深度学习中模型好坏的所有评价指标汇总(混淆矩阵、recall、precision、F1score、AUC面积、ROC曲线、ErrorRate)
导航
- 0、混淆矩阵
- 1、AUC面积
- 2、ROC曲线
- 3、F1score
0、混淆矩阵
- true positives (TP): 在这些情况下,我们预测“yes”(他们有这种病),并且他们确实有这种病。//
正确的将其预测为正样本 - true negatives (TN): 我们预测“no”,事实上他们确实没有患病。//
正确的将其预测为负样本 - false positives (FP): 我们预测“yes”,但是他们实际上并没有患病。(也称为“第一类错误”。) //
错误的将其预测为正样本 - false negatives (FN): 我们预测“no”,但他们确实有这种疾病。(也称为“第二类错误”。) //
错误的将其预测为负样本
- 假正率 / 假阳性率 FPR:预测为正例但实际为负例的样本占所有负例样本(真实结果为负样本)的比例。//
假阳性率:错误的将其预测为正样本的个数占所有负样本的比例- FPR=FP / (FP+TN)
- 召回率recall / 敏感度Sensitivity / 真正率 TPR:预测为正例且实际为正例的样本占所有正例样本(真实结果为正样本)的比例。//
正确的将其预测为正样本的个数占所有正样本的比例- TPR=TP / (TP+FN)
- 特异度Specificity:
正确的将其预测负样本的个数占所有负样本的比例- Specificity=TN / (TN+FP)
- 阳性预测值Positive predictive value PPV/ precision:
正确的将其预测为正样本的个数占所有预测为正样本的比例// 预测为正样本中,有多少是真正的正样本- PPV / Precision=TP / (TP+FP)
- 阴性预测值Negative predictive value NPV:
正确的将其预测为负样本的个数占所有预测为负样本的比例// 预测为负样本中,有多少是真正的负样本- NPV=TN / (FN+TN)
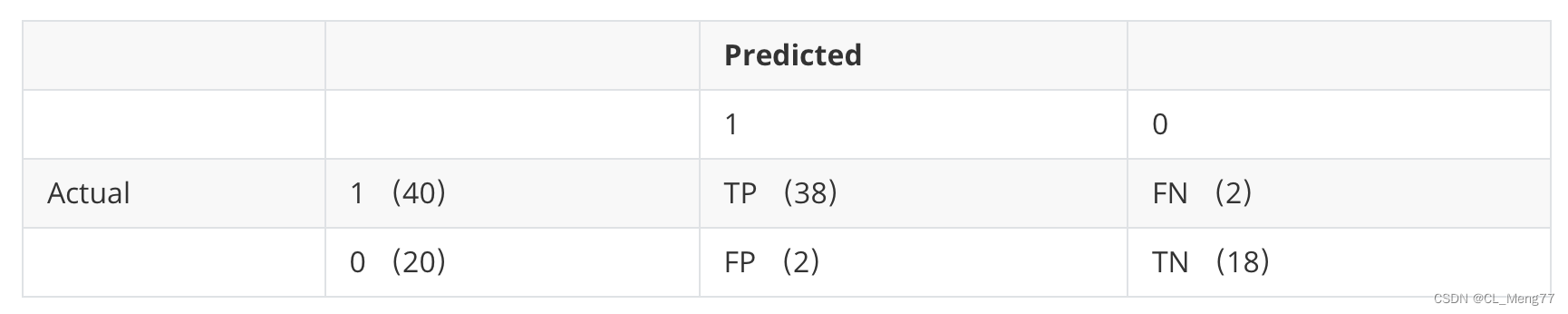
- 解析上表
- 总共有40个正样本,20个负样本;
- 其中,有38个正样本被预测为正样本,有2个正样本被预测为负样本;
- 其中,有18个负样本被预测为负样本,有2个负样本被预测为正样本;
- 其中,假正率FPR为 2/(2+18)=0.1
- 其中,召回率 / 敏感度 / 真正率TPF为 38/(38+2)=0.95
- 医学领域
