关注并星标
从此不迷路
计算机视觉研究院



公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
本文将分 2 期进行连载,共介绍 10 个在目标追踪任务上曾取得 SOTA 的经典模型。
第 1 期:MDNet、SiamFC、ADNet、CFNet、LSTM(RNN)
第 2 期:SiamRPN、SiamMask、UpdateNet、SiamAttn、SiamGAT
您正在阅读的是其中的第 1 期。
转自《机器之心》


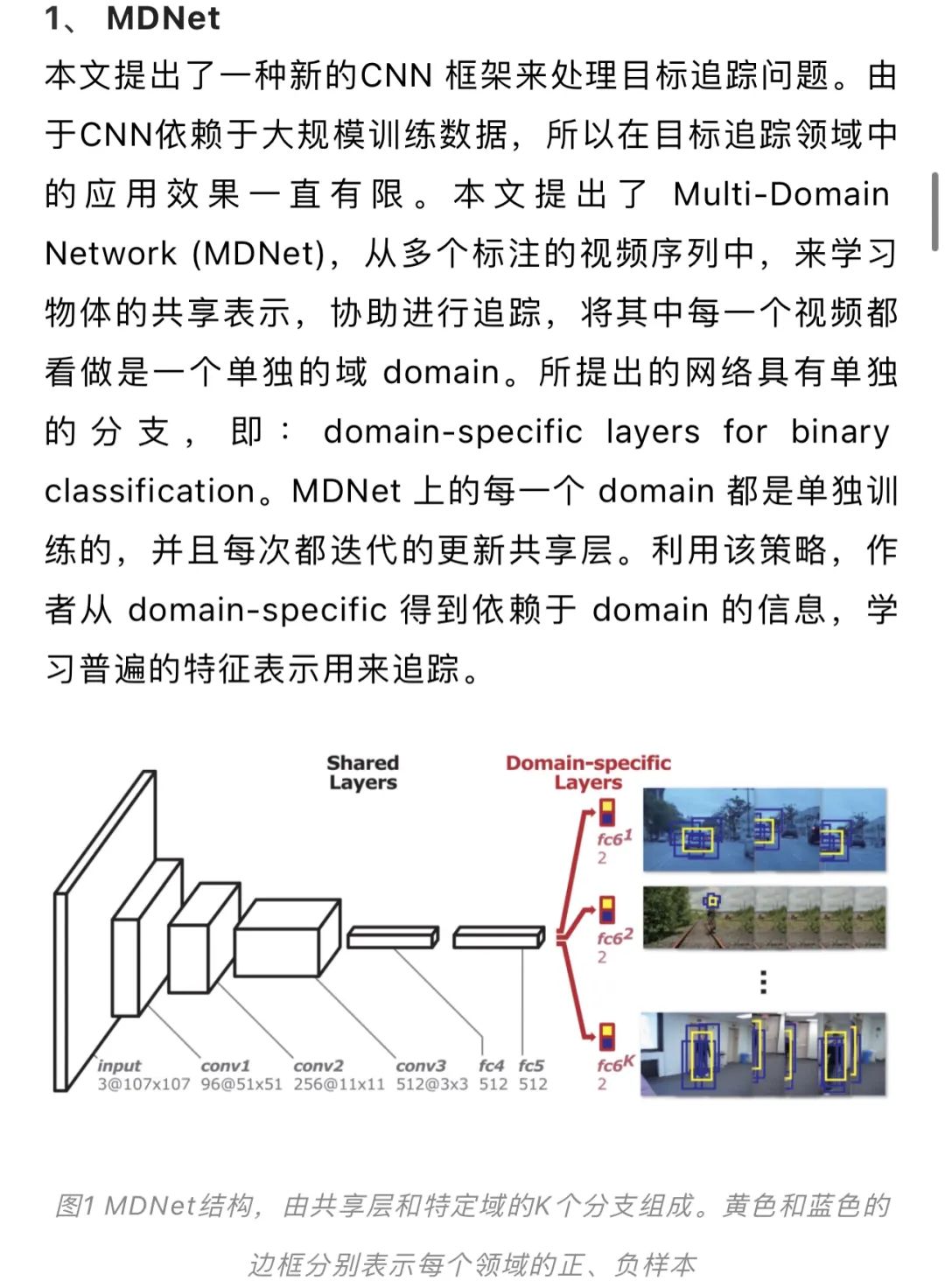



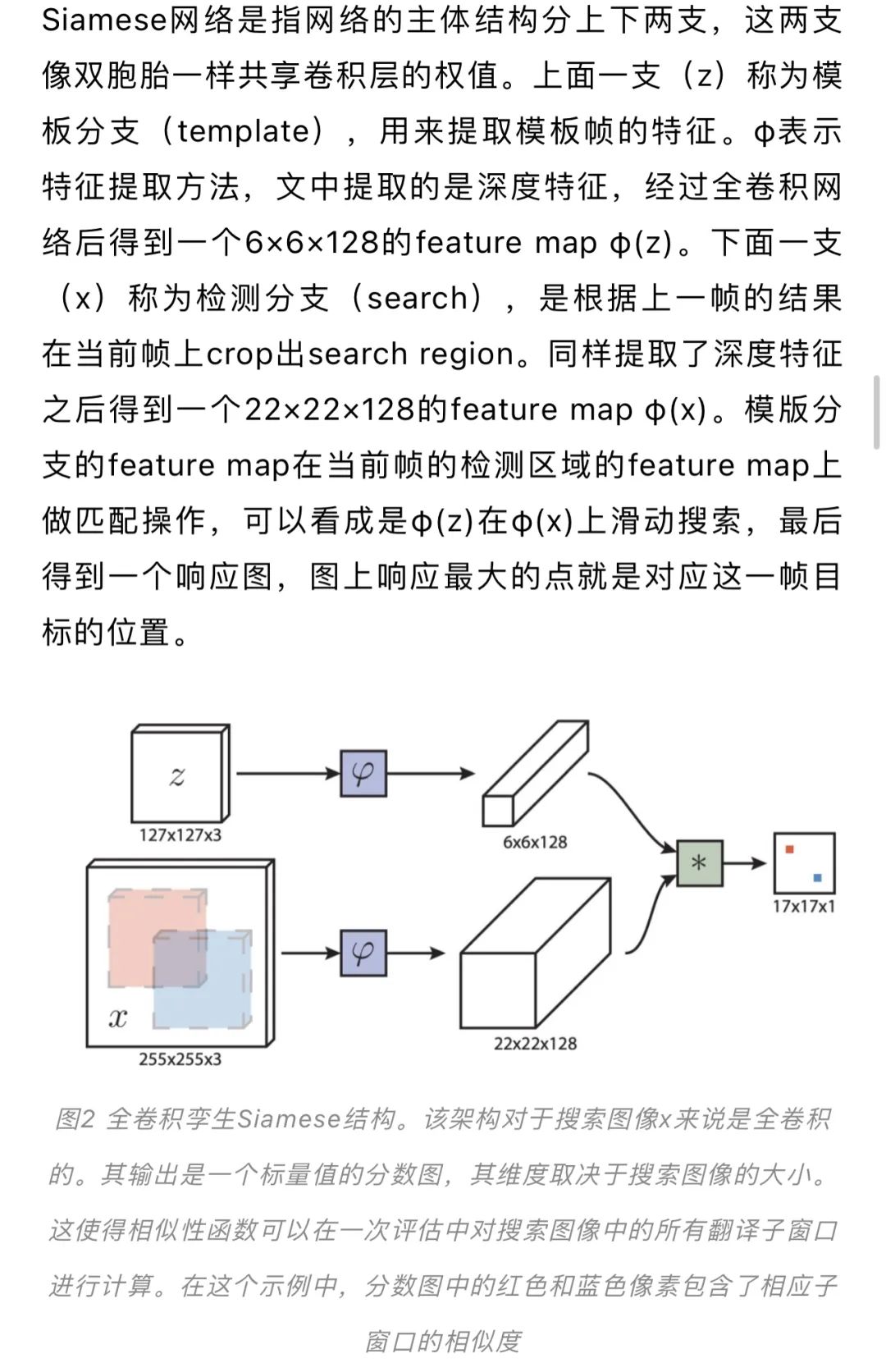




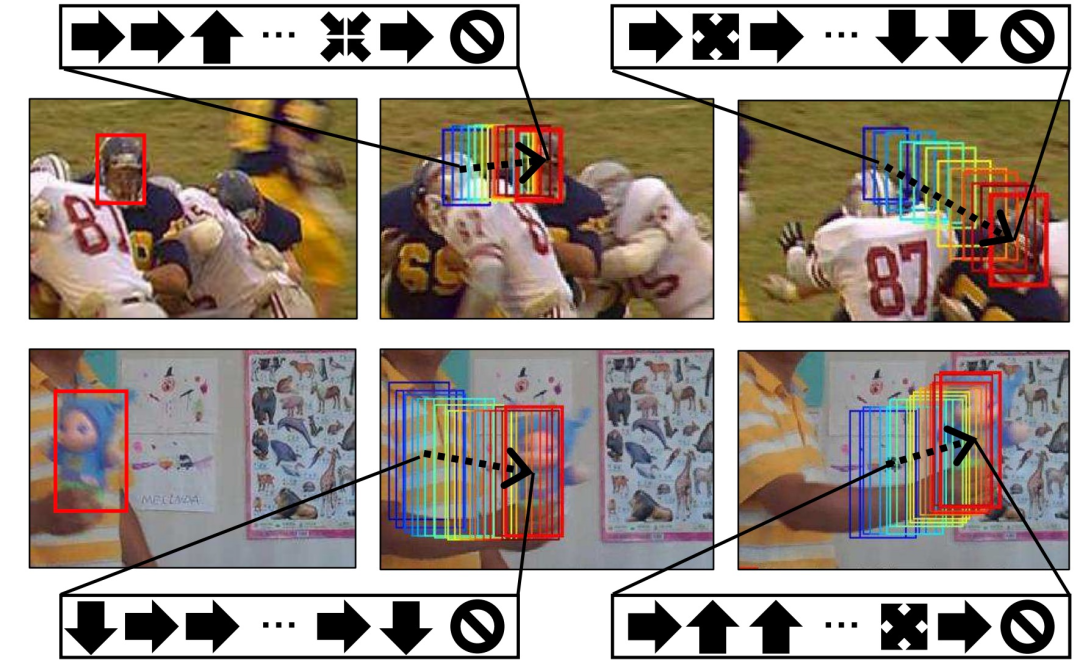 图3 本文提出的由顺序动作控制的视觉追踪的概念。第一列显示了目标的初始位置,第二和第三列显示了在每一帧中寻找目标边界框的迭代动作流程
图3 本文提出的由顺序动作控制的视觉追踪的概念。第一列显示了目标的初始位置,第二和第三列显示了在每一帧中寻找目标边界框的迭代动作流程
ADNet完整的网络架构如下图:
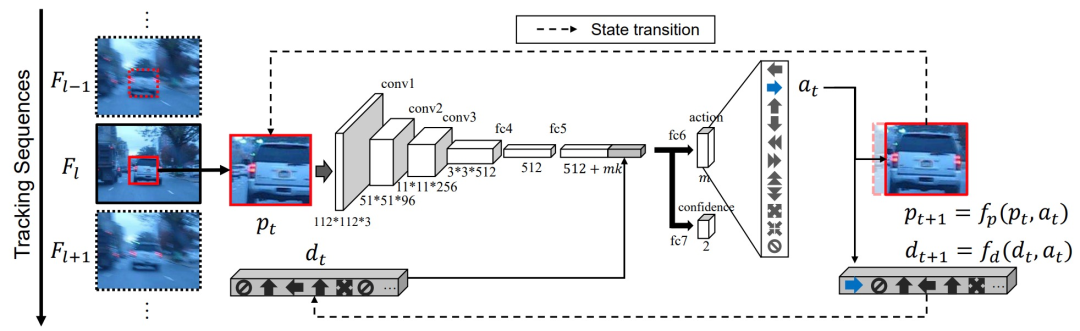 图4 网络结构。虚线表示状态转换。在这个例子中,选择 "向右移动 "的动作来捕捉目标物体。这个动作决定过程不断重复,直到最后确定每一帧中目标的位置
图4 网络结构。虚线表示状态转换。在这个例子中,选择 "向右移动 "的动作来捕捉目标物体。这个动作决定过程不断重复,直到最后确定每一帧中目标的位置
首先分析强化学习部分。
