【串口数据解析】C语言与Python的两种解析方案对比(结构体struct与class类存储数据,结构体嵌套的Python表示方法,长字节数据的存储与解析:bytes类型转flout)
文章目录
在这里 以一种串口数据协议为例子 分别用C语言和Python做解析 并且不使用第三方库来完成
C语言用结构体struct来完成 而Python用class类来完成
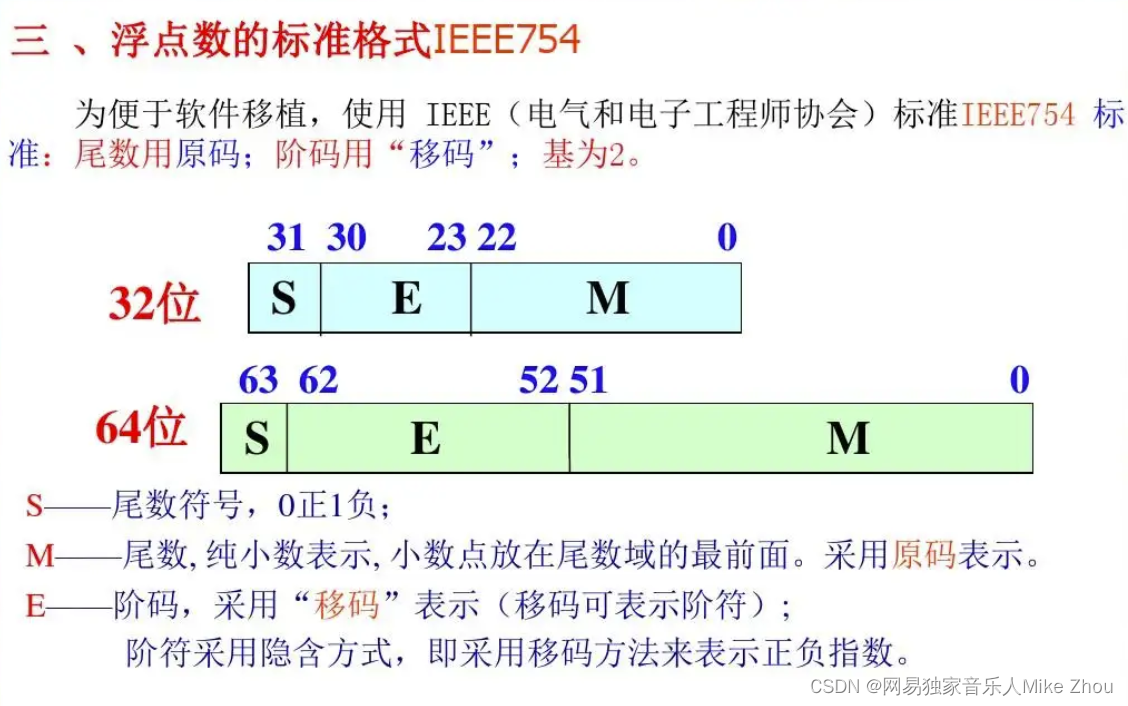
数据协议

格式说明
帧起始: 两个字节,固定值0x23 0x55。
数据域长度: 两个字节,表示数据域的长度。
设备地址: 两个字节,固定值 0x52 0x07。
数据域: 功能码和数据。其中功能码COM一个字节,数据DATA可有可无,具体看功能码定义。
帧校验: 两个字节,按位累加,从帧头开始到数据结束。
帧结束: 两个字节,固定值0x0D 0x0A。
数据域为小端格式,其他为大端格式。
结构体定义
typedef struct
{
uint8_t START[2]; 起始位
uint8_t BCNT[2]; 数据长度,表示从ADDR字节的后一字节开始,到校验码的前一字节为止,数据的长度;也是命令位+数据位的长度。即BCNT=len(COM+DATA[])
uint8_t ADDR[2]; 地址位
uint8_t COM; 命令字节
uint8_t DATA[25]; 数据字节
uint8_t CHK[2]; 校验码 表示校验码前所有字节之和。
CHK=START0+START1+BCNT0+BCNT1+ADDR0+ADDR1+COM+DATA[]
uint8_t STOP[2]; 停止位
}GUI_Struct;
如接收的数据为:
23 55 00 04 52 07 01 AB 12 45 XX 0D 0A
起始位23 55
数据长度4
ADDR为52 07
命令为01
数据字节AB 12 45
校验码XX
停止位 0D 0A
数据格式
一共有四种数据格式
字符串则由单个字符逐一拼接而成
u uint8_t 占1字节 8位无符号整型
f4 float 占4字节 单精度浮点
d8 double 占8字节 双精度浮点
c char 占1字节 单一字符 ASCII码
其中,f4和d8是小端格式,在发送数据时,先发低位再发高位。
比如:
浮点数里面 如 0x40 80 00 00表示4.0f,其中 00是低位 40是高位:
以小端格式发送,则依次发送0x00 0x00 0x80 0x40。
在采用C语言对数据进行处理时,建议遇到浮点数接收时,直接采用memcpy()函数从地址上进行复制,复制字节数为4或8(双精度浮点);同样的,在发送浮点数数据时,也采用memcpy()函数将变量值复制到要发送的DATA数组中,避免大小端格式出错。
C语言数据解析
/*
BCNT 数据长度 表示从ADDR字节的后一字节开始 到校验码的前一字节为止 数据的长度 也是命令位+数据位的长度
BCNT=len(COM+DATA[])
CHK 检验码 表示校验码前所有字节之和
CHK=START0+START1+BCNT0+BCNT1+ADDR0+ADDR1+COM+DATA[]
*/
typedef struct
{
uint8_t START[2];
uint8_t BCNT[2];
uint8_t ADDR[2];
uint8_t COM;
uint8_t DATA[50];
uint8_t CHK[2];
uint8_t STOP[2];
bool Flag; //校验数据是否正确的标志 解析数据时正确则有效 发送数据时无关
}GUI_Struct;
//数据字节为小端格式 其他为大端格式
数组转结构体
解析思路:
判断起始位
获取数据长度
计算校验位的序号
判断停止位
获取校验码
计算校验码是否正确(前面的项依次相加 由于校验码定义的是uint16 所以不用担心越界 越界以后直接从0开始计数)
获取地址位
获取命令字
获取数据位
GUI_Struct Trans_GUI_to_Struct(uint8_t * buf)
{
GUI_Struct GUI_Stu;
GUI_Stu.Flag=false;
uint8_t i=0;
uint8_t CHK_Num=0;
uint16_t Data_Len=0;
uint16_t Check_Sum=0;
GUI_Stu.START[0]=buf[0];
GUI_Stu.START[1]=buf[1];
if(GUI_Stu.START[0]!=GUI_START0 || GUI_Stu.START[1]!=GUI_START1)
{
return GUI_Stu;
}
GUI_Stu.BCNT[0]=buf[2];
GUI_Stu.BCNT[1]=buf[3];
Data_Len=(GUI_Stu.BCNT[0]<<8)|(GUI_Stu.BCNT[1]);
if(!Data_Len)
{
return GUI_Stu;
}
CHK_Num=Data_Len+6;
GUI_Stu.STOP[0]=buf[CHK_Num+2];
GUI_Stu.STOP[1]=buf[CHK_Num+3];
