前言
读一篇 ICML 2021 的论文How could Neural Networks understand Programs?
程序语义理解是程序设计语言处理(PLP)的一个基本问题。最近基于NLP预训练技术学习代码表示的工作,推动了该方向的前沿。然而,PL和NL的语义有着本质的区别。忽略这些,我们认为很难建立一个模型来更好地理解程序,要么直接将现成的NLP预训练技术应用于源代码,要么通过启发式向模型添加特征。事实上,程序的语义可以严格地用PL理论中的形式语义来定义。例如,操作语义,描述了一个有效程序的意义,通过基本操作(如内存I/O和条件分支)更新环境(即内存地址值函数)。在此启发下,本文提出了一种新的程序语义学习范式,模型学习的信息包括:(1)与操作语义中基本操作一致的表示;(2)程序理解所必需的环境变迁信息。为验证该建议,本文提出一种基于分层transformer的预训练模型OSCAR,以更好地促进对程序的理解。OSCAR学习从静态分析中获得的中间表示(IR)和编码表示,分别用于表示基本操作和近似环境变迁。OSCAR在许多实际的软件工程任务中展示了卓越的程序语义理解能力。
一句话: 应用Transformer模型做程序理解
项目地址: https://github.com/pdlan/OSCAR
导论
现代软件通常包含大量的代码、功能和模块,具有极其复杂的结构或组织方案。这给此类程序的编写、维护和分析带来了巨大挑战。幸运的是,一系列基于深度学习的生产力工具被开发出来,通过分析程序自动帮助程序员执行安全审计,代码检索等任务
受用于自然语言语义理解的预训练表示的成功启发,有许多尝试将传统的NLP预训练技术移植到源代码层面,其中代码表示通过从大量源代码文本中捕获上下文信息来获得,然后在微调后用于各种下游软件工程任务。例如,CuBERT利用强大的预训练上下文嵌入模型BERT在Python语料库上学习信息表示; CodeBERT通过对NL-PL对进行预训练来学习通用表示,以连接自然语言(NL)和高级编程语言(PL)。此外将专家设计的特征(如数据流图)添加到预训练模型中,旨在为程序语义理解提供额外的信息。
然而,编程语言与自然语言在本质上有许多基本差异。例如,同一个程序可能对其输入和内存状态表现出不同的行为,而在自然语言中没有这样明确的概念。目前试图直接从源代码中捕获语义特性的方法,无论是应用现成的NLP预训练技术,还是通过启发式向模型添加特征,都会限制对程序语义的理解。
受编程语言理论的启发,本文提出了一种代码表示学习范式,可以使模型更好地理解程序。代码表示应该从以下方面学习:(1)源代码文本的翻译要与操作语义中定义的基本操作保持一致; (2)环境变迁信息
为了验证该建议的有效性,进一步提出了一种新的基于分层Transformer的预训练模型,称为代码抽象表示的操作语义(Operational Semantics for Code Abstract Representation, OSCAR),旨在捕获长序列代码之间的上下文信息。一方面,OSCAR使用中间表示(intermediate representation, IR)来表示基本操作,由于中间表示是在具有有限指令集的抽象机器上建模的,几乎可以完美地映射到操作语义,因此相比高级编程语言更适合于学习代码表示