(1)状态。状态s_t分为p_t和d_t两部分。其中,p_t代表正在追踪的bbox(当前图片信息),d_t则是一个11x10=110维的向量,存储的是前10个动作,其中11代表的是11种不同的action,使用独热编码表示。
(2)动作。动作分为3类共11种。第一类是move,包括上下左右和快速上下左右;第二类是scale,包括放大和缩小;第三类是stop,即终止操作。

(3)状态转移。定义一个差值如下:
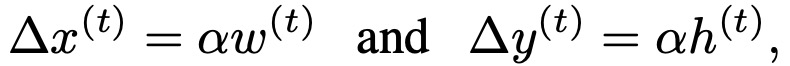
对于上下左右action(以此类推):
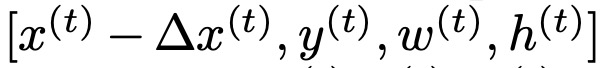
对于快速上下左右action(以此类推):
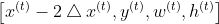
对于尺度变换action:
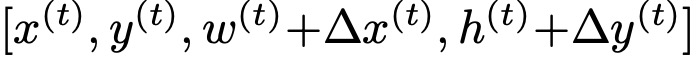
(4)奖励函数。假设动作序列action sequence的长度为T,则reward定义如下:
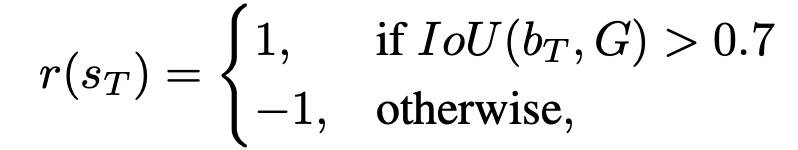
动作的终止有两种触发情况:①.选择了stop action;②.action sequence产生了波动(eg: {left, right, left})。
然后分析训练部分。
(1)训练监督学习部分
这部分训练{w1,w2,...,w7},训练部分的action lable通过以下方法获得:
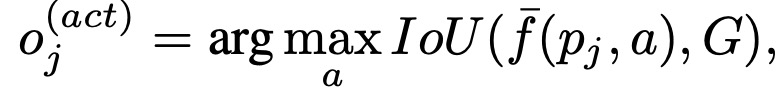
class lable的判断如下:
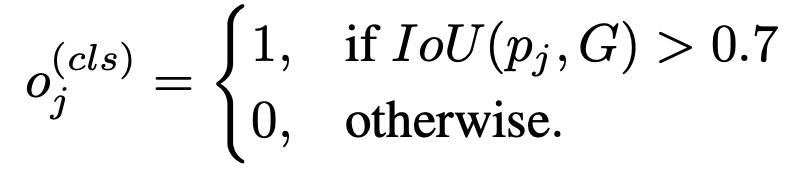
损失函数如下:
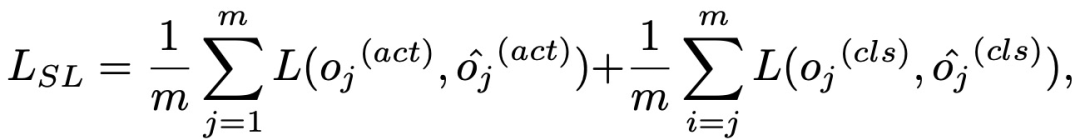
