数据清洗
数据清洗是指我们拿到数据的格式、内容不方便直接做分析工作。比如要做土豆丝,买到土豆(拿到原数据)后不会直接做成菜,要先把土豆洗一下去掉泥土(相当于数据清洗),根据需求把土豆切成想要的形状(按照需求把数据进行规整),然后下锅炒,装盘(相当于数据分析的可视化,把数据通过图表的形式展现出来)。
针对数据中的问题展开进行清洗,不同数据的清洗方式不同,分为数据中显性的问题(拿到数据就可以看到数据中存在的问题,如土豆发芽、泥土等)和隐形问题。
显性问题具体表现在异常数据,如列名称不规范;列名称重复出现;缺失数据;重复数据(求平均值影响比较大,机器学习中重复数据影响较小)。
隐性问题具体表现在数据类型、字符串、极端异常值等。
导入数据后的显示形式为
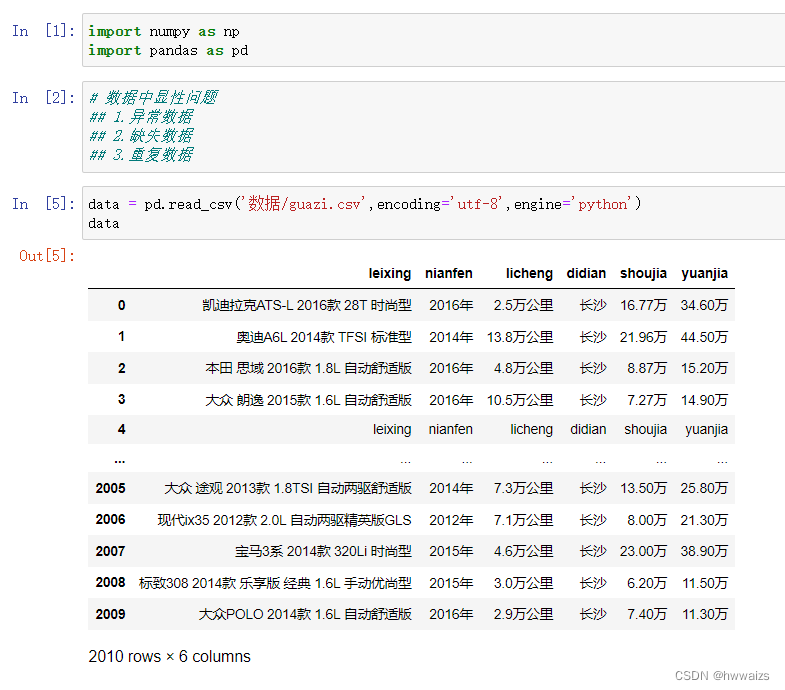
此时导入了2010条数据
数据中显性问题的处理
1.异常数据
异常数据直接进行删除。比如删除行索引为4和9的行,用drop进行删除。
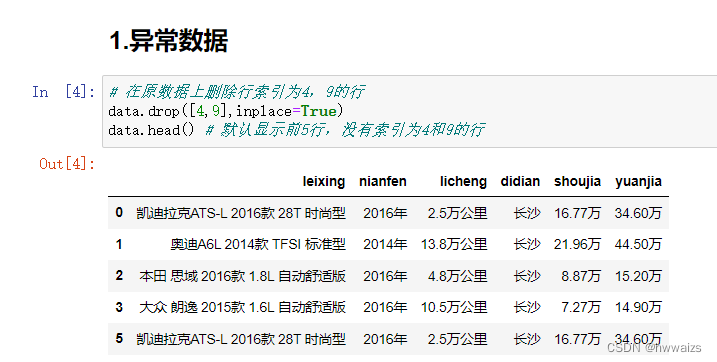
删除后数据的条数为2008条,但是索引还是显示到2009,我们就需要重新生成索引。
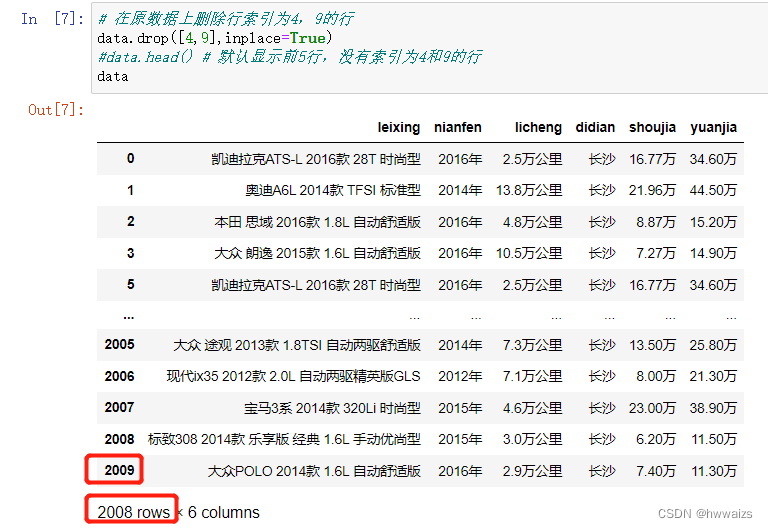