特别地,IR可以通过从目标程序的二进制代码或源代码翻译得到。另一方面,获取具体而精确的环境变迁信息需要大量的实际执行和计算,既不现实又存在风险。因此,OSCAR交替地使用抽象信息,这些抽象信息可以由抽象解释启发的静态程序分析轻易地获得。
抽象解释(Abstract interpretation)通过对程序可能行为的数学表征来描述程序语义,而不是对程序在许多实际执行轨迹之后的行为建模。此外,为了捕获目标程序或代码片段的控制结构,提出了一种新的位置条件编码(Position Condition Encoding, PCE),将控制流信息编码到模型中。
Contributions
(1) 提出一种新的学习范式,表明预训练模型可以从表面的指令和底层的环境变迁中学习代码表示,缓解了从操作语义理解程序语义的限制。
(2) 提出OSCAR来证明所提出的设计,一个层次化的Transformer,用IR表示基本操作,用从静态分析中导出的编码表示近似环境变迁。为OSCAR设计了高效的训练目标,以在很大程度上促进程序语义的理解。
(3) OSCAR在广泛的下游实际软件工程任务上显著提高了程序语义理解的性能。此外,与最先进的预训练方法相比,OSCAR显示了显著的零样本能力,即无需微调参数。
方法
提出一种新的学习范式, 让预训练可以学习到潜层的指令信息, 同时学习潜在的环境转移信息
在简化的抽象机上,赋值和组合的意义分别表示为
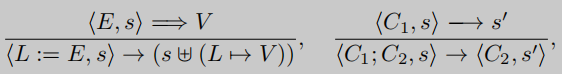
E、L、V分别表示表达式、内存位置和值,s∈S表示将所有内存位置映射到值的环境函数,C表示代码片段。
先看左边的表达式, 意思是如果上部分表达式成立, 环境s中的表达式E降为V,那么下部分表达式成立, 程序L:= E将用L = V更新环境函数s
再看右边表达式, 如果上部分表达式成立, 代码段 C 1 C_1 C1在环境s下执行得到s’, 那么下部分表达式成立, C 1 , C 2 C_1, C_2 C1,C2在环境s下执行, 等价于 C 2 C_2 C2在s’下执行
一个代码片段的语义依赖于两个部分:指令和抽象机上的环境转换信息。因此,本文提出从这两部分中充分学习到良好的代码表示,以更好地理解程序的语义。下面,我们将介绍OSCAR,它是一个分层模型,从这两个方面学习代码表示。
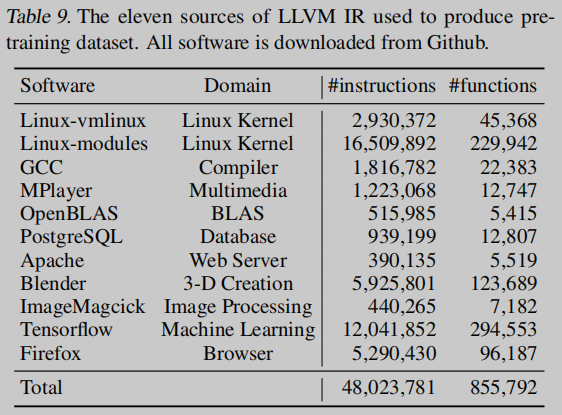
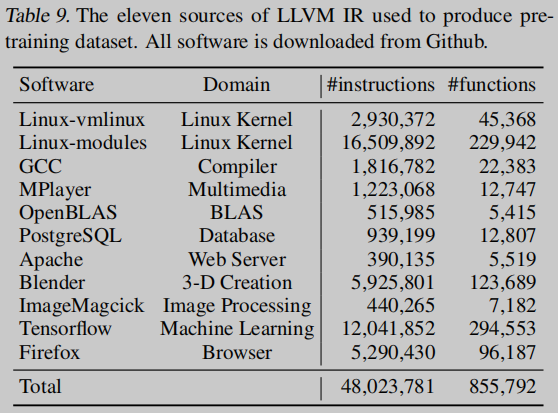
现有的程序理解方法已经广泛采用直接从高级PLs中学习表示法。然而,随着现代编程语言和编译器的发展,源代码或二进制代码的文本表示与实际计算意义之间的差距变得越来越大。这个不可忽略的差距增加了对现有模型的代码理解的难度。为了更好地分析和优化程序,现代编译器会在为目标体系结构生成机器码之前将源代码翻译成IR。IR是以抽象机器为模型的,这种抽象机器通常被设计成每条指令只代表一个基本操作。收集了大量真实世界程序的语料库,并将它们翻译成LLVM IR作为我们的预训练数据。
