1. 使用rowkeys排序列快速读取parquet文件
在进行cube的定义时,默认会有一个rowkeys排序列。这样cube构建时,每个cuboid的维度字段都会根据rowkeys排序列,进行数据的排序保存。这样在数据查询的时候就能很快的检索到数据了
在Cube Designer的Advanced Setting的Rowkeys部分,可以在ID区域拖拽进行rowkeys顺序的自定义,如下所示:
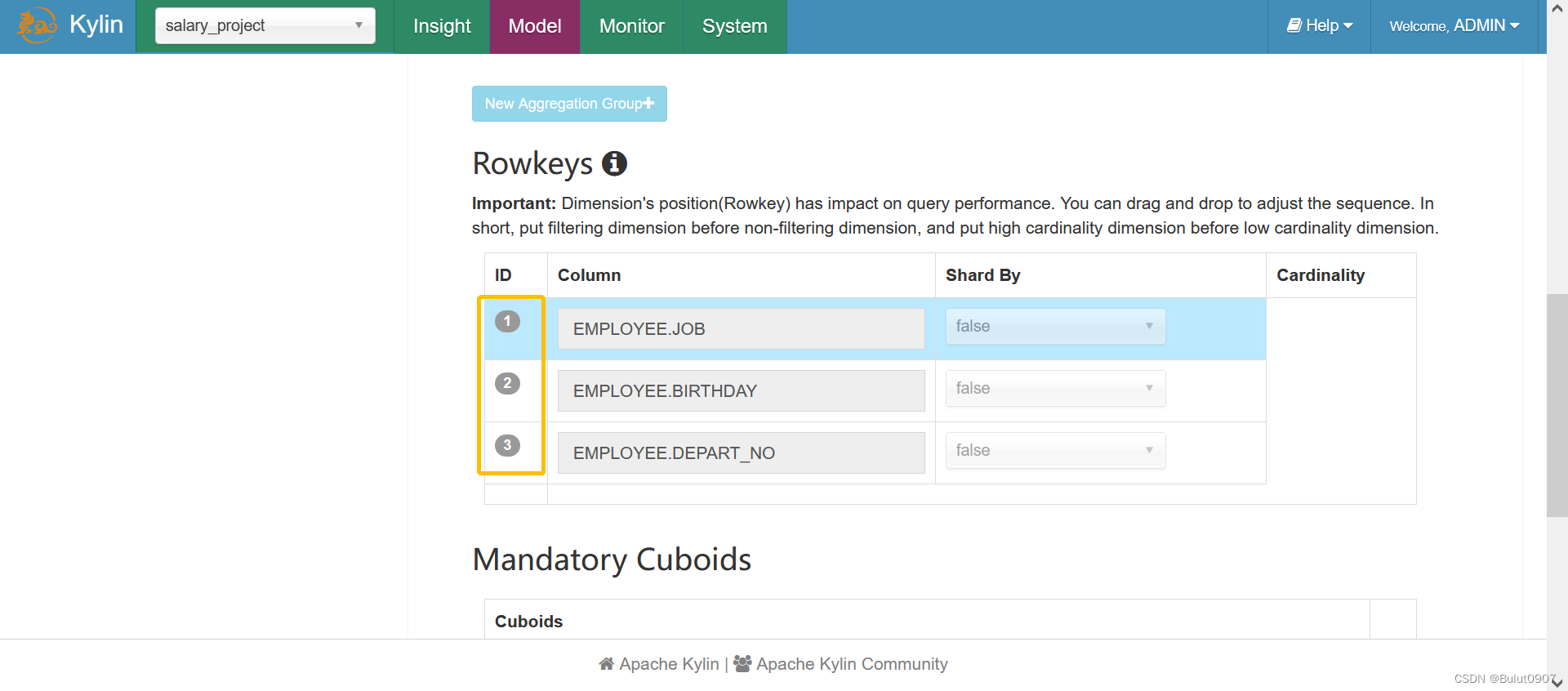
2. 使用shardby列来裁剪parquet文件
