我们的设备不存在这样的存在缺陷的设备,我们就不需要DMA zone,或者说整个Normal zone都是DMA zone。
HighMemzone存在原因是,当内存较大时,内核空间的3-4G空间无法把所有物理内存地址一一映射到内核空间,只能映射一部分,那么无法映射的那部分就是高端内存。
可以一一映射到内核空间的那部分内存,除去DMA zone就是Normal zone。
内存映射区可以简单的理解为,每个进程拥有的4G空间。其中3-4G为内核空间,这部分空间又被划分为多个区域,其中与DMA zone和Normal zone存在一一映射关系的区域是DMA+常规内存映射区,也叫做low memory映射区,同时也专门有个区域可以映射HighMem zone,但是并不存在一一映射的关系,这个区域是高端内存映射区。
所谓的一一映射,是指虚拟地址和物理地址只是存在一个物理上的偏移。
在x86系统中,内存分区和内存映射区存在如下的关系:
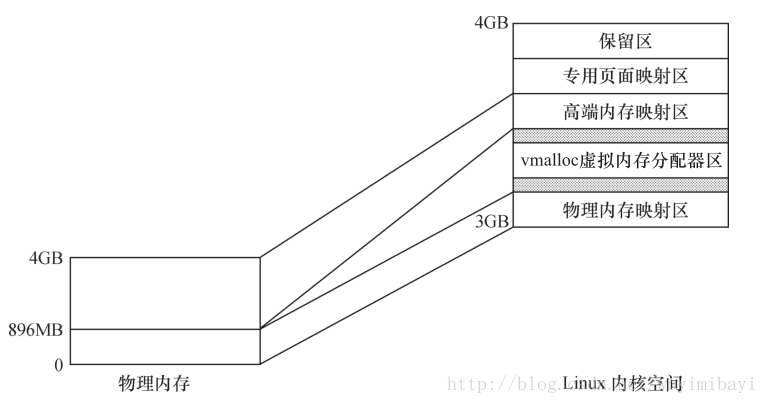
在arm linux中,内存分区和内存映射区的关系请参考内核文档Documentation/arm/memory.txt
Buddy算法是个什么鬼
Linux的最底层的内存分配算法叫做Buddy算法,它以2的n次方页为单位对空闲内存进行管理。就是说不管我在应用程序中分了多大的空间,1字节,100KB,或者其它任意的大小,底层实际分配的是以2的n次方个页对齐的空间,当然并不是每一次用户空间申请内存都会引起底层的内存分配,slab算法就可以在buddy算法的基础上对内存进行二次管理,分配更小的内存空间,当然C库也可以对分配的空间二次利用,比如指定mallopt函数的第一个参数为M_TRIM_THRESHOLD,并设置真正释放内存给系统的阀值。
Buddy算法的优点是避免了内存的外部碎片,但是长期运行后,大片的内存会比较少,而1页,2页,4页这种内存会非常多,当我们分配大片连续内存的时候就会出问题,具体解决办法请参考下一节-CMA的工作原理。
在linux系统中,我们可以通过/proc/buddyinfo文件来查看当前系统空闲的连续内存空间剩余情况。
CMA的工作原理
应用程序中申请一块内存,在应用程序看来是连续的,因为虚拟地址本身是连续的,但实际的内存空间中,所申请的这片内存未必是连续的,不过这对应用程序来说是没关系的,因为应用程序不需要关心实际的内存情况,只要MMU把物理地址映射成虚拟地址就好了。但是如果没有MMU的情况呢,我们又需要一片连续的内存空间,比如设备通过DMA直接访问内存,这种情况下应该怎么办呢?
CMA机制就是为了解决上面提到的问题而产生的。DMA zone并不是DMA专属,其它的程序也可以申请该zone的内存,如果当设备要申请DMA zone空间的一大片连续的内存时候,已经没有连续的大片内存了,只有1页,2页,4页的这种连续的小内存。解决办法就是我们标记某一片连续区域为CMA区域,这部分区域在没有大片连续内存申请的时候只给moveable的程序使用,当大片连续内存请求来的时候,我们去这片区域,把所有moveable的小片内存移动到其它的非CMA区域,更改对应的程序的页表,然后再把空出来的CMA区域给设备,从而实现了DMA大片连续内存的分配。
CMA机制并不是单独存在的,它通常服务于DMA设备,在设备调用dma_alloc_coherent函数申请一块内存后,为了得到一片连续的内存,CMA机制被调用,它保证了申请的内存的连续性。
另外CMA区域通常被分配在高端内存。
校正1:const变量需要c语言编译器的语义支持,编译后被放到rodata区,内核在程序装载时建立页表,标记该片内存区域为readonly。MMU提供运行时检查支持,感谢群里好友 丈二先生 的指正