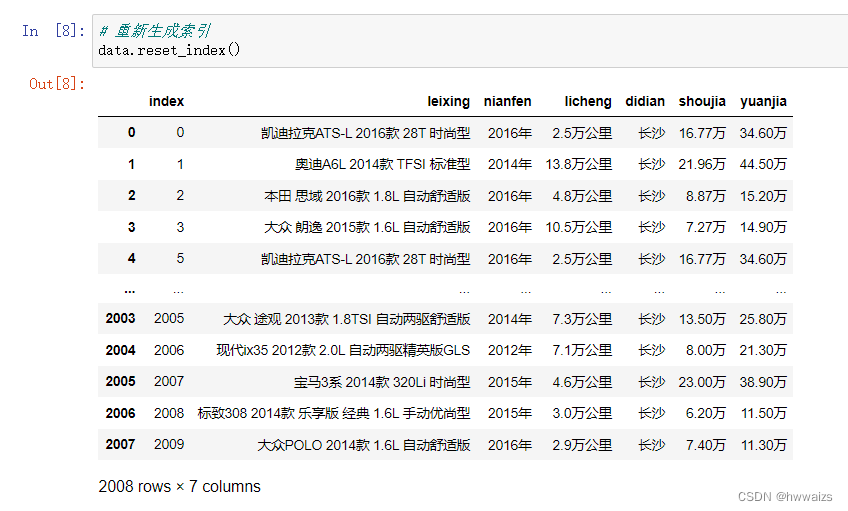
可用reset_index(),来生成新的索引对象,此时原索引会作为一列数据存放到表中。
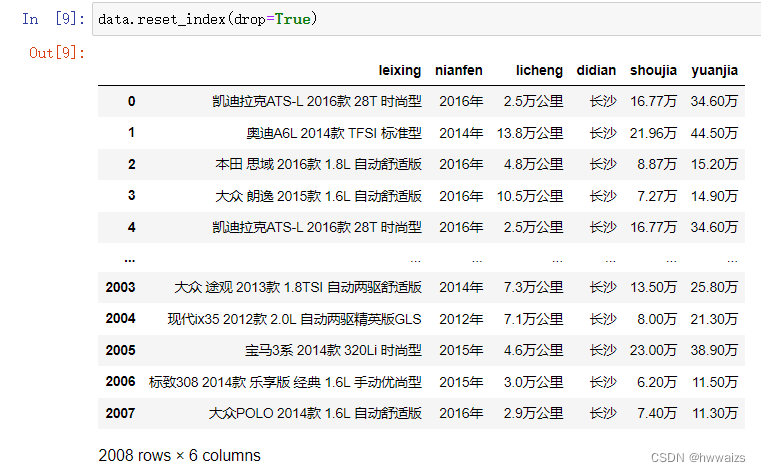
我们可以在括号内设置drop=True,删除原有的索引对象,重新生成新的索引对象。
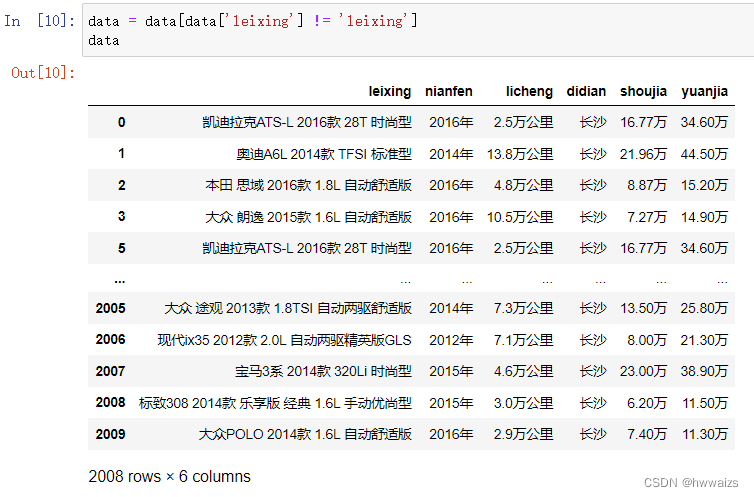
刚才进行删除的时候,是实现知道索引为4和9的行出现重复的内容,而实际操作中并不知道其他行是否也存在重复的数据,我们可以通过布尔索引来选择数据里是否包含标题内容;也可以用判断“nian”里是否包含“年”。
2.缺失数据
不管有没有缺失数据,都要先进行检测一下。
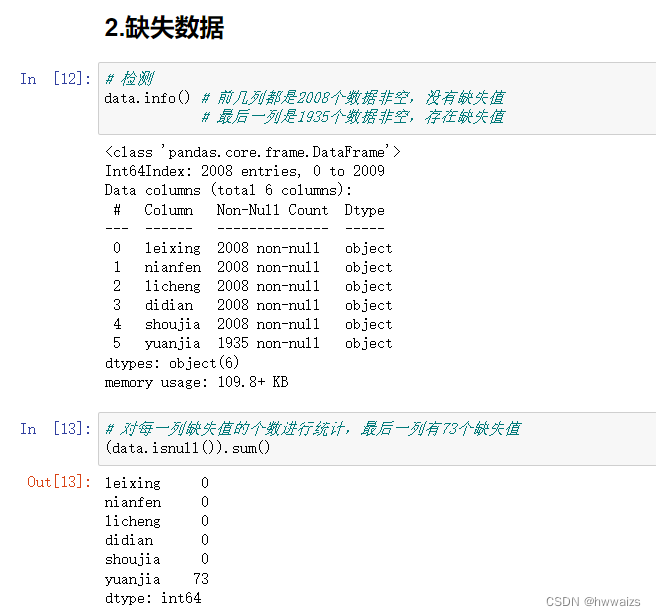
检测出有缺失值后,要判断对缺失值的数据是进行填充还是删除,这个表中缺失的是汽车的原价,每种汽车的品牌和生产日期均不一致,无法进行填充,且缺失的数据量相对于总数据量较小,所以这个表中对缺失值进行删除。
如果缺失的是地点,可以根据上下行进行填充。

3.重复数据
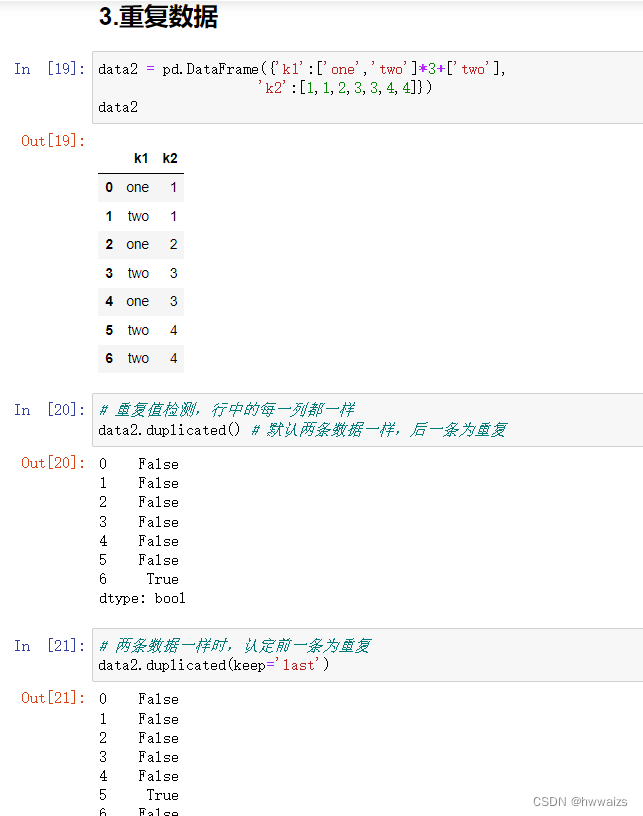
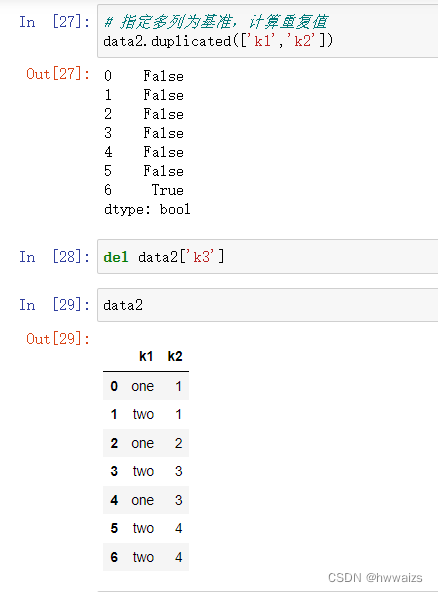
