制作VOC数据集过程中,打好标签后,需要将文件名按照自定义比例划分到训练,验证集,测试集中,下面是详细的划分过程:
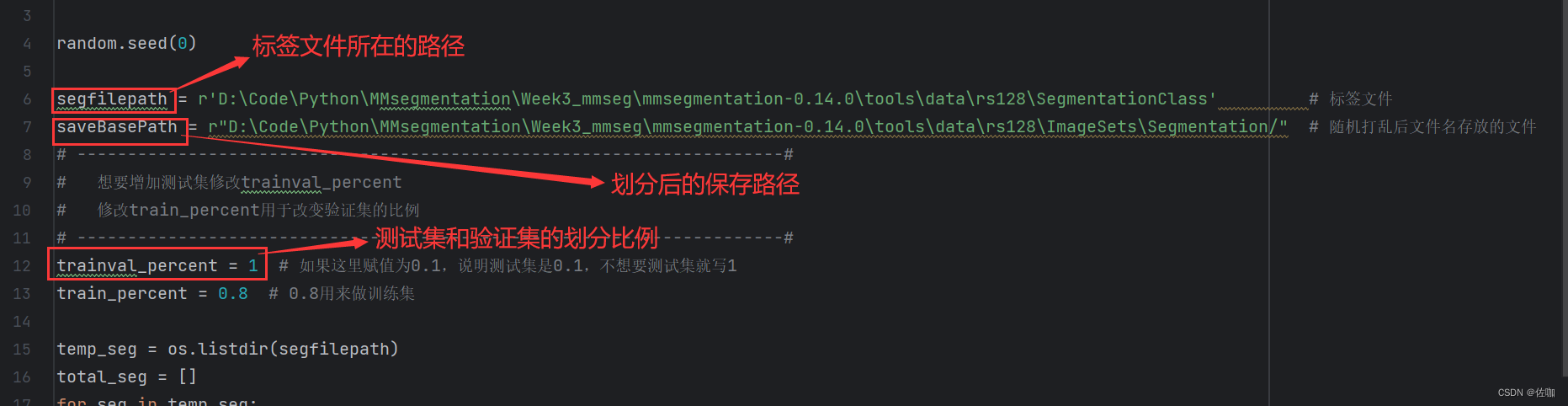
通过下面代码进行划分,要正确导入标签所在文件路径和划分后的保存路径,以及自定义训练集,验证集,测试集的划分比例,需要修改的地方见下:
代码见下:
import os
import random
random.seed(0)
segfilepath = r'D:\Code\Python\MMsegmentation\Week3_mmseg\mmsegmentation-0.14.0\tools\data\rs128\SegmentationClass' # 标签文件
saveBasePath = r"D:\Code\Python\MMsegmentation\Week3_mmseg\mmsegmentation-0.14.0\tools\data\rs128\ImageSets\Segmentation/" # 随机打乱后文件名存放的文件
# ----------------------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# 修改train_percent用于改变验证集的比例
# ----------------------------------------------------------------------#
trainval_percent = 1 # 如果这里赋值为0.1,说明测试集是0.1,不想要测试集就写1
train_percent = 0.8 # 0.8用来做训练集
temp_seg = os.listdir(segfilepath)
total_seg = []
for seg in temp_seg:
if seg.endswith(".png"):
total_seg.append(seg)
num = len(total_seg)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub suze", tr)
ftrainval = open(os.path.join(saveBasePath, 'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath, 'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath, 'train.txt'), 'w')
fval = open(os.path.join(saveBasePath, 'val.txt'), 'w')
for i in list:
name = total_seg[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行代码后生成的4个.txt文件结果如下:
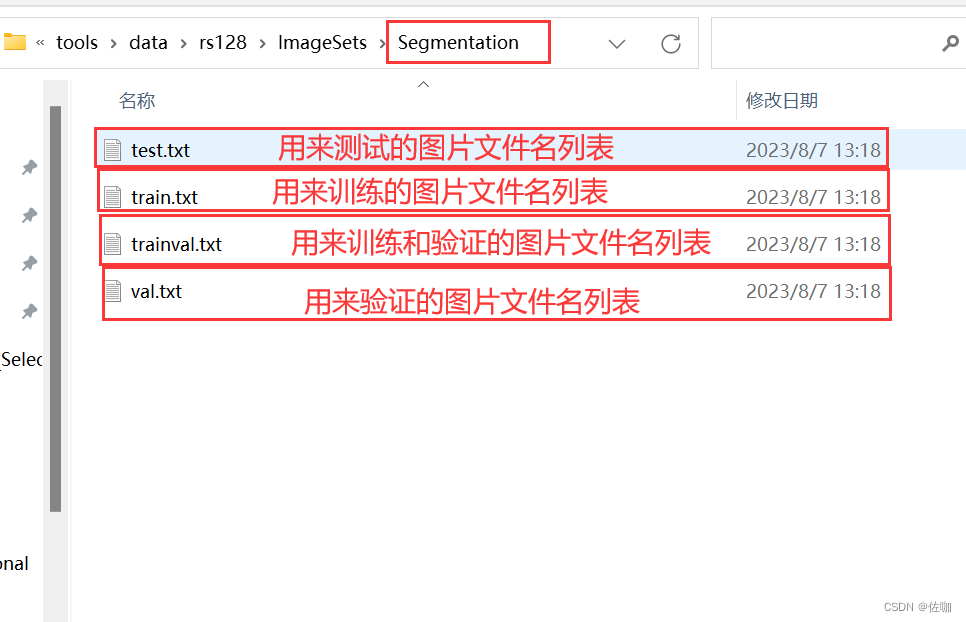
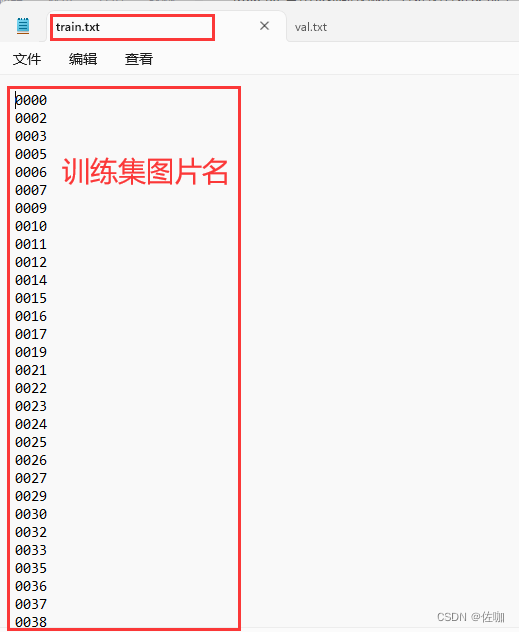
以上就是VOC格式数据集制作:ImageSets->Segmentation文件中的train.txt,test.txt,trainval.txt,val.txt详细制作过程,谢谢!