(2)训练强化学习部分。这部分就是使用SGD最大化:
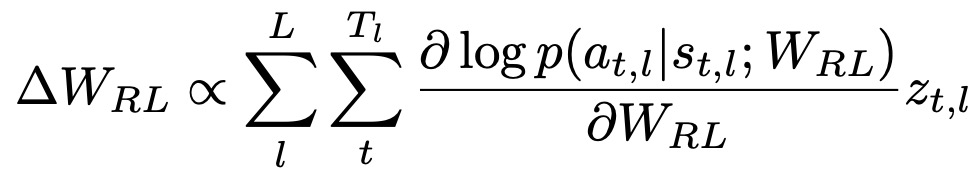
本框架可以训练ADNet,即使ground-truth{Gl}是部分给定的,也就是图5中所示的半监督设置。监督学习框架不能学习未标记的帧的信息,但是,强化学习可以以半监督的方式利用未标记的帧。为了在RL中训练ADNet,应该确定追踪分数{z_t,l},然而,在未标记的序列中的追踪分数不能立即确定。相反,我们将追踪分数分配给从追踪模拟结果中获得的奖励。在其他工作中,如果在无标签序列中追踪模拟的结果在有标签的帧上被评价为成功,那么无标签帧的追踪分数由z_t,l = +1给出。如果不成功,则z_t,l被赋予-1,如图5所示。

图5 半监督情况下对Walking2序列的追踪模拟说明。红框和蓝框分别表示ground-truth和预测的目标位置。在这个例子中,只有#160、#190和#220帧被注释了。通过连续的行动,agent在#190帧获得+1奖励,在#220帧获得-1奖励。因此,从#161到#190帧的追踪得分将是+1,#191和#220之间的追踪得分是-1
(3)在线自适应。在线更新的时候,只对{w1,w2,...,w7}进行更新。每帧使用前面帧中置信分数大于0.5的样本进行微调。如果当前的置信分数小于-0.5,说明“跟丢了”,需要进行re-detection。
4、 CFNet
不同数据集间场景(域)差异较大(large domain differences)且视差分布不平衡,这极大地限制了现有深度立体匹配模型在现实生活的应用。为提高立体匹配网络的鲁棒性,文中提出一种基于级联和融合的代价量网络:CFNet。具体来说,作者基于SiamseFC的结构引入CF层(Correlation Filter),网络通过端到端训练,证明可以用较少网络的卷积层数而不降低准确度。CFNet整体结构如图6 所示:
