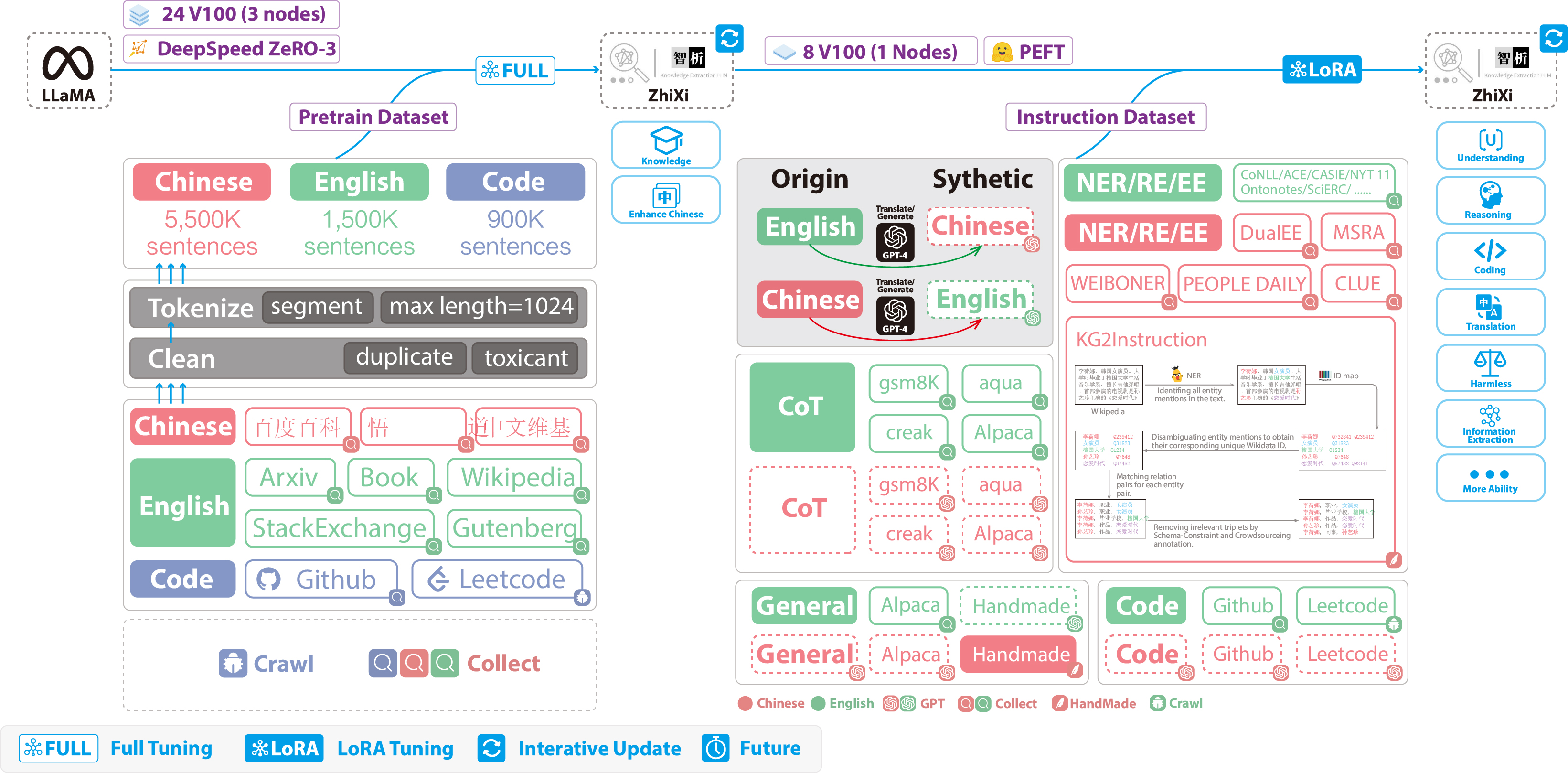
使用LoRA的指令微调阶段。该阶段让模型能够理解人类的指令并输出合适的内容。
GitHub - zjunlp/KnowLM: Knowledgable Large Language Model Framework.
训练细节 · ymcui/Chinese-LLaMA-Alpaca Wiki · GitHub