【论文】基于可微分二值化的实时场景文字检测模型:1911.Real-time Scene Text Detection with Differentiable Binarization
【代码】官方代码pytorch | | 飞浆PaddleOCR
主要参考
- 唐宇迪视频讲解: OCR文字识别:迪哥带你从零详解DBNet+ABINet算法
- DBNet阅读笔记 - 周军的文章 - 知乎 https://zhuanlan.zhihu.com/p/94677957
为什么要理解这篇论文?
主流的OCR框架都将其集成,作为基础经典实用算法,应对一般检测需求无压力
华为MindSpore 框架 : MindOCR 集成
微信: WeChat OCR engine
OpenCV:DNN模块
百度 paddle框架:PaddleOCR
OpenMMLab : MMOCR集成
本文的核心思想 ?
基于实例分割的DBNet算法,
DBNet将二值化进行近似,使其可导,融入训练,从而获取更准确的边界,大大降低了后处理的耗时
标注、训练流程图
看不清楚见原论文或者后续
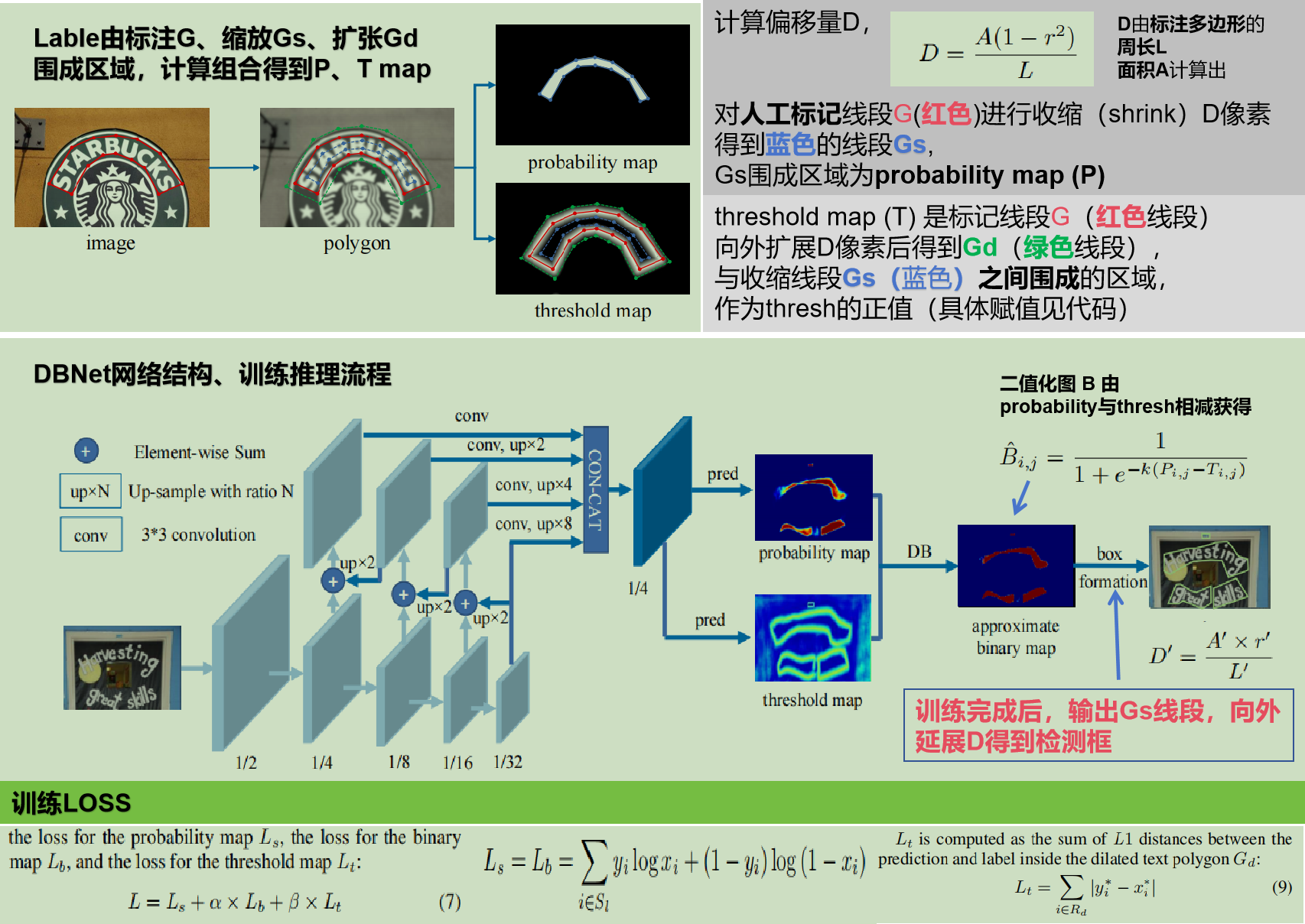
训练与推理细节
我们首先用SynthText数据集(由80万图片组成),对模型就行从零训练,进行100k次迭代
