一、为什么需要逻辑回归?
线性关系的拟合效果很好、计算速度快、分类不是固定的0,1,而是类概率数字。
抗噪能力强。
1. sklearn中的逻辑回归

评估类:

1.1 LogisticRegression
参数:

- penalty:l1 或者 l2,表示是哪种正则方式。默认l2.若是l1,则参数solver只能使用liblinear。但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小。
- C :必须是一个大于0的浮点数,默认0.1。c越小,正则化的效果越强,对损失函数惩罚越重。
我们使用“损失函数"这个评估指标,**来衡量参数p的优劣,即这一组参数能否使模型在训练集上表现优异。**如果用一组参数建模后,模型在训练集上表现良好,那我们就说模型表现的规律与训练集数据的规律一致,拟合过程中的损失很小,损失函数的值很小,这一组参数就优秀;相反,如果模型在训练集上表现糟糕,损失函数就会很大,模型就训练不足,效果较差,这一组参数也就比较差。即是说,我们在求解参数p时,追求损失函数最小,让模型在训练数据上的拟合效果最优,即预测准确率尽量靠近100%
- 损失函数如下:
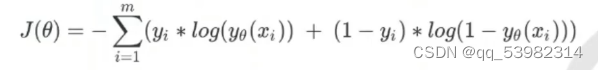
由于我们追求损失函数的最小值,让模型在训练集上表现最优,可能会引发另一个问题:**如果模型在训练集上表示优秀,却在测试集上表现糟糕,模型就会过拟合。**虽然逻辑回归和线性回归是天生欠拟合的模型,但我们还是需要控制过拟合的技术来帮助我们调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。 - 正则化:

第一个是绝对值之和的平均数,第二个是平方和开根的平均数。
代码:
from sklearn.liner_model import LogisticRegression as lr
from sklearn.datasets import load_breast_cancer as lbc
import numpy as np
import matplotlib.pyplot as pt
from sklearn.model_selection import train_test_split as ttp
from sklean.metrics import accuracy_score as acs
data=lbc()//字典
x=data.data
y=data.target
print(s.shape) //569,30
lr1=lr(penalty="l1",solver="liblinear",C=0.5,max_iter=1000)
lr2=lr(penalty="l2",solver="liblinear",C=0.5,max_iter=1000)
lr1=lr1.fit(x,y)
print(lr1.coef_)//p
print(lr1.coef_!=0).sum(axis=1)//p不等于0的个数
lr2=lr2.fit(x,y)
print(lr2.coef_)//不会出现0
哪个效果更好?

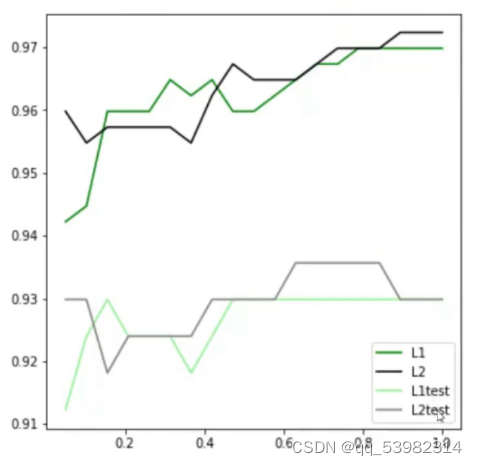
横坐标是c的值,由图可得,在该图l2较好。