利用结构化操作语义来说明如何将环境转换信息编码到模型中。结构操作语义的归纳性需要一个适当定义的初始条件,初始条件用初始环境函数来描述。为了充分捕捉环境变迁的具体而精确的信息,必须迭代输入值和初始条件的多种可能组合,并根据顺序规则实际执行程序来推断变迁。这显然是不可行的,因为实际执行非常耗时且有风险,例如对大型软件项目或恶意软件的分析。因此,我们交替使用从静态程序分析中获得的抽象环境信息,而不是具体的环境信息。抽象的环境信息受到抽象解释的启发, 通过对程序可能的行为的数学表征来描述程序语义,而不是在许多实际执行轨迹之后对程序的行为建模。将这一思想应用到结构化操作语义中,每个表达式不仅可以归约为一个具体的值,而且可以归约为值空间中的一个关系或一个可能的范围。
从指令中提取了三种类型的环境关系约束:由静态单赋值(SSA)控制的约束、由内存读取控制的约束和由内存写入控制的约束。这些信息可以很容易地通过LLVM内置的分析功能获得,例如MemorySSA。
OSCAR的模型架构是一个分层的多层Transformer编码器,如下图所示。OSCAR由两级编码器组成。下层由两个token级编码器组成,分别用于处理IR和抽象环境信息。上层是一个指令级编码器,旨在根据下层的输出进一步提取特征。每个级别编码器的实现与BERT相同。我们将两个标记级编码器称为IR和Env编码器。编译时将源码编译为binary, 然后用retdec反编译出LLVM IR, 将编写的pass作用于IR, 生成LLVM Abstract Environment文件, 每一条IR指令对应一个environment.

由于Transformer是为解决自然语言中的序列转导问题而开发的,它不能很好地捕获编程语言中复杂的控制结构,如迭代逻辑和选择逻辑。然而,控制流信息对于理解程序的语义是不可或缺的。为了克服这个问题,在之前的工作中,将控制流图(CFG)纳入Transformer.
本文设计了一种更为简单有效的方法PCE (Positional Condition Encoding),通过位置编码将控制流信息编码到模型中。PCE为目标程序或代码片段中的每条指令的位置分配3个可学习的嵌入向量,分别表示指令的当前位置和条件跳转后的目标位置,分别为true和false。图2给出了该代码片段对应的PCE示意图和控制流图,其中 p i p_i pi、 p i 1 p^1_i pi1 和 p i 0 p^0_i pi0 分别表示位置 i i i 的指令在当前位置的可学习嵌入,真跳跃位置的可学习嵌入,假跳跃位置的可学习嵌入。

从图2中我们可以看到,PCE可以将CFG中节点的出边信息纳入注意力模块,而入边信息也会在公式2中计算位置相关性后被捕获。这表明OSCAR可以用PCE捕获CFG的所有信息,即使CFG没有显式地输入到模型中。
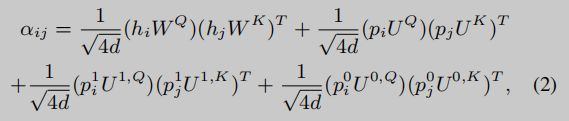
基于优化技术的对比学习如何在预训练期间有效地捕获程序或代码片段级的语义知识对于代码表示模型无疑是至关重要的。然而,之前的工作并没有很好地研究它。实际上,现代编译器支持多种编译选项以满足不同的优化需求,例如最小化执行时间、内存占用、存储大小等。使用不同的优化技术可以将单个源代码翻译成对比IR,但不会改变代码的含义。当然,多种优化的不同组合可以用作源代码的数据增强方法。受此启发,本文建议采用动量编码器对比学习的[CLS]标记的目标作为OSCAR的自监督任务,以更好地促进从程序层面的语义理解。
实验
对公开的开源GitHub存储库中的大量真实程序语料库进行了OSCAR的预训练,涵盖了从操作系统和编译器到机器学习系统和线性代数子程序的广泛学科.