敏感度/召回率更关注漏诊率(有病之人不能漏)特异度更关注误诊率(无病之人不能误)假正率 / 假阳性率= 1 - 特异度,假阳性越多,误诊越多阳性预测值 / 精确率,是看预测为阳性中,有多少是真阳性阴性预测值是看预测为阴性中,有多少是真阴性
1、AUC(Area under curve)
-
常用于二分类模型
-
理解1:ROC曲线下的面积
-
理解2:随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类模型来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率
-
优点:
- 它不受类别不平衡问题的影响,不同的样本比例不会影响AUC的评测结果。
- 在训练时,可以直接使用AUC作为损失函数
-
计算方式1:
- 在有M个正样本,N个负样本的数据集里。一共有MN对样本(一对样本即,一个正样本与一个负样本)。统计这MN对样本里,正样本的预测概率大于负样本的预测概率的个数
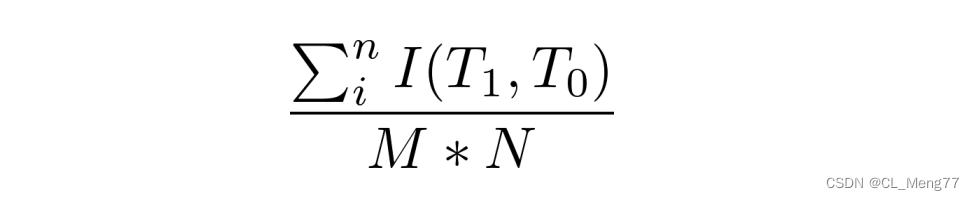

- 假设有4条样本。2个正样本,2个负样本,那么M*N=4。
即总共有4个样本对。分别是:
(d,b),(d,a),(c,b),(c,a)
在(d,b)样本对中,正样本d预测的概率大于负样本b预测的概率(也就是d的得分比b高),记为1
同理,对于(c,b)。正样本c预测的概率小于负样本b预测的概率,记为0
因此,AUC=(1+1+1+0)/4 = 0.75
-
计算方式2:
-
对预测概率从高到低排序
-
对每一个概率值设一个rank值(最高的概率的rank为n,第二高的为n-1)
-
rank实际上代表了该score(预测概率)超过的样本的数目
为了求的组合中正样本的score值大于负样本,如果所有的正样本score值都是大于负样本的,那么第一位与任意的进行组合score值都要大,我们取它的rank值为n,但是n-1中有M-1是正样例和正样例的组合这种是不在统计范围内的(为计算方便我们取n组,相应的不符合的有M个),所以要减掉,那么同理排在第二位的n-1,会有M-1个是不满足的,依次类推,故得到后面的公式M*(M+1)/2,我们可以验证在正样本score都大于负样本的假设下,AUC的值为1 -
除以M*N
-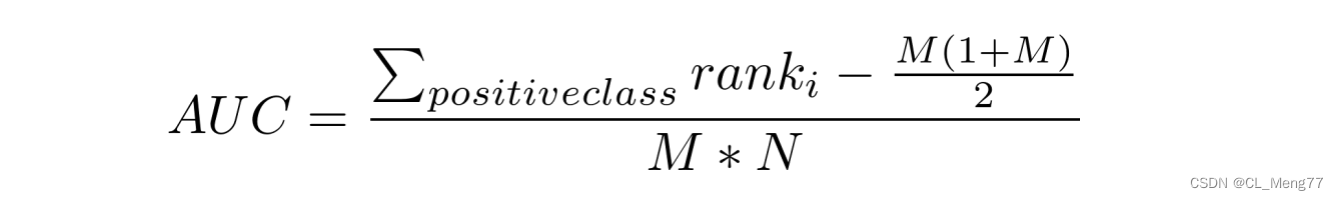
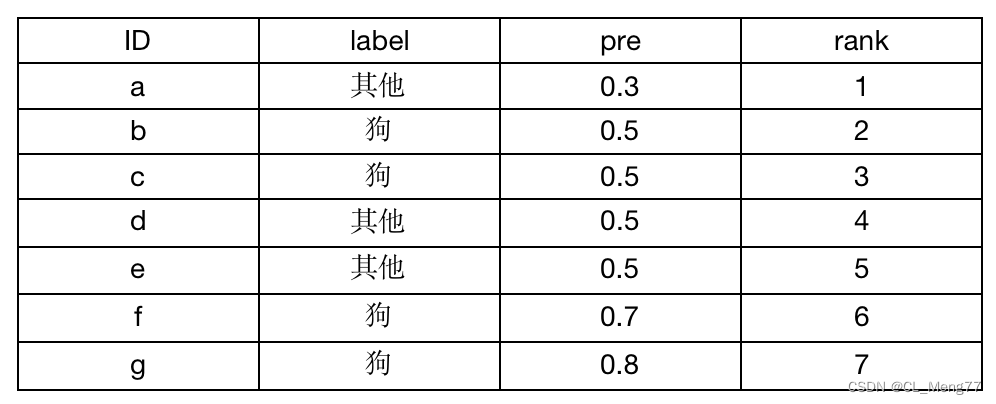
-
tips:相等概率得分的样本,无论正负,谁在前,谁在后无所谓。
-
正样本为狗:数量为4;
扫描二维码关注公众号,回复: 15789784 查看本文章
-
负样本为其他:数量为3
-
由于只考虑正样本的rank值:
