本文已获授权,部分有删改。来源:Xtreme1
自 2012 年以来,深度学习技术变革引起的人工智能热潮,这股势头已经持续十年。在去年底 ChatGPT 的出现,大模型的超能力完全展现在大众的视线中,将人工智能行业又推向了一个全新的发展阶段,许多研究者更是惊呼“ChatGPT 爆火后,NLP 技术不存在了” [1]。因为过去的自然语言专家,有着擅长于自己的领域,有人专门做文本分类、有人专门做信息抽取、有人做问答、有人做阅读理解,而在大模型范式下,一个大语言模型就能实现多种NLP任务的完美统一。
计算机视觉(CV)领域,大家也都密切关注着“大一统”模型,所谓的“ImageGPT”以及“多模态 GPT”的发展。
4 月 5 日 Meta 发布了Segment Anything Model(SAM)——第一个图像分割基础模型,可以称得上是当前最先进的一种图像分割模型,其将NLP领域的prompt范式引进CV,让模型通过prompt一键抠图,在照片或视频中对任意对象实现一键分割,并且能够零样本迁移到其他任务[2],这意味着图片大模型时代已经来临。
同时,让人不禁发问,学术界和商用落地场景使用的、耗时耗力的人工标注的标准答案(Ground truth)是否还有存在的必要?
(文末有图像分割开源数据集推荐)
一、 什么是图像分割?
图像分割(Image Segmentation)是图像处理中的一种技术,也是计算机视觉领域核心任务之一。它是预测图像中每一个像素所属的类别或者物体,输出不同类别的像素级掩码。简单来说,就是将图像中的每个像素标注为属于哪一个对象,比如人、车、树等等,并精细地标注出每个物体的具体位置和形状。