在本节中,我们评估OSCAR在几个程序语义理解任务中的性能。我们首先在一个实际而重要的软件工程任务上执行我们的模型,即Binary Diffing. 然后,在算法分类任务上评估OSCAR对高层次PL理解的性能。此外,作为一种预训练方法,研究了OSCAR在零样本学习中的性能,其中OSCAR的参数是固定的。最后,对消融研究中模型的组成部分进行了分析。
Bin-diff
 如图所示,OSCAR在五个程序的所有优化级别上的召回率都远远超过BinDiff、Asm2vec和BinaryAI。例如,在最困难的匹配情况下,即O0和O3优化水平之间的差异,OSCAR提高了每个程序上所有基线技术的召回率。
如图所示,OSCAR在五个程序的所有优化级别上的召回率都远远超过BinDiff、Asm2vec和BinaryAI。例如,在最困难的匹配情况下,即O0和O3优化水平之间的差异,OSCAR提高了每个程序上所有基线技术的召回率。
Algorithm Classification
在这一小节中,我们将研究OSCAR在高级编程语言理解方面的性能。实验在包含104个算法问题的POJ-104数据集[1]上进行.

与之前的所有方法相比,该模型取得了很大的改进,这表明OSCAR可以很好地理解用高层PLs编写的源代码的语义。
Zero-Shot Learning
我们进一步研究了预训练OSCAR在零样本学习设置中的性能,即在不修改参数的情况下评估OSCAR。
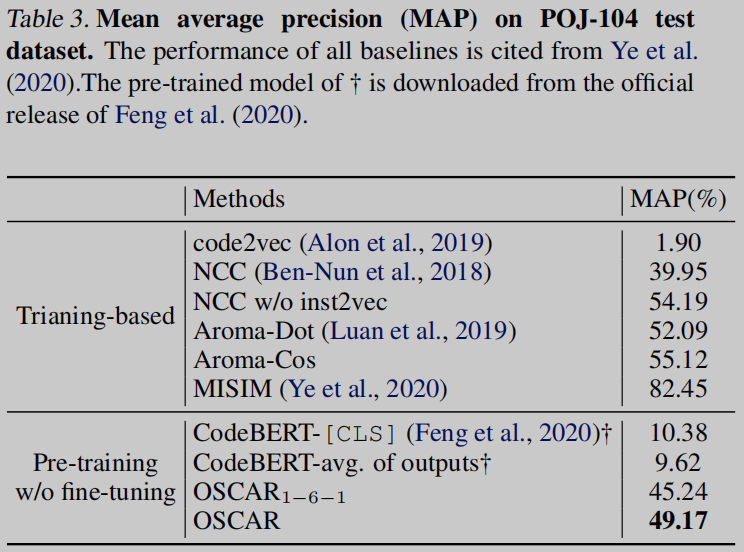
如表3所示,在不进一步修改参数的情况下,与其他预训练模型相比,预训练的OSCAR和OSCAR1−6−1在代码相似性检测方面都表现出了良好的性能。这表明OSCAR在无需微调的情况下对下游任务具有可移植性的潜力。
Ablation Study
在本小节中,我们将使用BusyBox研究OSCAR中每个组件对Binary Diffing任务的影响.

表4 展示OSCAR两个组件 contrastive loss 和 PCE 的消融实验, 如图所示,所有组件都是有益的,提高了二进制diffing任务的召回率。同时,我们在IR语料库上进一步训练BERT,这与CuBERT类似 [2],因为它们共享完全相同的架构,唯一的区别是CuBERT是在Python语料库上预训练的。实验结果表明,CuBERT在IR的二进制diffing任务上表现不佳,这反映了OSCAR的层次结构显著有益。
总结
Related Works
[1] Mou, L., Li, G., Zhang, L., Wang, T., and Jin, Z. Convolutional neural networks over tree structures for programming language processing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30, 2016.
[2] Kanade, A., Maniatis, P., Balakrishnan, G., and Shi, K. Learning and evaluating contextual embedding of source code. 2020.
Insights
(1) Model的作用并不显著, 应该更加关注数据的处理, 考虑使用IR或者伪代码(IDA反编译出的结果)
(2) 一般来说, 如果用IR或者反编译的伪代码, 应该更接近汇编的形式, 作为数据集进行模型训练可能会有更好的效果? 不过目前的难点在于IR的生成问题, 这个问题亟待研究.