-
对于正样本b,其rank值为(5+4+3+2)/4 = 7/2
-
对于正样本c,其rank值为(5+4+3+2)/4 = 7/2
-
对于正样本f,其rank值为 6
-
对于正样本g,其rank值为 7
-
AUC={ 6+7+7/2+7/2- [ 4*(4+1) ] /2 } / (4*3) =0.834
-
-
python实现
import numpy as np from sklearn.metrics import roc_curve from sklearn.metrics import auc y = np.array([1,1,0,0,1,0,1,0,]) pred = np.array([0.77, 0.8, 0.6, 0.1,0.4,0.9,0.66,0.7]) fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1) print("AUC:",auc(fpr, tpr))AUC: 0.5625
2、ROC曲线(receiver operating characteristic curve)
- 用来衡量一个二分类学习器的好坏;
- 如果一个学习器的ROC曲线能将另一个学习器的ROC曲线完全包住,则说明该学习器的性能优于另一个学习器;
- 纵坐标:TPR= TP/(TP+FN) (真正率 / 召回率 / 敏感度 )
- 横坐标:FPR= FP/(FP+TN) (假正率 / 假阳性率)
-
python实现
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import sklearn.metrics as metrics
def plot_ROC(labels,preds,savepath):
"""
Args:
labels : ground truth
preds : model prediction
savepath : save path
"""
# fpr1, tpr1, threshold1 = metrics.roc_curve(labels, preds) ###计算真正率和假正率
fpr, tpr, thresholds = roc_curve(y, pred, pos_label=1)
roc_auc1 = metrics.auc(fpr, tpr) ###计算auc的值,auc就是曲线包围的面积,越大越好
plt.figure()
lw = 2
plt.figure(figsize=(10, 10))
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='AUC = %0.2f' % roc_auc1) ###假正率为横坐标,真正率为纵坐标做曲线