if(GUI_Stu.STOP[0]!=GUI_STOP0 || GUI_Stu.STOP[1]!=GUI_STOP1)
{
return GUI_Stu;
}
GUI_Stu.CHK[0]=buf[CHK_Num];
GUI_Stu.CHK[1]=buf[CHK_Num+1];
for(i=0;i<CHK_Num;i++)
{
Check_Sum=Check_Sum+buf[i];
}
if((Check_Sum>>8)!=GUI_Stu.CHK[0] || (Check_Sum&0x00FF)!=GUI_Stu.CHK[1])
{
return GUI_Stu;
}
GUI_Stu.ADDR[0]=buf[4];
GUI_Stu.ADDR[1]=buf[5];
GUI_Stu.COM=buf[6];
for(i=0;i<Data_Len-1;i++)
{
GUI_Stu.DATA[i]=buf[i+7];
}
GUI_Stu.Flag=true;
return GUI_Stu;
}
结构体转数组
也就是反过来:
传入起始位
传入数据长度
传入地址位
传入数据长度位 计算数据长度
计算校验码序号
传入命令字
传入数据位
计算校验码
传入校验位和停止位
uint8_t Trans_GUI_to_Buf(GUI_Struct GUI_Stu,uint8_t * buf)
{
uint8_t i=0;
uint8_t CHK_Num=0;
uint16_t Data_Len=0;
uint16_t Check_Sum=0;
if(GUI_Stu.START[0]!=GUI_START0 || GUI_Stu.START[1]!=GUI_START1)
{
return 0;
}
if(GUI_Stu.STOP[0]!=GUI_STOP0 || GUI_Stu.STOP[1]!=GUI_STOP1)
{
return 0;
}
buf[0]=GUI_Stu.START[0];
buf[1]=GUI_Stu.START[1];
buf[2]=GUI_Stu.BCNT[0];
buf[3]=GUI_Stu.BCNT[1];
buf[4]=GUI_Stu.ADDR[0];
buf[5]=GUI_Stu.ADDR[1];
Data_Len=(GUI_Stu.BCNT[0]<<8)|(GUI_Stu.BCNT[1]);
if(!Data_Len)
{
return 0;
}
CHK_Num=Data_Len+6;
buf[6]=GUI_Stu.COM;
for(i=0;i<Data_Len-1;i++)
{
buf[i+7]=GUI_Stu.DATA[i];
}
for(i=0;i<CHK_Num;i++)
{
Check_Sum=Check_Sum+buf[i];
}
buf[CHK_Num]=(Check_Sum&0xFF00)>>8;
buf[CHK_Num+1]=Check_Sum&0x00FF;
buf[CHK_Num+2]=GUI_Stu.STOP[0];
buf[CHK_Num+3]=GUI_Stu.STOP[1];
return (CHK_Num+4);
}
C语言测试
int main(void)
{
uint8_t buf[61]={
0x23,0x55,0x00,0x29,0x52,0x04,0x42,0x03,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x01,0x3C,0x0D,0x0A};
GUI_Struct A;
A=Trans_GUI_to_Struct(buf);
printf("%d %s\n",A.COM,A.START);
printf("%d\n",A.Flag);
GUI_Struct B = A;
Trans_GUI_to_Buf(B,buf);
for(int i=0;i<61;i++)
{
printf(" 0x%02x",buf[i]);
}
printf("\n");
B=Trans_GUI_to_Struct(buf);
printf("%d\n",B.Flag);
}
运行效果:
66 #U
1
0x23 0x55 0x00 0x29 0x52 0x04 0x42 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x01 0x3c 0x0d 0x0a 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
1
Python数据解析
Python传入的数组为bytes类型(其实也相当于一种列表形式的整形)
取值方式为buf[i] 取值的类型虽然为bytes类型 但可以用整型的计算方式
这里用class类来存放数据
class GUI_Struct:
def __init__(self):
self.START = bytes([0,0])
self.BCNT = bytes([0,0])
self.ADDR = bytes([0,0])
self.COM = bytes([0])
self.DATA = bytes([])