大体上,图像分割可以分为三个子任务: 实例分割 (instance segmentation) 、语义分割 (semantic segmentation) 、全景分割 (panoptic segmentation),这三个子任务都有着大量的算法与模型。他们在计算机视觉、医学影像处理、数字艺术等领域都有广泛的应用。

目标检测与语义分割标注
二、“Segment Anything”项目发布了什么?
Meta 发布了“Segment Anything Model(SAM)”和相应的数据集 SA-1B(segment anything),这是一项新的图像分割任务、模型和数据集。
核心亮点:
1. 该模型被设计和训练为可提示性(promptable),支持文本、关键点、边界框等多模态提示。你可以用一个点、一个框、一句话等方式轻松分割出指定物体;甚至接受其他系统的输入提示,比如根据AR/VR头显传来的视觉焦点信息,来选择对应的物体;
2. 可以非常灵活地泛化到新任务和新领域。积累了大量学习经验的SAM 已经能够理解对象的一般概念,不要额外训练,即可对不熟悉的物体和图像进行全自分割标注,可以为任意图像或视频中的任何对象生成掩码;
3. 对于稠密的图片,仍然有非常好的分割效率和效果;

4. 使用高效的SAM模型构建了迄今为止最大的分割数据集SA-1B(segment anything),包括超过 1 亿个 Mask 图和 1100 万张符合许可证的图片。为模型提供了充足的训练数据,有望成为未来计算机视觉分割模型训练和评测的经典数据集。
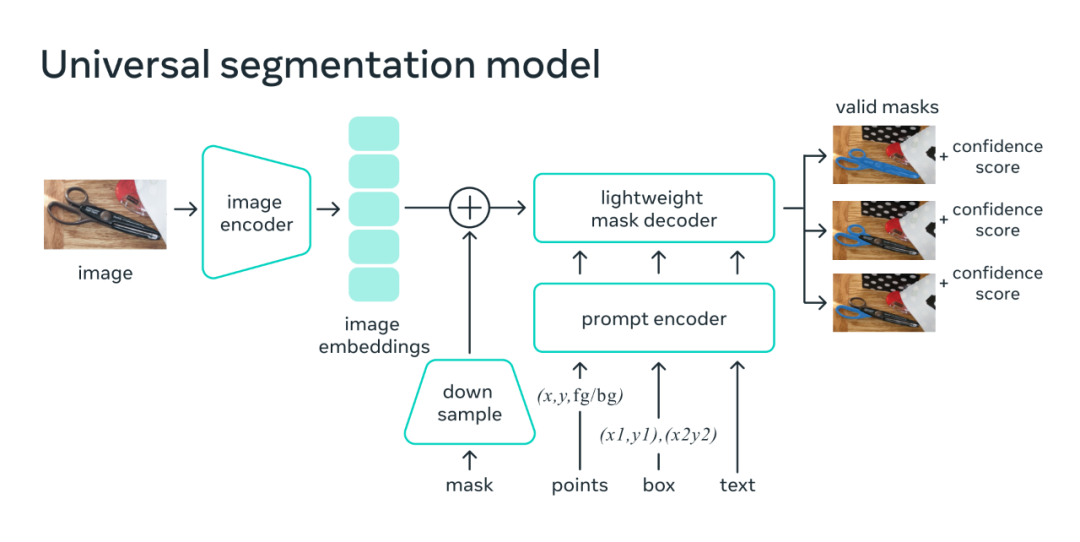
要知道,以往创建准确的分割模型“需要技术专家通过 AI 模型训练和大量人工精细标注数据进行高度专业化的工作”。而Meta 创建 SAM,旨在减少对专业培训和专业知识的需求,让这个过程更加“平等化”,以求推动计算机视觉研究的进一步发展。
