1,先下载模型Baichuan-7B
找到个网站可以快速的下载模型。
https://aliendao.cn/models/baichuan-inc/Baichuan-7B
pytorch_model.bin 13.0 GB
Baichuan-7B 是由百川智能开发的一个开源可商用的大规模预训练语言模型。基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。在标准的中文和英文 benchmark(C-Eval/MMLU)上均取得同尺寸最好的效果。
其他信息介绍:
https://gitee.com/mirrors/baichuan-7B
2,先下载项目,编译下,然后下载模型
在docker 中折腾吧,使用python的镜像就可以。
因为需要进行转换。
git clone https://ghproxy.com/https://github.com/ggerganov/llama.cpp
docker run -itd --rm --name python -v `pwd`/llama.cpp:/data python:slim-bullseye
docker exec -it python bash
# 默认注释了源码镜像以提高 apt update 速度 https://developer.aliyun.com/mirror/
echo "deb https://mirrors.aliyun.com/debian/ bullseye main contrib non-free" > /etc/apt/sources.list
echo "deb https://mirrors.aliyun.com/debian/ bullseye-updates main contrib non-free" >> /etc/apt/sources.list
echo "deb https://mirrors.aliyun.com/debian/ bullseye-backports main contrib non-free" >> /etc/apt/sources.list
echo "deb https://mirrors.aliyun.com/debian-security bullseye-security main contrib non-free" >> /etc/apt/sources.list
# 执行工具安装
apt-get update && apt-get -y install build-essential
cd /data
# 设置pyton3 源
pip3 config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip3 config set install.trusted-host mirrors.aliyun.com
python3 -m pip install -r requirements.txt
# 直接就可以编译成功了
make -j
3,重要步骤!进行两次转换,生成ggml-model-q4_0.bin文件
LLaMA 模型为 16 位浮点精度,其 7B 版本有 70 亿参数,该模型完整大小为 13 GB,则用户至少须有如此多的内存和磁盘,模型才能可用,更不用提 13B 版本 24 GB 的大小,令人望而却步。但通过量化,比如将精度降至 4 位,则 7B 和 13B 版本分别压至约 4 GB 和 8 GB,消费级硬件即可满足要求,大家便能在个人电脑上体验大模型了。
这个地方作者没有写太清楚,参考别人的方法,最近作者升级了,脚本直接叫 convert.py 了
先执行转换:
python3 convert.py ./models/Baichuan-7B/
# 会生成文件:
Wrote models/Baichuan-7B/ggml-model-f16.gguf
然后生成了文件:
models/Baichuan-7B/ggml-model-f16.gguf
14G ggml-model-f16.gguf
再执行:
./quantize ./models/Baichuan-7B/ggml-model-f16.gguf ./models/Baichuan-7B/ggml-model-q4_0.gguf q4_0
3.8G ggml-model-q4_0.gguf
就生成了文件:ggml-model-q4_0.gguf 这个是经过优化的速度快。
4,运行模型cpu的 main 测试下
./main -m ./models/Baichuan-7B/ggml-model-q4_0.gguf -n 256 -p "搜狗公司介绍"
测试了两个问题,感觉上内容上和chatglm的结果差些。
问题天津景点:
天津景点有哪些-百度经验 这座城市,在古代时被称为直沽。它有两个名字:一个是海河的上游北运河口的小渔村;另一个是南运河南端的大津关码头,与南方的水路相连... [end of text]
问题北京景点:
北京景点大全. 2018北京旅游攻略 3天2夜行程安排
“不到长城非好汉”来京必须做的事情,去爬一次八达岭。看一场升旗仪式,再去看一次故宫的雪景! [end of text]
其他的没有测试。
5,在GPU 下运行 man 测试下
切换显卡镜像,这里使用的是 devel 镜像,比较大,包括 cuda的命令才行。
ncvv作为cuda的编译器,在runtime的镜像中是不提供的。