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('1 - Specificity')
plt.ylabel('Sensitivity')
# plt.title('ROCs for Densenet')
plt.legend(loc="lower right")
# plt.show()
plt.savefig(savepath) #保存文件
if __name__=="__main__":
y = np.array([1,1,0,0,1,0,1,0,])
pred = np.array([0.77, 0.8, 0.6, 0.1,0.4,0.9,0.66,0.7])
savepath="./ROC.jpg"
plot_ROC(y, pred, savepath)
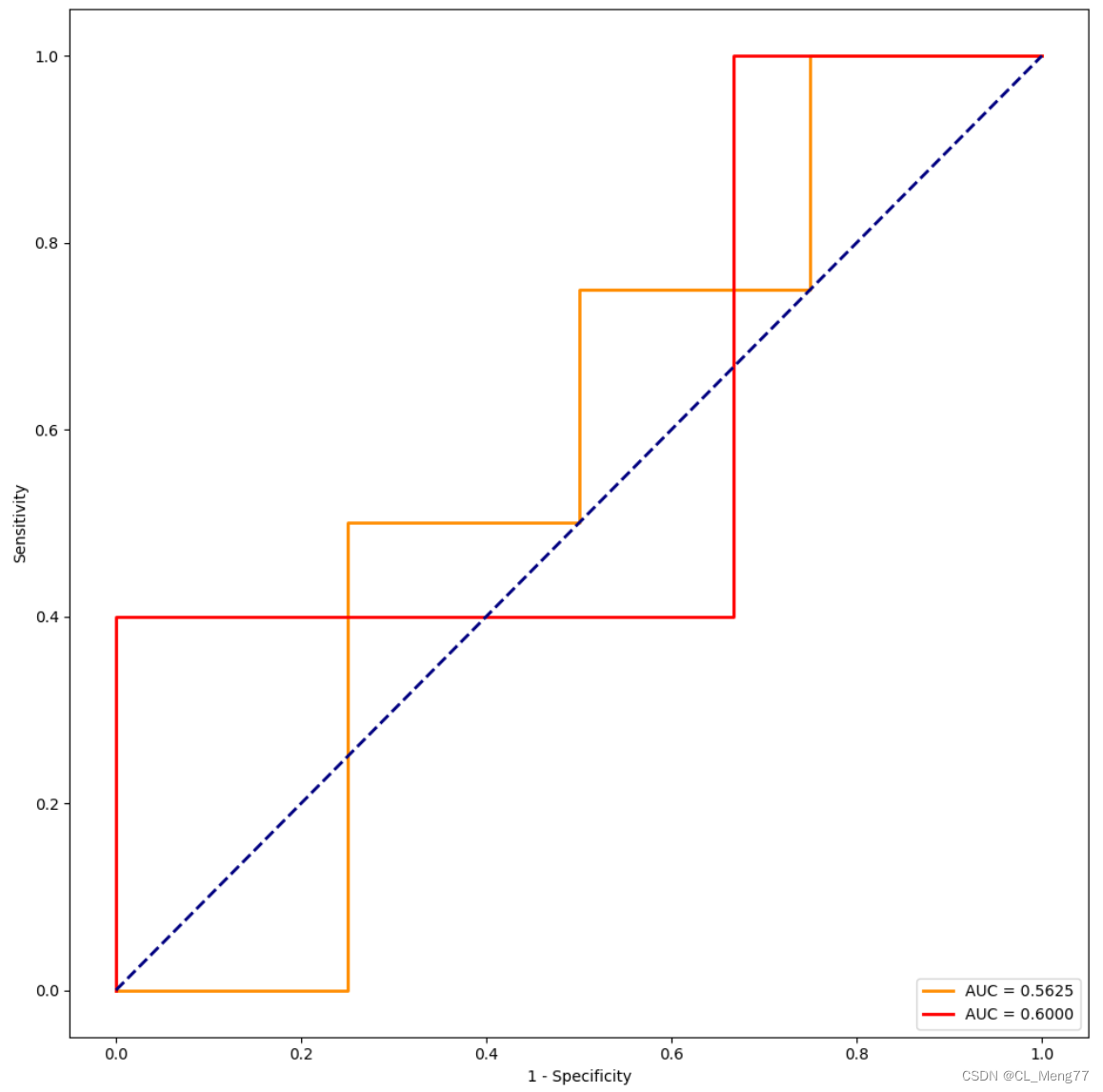
结果如下图所示:

绘制两个模型的ROC曲线
def plot_ROC_2(labels1, preds1, labels2, preds2,savepath):
"""
Args:
labels1 : ground truth
preds1 : model prediction
savepath : save path
"""
plt.figure()
plt.figure(figsize=(10, 10))
fpr1, tpr1, threshold1 = metrics.roc_curve(labels1, preds1) ###计算真正率和假正率
roc_auc1 = metrics.auc(fpr1, tpr1) ###计算auc的值,auc就是曲线包围的面积,越大越好
plt.plot(fpr1, tpr1, color='darkorange', lw=2, label='AUC = %0.4f' % roc_auc1) ###假正率为横坐标,真正率为纵坐标做曲线
fpr2, tpr2, threshold2 = metrics.roc_curve(labels2, preds2) ###计算真正率和假正率
roc_auc2 = metrics.auc(fpr2, tpr2) ###计算auc的值,auc就是曲线包围的面积,越大越好
plt.plot(fpr2, tpr2, color='red', lw=2, label='AUC = %0.4f' % roc_auc2) ###假正率为横坐标,真正率为纵坐标做曲线
plt.xlim([-0.05, 1.05])