默认一个cube的一个segment的一个cuboid里面,会有多个parquet文件。如下所示:
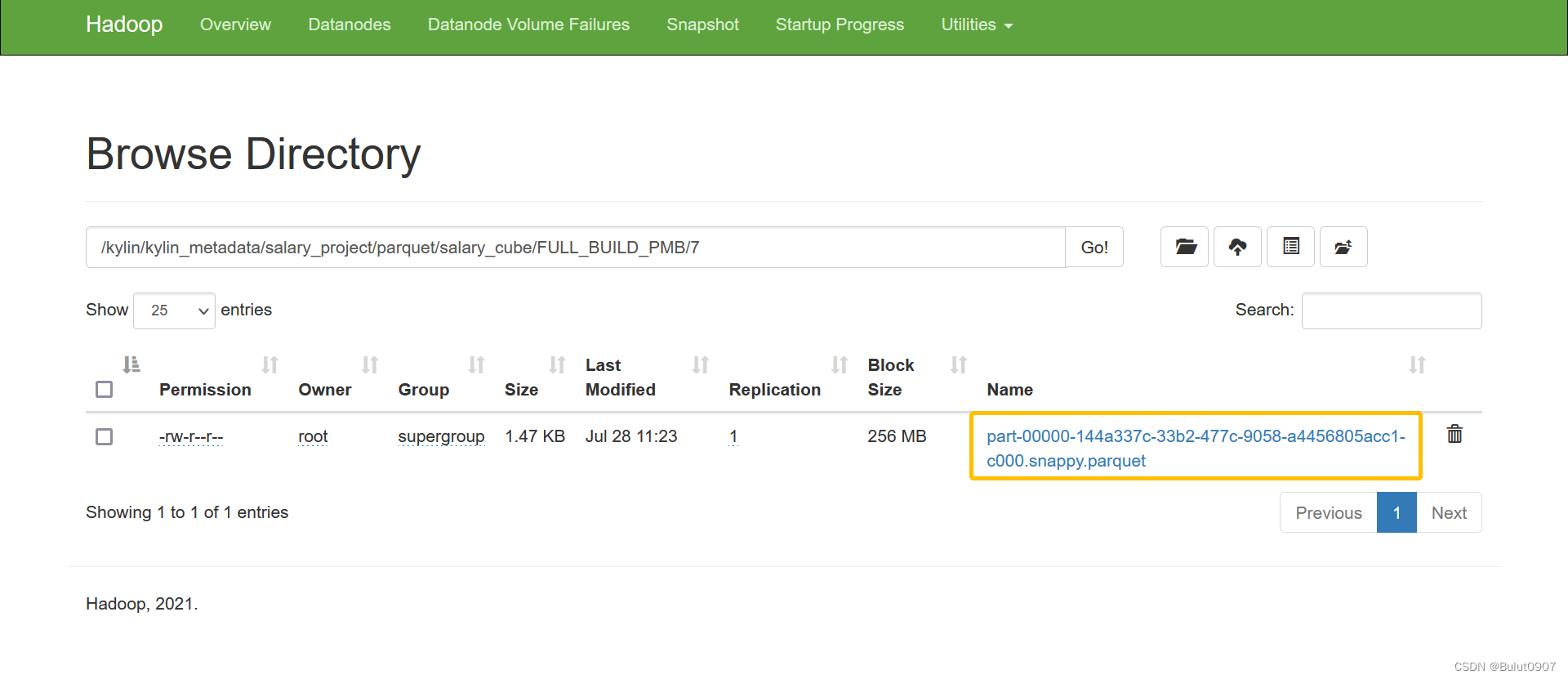 如果将一个列定义为shardBy列,则shardBy列不同的值会形成不同的parquet文件,这样查询的时候对shardBy列做条件过滤,就能直接跳过不必要的文件扫描
如果将一个列定义为shardBy列,则shardBy列不同的值会形成不同的parquet文件,这样查询的时候对shardBy列做条件过滤,就能直接跳过不必要的文件扫描
建议选择高基列(数据基本不重复或者均为唯一值的列),并且会在多个cuboid中