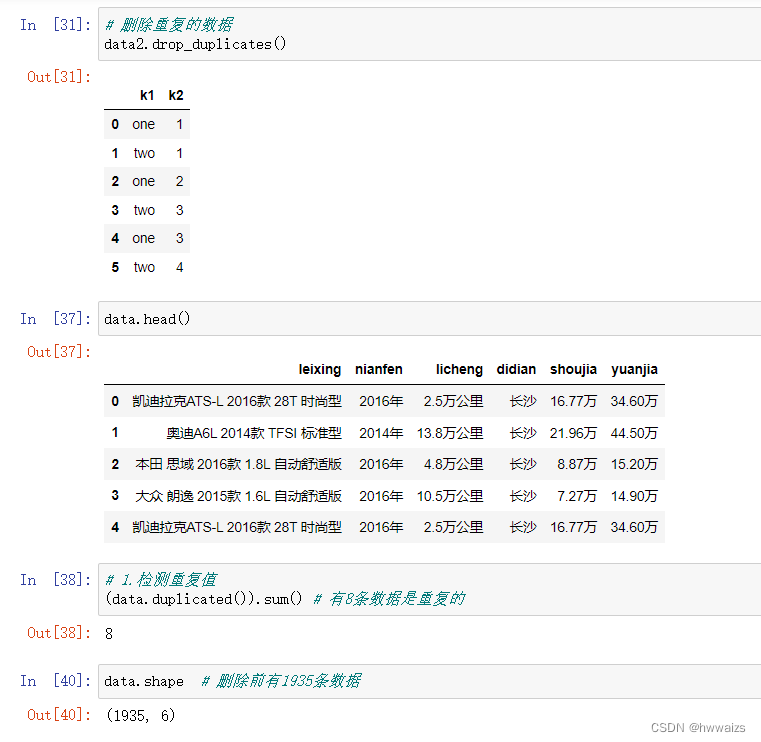
拿到的数据量很大,不可能对每一条数据进行检查,看是否存在重复值。要对数据进行重复值检测,这里的重复值指的是行里的每一列数据都重复,如数据表中车的类型、年份、里程、地点、售价、原价均一样,说明这条数据是重复的。如果1班和2班均有个学生叫“小明”,这个小明不是重复的。要分类对重复值进行处理,避免对分析结果产生影响,对于重复值数据比较少的,可以直接进行删除。
在对异常数据进行删除后,需要对数据进行重新索引,保证以后可以准确的选择数据。

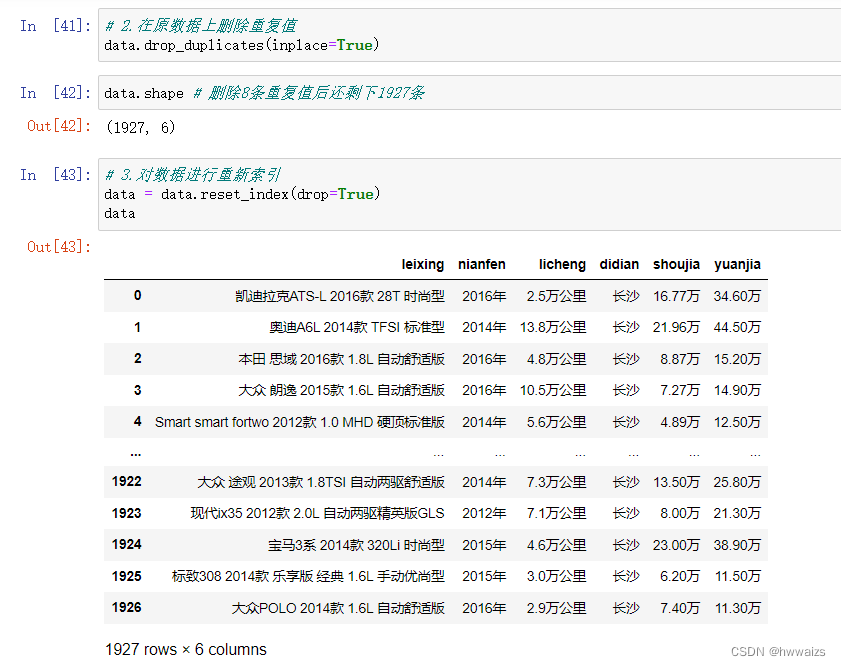
数据中隐性问题的处理
我们可以把数据表中的标题改为中文的。
数据中存在的隐性表现在数据类型(如求汽车的原价减去售价的差价,需把数据转为浮点型)、字符串(数字中去掉字符串,如“万”字)、极端异常值(行驶里程里的万公里与公里的处理)
1.数据类型
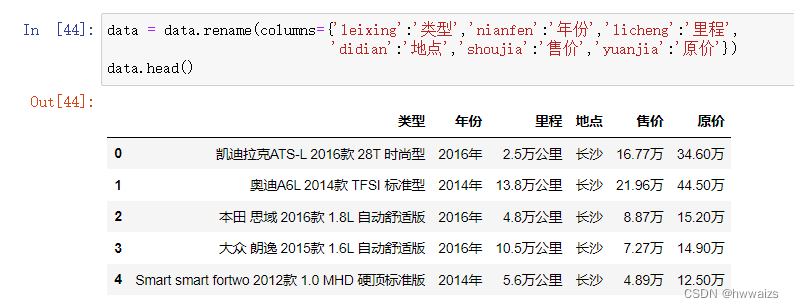
数据类型相同的,可以直接进行计算,如k3和k2,k1为字符串则不能一起运算。
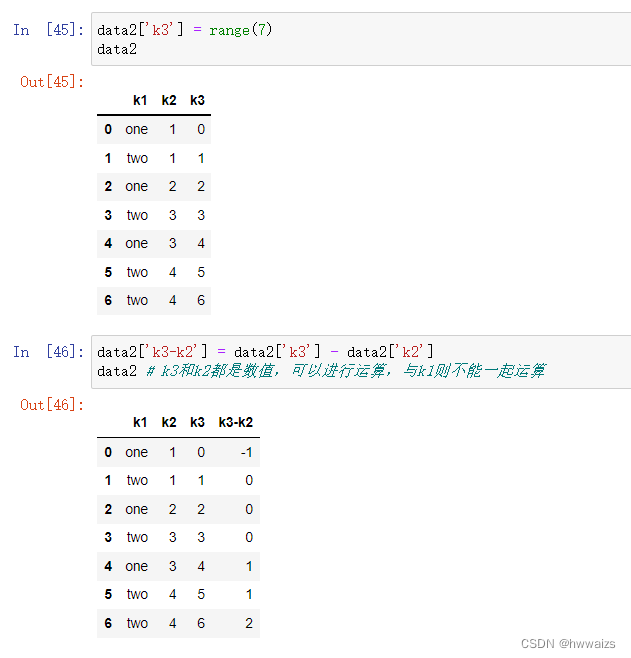
利用函数和映射进行数据转换