三、 Segment Anything Model 的效果如何?
Meta 表示,SAM 已经掌握了对物体的一般概念,能为任何图像或视频中的任何物体生成 Mask,即使在训练过程中没有遇到过这些物体和图像类型。SAM 足够通用,覆盖了广泛的用例,并可在新的图像“领域”(例如水下照片或细胞显微镜图像)上直接使用,无需额外训练(这种能力通常称为零样本迁移)。


SAM与人工标注的对比
四、我们所看到的挑战与机遇
市场上早有相似的技术
在此之前我们见过很多不错的分割工具,例如 Photoshop 软件或 IOS 系统中自带的抠图功能,它们都能生成不错的效果,也用不错的交互体验提高了图像处理的效率,与SAM模型有着类似的功能。
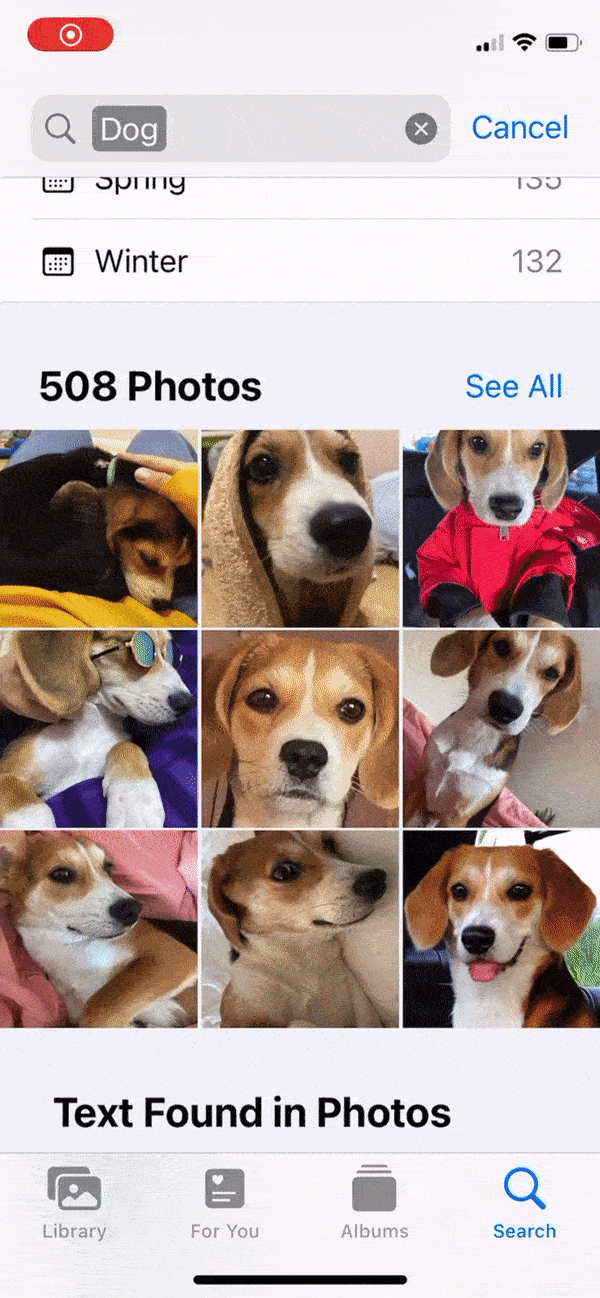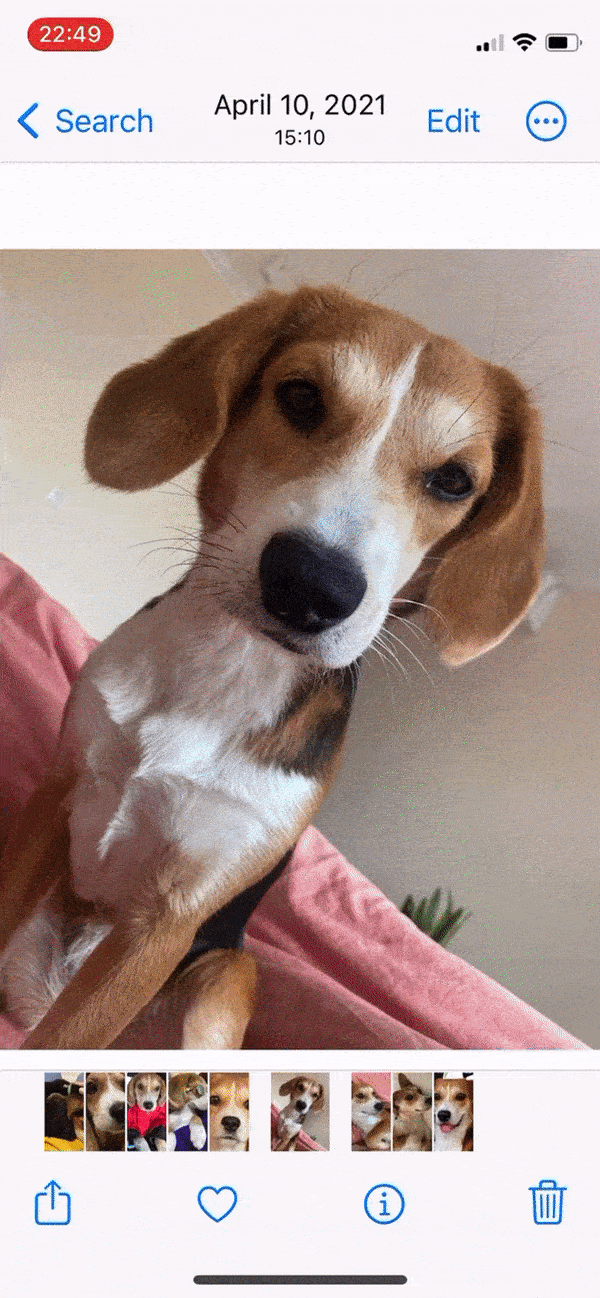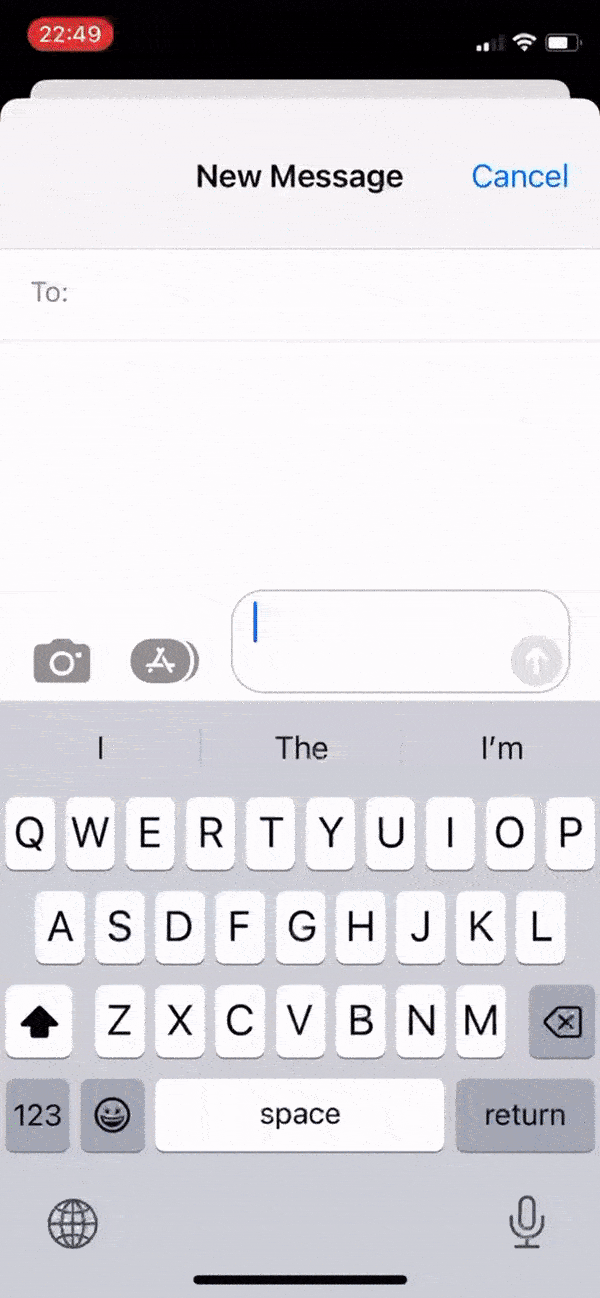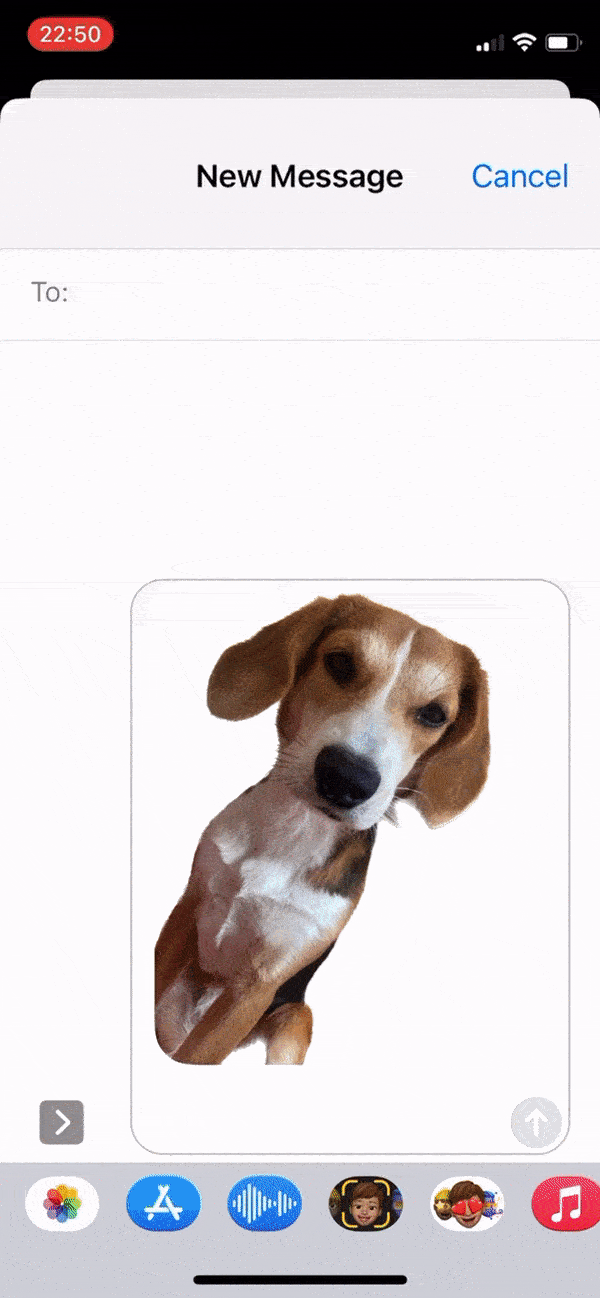
在 iOS 16 及更高版本中,您可以将照片的主题抠图出来,然后复制或共享
开源数据集的“标准答案(Ground truth)错误百出
图像算法工程师在商业项目中,经常会要求标注员重新标注开源数据集,这花费了不少的成本。这主要是原因是开源数据集的“标准答案(Ground truth)”并不标准,其中存在这大量的标注错误。

对于一些细分场景的研究时,这些人工标注是不能达到数据质量的要求的。例如,一位工程师在做交通灯的场景相关研究时发现,COCO 等数据集的标注错误是非常明显的。这些问题也存在于其它的知名数据集,例如 CIFAR-100和ImageNet。数据标注是一项容易出错的艰巨任务,其原因既有模糊的标注要求文档说明,也有人为主观判断不一致性等。SAM模型同样也存在部分漏标、误标问题。