然后再用实际场景的数据,迭代1200 epochs
训练的batch_size=16
学习率策略 lr= 0.007 * (1- cur_iter/max_iter) 0.9 ^{0.9} 0.9
开源的数据集
- SynthText (合成的80万基础数据集)
- MSRA-TD500 dataset (300张中英文训练集,200张测试集,
按行标注(text-line level.)) - ICDAR 2015 dataset (1000张训练图片,500张测试,
单词级标注(labeled at the word level)) - Total-Text dataset (1255 训练图片 and 300 测试图片)

数据增强策略
- 随机旋转 -10度到10度
- 随机裁剪 (random cropping)
- 随机反转 (random flipping)
- 图片resize到 640 x 640 (为了更好的训练效果)
推理
- 保持图片的长宽比后,再resize
- 基于1080ti 单张推理
- 后推理占整个处理时间的 30%
在推理阶段内,我们可以使用概率映射图(probability)或近似的二进制映射图(approximate binary map)来生成文本边界框 ,从而产生几乎相同的结果(2选一,因为训练好了,就能直接得到了)。
为了提高效率,我们使用概率映射,以便可以删除阈值分支( threshold branch)
生成box的过程 (后处理)
- 概率映射图(probability)或近似的二进制映射图(approximate binary map) 直接实用
固定的阈值0.2进行二值化 - 得到的二值图,实际是收缩的文字区域(shrink)
- 收缩的区域,根据公式向外扩展 D’
推理时文字边界的获取
文字形成过程包括三个步骤:
(1)首先对概率图/近似二值映射进行固定阈值(0.2)二值化,得到真实二值图;
(2) 连接区域(缩小文本区域 shrink );
(3) 再对区域放缩回去,D为曲线向外面扩的像素长度
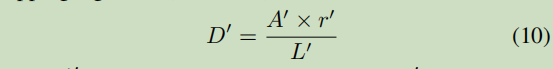
其中:
A‘是收缩多边形的面积;L‘是收缩多边形的周长;根据经验,r’ 设置为1.5(经验值)
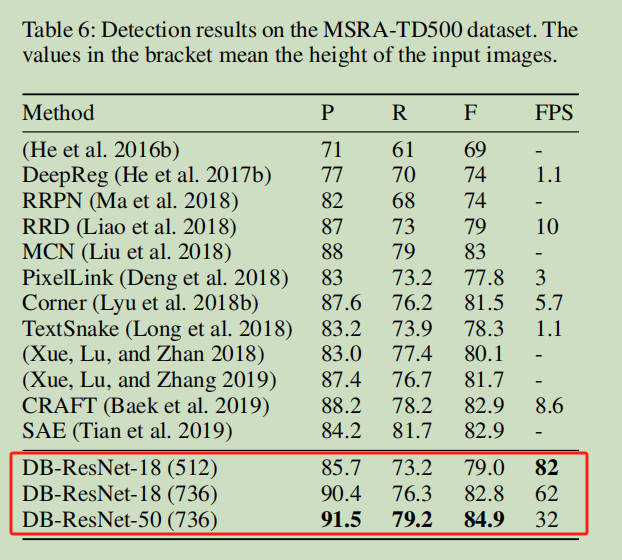
算法效果
在 MSRA-TD500 的 多语言检测结果(主要是中文)
实际检测效果 (原图画框,thresh图,probability map)

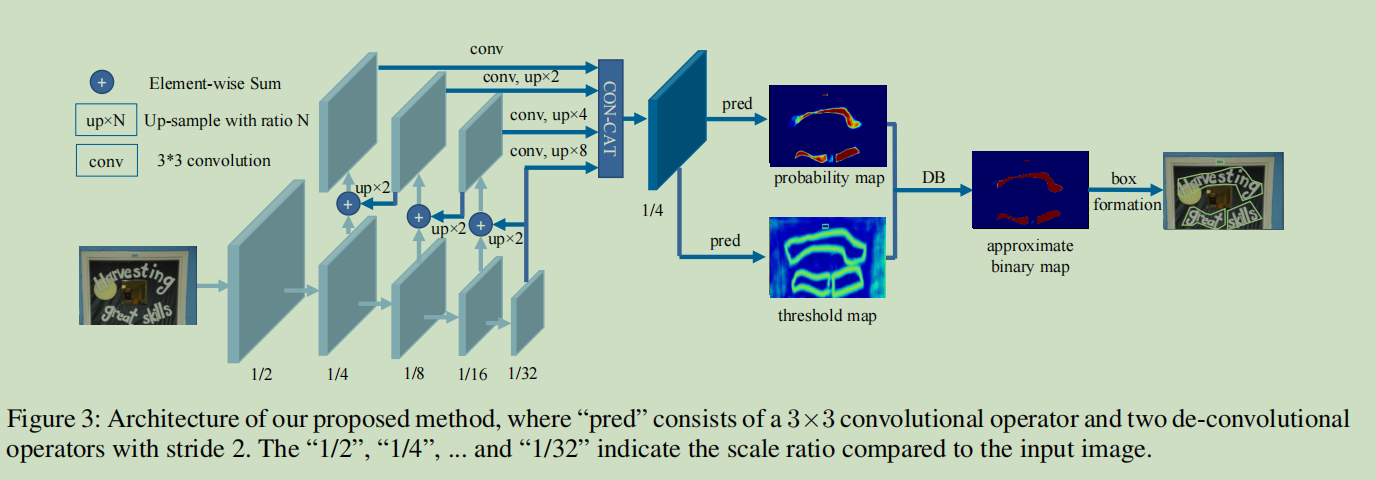
具体方法
首先,图片输入到 特征金字塔的骨干网络( feature-pyramid backbone.)