在data3中,food列的大小写不统一,提取的时候会出现提取数据不全,可以统一都改成小写。也可以利用映射的关系去添加新的一列,不改变第一列的内容。
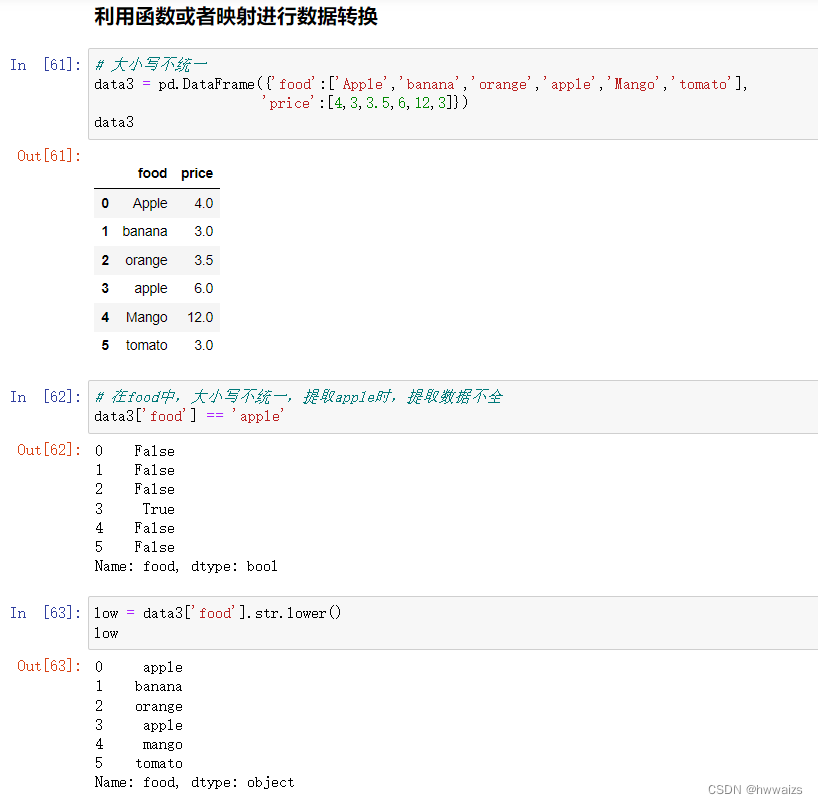
从data3里提取apple时候,第一行不会被提取出来,需要把字符串的大小写改为一致。当需要加上一列内容,把第一列的内容进行映射时,data3[‘class’] = data3[‘food’].map(rela) ,这个时候data3里的Apple和Mango 对应的都是NaN,是因为在rela的字典里,这两个内容没有对应的映射关系,可以增加Apple的映射关系,也可以进行大小写的转换(low.map(rela)),利用转换关系,统一成小写,再进行相应的映射。
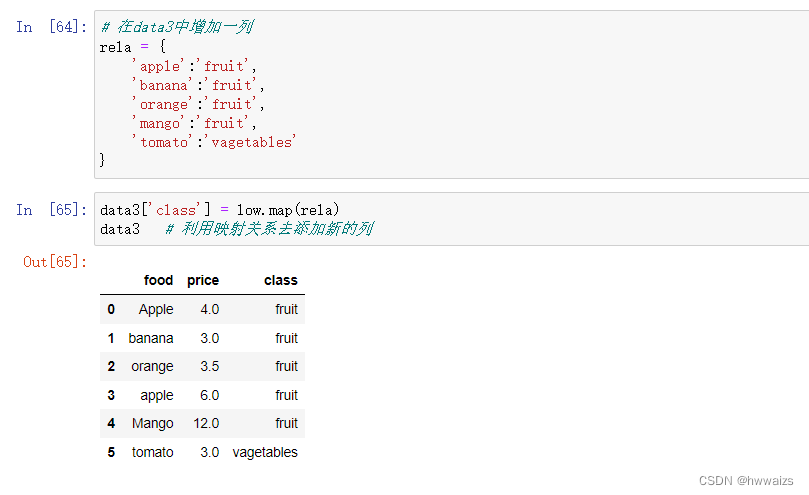
根据映射关系(小写的第一列)添加第三列的数据,并没有对原数据进行更改,更改的返回值,利用返回值去对应映射关系。如果要更改第一列,需要把第一列转换成小写,data3[“food”] = data3[“food”].str.lower() ,然后再进行映射,这样改变了原数组,都改为了小写。
2.离散化和面元划分