出现的列作为shardBy列
目前在SQL查询中只支持以下过滤操作来裁剪parquet文件:Equality、
In、InSet、IsNull
2.1 shardBy列的使用
先将cube进行Disable,再进行Purge(会删除cube的元数据,但是HDFS上的数据不会删除)
最后进行Edit,在Cube Designer的Advanced Setting的Rowkeys部分,可以定义某些维度为shardBy列,如下所示:
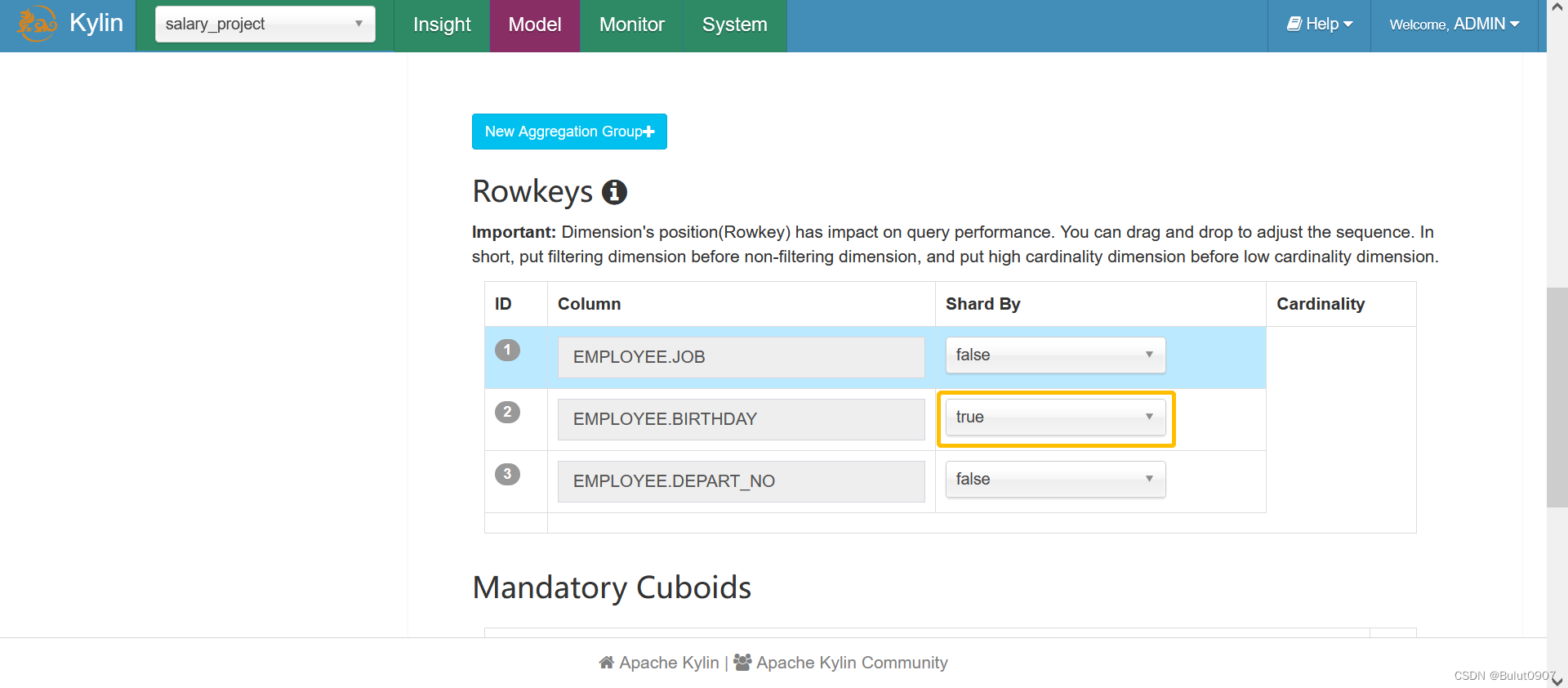 再次进行cube的构建即可
再次进行cube的构建即可