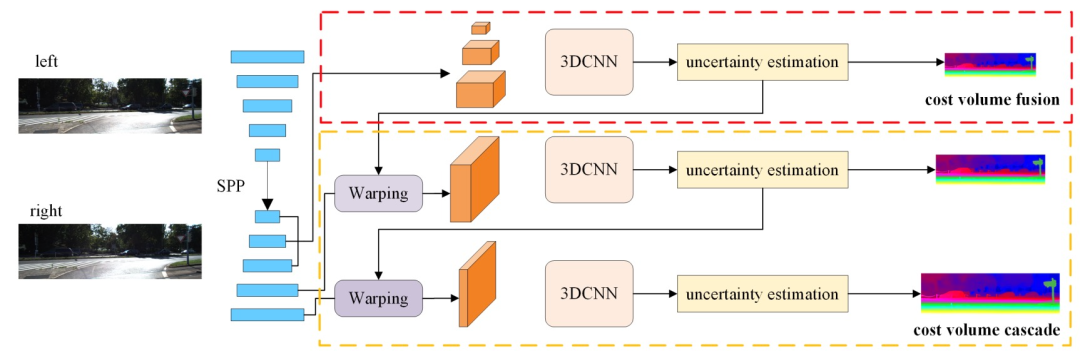 图6 CFNet整体结构,网络由3部分组成:金字塔特征提取网络、融合代价体和级联代价体
图6 CFNet整体结构,网络由3部分组成:金字塔特征提取网络、融合代价体和级联代价体
CFNet网络由三部分组成:金字塔特征提取网络 — pyramid feature extraction;融合代价体 — fused cost volume;级联代价体 — cascade cost volume。
金字塔特征提取网络。该网络是带有跳跃连接的编码器解码器结构,由 5 个残差块组成,提取多尺度图像特征。后面紧接一个SPP(Spatial Pyramid Pooling,空间金字塔池化)模块,用以更好的合并多尺度特征的上下文信息。SPP模块就是对特征进行不同Size的池化,然后进行信息融合。
融合代价体。文中提出融合多个低分辨率密集代价体(小于原始输入图像分辨率的1/4的代价体,代码中是1/8,1/16,1/32),以减少初始视差估计中不同数据集之间的域差异 (domain shifts)。很多工作都意识到多尺度代价体的重要性,但这些工作通常都认为低分辨率的代价体特征信息不足,无法生成准确的视差图,所以弃之不用。但文中认为不同尺度的低分辨率代价体可以融合在一起提取全局结构化表示,其生成的初始视差图更加准确(鲁棒)。具体的,在每个尺度上分别构建低分辨率成本体积,文中同时使用特征拼接(feature concatenation)和组相关(group-wise correlation)来生成融合代价体,公式如下:
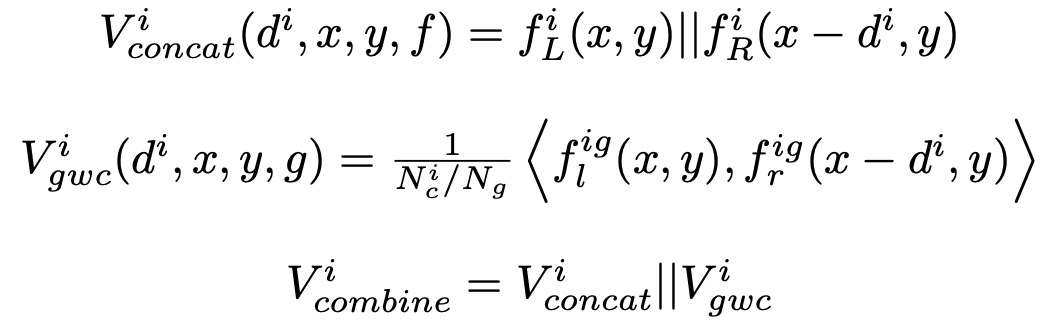