创建一个年龄的列表,按照指定的面元进行划分,指定划分的范围为18-25,25-35,35-60,60-100,得到数值所在的数据区间,进而统计数据所在的区间以及相应的数量,也可以改变参数调整区间的闭开方向,在切割时增加参数labels,可以改变默认区间的名称,便于观察。

按照指定的面元进行划分后,得到数据划分的区间,默认区间是左开右闭,不在任何区间内的值,则为NaN,判断数据所在的区间。

统计数据所在区间的索引,计算出在每个区间的数据数量,默认显示的结果是按数据量的多少进行排序。

也可以用right参数调整区间的左右开闭方向,设置参数labels,可以更改区间的名称。
例题1
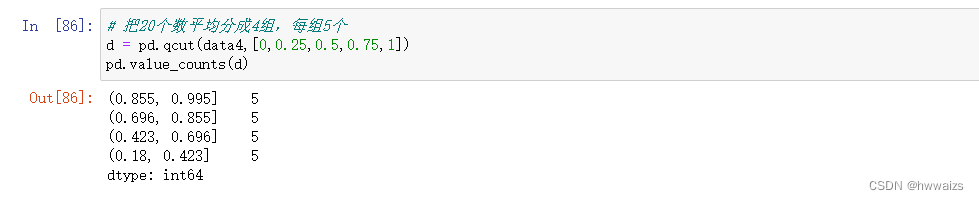
随机生成20个数的数组,随机分成4个区间,统计每个区间的个数。

例题2
随机生成20个数的数组,平均分成4个区间或者指定分成数据数量的4个区间。

3.字符串操作
数据类型是整型,浮点型,字符串,数值之间的转换,去掉字符串中的汉字然后转为数值型进行运算。
1.字符串函数
2.正则
3.pandas的字符串函数
| 方法 | 说明 |
|---|---|
| cat | 实现元素级的字符串连接操作,可指定分隔符 |
| count | 返回表示字符串是否有指定模式的布尔型数据 |
