一、pca
pca使用的信息衡量指标就是样本的方差。
方差越大,所携带的信息量越多:
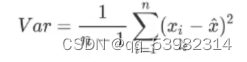
1.pca降维是如何实现的?
class sklearn.decomposition.PCA
- 参数:
n_components:降维后所需要的维度。要小于特征数量。如果是需要可视化,一般就是2,或者3.
copy:
whiten:
svd_solver:
random_state:
降维原理:用二维举例:
若是所有的点都来自于y=x这条线,它是二维的,若他顺时针旋转了45°,这样就是在坐标轴上的一条直线。此时它变成了一维。只需要y`=0这条线。并且这条线上的所有的点的距离比例是没有改变的。(即保留了原本的信息)
2.代码
from matplotlib import pyplot as pt
from sklran.datasets import load_iris as li
from sklean.decomposition import PCA pa pca
//提取数据集
iris=li()
y=iris.target
x=iris.data
print(x.shape) //(150,4) 2维
import pandas as pd
pd.DataFrame(x) //在特征矩阵中,维度是特征的数量,4维-》2维 降维
//降维
pca=pca(n_components=2)
x_new=pca.fit_transform(x)
print(y) //y是0,1,2三种类型
colors=["red","black","orange"]
print(iris.target_names)
pt.figure(figsize=(20,8))
for i in[0,1,2]:
pt.scatter(x[y==i,0],x[y==i,1],alpha=.7,c=colors[i],label=iris.target_names[i])
pt.legend()
pt.title(;pca of iris dataset')
pt.show()
如何查看所带信息量:
pca=pca().fit(x)
print(pca.explained_variance_ratio_)
返回信息: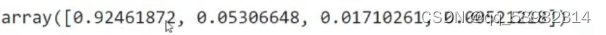
即每个特征占总特征的比值。累加起来就知道这4维特征所占所有信息的比例。
二、SVD
PCA和SVD是两种不同的降维算法,但他们都遵从上面的过程来实现降维,只是两种算法中矩阵分解的方法不同,信息量的衡量指标不同罢了。
PCA使用方差作为信息量的衡量指标,并且特征值分解来找出空间V。降维时,它会通过一系列数学的神秘操作(比如说,产生协方差矩阵)将特征短阵X分解为三个矩阵,其中一个只有对角线上有值的就是方差矩阵。
降维完成之后,PCA找到的每个新特征向量就叫做“主成分”,而被丢弃的特征向量被认为信息量很少,这些信息很可能就是噪音

1.svd
奇异值分解
三、降维和特征选择都是特征工程技术,有什么区别?
特征工程中有三种方式:特征提取,特征创造和特征选择。特征选择是从已存在的特征中选取携带信息最多的,选完之后的特征依然具有可解释性。
而降维算法,是将已存在的特征进行压缩,降维完毕后的特征不是原本的特征矩阵中的任何一个特征,而是通过某些方式组合起来的新特征。通常来说,**在新的特征矩阵生成之前,我们无法知晓降维算法们都建立了怎样的新特征向量,新特征矩阵生成之后也不具有可读性,**我们无法判断新特征矩阵的特征是从原数据中的什么特征组合而来,新特征虽然带有原始数据的信息,却已经不是原数据上代表着的含义了。降维算法因此是特征创造 (feature creation,或feature construction) 的一种。
可以想见,PCA一般不适用于探索特征和标签之间的关系的模型(如线性回归),因为无法解释的新特征和标签之间的关系不具有意义。在线性回归模型中,我们使用特征选择。