单目室内3D场景理解
Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image
- 工程主页:https://yinyunie.github.io/Total3D/
- 论文链接:https://arxiv.org/pdf/2002.12212.pdf
- 开源代码:https://github.com/yinyunie/Total3DUnderstanding
- 相关机构:2020, 伯恩茅斯大学,香港中文,深圳大数据中心,厦门大学
论文摘要

摘要核心内容:
- 室内语义重建定义:同时进行场景理解(scene understanding)和目标重建(object reconstruction)。
- 本文贡献:基于单张图,提出端到端,同时进行室内布局重建,目标3Dbox提取,目标网格重建的联合优化。
- 数据集:SUN RGB-D,Pix3D.
论文创新
- 首次提出复杂室内场景下,基于单张图,同时进行室内布局重建,目标边框检测,以及目标网格重建等任务的联合优化。实验表明,多任务同时进行优化的策略使得每一个子任务相互补充,从而使得各个任务均达到业内最佳水平。
- 在目标网格重建任务中,提出一种新的基于密度的网格拓扑修改器。根据局部点集密度,逐步修剪网格的边(edge)。该方法很好的解决了复杂背景下室内目标的重建。
- 我们充分考虑注意力机制,以及目标之间的相互关系。在室内3D目标检测任务中,目标的姿态与周围的目标有着潜在、多方面的相互关系。我们提出的策略提取了潜在的特征(latent features),可以更好的确定目标的位置和姿态,改善3D检测任务。
整体结构

整个网络结构包含如下几个部分:
- 2D目标检测:输入单张场景图,网络为Faster-RCNN,输出为2D目标检测框。
- Layout Estimate Network(LEN):输入为单张场景图,输出为相机姿态,场景布局的 Bounding Box 参数。
- 3D Object Detection Network(ODN):输入包括(1)场景图内2D检测框内的目标图像;(2)几何特征(geometry features),根据2D检测框计算。输出为 3D Bounding Box相关参数的估计。
- Mesh Generatioin Network(MGN):输入包括(1)2D目标检测框的目标图像;(2)2D检测目标类别的one-hot编码;(3)模板球。输出为目标的Mesh网格。
- 融合结果:将所有模块的结果嵌入到一起,统一进行优化,最终得到整个场景的重建结果。首先,通过缩放,将MGN重建的的Mesh置入ODN估计的Bounding Box内,然后通过LEN估计的相机姿态,将其转换到世界坐标系。
核心模块
-
Camera and World Systerm Setting

如上图所示,将世界坐标系与相机坐标系的原点重合,y 轴垂直于地面。围绕 y 轴将世界坐标系的 x 轴与相机的前进方向对齐,因此,相机的 yaw 角可以去除。那么,相机相对于世界坐标系的姿态可以被 pitch β \beta β,roll γ \gamma γ 表达,具体如下:
R ( β , γ ) = [ c o s ( β ) − c o s ( γ ) s i n ( β ) s i n ( β ) s i n ( γ ) s i n ( β ) − c o s ( β ) c o s ( γ ) − c o s ( β ) s i n ( γ ) 0 − s i n ( γ ) c o s ( γ ) ] R(\beta,\gamma)=\left[ \begin{matrix} cos(\beta) & -cos(\gamma)sin(\beta) & sin(\beta)sin(\gamma) \\ sin(\beta) & -cos(\beta)cos(\gamma) & -cos(\beta)sin(\gamma) \\ 0 & -sin(\gamma) & cos(\gamma) \end{matrix} \right] R(β,γ)= cos(β)sin(β)0−cos(γ)sin(β)−cos(β)cos(γ)−sin(γ)sin(β)sin(γ)−cos(β)sin(γ)cos(γ) -
标签的参数化表达
在世界坐标系下,3DBox 可以由 3D 中心 C ∈ R 3 C \in R^3 C∈R3,尺寸 s ∈ R 3 s \in R^3 s∈R3,朝向角 θ ∈ [ − π , π ] \theta \in[-\pi,\pi] θ∈[−π,π]表达。对于室内的目标,3D Box 的中心 C C C 由图像平面的2D投影中心 c ∈ R 2 c \in R^2 c∈R2,以及距离相机中心的距离 d ∈ R d \in R d∈R 表达。给定相机的内参矩阵 K ∈ R 3 K \in R^3 K∈R3, C C C 的表达公式如下:
C = R − 1 ( β , γ ) ⋅ d ⋅ K − 1 [ c , 1 ] T ∣ ∣ K − 1 [ c , 1 ] T ∣ ∣ 2 (1) C=R^{-1}(\beta,\gamma) \cdot d \cdot \frac{K^{-1}[c,1]^T}{||K^{-1}[c,1]^T||_2} \tag{1} C=R−1(β,γ)⋅d⋅∣∣K−1[c,1]T∣∣2K−1[c,1]T(1)
其中,2D 投影中心 c c c 可以进一步被表达为 c b + δ c^b+\delta cb+δ, c b c^b cb 是2D边框的中心, δ ∈ R 2 \delta \in R^2 δ∈R2 表示偏移量,需要被网络学习得到。从2D检测结果 I I I 到 3D Bounding Box,网络的表达为:
F ( I ∣ δ , d , β , γ , s , θ ) ∈ R 3 × 8 F(I|\delta,d,\beta,\gamma,s,\theta)\in R^{3\times8} F(I∣δ,d,β,γ,s,θ)∈R3×8
综述所述,ODN 网络估计的 Bounding Box 参数如下:
( δ , d , s , θ ) (\delta,d,s,\theta) (δ,d,s,θ)
LEN 网络估计的参数包括相机姿态和室内布局的 Bounding Box,分别表达如下:
R ( β , γ ) a n d ( C , s l , θ l ) R(\beta,\gamma)~~and~~(C,s^l,\theta^l) R(β,γ) and (C,sl,θl)
参数化表达的图示如下:

-
Object Detection Network(ODN)
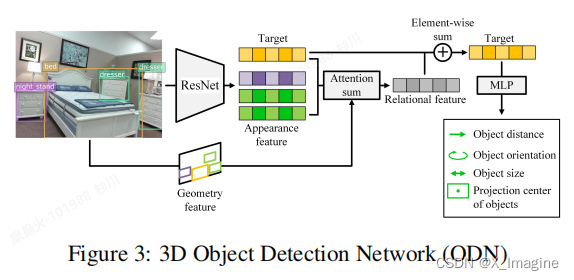
上图是ODN网络的整个结构,基本流程如下:输入:2D检测结果,几何特征(Geometry Feature)
(1)使用 ResNet-34 提取每一个检测框内的图像特征(Apperence Feature)。
(2)将检测框结果以及它们之间的相对位置一起编码为几何特征(gemetry feature),作为输入之一。
(3)使用 object relation module 计算每一个检测目标与其它目标的关系特征(relational feature)。
(4)根据图像特征和几何形状的相似度,进行加权求和,称为 Attention Sum.
(5)以 Element-Wise 的方式,将 Relational Feature 与 Target 特征相加。
(6)使用两层 MLP网络回归每一个box的参数 ( δ , d , s , θ ) (\delta,d,s,\theta) (δ,d,s,θ)。
对于室内的重建,object relation module 表达物理世界中的重要含义:对于距离较近的目标或者外表相似度高目标,往往具有较强的关系。具体的结构,如下表所示:

-
Layout Estimation Network(LEN)
LEN 网络输入是单张场景图,输出为相机姿态 R ( β , γ ) R(\beta,\gamma) R(β,γ),3D Box ( C , s l , θ l ) (C,s^l,\theta^l) (C,sl,θl). 网络结构与ODN一样,但是去除了 关系特征(relational feature). 具体的网络结构如下图:

-
Mesh Generation for Indoor Objects(MGN)

上图是MGN网络的整体结构,具体处理逻辑如下:(1)网络输入:(a)2D检测框内的目标图像;(b)2D检测框内目标类别的one-hot编码(Category Code);(c)模板球(Template Sphere),2562个顶点的单位球。
(2)使用 ResNet-18 提取图像特征(Apperence Feature)。
(3)目标类别的one-hot编码可以提供一定的形状先验信息,有助于更快的拟合至目标的3D形状。
(4)将 Cattegory code 和 Apperence feature 连接,与 Template sphere 一同输入到解码器网络 AtlasNet,可以得到目标的粗略形状。
(5)Edge Classifier:结构与形状解码器(AtlasNet)一样,最后一层使用全连接代替。输入是图像特征以及形变后的目标Mesh,输出 f ( ∗ ) f(*) f(∗)(可以去除冗余的meshes)。
(6)Boundary Refinement:精修Mesh的边界,输出最终的Mesh.具体的网络结构如下:

Density vs Distance:mesh重建过程中,需要修改边的连接对象。之前的方法TMN基于固定的距离修改mesh的拓扑关系。作者认为应该基于局部的几何特性进行拓扑修改。为此,提出基于 ground-truth 的局部密度(local density)自适应的修改Mesh。令 p i ∈ R 3 p_i \in R^3 pi∈R3 是重建mesh上的一个点, q i ∈ R 3 q_i \in R^3 qi∈R3 是 p i p_i pi 在 ground-truth 上的近邻点(见MGN网络结构图)。因此,我们设计二值分类器 f ( ∗ ) f(*) f(∗)预测 p i p_i pi是否接近 ground-truth 网格,方程如下:
f ( p i ) = { F a l s e ∣ ∣ p i − q i ∣ ∣ 2 > D ( q i ) T r u e otherwise (2) f(p_i)= \begin{cases} False & ||p_i-q_i||_2>D(q_i)\\ \tag 2 True & \text{otherwise} \end{cases} f(pi)={ FalseTrue∣∣pi−qi∣∣2>D(qi)otherwise(2)
其中, D ( q i ) = max min q m , q n ∈ N ( q i ) ∣ ∣ q m − q n ∣ ∣ 2 , m ≠ n D(q_i)=\max\min\limits_{q_m,q_n\in N(q_i)}||q_m-q_n||_2,m\ne n D(qi)=maxqm,qn∈N(qi)min∣∣qm−qn∣∣2,m=n, N ( q i ) N(q_i) N(qi) 表示 q i q_i qi在ground-truth上的邻域点集合, D ( q i ) D(q_i) D(qi)表示局部密度。
损失函数
- Individual loss
ODN和LEN:使用分类和回归损失 L c l s , r e g = L c l s + λ r L r e g L^{cls,reg}=L^{cls}+\lambda_rL^{reg} Lcls,reg=Lcls+λrLreg 优化 ODN和LEN的参数 ( θ , θ l , β , γ , d , s , s l (\theta,\theta^l,\beta,\gamma,d,s,s^l (θ,θl,β,γ,d,s,sl)。 C , δ C,\delta C,δ 使用L2损失。
MGN:使用Chamfer loss L c L_c Lc,边损失为 L e L_e Le,边界损失 L b L_b Lb,交叉熵损失 L c e L_{ce} Lce。 - Joint loss
L = ∑ x ∈ { δ , d , s , θ } λ x L x + ∑ y ∈ { β , γ , C , s l , θ l } λ x L x + ∑ z ∈ { c , e , b , c e } λ z L z + λ c o L c o + λ g L g (4) L=\sum_{x\in{\lbrace\delta,d,s,\theta\rbrace}} \lambda_xL_x+\sum_{y\in{\lbrace\beta,\gamma,C,s^l,\theta^l\rbrace}} \lambda_xL_x+\sum_{z\in{\lbrace c,e,b,ce\rbrace}} \lambda_zL_z+\lambda_{co}L_{co}+\lambda_gL_g \tag{4} L=x∈{ δ,d,s,θ}∑λxLx+y∈{ β,γ,C,sl,θl}∑λxLx+z∈{ c,e,b,ce}∑λzLz+λcoLco+λgLg(4)
其中,前三项分别表示ODN,LEN,MGN各自的损失。后两项表示联合损失项, L c o L_{co} Lco 保证预测的LEN,ODN Boxes的世界坐标系与ground-truth的一致性。 L g L_g Lg 为了约束重建的Mesh与场景点云的对齐。由于室内场景实际场景通常比较粗糙,部分遮挡,所有没有使用 Chamfer distance 定义 L g L_g Lg,联合训练的全局损失如下:
L g = 1 N ∑ i = 1 N 1 ∣ S i ∣ ∑ q ∈ S i min p ∈ M i ∣ ∣ p − q ∣ ∣ 2 2 (3) L_g=\frac{1}{N}\sum_{i=1}^N\frac{1}{|S_i|}\sum_{q\in S_i}\min\limits_{p\in M_i}||p-q||^2_2 \tag{3} Lg=N1i=1∑N∣Si∣1q∈Si∑p∈Mimin∣∣p−q∣∣22(3)
实验设置
- 数据集
SUN RGB-D:10335张室内图片,标注3D布局,2D/3D bounding box,稀疏的点云。
Pix3D:395个家具模型,9个类别,与10069张图对齐,用于训练Mesh重建。 - 评估指标
Layout:使用IoU评估。
Camera Pose:MAE误差。
Object Detection:所有类的AP值。
Single Mesh Generation:Charmfer 距离,评估空间上两个点云集的相似度。
Scene Mesh:方程(4)中的 L g L_g Lg. - 训练策略
首先,在SUN RGB-D上独立的训练LEN,ODN网络,在Pix3D上训练MGN网络。然后,将Pix3D与SUN RGB-D一起监督Mesh的生成训练,并且联合训练所有的网络。 - 推理
单个2080Ti,一个场景大概需要1.2s推理时间。
实验结果
- 3D目标检测的量化结果
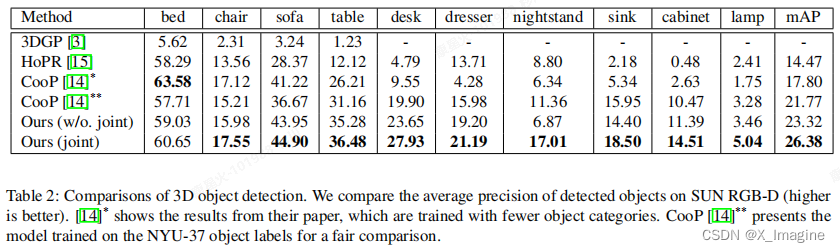
- Mesh重建结果