| extract | 使用带分组的正则表达式从字符串Series提取一个或多个字符串,结果是一个DataFrame,每组有一列 |
| endswith | 相当于对每个元素执行 x.endswith(pattern) |
| startswith | 相当于对每个元素执行 x.startswith(pattern) |
| findall | 计算各字符串的模式列表 |
| get | 获取各元素的第i个字符 |
| isalnum | 相当于内置的str.isalnum |
| isalpha | 相当于内置的str.isalpha |
| isdecimal | 相当于内置的str.isdecimal |
| isdigit | 相当于内置的str.isdigit |
| islower | 相当于内置的str.islower |
| isnumeric | 相当于内置的str.isnumeric |
| isupper | 相当于内置的str.isupper |
| join | 根据指定的分隔符将Series中各元素的字符串连接起来 |
| len | 计算各字符串的长度 |
| lower,upper | 转换大小写,相当于对各个元素执行x.lower()或x.upper() |
| match | 根据指定的正则表达式对各个元素执行 re.match,返回匹配的组为列表 |
| pad | 在字符串的左边、右边或两边添加空白符 |
| center | 相当于pad(side=‘both’) |
| repeat | 重复值。如s.str.repeat(3)相当于对各个字符串执行x*3 |
| slice | 对Series中的各个字符串进行字串截取 |
| split | 根据分隔符或正则表达式对字符进行拆分 |
| strip | 取出两边的空白符,包括新行 |
| rstrip | 取出右边的空白符 |
| lstrip | 取出左边的空白符 |
用字符串函数、正则、pandas字符串函数分别处理数据
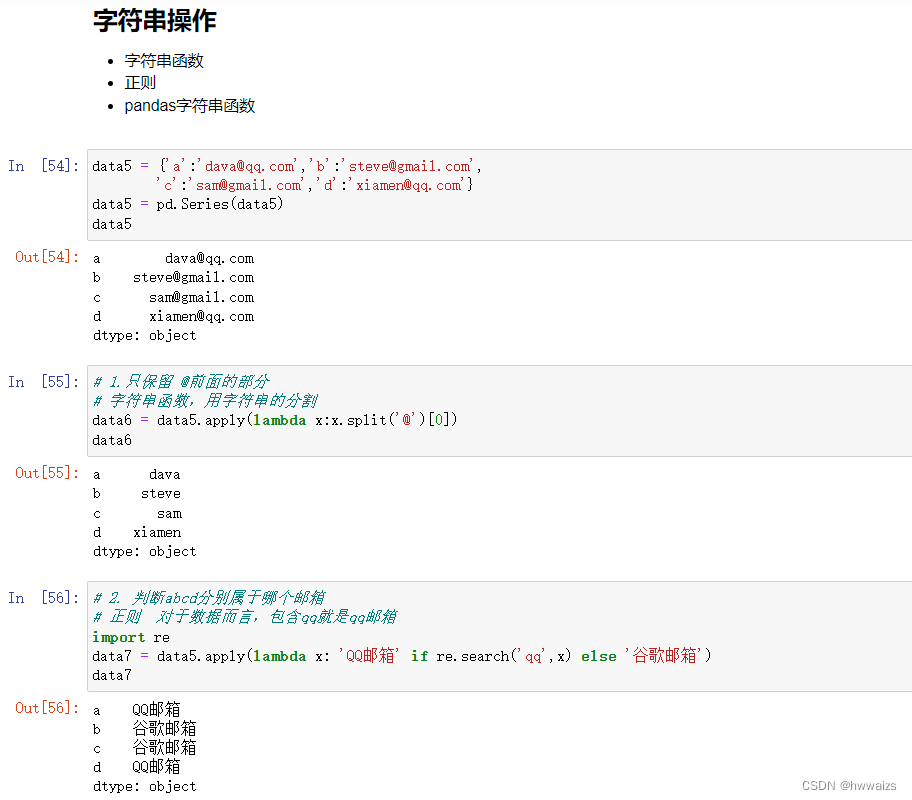
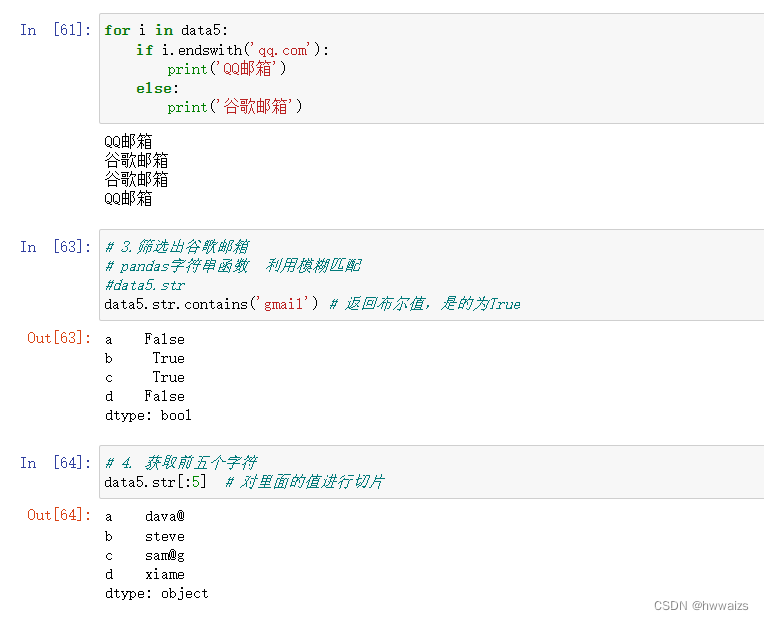
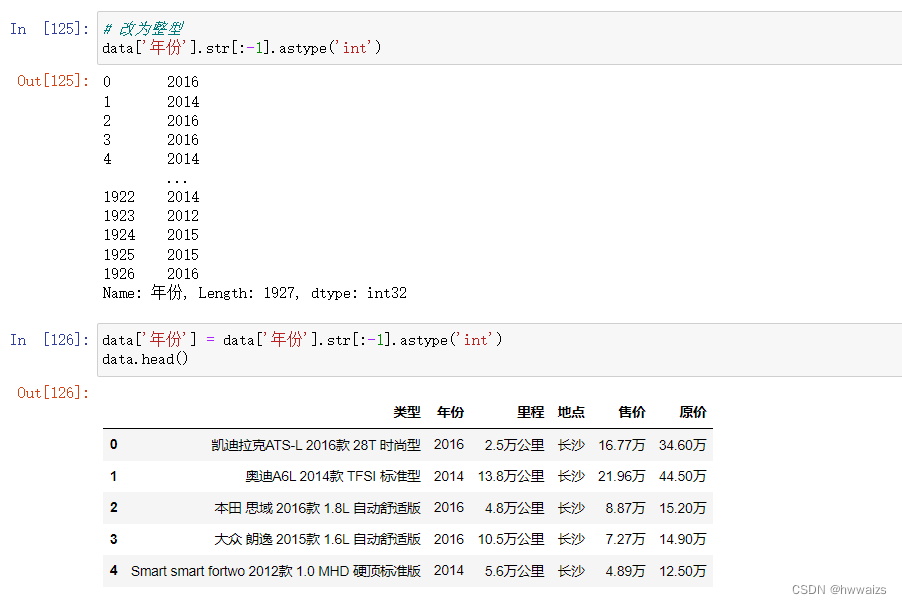
把data表中的年份,去掉“年”字

用“replace”去掉原价和售价中的“万”字,并计算差价。
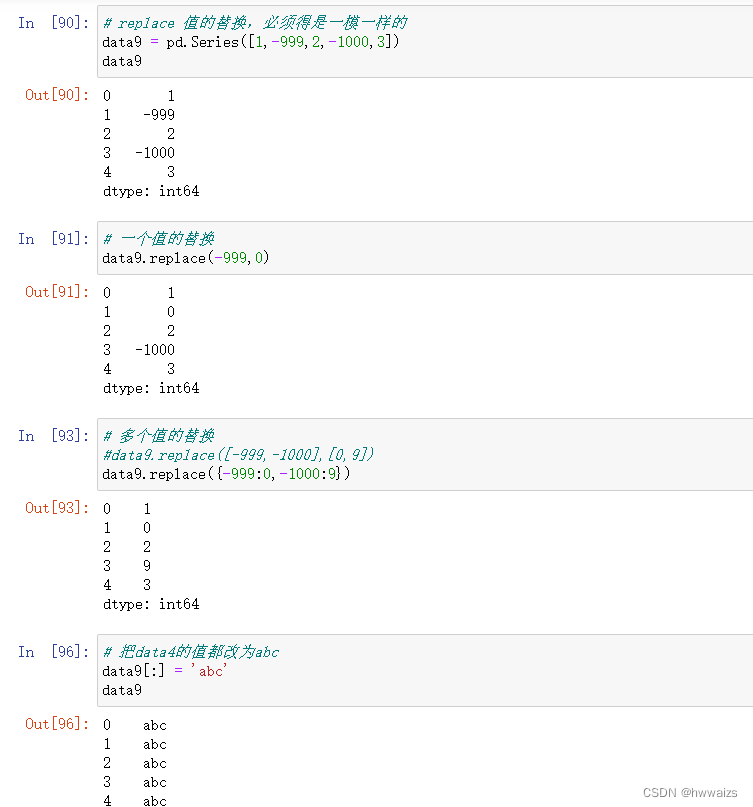
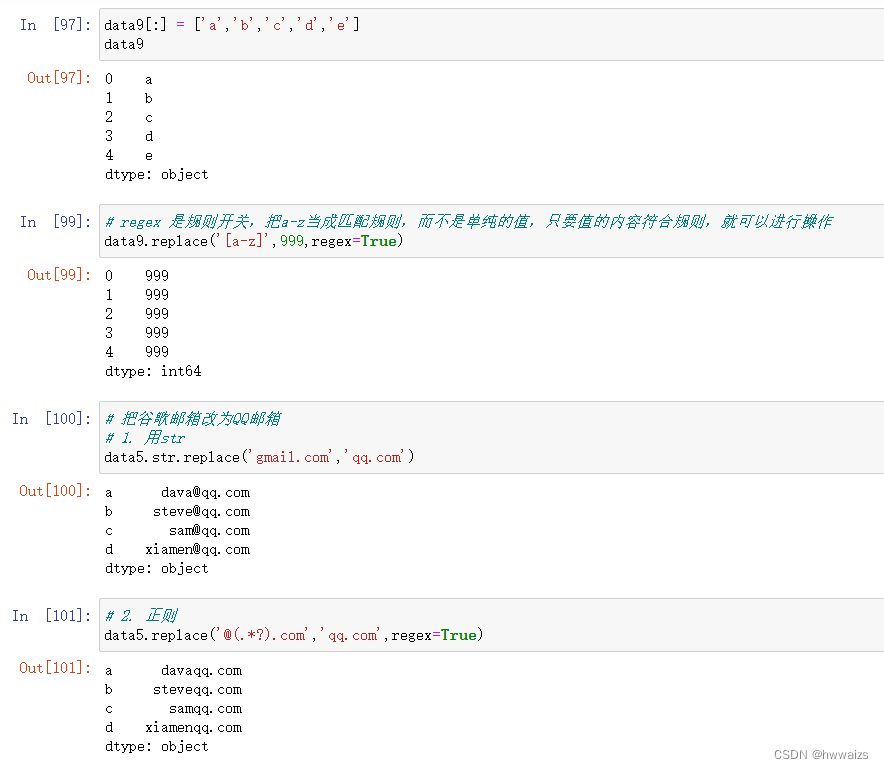
“regex” 是规则开关,打开开关,只要值得内容符合规则,就可以进行运算。
