引言
最近一段时间我接触到了一些气象学方面的文件处理。nc文件处理气象学的各位都要用到,那么在此我将介绍一下如何使用python批量下载ERA5数据并将多年的nc文件合并成一个。
数据下载
本文采用的数据是ERA5每日降雨量数据,数据的时间范围是1980年至2005年,空间范围是21N到25N,110E到117E。
可以按照以下步骤使用 Python 和 CDS API 批量下载 ERA5 地每日降雨量数据:
第一步
安装 CDS API。首先需要在终端中安装 CDS API,使用以下命令:
pip install cdsapi第二步
获得数据下载的API Key
打开ERA5官网ERA5-Land hourly data from 1950 to present (copernicus.eu)
注册账号并登录。
打开How to use the CDS API | (copernicus.eu)
如果你是登陆状态,会显示你的key
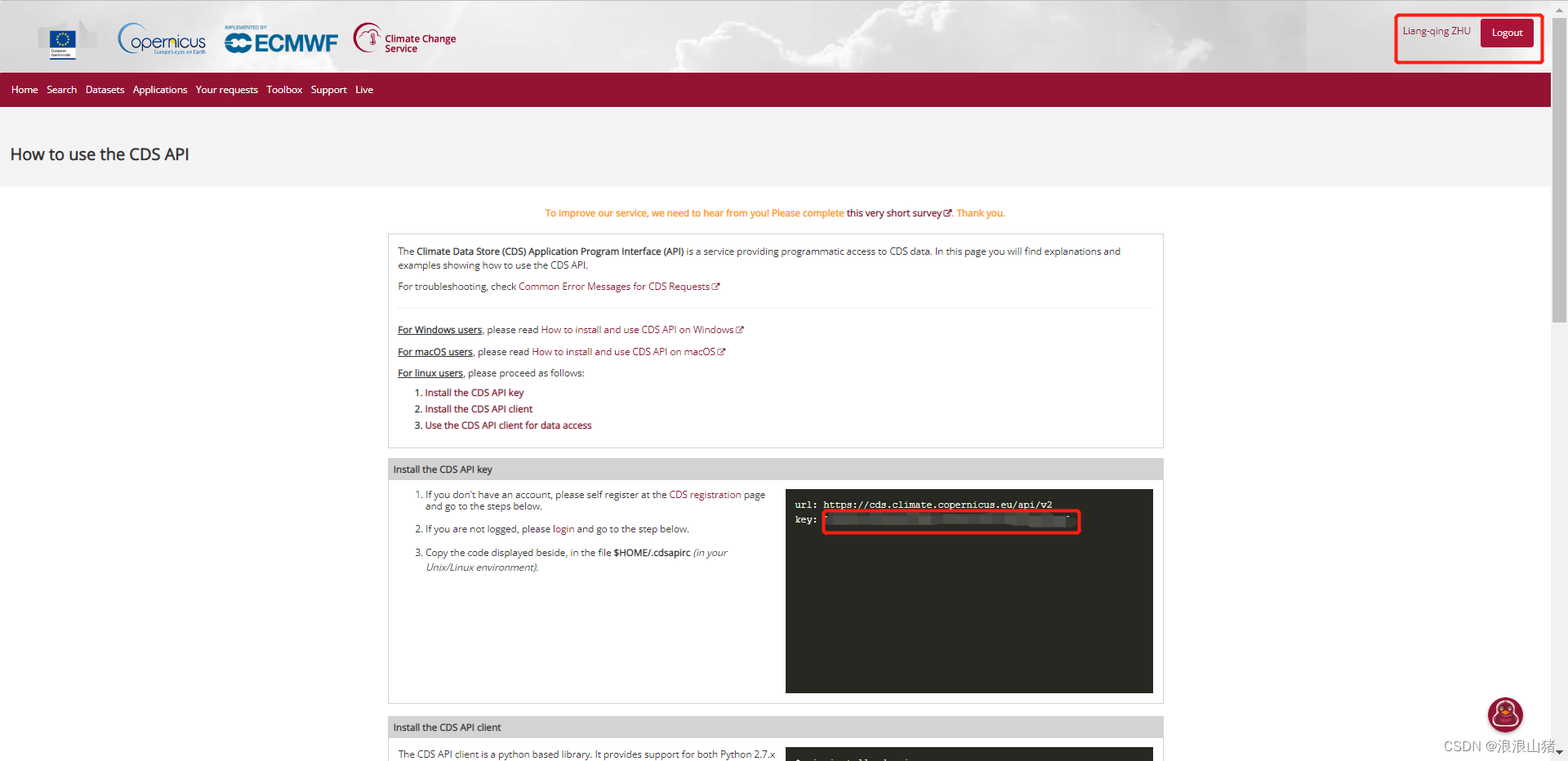 第三步
第三步
写 Python 脚本。在 Python 脚本中编写代码来调用 CDS API 并批量下载 ERA5 每日降雨量数据。以下是示例代码:
import cdsapi
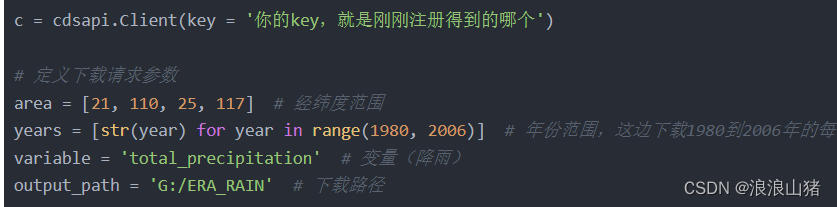
c = cdsapi.Client(key = '你的key,就是刚刚注册得到的哪个')
# 定义下载请求参数
area = [21, 110, 25, 117] # 经纬度范围
years = [str(year) for year in range(1980, 2006)] # 年份范围,这边下载1980到2006年的每日降雨量数据
variable = 'total_precipitation' # 变量(降雨)
output_path = 'G:/ERA_RAIN' # 下载路径
# 循环下载每一年的数据
for year in years:
c.retrieve(
'reanalysis-era5-single-levels',
{
'product_type': 'reanalysis',
'variable': variable,
'year': year,
'month': [
'01', '02', '03',
'04', '05', '06',
'07', '08', '09',
'10', '11', '12'
],
'day': [
'01', '02', '03',
'04', '05', '06',
'07', '08', '09',
'10', '11', '12',
'13', '14', '15',
'16', '17', '18',
'19', '20', '21',
'22', '23', '24',
'25', '26', '27',
'28', '29', '30',
'31'
],
'time': '00:00',
'format': 'netcdf',
'area': area
},
output_path + '/era5_' + variable + '_' + year + '.nc'
)
以上代码中,根据个人情况输入你的key,经纬度范围,时间范围,和下载路径。只改这一部分