Holistic 3D Scene Understanding from a Single Image with Implicit Representation
论文摘要

摘要核心内容:
- 论文目的:基于单张图进行3D场景理解,可以预测单张图内的目标形状(object shapes),目标姿态(object poses),场景布局(scene layout)。
- 面临挑战:众所周知,单图恢复3D信息是一个病态问题(ill-posed problem);室内目标面临严重的遮挡、粘连、聚集等问题。
- 解决办法:(1)利用最新的深度隐式表达(deep implicit represention)解决;(2)提出基于图像的局部隐式网络结构改善目标形状的估计;(3)提出新的隐式图神经网络(SGCN),修正3D姿态和场景布局的估计。(4)提出新的【physical violation loss】损失解决重叠目标的信息估计。
前置知识
图卷积网络(GCN)
直观定义:在图结构上进行卷积操作,进而提取特征。根据提取的卷积特征,进行节点分类(node classification),图分类(graph classification),边预测(link prediction)。
图的基本结构:节点(node),边(edge),边也分为有向或无向。
基本原理:假设有一批图数据,其中有N个节点(node),每个节点都有自己的特征,假设特征一共有D个,我们设这些节点的特征组成一个N×D维的矩阵X,各个节点之间的关系也会形成一个N×N维的矩阵A,也称为邻接矩阵(adjacency matrix)。X和A便是模GCN模型的输入。
简单图例:如下图所示,输入C,经过若干隐藏层(图卷积层,类似全连接层的作用),输出层F(节点特征被更新),激活函数可以是ReLU等。GCN输入一个图,通过若干层,GCN每个Node的特征从X变为Z,但是无论经过多少层,Node之间的连接关系都是共享的,也即是邻接矩阵。
GCN的传播公式: H ( l + 1 ) = δ ( D − 1 / 2 A ∗ D 1 / 2 H ( l ) W ( l ) ) H^{(l+1)}=\delta(D^{-1/2}A^*D^{1/2}H^{(l)}W^{(l)}) H(l+1)=δ(D−1/2A∗D1/2H(l)W(l))
下图中的特征矩阵X相当于公式中的H,公式中, A ∗ = A + I A^*=A + I A∗=A+I, I I I 是单位矩阵,相当于无向图G的邻接矩阵自连接。如此,聚合时,既可以聚合来自其它节点的信息,也能聚合自身节点的信息。 D D D 是 A ∗ A^* A∗的度矩阵, H H H 是每一层特征, W W W 是每一层的权重参数。