COCO 数据集关于红绿灯的错误标注
无法胜任于专业领域
因此,前文提到的 SAM 与人工标注的比较时,它已经非常接近或者在某些数据分割的表现超越了人工标注结果时,我们只是惊讶——为什么开源数据集的质量这样差?相信也没有人会 100% 使用 ChatGPT 回复的结果,放在自己的文章中,我们在其中不得不接受那些很有道理但是扭曲了事实的“胡说八道”。通用大模型所训练的专业数据不够时,也无法满足项目的需求。在一些严谨的学科,例如在医学诊断,自动驾驶,安防等领域,我们是无法容忍这样的错误的。对于专业领域、非通用型图像,SAM标注不够理想。
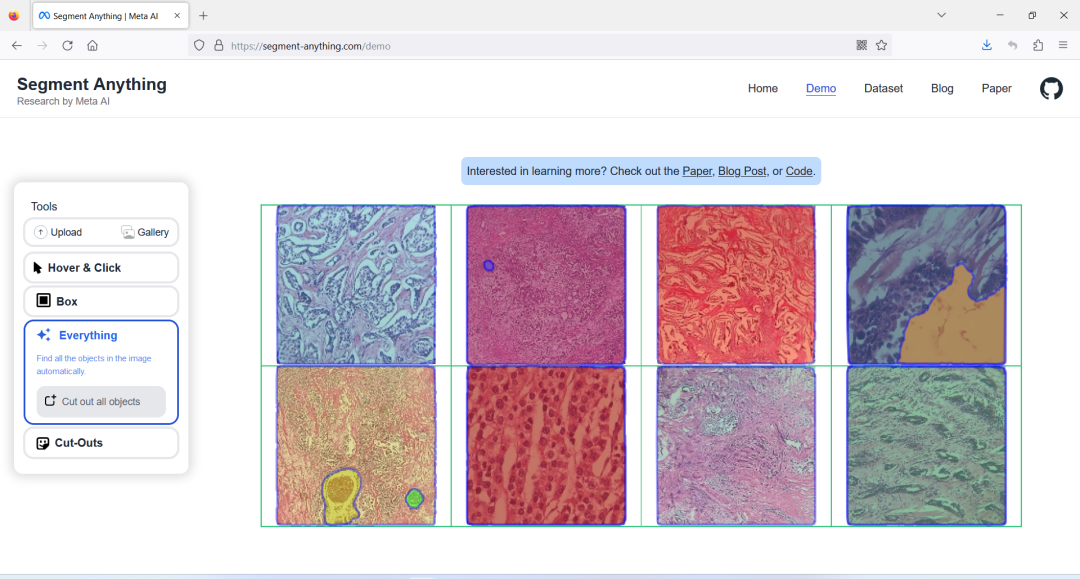
SAM 在医学方面的数据标注并不理想,这要求具有专业背景的医生来完成此项工作
其他挑战
这里还有类似于 ChatGPT 已经遇到的算力问题和数据安全。在实际环境中,很多上线的小型模型也无法承受过大的运行成本等。
机遇
确实,随着人工智能技术不断的发展,传统的 NLP、CV 技术未来可能会逐渐淘汰。未来的研究方向应该聚焦于更深层次、更抽象的框架下进行思考和探索。
● 接受并利用尖端技术:革命性的新技术所带来的不应是对行业的惶恐的绝望,我们要试图去理解并利用它,这些新范式将帮助我们提高已有的生产效率,从而为未来的技术创新奠定坚实的基础。在很多细分赛道,专业的人士仍需继续深耕。
● 软件开源:AI 技术的迅猛发展得益于开源的理念,它让每个人可以站在巨人的肩膀上,这也是我们打造 Xtreme1 的初衷:https://github.com/xtreme1-io/xtreme1/