需要注意的是,ERA5不仅仅可以提供降雨数据,还有许多数据都可以提供,并被国际认可可作为气象观测数据。本文中下载的是降雨量数据。如果想深入探索其他的数据下载,可转移至这篇知乎文章:ERA5(欧洲中期天气预报中心)再分析数据集介绍与下载 - 知乎 (zhihu.com)
合并数据
下载完成的数据如下图所示:

每个文件就是当年的每日降雨量数据,本文下载了从1980至2005年的数据。如果要做后期处理,最好在时间尺度上把他们合并为一个文件。
下面介绍如何合并nc文件:需要注意的是如果你合并的多个文件中包含不同的变量或坐标系,可能需要进行额外的处理以确保它们可以正确地对齐。本文数据是批量下载的同一区域的数据,只是时间上不同,需要在时间上依次合并成一个文件,所以这么写
第一步:
导入必要的库
import xarray as xr
第二步:
使用 xr.open_mfdataset() 函数打开多个 NetCDF 文件,并将它们合并为一个数据集。以下是示例代码:
# 定义要合并的文件名列表
filenames = ['path/to/file1.nc', 'path/to/file2.nc', 'path/to/file3.nc']
# 打开多个文件,并合并为一个数据集
ds = xr.open_mfdataset(filenames, combine='nested', concat_dim='time')
filenames是包含所有要合并的 NetCDF 文件名的列表。combine='nested'表示要使用嵌套的方式来合并多个数据集,以便在内存中生成更大的数据集。concat_dim='time'表示要将所有数据集沿着时间维度拼接在一起。
第三步:
将合并后的数据集保存为一个 NetCDF 文件。以下是示例代码:
# 定义输出文件的路径和名称
output_file = 'path/to/merged_file.nc'
# 将合并后的数据集保存为一个 NetCDF 文件
ds.to_netcdf(output_file)
完整代码
import xarray as xr
#定义要合并的文件名称
filenames = []
for i in range(26):
year = 1980 + i
filenames.append('G:\\ERA_RAIN\\era5_total_precipitation_{}.nc'.format(year))
# print(filenames)
#用xr.open_mfdataset() 函数打开多个 NetCDF 文件,并将它们合并为一个数据集
ds = xr.open_mfdataset(filenames, combine='nested', concat_dim='time') #filenames 是包含所有要合并的 NetCDF 文件名的列表。combine='nested' 表示要使用嵌套的方式来合并多个数据集,以便在内存中生成更大的数据集。concat_dim='time' 表示要将所有数据集沿着时间维度拼接在一起。
# 定义输出文件的路径和名称
output_file = 'G:\\ERA_RAIN\\merged_file_1980_2005.nc'
# 将合并后的数据集保存为一个 NetCDF 文件
ds.to_netcdf(output_file)因为文件太多了,所以定义了一个for循环用于批量输入文件路径,大家可根据自身需要修改filename。如何修改看合并数据的第二步。
现在我们就将nc数据合并了

注意filename中文件路径要按照时间顺序输入。