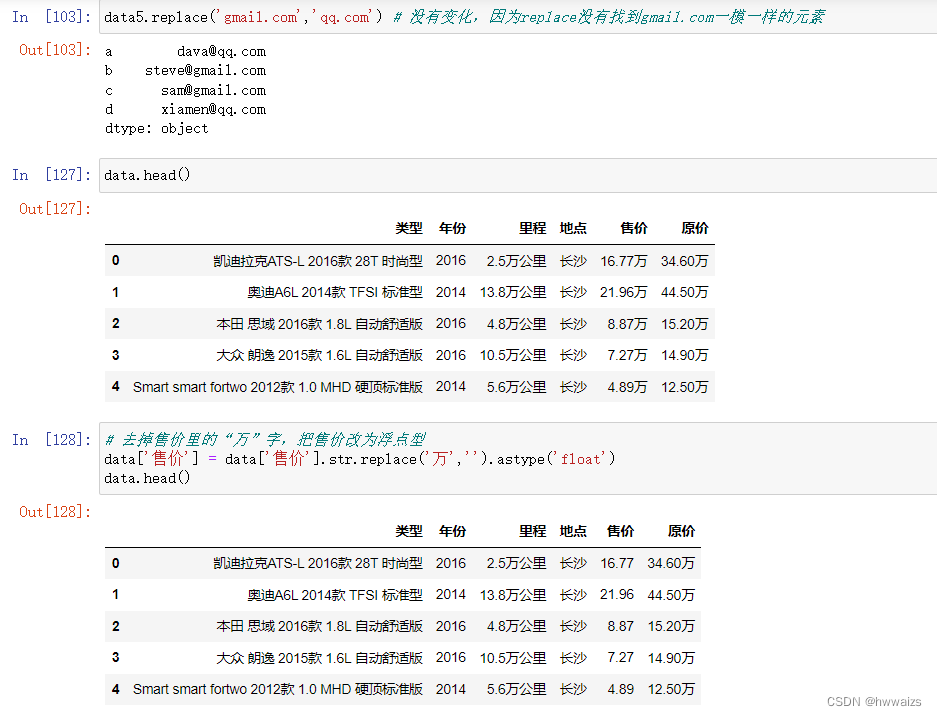
利用“replace” 把“万”替换为空,并把数据类型改为浮点型。
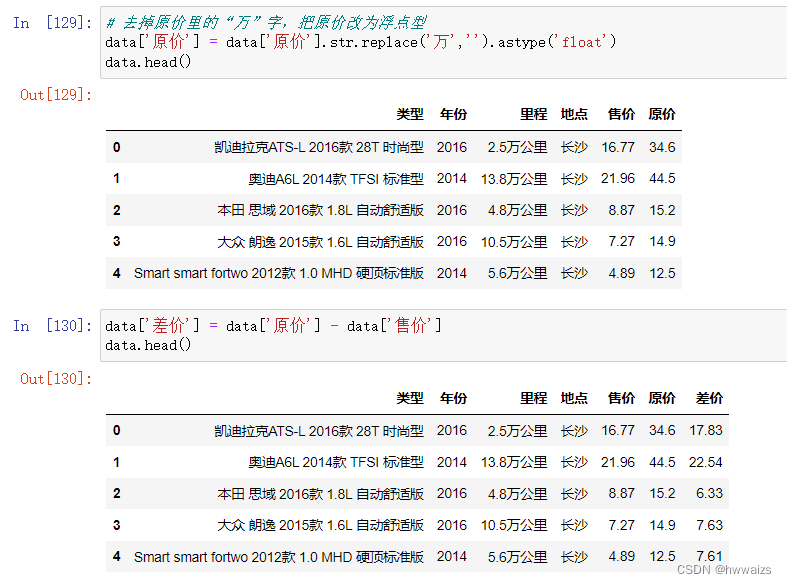
在数据分析的各个阶段过程中都会随时用到数据清洗,如在可视化画图的时候,发现有些点是异常值,就要做异常值的去除,数据清洗会不断随着问题的产生一直进行操作。
作业
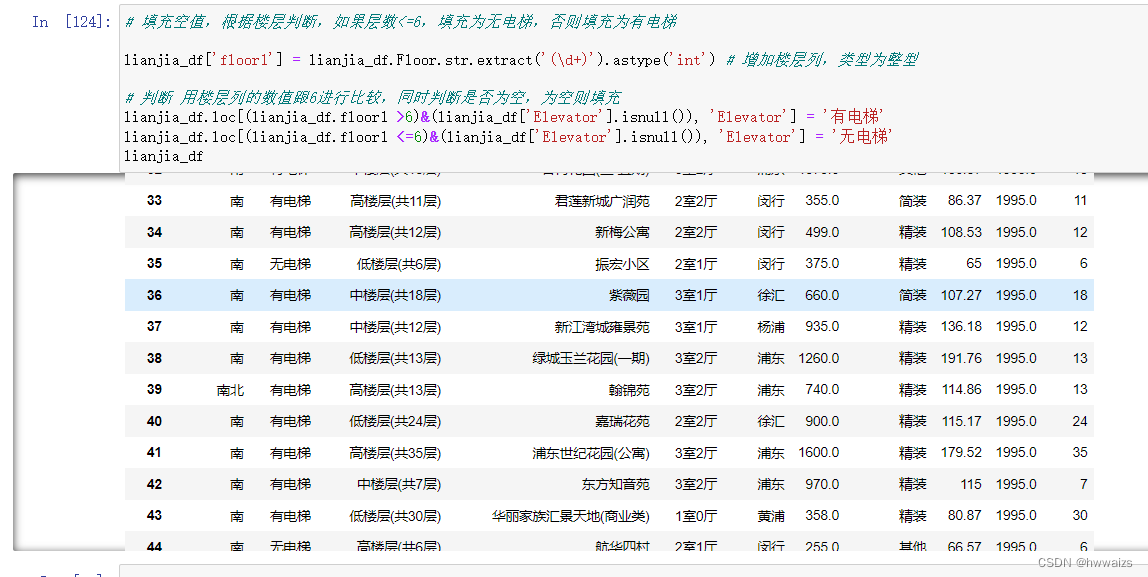
- 读取lianjia.csv文件里的数据
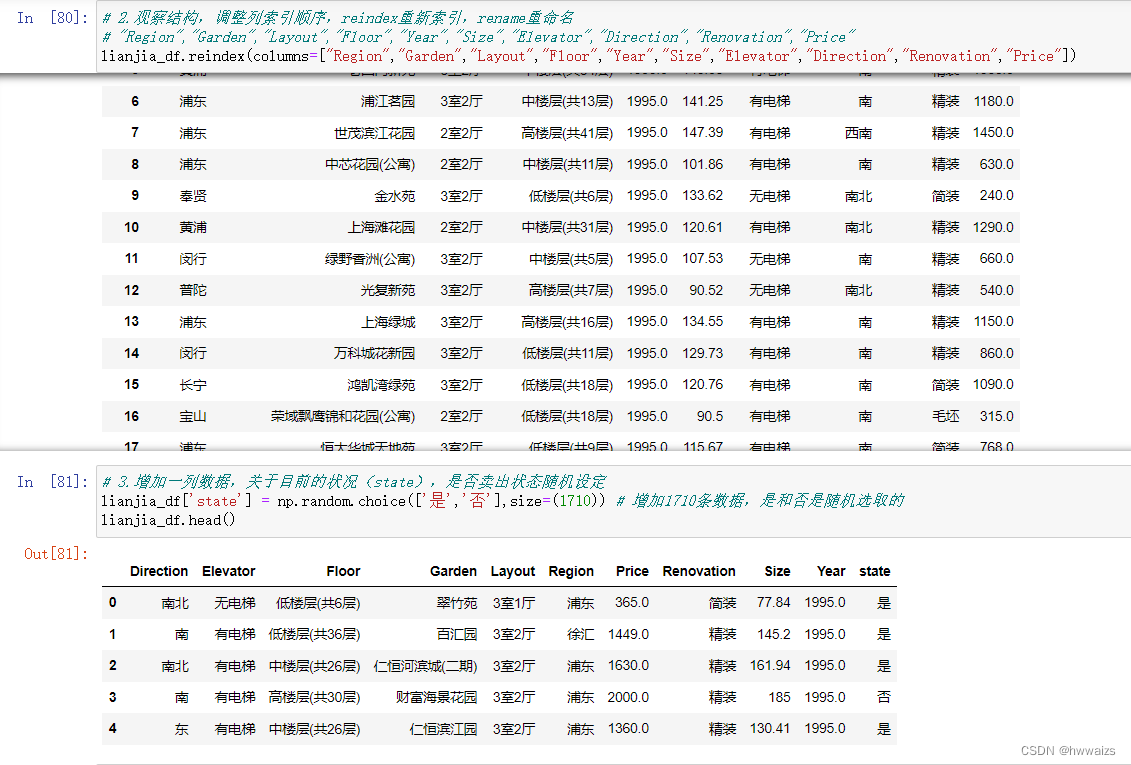
- 观察结构,调整列索引顺序(“Region”,“Garden”,“Layout”,“Floor”,“Year”,“Size”,“Elevator”,“Direction”,“Renovation”,“Price”)
- 增加一个列关于目前状况(state),是否卖出状态随机设定
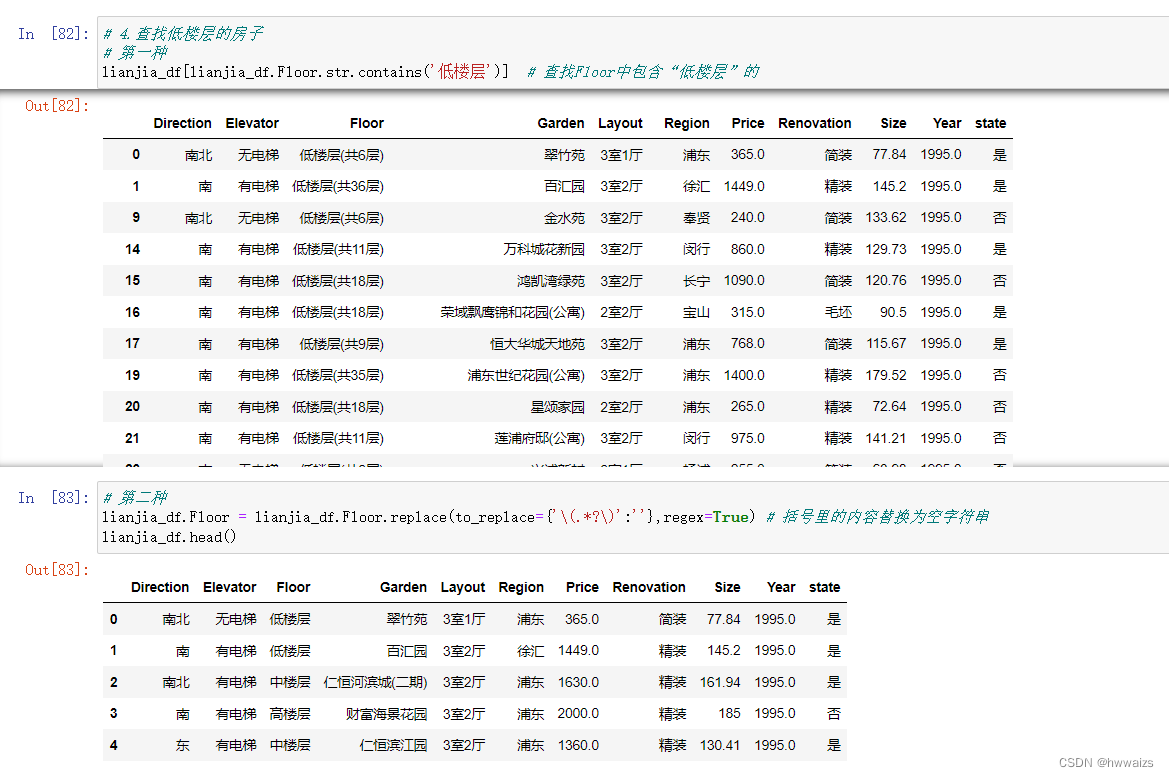
- 查找楼层低的房子(这里提取低楼层)
- 电梯这列存在缺失值,想办法处理下缺失值

对于少量的空值可以删除,也可以用填充的方法,根据楼层进行判断,一般小于6层的是都是无电梯的。