Xtreme1 是全球首个开源多模态训练数据平台,通过提供 AI 赋能的软件工具、数万项目提炼的本体中心和丰富的数据治理特性,来加速多模态训练数据的处理效率,进而提高 AI 工程师的建模效率。特别是在 2D & 3D 多模态融合数据方面,标注效率的提升可达 72%。自 2022 年 9 月 15 日正式开源以来,Xtreme1 平台已经在 2022 年 12 月 15 日成为了 LF AI & DATA 托管项目。
● 数据开源:没有优秀的数据,AI 是无法正确运作的。我们最近也在研究全球首个多模态数据,涵盖了最新的传感器设备以及精准地人工标注数据,敬请期待~
五、SA-1B下载脚本与图像分割评测数据集
最后,分享SA-1B数据集快速下载脚本及其评测数据集资源:
● 下载代码:
cat ~/fb-sam.txt | parallel -j 5 --colsep $'\t' wget -nc -c {2} -O {1}注:fb-sam.txt是跳过标题行的数据集 txt 的文件副本。
● SA-1B(segment anything)国内免费快速下载地址:
● 评测数据集资源(部分):
ADE20K:https://opendatalab.com/ADE20K_2016
NDD20 (Northumberland Dolphin Dataset 2020):https://opendatalab.com/NDD20
LVIS:https://opendatalab.com/LVIS
STREETS:https://opendatalab.com/STREETS
VISOR:https://opendatalab.com/VISOR
WoodScape:https://opendatalab.com/WoodScape
TrashCan:https://opendatalab.com/TrashCan
PIDray:https://opendatalab.com/PIDray
GTEA (Georgia Tech Egocentric Activity):https://opendatalab.com/GTEA
本文作者|张子千 Nico
本期封面图来自 Segment Anything | Meta
引用
[1] ChatGPT爆火后,NLP技术不存在了.
https://mp.weixin.qq.com/s/FknHZ_FFdwdofp5vn9ot3g;
[2] Segment Anything.
https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation;
[3] Create and share photo cutouts on your iPhone.
https://support.apple.com/en-us/HT213459;
[4] The Mislabelled Objects in COCO.
https://www.neuralception.com/mislabelled-traffic;
[5] How I found nearly 300,000 errors in MS COCO.
https://medium.com/@jamie_34747/how-i-found-nearly-300-000-errors-in-ms-coco-79d382edf22b;
[6] 感谢OpenDataLab提供的数据集支持,更多数据集请访问:https://opendatalab.org.cn/;
-END-
更多公开数据集,欢迎访问OpenDataLab官网查看与下载:https://opendatalab.org.cn/