需要使用镜像:nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04 才可以。
# 还是依赖上面的步骤
docker run -itd --rm --name cuda --runtime=nvidia --gpus all -v `pwd`/llama.cpp:/data nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04
# 进入镜像
docker exec -it cuda bash
# 基础库都已经好了,直接运行即可:
make clean && make LLAMA_CUBLAS=1
如果要执行模型转换需要再安装 python3 环境:
apt-get update && apt-get -y install build-essential python3 python3-pip
python3 -m pip install -r requirements.txt
# 转换成 gguf 格式
python3 convert.py ./models/Baichuan-7B/
# 支持转换的模型:F16 Q4_0 Q4_1 Q5_0 Q5_1 Q8_0
./quantize ./models/Baichuan-7B/ggml-model-f16.gguf ./models/Baichuan-7B/ggml-model-q8_0.gguf q8_0
./quantize ./models/Baichuan-7B/ggml-model-f16.gguf ./models/Baichuan-7B/ggml-model-q5_0.gguf q5_0
./quantize ./models/Baichuan-7B/ggml-model-f16.gguf ./models/Baichuan-7B/ggml-model-f16_0.gguf f16
转换的文件大小:
-rw-r--r-- 1 root root 13G 9月 10 22:18 ggml-model-f16_0.gguf
-rw-r--r-- 1 root root 14G 9月 10 22:12 ggml-model-f16.gguf
-rw-r--r-- 1 root root 3.8G 9月 10 19:33 ggml-model-q4_0.gguf
-rw-r--r-- 1 root root 4.6G 9月 10 22:20 ggml-model-q5_0.gguf
-rw-r--r-- 1 root root 7.0G 9月 10 22:17 ggml-model-q8_0.gguf
测试运行main
time ./main -m ./models/Baichuan-7B/ggml-model-q4_0.gguf -n 256 -p "北京景点"
time ./main -m ./models/Baichuan-7B/ggml-model-q5_0.gguf -n 256 -p "北京景点"
time ./main -m ./models/Baichuan-7B/ggml-model-q8_0.gguf -n 256 -p "北京景点"
time ./main -m ./models/Baichuan-7B/ggml-model-f16.gguf -n 256 -p "北京景点"
q4_0 使用GPU 内存才 148 MB
real 1m7.764s
user 3m11.404s
sys 0m3.073s
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 22629 C ./main 148MiB |
+---------------------------------------------------------------------------------------+
q5_0 使用GPU 内存也是 148 MB
real 1m20.153s
user 3m48.040s
sys 0m3.741s
q8_0 使用GPU 内存也是 148 MB
real 1m59.107s
user 5m36.037s
sys 0m4.938s
f16 使用GPU 内存也是 148 MB
real 2m54.644s
user 7m13.311s
sys 0m9.271s
每次返回的结果都是不太一样的。尤其是感觉和问题差异比较大:
比如这个结果:
北京景点预约 1.0.4版本更新,增加了“门票预订”功能。用户在手机淘宝搜索 “北京景点网”,进入主页面后点选景区下方的“免费在线购票… [end of text]
挺奇怪的,GPU的内存消耗并不是很大。
但是发现 int4 是比较顺畅的,但是到了q8 和 f16 就不是很快了。稍微有点卡了。
6,总结
有一点感觉上这个问题必须要具体点,否则百川给出的结果会不一样。
这个和chatglm 还是有差距的:
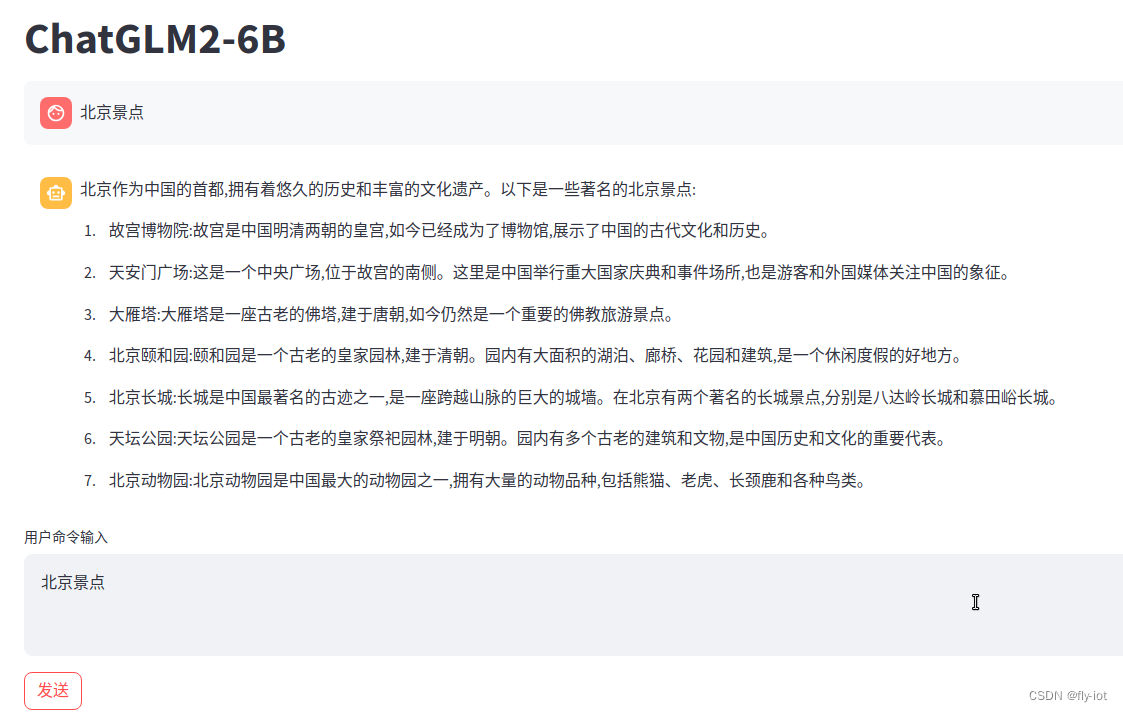
同样的问题,chatglm2 结果比较稳定。错误也比较明显,居然返回大雁塔了??!!
baichuan 好的一点是新模型发布了。baichuan2 估计会解决这个问题。
同时baichuan 可以支持使用 llam.cpp 上面运行。
同时还有 13B的模型可以使用,所以要好好的研究下。