论文创新
论文贡献体现在四个方面,具体如下:
- 基于单张图,设计 【two-stage】 3D场景理解系统。借助深度隐式表达【deep implicit representation】,同时预测目标形状,目标姿态,场景布局,并且可以同时优化后两项。
- 提出局部隐式形状嵌入网络(local implicit shape embedding network),可以提取目标精确的潜在形状信息。
- 提出基于 GCN 的场景上下文理解网络,可以对初始估计进行精修。
- 设计新的损失函数 【physical violation loss】,解决预测目标交叉的问题。
网络结构

上图是本文整体网络结构:包括初始化估计阶段(Initial Estimation Stage)和改善阶段(Refinement Stage)
- 2D Dectector:输入2D图像,使用Faster-RCNN进行2D目标检测。
- Object Detection Network(ODN):输入2D检测框内图像和2D检测框生成的几何特征(Geometry Feature),估计目标的初始 3D Bounding Boxes 参数。
- Local Implicit Embedding Network(LIEN):输入2D检测框内图像和检测目标类别的 one-hot 编码,提取隐式局部的形状信息,得到目标的潜在编码(latent code)。
- Layout Estimation Network(LEN):输入场景图像,估计 3D Layout Bounding Box 参数 以及相机姿态。
- Scene Graph Convolutional Network(SGCN):图卷积网络,根据场景内上下文信息,精修初始估计的各种结果。
- LDIF:解码模块,将LIEN的潜在编码特征解码为具体的3D几何体。
Scene Graph Convolutional Network(SGCN)
该模块是作者的创新点之一,借助图卷积网络(GCN),融合初始阶段的各种特征,对其进行修正,得到最优的场景重建结果。下图是SGCN的具体结构,输入是初始阶段的各个模块的特征,将其转换为各种节点特征(如下图所示,Layout Feature,Relation Feature,Object Feature),然后将分别通过【MLPs】将特征转换为相同长度的表达(如下图,Layout Representation,Relation Representation,Object Representation,长度均为512)。

场景图卷积网络(SGCN)的构造过程具体如下:
- 将整个场景构造为一张图 G G G。该图有三种类型的节点(Nodes):目标节点(object node),场景布局节点(scene layout node),以及它们之间的关系节点(relationship node)。初始的图是无向边图,保证目标(object)和布局(layout)之间的信息相互流动。然后,在每一对object/layout 之间添加关系节点(relation node)。
- 对于不同类型的节点,根据输入源的不同,输入特征是被精心设计的。对于每一个节点,特征会被 flattened and concaenated 为一个向量,然后利用 MLP 将其转换为相同长度的向量,最终将其嵌入一个节点的表达向量。
- Layout Node:特征组成包括LEN提取的图像基础特征,layout bounding box的参数化输出,相机姿态,以及相机的内参连接(作为相机先验知识)。
- Object Node:特征组成包括ODN提取的基础图像特征,LIEN的分析编码(analytic code),2D Detector预测框类别的one-hot编码特征(引入语义信息)。
- Relationship Node:(1)两个object之间(objec–object)的关系节点的特征包括2D边框生成的几何特征(geometry feature)和目标的3D边框信息。(2)目标和布局(object–layout)的关系节点特征被初始化为固定值,然后由SGCN网络学习得到合理的关系表达。
- 假设图包含N个目标,1个布局,那么,object-layout nodes,relationship nodes 可以被表达为两个矩阵 Z o ∈ R d × ( N + 1 ) a n d Z r ∈ R d × ( N + 1 ) 2 Z^o \in R^{d\times(N+1)}~~and~~Z^r \in R^{d\times(N+1)^2} Zo∈Rd×(N+1) and Zr∈Rd×(N+1)2. 针对不同的【sourc-destination】类型,定义独立的消息传递权重(message passing weights)。假设 source node 的类型为a,destination node 的类型为b,我们定义线性变换(linear transformation)和邻接矩阵(adjacent matrix)分别为 W a b , α a b W^{ab},\alpha ^{ab} Wab,αab.
- Node 更新策略:假设 source object(or layout)为 s,destination object (or layout)为 d,relationship 为 r,那么object node 和 layout node 的表达更新策略如公式(1),relationship node 更新表达为公式(2):
- message passing x4:经过四次消息传递,独立的【MLPs】将 object node Representation 解码为相关的 bounding box 参数( δ , d , s , θ \delta,d,s,\theta δ,d,s,θ),以及 layout node 解码为 ( C , s l , θ l C,s^l,\theta^l C,sl,θl)和相机姿态 R ( β , γ ) R(\beta,\gamma) R(β,γ)。