第二步, 不同分辨率的 feature-pyramid backbone.,向上采样到同一尺度并级联(cascaded),合成产生总特征图F
然后,总的特征图 F ,用作预测文本框分割概率图(P,probability map) 以及 阈值图(T,threshold map )
最后,用P和F计算出近似的(approximate)二进制映射(binary map)。
在训练期间,对概率图、阈值映射和近似二值映射进行监督训练(制作多个label)
推理时,通过一个box计算公式(box formulation)模块,可以很容易地从近似的二进制映射或概率映射中得到边界框
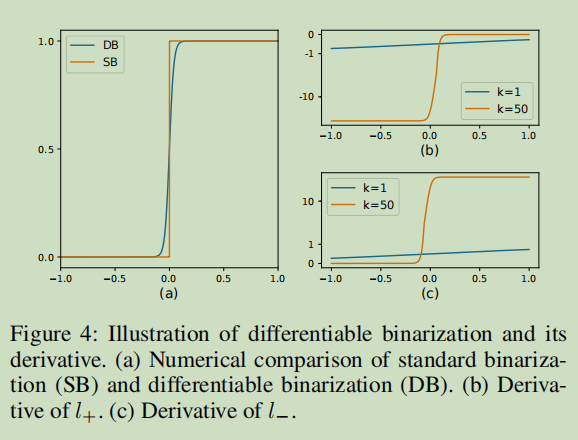
可微分二值化模块(可学习的参数)
原始的二值化过程
是对概率图(probability map)的输出结果,逐像素进行处理的,指定阈值t,像素值大于t,则为输出区域
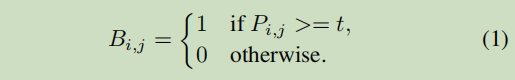
自适应可微分的二值化过程 (Differentiable binarization)
输出结果就是估计的二值化图(binary map)
T是从网络中学习到的自适应阈值图;
k表示放大因子,根据经验设置为50
i,j 表示对应位置的map上的数据点
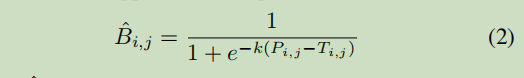
实质是根据sigmoid函数改的,可微可倒,且求导为自己

* 如何生成 Label ( 用于监督训练)
红色的线:标注的文本框区域
蓝色的线:收缩算法处理区域 ,见probability map
绿色的线:膨胀区域
threshmap 就是按D 收缩和膨胀后之间的区域
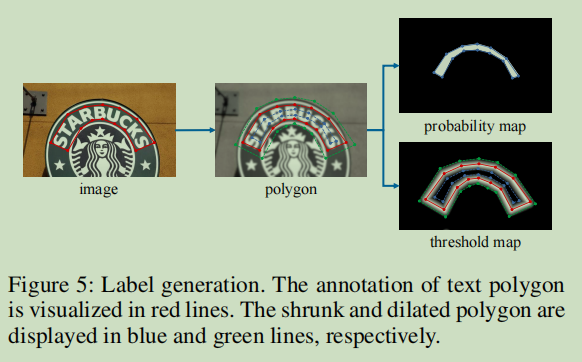
收缩算法求thresh map (Vatti裁剪算法)
D 表示图片收缩的距离
L 表示标注的多边形的周长(perimeter)
A 表示标注区域的面积
r 表示收缩率(shrink ratio),一般经验性的(empirically)设为 0.4
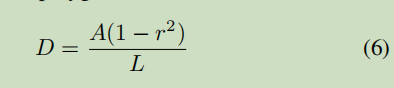
通过类似的过程,我们可以为阈值映射(threshold map)生成标签。首先将文本多边形G以相同的偏移D到Gd。我们将Gs和Gd之间的间隙作为文本区域的边界,其中阈值映射可以通过计算到G中最近段的距离来生成的标签。
优化函数相关
总的损失函数
Ls是收缩之后文本实例的loss
Lb是二值化阈值map的loss
Lt是threshold map的loss
α ,β 分别表示权重,设为经验值 1和10

其中 Ls和 Lb 使用都使用二值化交叉熵 (binary cross-entropy (BCE) loss)
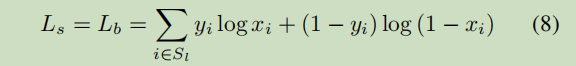
Lt 的具体表达式为:
在膨胀后(dilated)文字多边形区域Gd内的预测和标签之间的距离
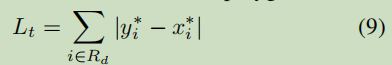
Ls和 Lb 梯度与反向传播分析
对于正样本 ,训练时,如果与lable接近,梯度很大,导数小。
对于负样本,训练时,如果与lable接近,否则倒数很小