接下来对代价体进行融合。如图7,首先对每个 cost volume 使用 4 个具有skip connection的 3D 卷积层(每个分支的前四个蓝色块)。使用stride = 2 的 3D 卷积将 scale3 的分辨率从 1/8 降到 1/16。然后将下采样后的 scale3 和 scale4 拼接再通过一个额外的 3D 卷积将特征通道缩放。继续采取类似的操作来逐步将 scale3 的 cost volume 下采样到原始输入图像分辨率的 1/32与 scale5进行信息融合 ,最后采用 3D 转置卷积对 cost volume上采样并对上采样后的 cost volume 利用特征信息进行细化。对细化后的 cost volume 进行视差回归(soft argmin operation)就可以得到初始视差图:
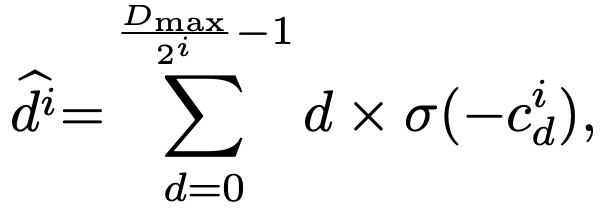
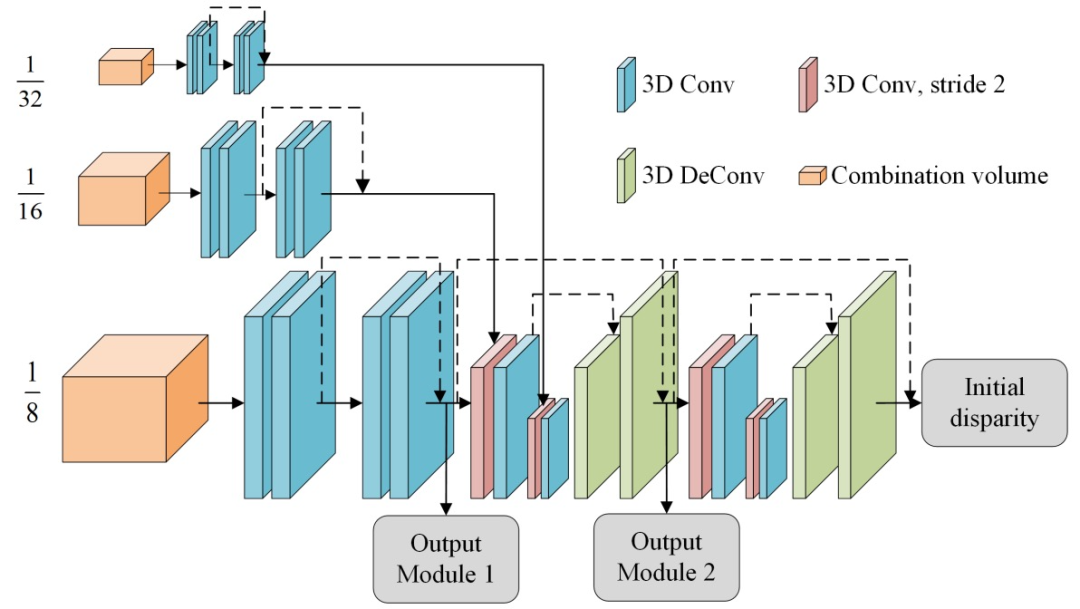
图7 成本代价体融合模块结构。三个低分辨率的成本代价体(i∈(3, 4, 5))被融合以生成初始差异图
级联代价体。有了初始化视差下一步就是构建高分辨率的cost volume,细化视差图。理想的视差概率分布应该是单峰的,即该位置属于某个视差的概率非常高、属于其它视差的概率非常低。然而视差的实际的概率分布主要是多峰,即对某个位置的视差不是很确定,这种情况常出现于遮挡、无纹理区域。文中提出定义一个不确定性估计来量化视差概率分布趋向于多峰分布的程度:
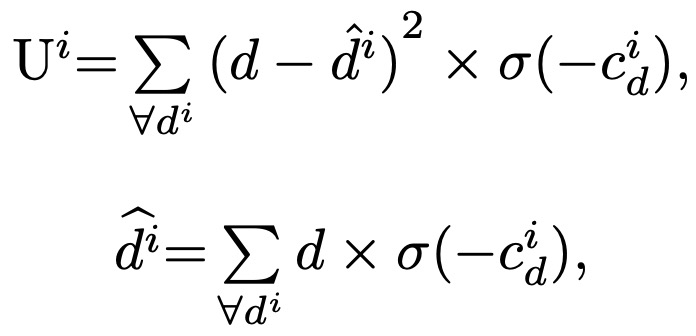
文中根据当前阶段的不确定性来计算下一阶段的视差搜索范围,具体公式如下:
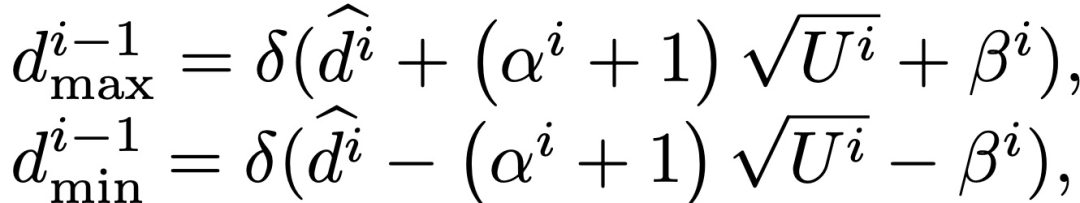