Local Implicit Embedding Network
- LIEN 网络结构
如下图所示,网络的输入是2D目标检测结果,以及检测框类别的one-hot编码(提供一定的形状先验),输出是 32 × 42 32\times42 32×42 的特征向量。

- Latent code and Analytic code?
根据网络结构可知,LIEN网络是为了得到目标形状信息的潜在编码。那么应该将什么特征融入节点,才更有利于SGCN网络有效的提取场景目标的上下文信息?论文提出使用局部隐式表达特征。如上图所示,LIEN得到(32x42)的特征矩阵,其中 32表示32个3D元素,42包括10个高斯函数参数(analytic code)和 32维度 latent variables(latent code)。高斯参数描述每一个高斯函数的缩放常量,中心点,半径,欧拉角,显然它们包含了3D几何体的结构信息。因此,将 analytic code 作为 object node 的特征之一,也为SGCN提供局部目标的结构信息。
损失函数
- 单个模型的损失函数
单独训练LIEN以及LDIF,损失函数如下,
L p = λ n s L n s + λ u s L u s (3) L_p=\lambda_{ns}L_{ns}+\lambda_{us}L_{us} \tag{3} Lp=λnsLns+λusLus(3)
其中, L n s , L u s L_{ns},L_{us} Lns,Lus表示靠近目标表面的采样点和均匀采样点。
LEN损失:
L L E N = ∑ y ∈ { β , γ , C , s l , θ l } λ y L y (4) L_{LEN}=\sum_{y\in\lbrace \beta,\gamma,C,s^l,\theta^l\rbrace}\lambda_yL_y\tag{4} LLEN=y∈{ β,γ,C,sl,θl}∑λyLy(4)
ODN损失:
L O D N = ∑ x ∈ { δ , d , s , θ } λ x L x (5) L_{ODN}=\sum_{x\in\lbrace \delta,d,s,\theta\rbrace}\lambda_xL_x\tag{5} LODN=x∈{ δ,d,s,θ}∑λxLx(5) - 联合损失
L j = L L E N + L O D N + λ c o L c o + λ p h y L p h y (6) L_j=L_{LEN}+L_{ODN}+\lambda_{co}L_{co}+\lambda_{phy}L_{phy}\tag{6} Lj=LLEN+LODN+λcoLco+λphyLphy(6)
其中, L p h y L_{phy} Lphy 是提出的新的损失,用于解决预测目标相互交叉的问题。具体的损失公式如下:
L p h y = 1 N ∑ i = 1 N 1 ∣ S i ∣ ∑ x ∈ S i ∣ ∣ r e l u ( 0.5 − s i g ( α L D I F i ( x ) ) ) ∣ ∣ (7) L_{phy}=\frac{1}{N}\sum_{i=1}^N\frac{1}{|S_i|}\sum_{x \in S_i}||relu(0.5-sig(\alpha LDIF_i(x)))|| \tag{7} Lphy=N1i=1∑N∣Si∣1x∈Si∑∣∣relu(0.5−sig(αLDIFi(x)))∣∣(7)
其中, L D I F i ( x ) LDIF_i(x) LDIFi(x) 将目标 i i i 的坐标点 x x x 转换为LDIF值,经过 sigmoid函数,得到LDIF的预测值,ReLU表示只惩罚交叉点。惩罚交叉点 p p p 如下图所示,

实验设置
- 数据集
Pix3D,SUN RGB-D,具体参考前面Total3D的解析。 - 评估指标
参考前面的Total3D。 - 实验细节
直接使用Total3D 2D目标检测的输出,LEN,ODN与Total3D的结构一样。LIEN与LDIF一起在Pix3D上训练。SGCN在SUN RGB-D上训练。训练过程依然是先独立训练各个模块,然后联合训练,独立训练SGCN时,不用损失 L p h y L_{phy} Lphy.
实验评估
- SUN RGB-D 量化

- Mesh重建结果