plt.ylim([-0.05, 1.05])
plt.xlabel('1 - Specificity')
plt.ylabel('Sensitivity')
# plt.title('ROCs for Densenet')
plt.legend(loc="lower right")
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.show()
# plt.savefig(savepath) # 保存文件
if __name__=="__main__":
y1 = np.array([1, 1, 0, 0, 1, 0, 1, 0, ])
pred1= np.array([0.77, 0.8, 0.6, 0.1, 0.4, 0.9, 0.66, 0.7])
y2 = np.array([0, 1, 1, 1, 1, 1, 0, 0, ])
pred2 = np.array([0.87, 0.91, 0.6, 0.67, 0.3, 0.9, 0.16, 0.8])
savepath="./"
plot_ROC_2(y1,pred1,y2,pred2, savepath)
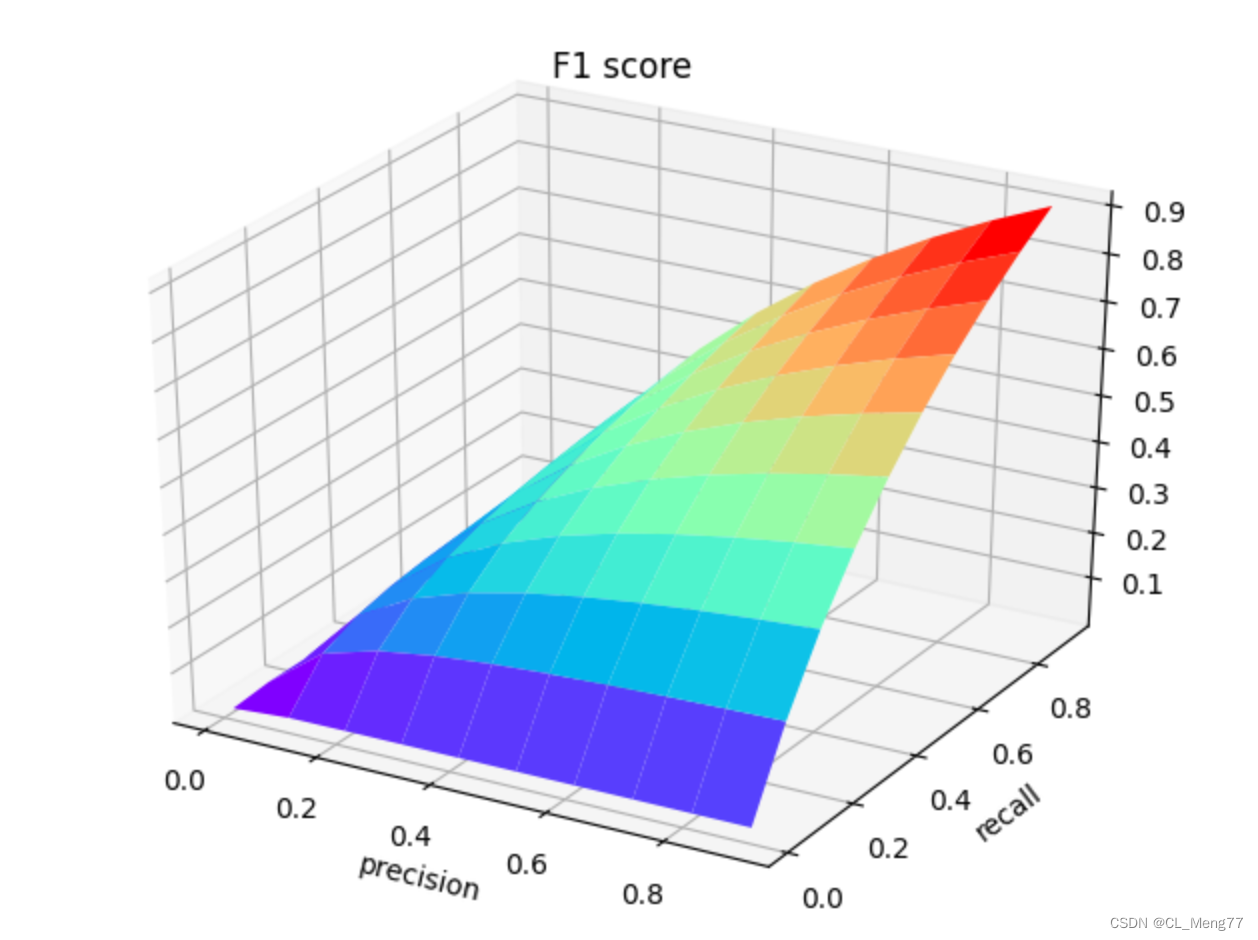
3、F1score
- 用于平衡
精准度precision和召回率recall / 敏感度Sensitivity / 真正率这两种指标,只有当这两个指标都很高时,F1才会高 - python脚本如下
"""
Precision = tp/tp+fp
Recall = tp/tp+fn
进而计算得到:
F1score = 2 * Precision * Recall /(Precision + Recall)
"""
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure() #定义新的三维坐标轴
ax3 = plt.axes(projection='3d')
#定义三维数据
precision = np.arange(0.01, 1, 0.1)
recall = np.arange(0.01, 1, 0.1)
X, Y = np.meshgrid(precision, recall) # 用两个坐标轴上的点在平面上画网格
Z = 2*X*Y/(X+Y)
# 作图
ax3.plot_surface(X, Y, Z, rstride = 1, cstride = 1, cmap='rainbow')
plt.xlabel('precision')
plt.ylabel('recall')
plt.title('F1 score')
plt.show()