根据均匀采样,得到下一阶段离散的平面假设深度:
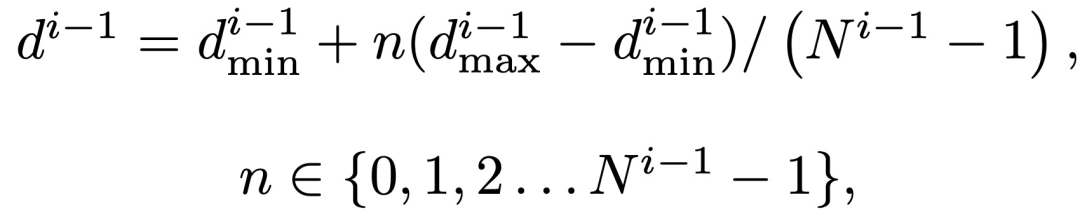
5、 LSTM(RNN)
本文提出了一种对长时间存在的多线索依赖关系进行编码的在线追踪方法。其中,为了解决不能很好地对发生遮挡或具有相似外观环绕的目标进行区分追踪的问题,本文提出使用RNN架构、结合一定时间窗内的多线索来进行追踪的方法。通过该方法,我们可以修正数据关联的错误,以及从被遮挡状态中恢复原目标观测。本文证明了使用目标的外观、运动以及交互这三个方面来进行数据驱动的追踪算法的鲁棒性。
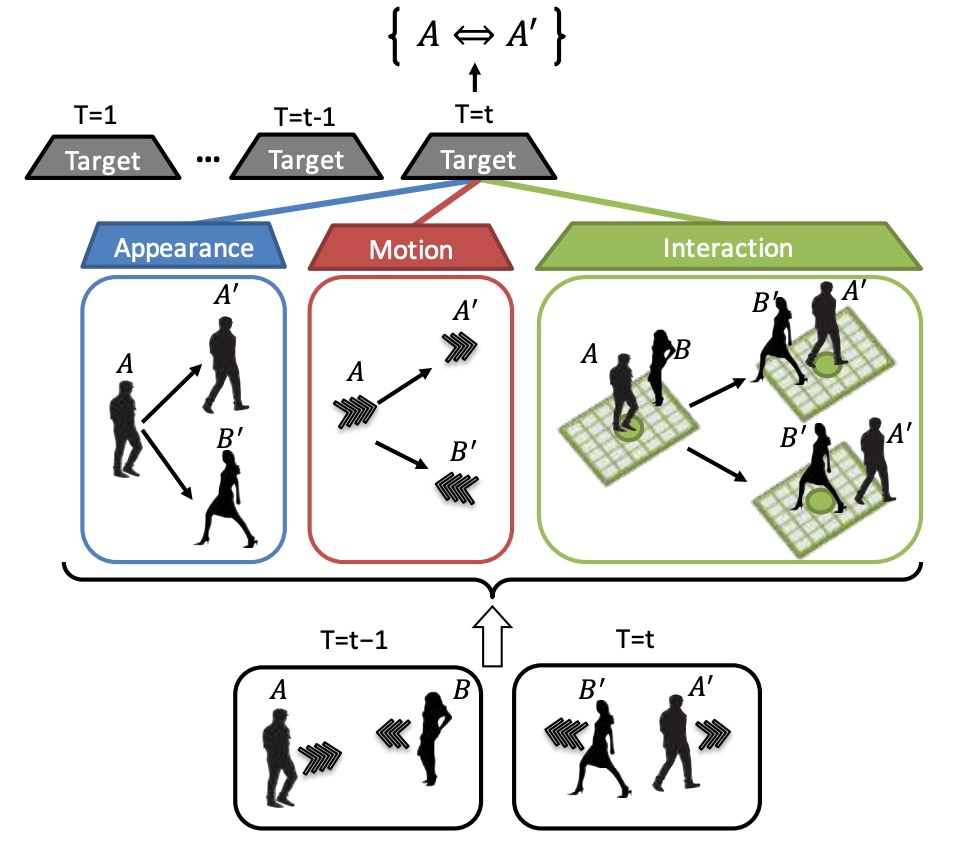
本文引入了一种新的方法来计算相似度。三个特征提取模块将提取出的特征分别输入3个RNN:(A)(M)(I),计算出对应特征向量( ϕA , ϕM , ϕI ),这些向量再输入一个RNN(O) 得到结合了多信息通道的最终特征向量ϕ(t,d),这个向量将用于计算target t和detection d之间的相似度。
首先介绍外观模型(A)。外观模型主要用于解决重识别问题,同时还要能够处理遮挡和其他视觉问题。外观模型是一个基于CNN和LSTM结构的RNN,首先将不同帧数的轨迹目标图像传入CNN,得到500维的特征向量,然后将序列所有特征向量传入LSTM得到H维特征向量,接着将当前目标检测也传入CNN得到H维特征向量,连接两个H维特征向量并传入FC层得到k维判别外观的特征向量。最后的ϕA特征包含的信息是:基于target i 的长时外观特征以及detection j 的外观特征,判断两者是否属于同一目标。外观模型如图9:
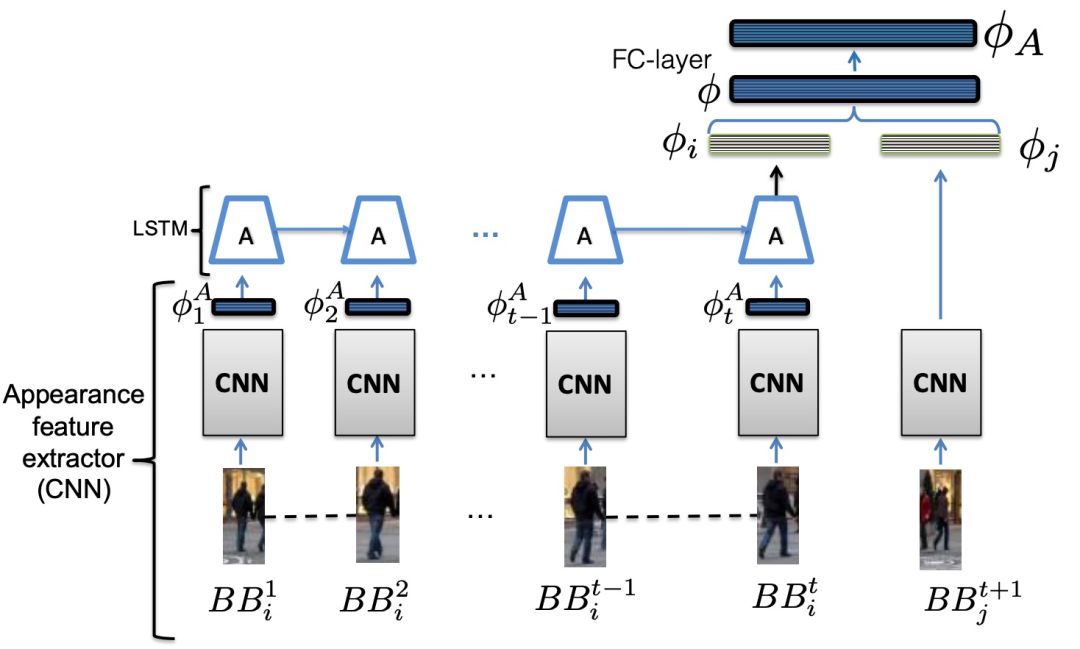
