分类目录:《深入理解深度学习》总目录
相关文章:
· BERT(Bidirectional Encoder Representations from Transformers):基础知识
· BERT(Bidirectional Encoder Representations from Transformers):BERT的结构
· BERT(Bidirectional Encoder Representations from Transformers):MLM(Masked Language Model)
· BERT(Bidirectional Encoder Representations from Transformers):NSP(Next Sentence Prediction)任务
· BERT(Bidirectional Encoder Representations from Transformers):输入表示
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[句对分类]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[单句分类]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[文本问答]
· BERT(Bidirectional Encoder Representations from Transformers):微调训练-[单句标注]
· BERT(Bidirectional Encoder Representations from Transformers):模型总结与注意事项
BERT根据自然语言处理下游任务的输入和输出的形式,将微调训练支持的任务分为四类,分别是句对分类、单句分类、文本问答和单句标注。本文就将介绍句对分类的微调训练,其它类别的任务将在《深入理解深度学习——BERT(Bidirectional Encoder Representations from Transform)》系列中的其它文章介绍。
给定两个句子,判断它们的关系,统称为句对分类。常见的任务如下:
- 多类型自然语言推理MNLI(Multi-Genre Natural Language Inference):给定句对,判断它们是否为蕴含、矛盾或中立关系,属于三分类任务。
- Quora问答QQP(Quora Question Pairs):给定句对,判断它们是否相似,属于二分类任务。
- 问答自然语言推理QNLI(Question Natural Language Inference):给定句对,判断后者是否为对前者的回答,属于二分类任务。
- 语义文本相似度STS-B(Semantic Textual Similarity):给定句对,判断它们的相似程度,属于五分类任务。
- 微软研究院释义语料库MRPC(Microsoft Research Paraphrase Corpus):给定句对,判断语义是否一致,属于二分类任务。
- 文本蕴含识别RTE(Recognizing Texual Entailment):给定句对,判断两者是否具有蕴含关系,属于二分类任务。
- 根据语境选取候选句子SWAG(Situation With Adversarial Generations):给定句子 A A A和四个候选句子 B B B,根据语义连贯性选择最优的 B B B。该任务可以转换成求 A A A与每个候选句子的匹配值,根据匹配值的量化程度,可以将此类任务视为多分类任务。
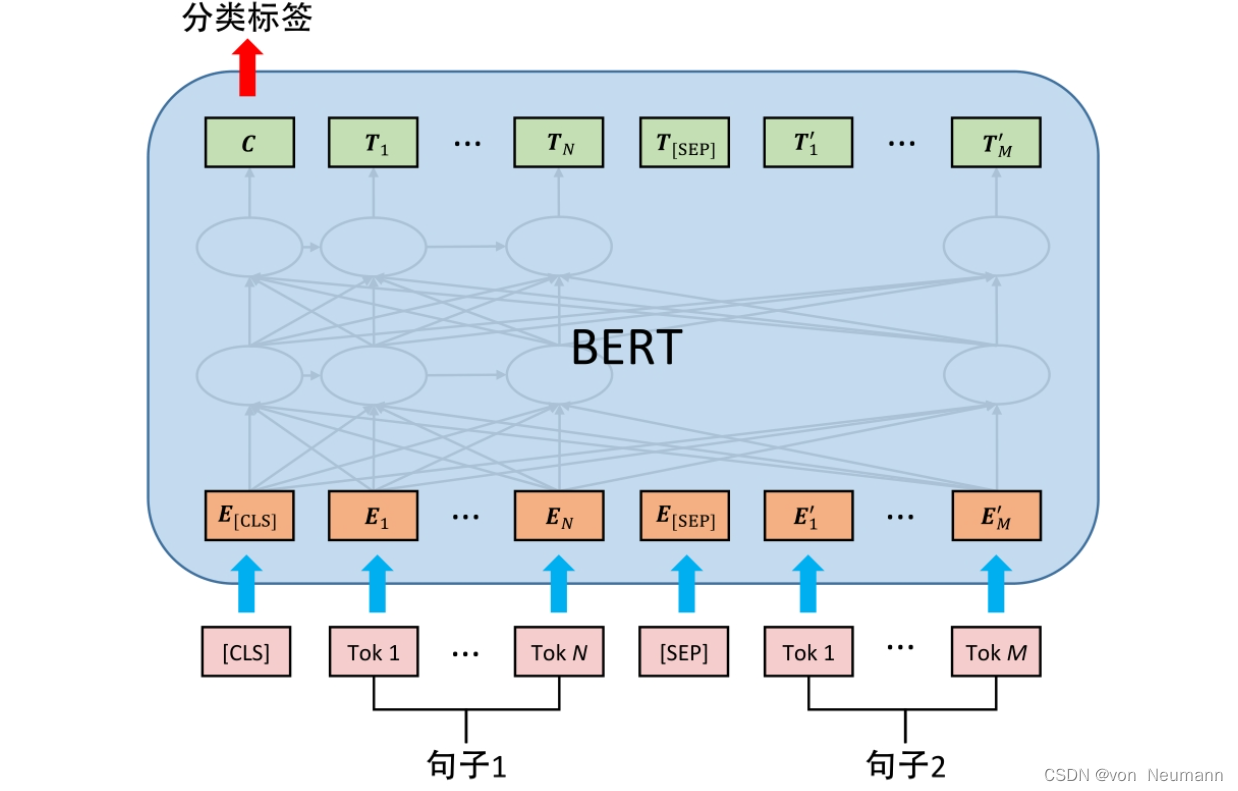
针对句对分类任务,BERT在预训练过程中就做了充分的准备,使用NSP训练方法获得了直接捕获句对语义关系的能力。针对二分类任务,BERT不需要对输入数据和输出数据的结构做任何改动,直接使用与NSP训练方法一样的输入和输出结构即可。如下图所示,句对用[SEP]分隔符拼接成输入文本序列,在句首加入标签[CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。针对多分类任务,需要在句首标签[CLS]的输出特征向量后接一个全连接层与Softmax层,保证输出维数与类别数目一致,即可通过 arg max \arg\max argmax操作得到对应的类别结果。下面给出句对相似性任务的实例,重点关注输入数据和输出数据的格式:
任务:判断句子“我很喜欢你”和句子“我很中意你”是否相似
输入改写:“[CLS]我很喜欢你[SEP]我很中意你”
取“[CLS]”标签对应输出: [ 0.02 , 0.98 ] [0.02, 0.98] [0.02,0.98],通过 arg max \arg\max argmax操作得到相似类别为1(类别索引从0开始),即两个句子相似
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.