图9 外观模型。输入是目标i从时间1到t的bounding box,以及我们希望比较的时间t+1的检测j。输出是一个特征向量φA,它编码了时间t+1的bounding box是否与时间1、2、...的特定目标i相对应。使用一个CNN作为外观特征提取器
其次介绍运动模型(M)。运动模型主要用于判断目标是否被遮挡或产生其他状况,其主要面临问题在于在遇到干扰的目标检测时会有不好的结果,因此本文使用LSTM来处理这类问题。除了CNN外,运动模型和外观模型的结构类似,唯有输入从图像变成了运动向量,该向量主要包括x,y两个方向的速率变化,其余输出的维度以及预训练的操作都保持不变。如图10。运动特征提取器(Motion feature extractor)所提取的2维速度特征v_{i}^{t}通过下式计算:
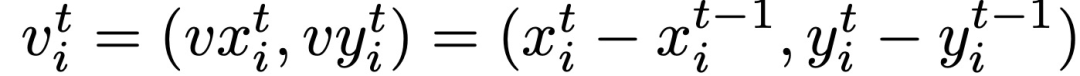
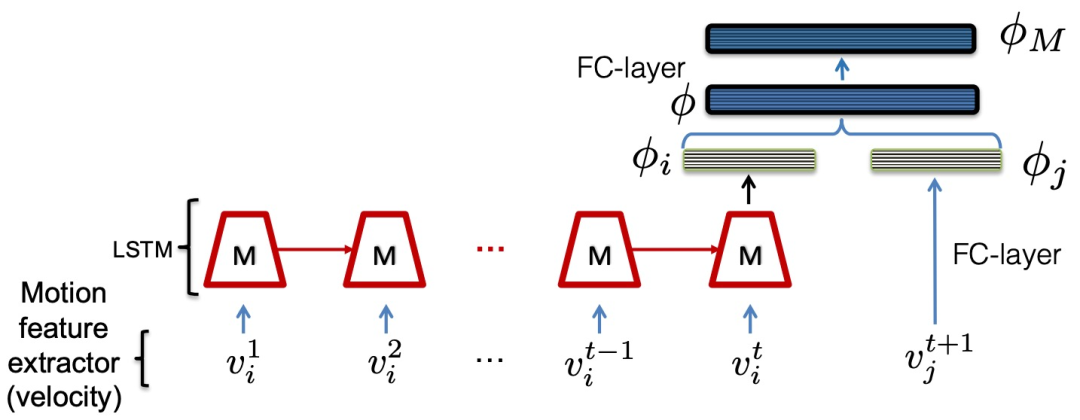
图10 运动模型,输入是目标的二维速度(在图像平面上)。输出是一个特征向量φM,用于编码速度v_{j}^{t+1}是否对应于真实轨迹v_{i}^{1}, v_{i}^{2}, .... , v_{i}^{t}
最后是交互模型(I)。交互模型主要用于处理目标与其周围事物的作用力关系。由于目标附近的其他目标数量是会发生变化的,为了使网络模型使用相同的输入大小,本文将每个目标的周围都建模成固定的"占有块"。和运动模型的结构相同,只有输入变成了"占有块图",其余皆不变。把每个目标的周围区域建模为一个固定大小的occupancy grid(可被占用的网格图,0/1)。交互特征提取器对以目标target为网格中心,生成一张网格图,并转化为向量表达。如果周围某物体的bbox中心落在网格(m,n)处,则网格(m,n)位置处标为1,不被占用的网格位置为0。网络结构如图11。数学公式表达为:
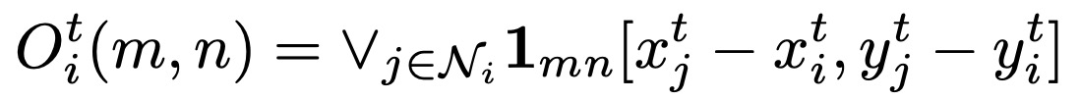
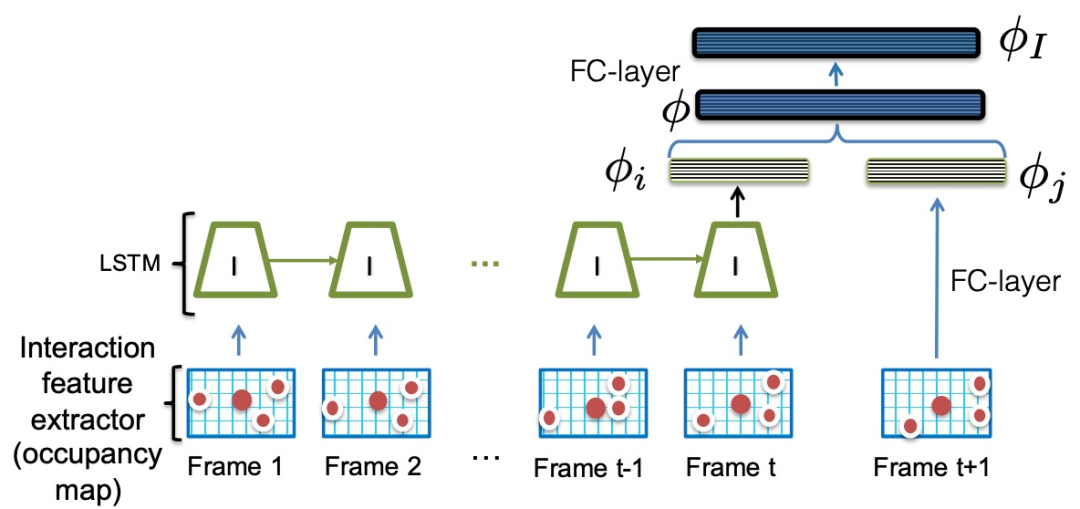
图11 交互模型,输入是跨时间的占用图(在图像平面上)。输出是一个特征向量φI,它编码了时间t+1的占用图是否对应于时间1、2、...t的占用图的真实轨迹
当外观模型、运动模型、交互模型分别提取出k维特征向量后,将这些特征向量拼接后作为target RNN(O)的输入。整个训练过程可以分为两步:
首先,分别独立预训练 A/M/I 三个子模块RNN模型,以及外观特征特征提取器CNN。外观特征提取器CNN先使用VGG-16的预训练权重 ,移除最后一个全连接层,添加一个500维的全连接层。然后用这个结构构造一个Siamese网络,在re-identification数据集上进行训练。最后再将这个训练完的CNN网络单独拿来用作特征提取,可以得到500维具有强区分度的外观特征。三个子模块RNN都用Softmax分类器进行0/1分类的预训练,即在RNN输出的k维特征上再加一个Softmax层,输出正类/负类的概率。这里我们定义,正类指输入的target i 和 detection j 属于同一物体,负类反之。
其次,联合训练 target RNN(O) 和前面提到的三个子模块RNN,即同时更新它们的网络参数,但CNN不再更新。这是一个端到端的训练过程,target RNN要求输出detection和target的相似度,使用Softmax分类器和交叉熵损失进行训练。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606