self.CHK = bytes([0,0])
self.STOP = bytes([0,0])
self.Bytes_Buf = bytes([])
self.__Trans_to_Struct_Flag = False
self.__Trans_to_Buf_Flag = False
为了防止传入的数据出错 加一个初始化函数:
def Init_All(self):
self.START= bytes(list(self.START))
self.BCNT= bytes(list(self.BCNT))
self.ADDR= bytes(list(self.ADDR))
self.COM= bytes(list(self.COM))
self.DATA= bytes(list(self.DATA))
self.CHK= bytes(list(self.CHK))
self.STOP= bytes(list(self.STOP))
self.Bytes_Buf= bytes(list(self.Bytes_Buf))
并且增加了两个私有函数 获取flag
def Get_Trans_to_Struct_Flag(self):
return self.__Trans_to_Struct_Flag
def Get_Trans_to_Buf_Flag(self):
return self.__Trans_to_Buf_Flag
数组转类
与C语言的方法相同
只不过这里校验码需要避坑
由于Python里面没有uint16这种整形的定义 所以需要与上0x0000FFFF
def Trans_to_Struct(self):
buf=bytes(list(self.Bytes_Buf))
self.__Trans_to_Struct_Flag=False
i=0
CHK_Num=0
Data_Len=0
Check_Sum=0
Data_List = []
self.START=bytes([buf[0],buf[1]])
if self.START!=GUI_START:
return 0
self.BCNT=bytes([buf[2],buf[3]])
Data_Len=(self.BCNT[0]<<8)|(self.BCNT[1])
if Data_Len==0:
return 0
CHK_Num=Data_Len+6
self.STOP=bytes([buf[CHK_Num+2],buf[CHK_Num+3]])
if self.STOP!=GUI_STOP:
return 0
self.CHK=bytes([buf[CHK_Num],buf[CHK_Num+1]])
for i in range(CHK_Num):
Check_Sum=Check_Sum+buf[i]
Check_Sum = Check_Sum&0x0000FFFF
if Check_Sum!=(self.CHK[0]<<8)|self.CHK[1]:
return 0
self.ADDR=bytes([buf[4],buf[5]])
self.COM=bytes([buf[6]])
for i in range(7,Data_Len+6):
Data_List.append(buf[i])
self.DATA=bytes(Data_List)
self.__Trans_to_Struct_Flag=True
return 1
类转数组
同样 这里的校验位也是需要避坑的地方
并且这里用append函数来依次添加元素 所以得按位的顺序来
def Trans_to_Buf(self):
self.START= bytes(list(self.START))
self.BCNT= bytes(list(self.BCNT))
self.ADDR= bytes(list(self.ADDR))
self.COM= bytes(list(self.COM))
self.DATA= bytes(list(self.DATA))
self.CHK= bytes(list(self.CHK))
self.STOP= bytes(list(self.STOP))
self.__Trans_to_Buf_Flag = False
buf=[]
i=0
CHK_Num=0
Data_Len=0
Check_Sum=0
if self.START!=GUI_START:
return 0
if self.STOP!=GUI_STOP:
return 0
buf.append(self.START[0])
buf.append(self.START[1])
buf.append(self.BCNT[0])
buf.append(self.BCNT[1])
buf.append(self.ADDR[0])
buf.append(self.ADDR[1])
Data_Len=(self.BCNT[0]<<8)|(self.BCNT[1])
if Data_Len == 0:
return 0
CHK_Num=Data_Len+6
buf.append(self.COM[0])
for i in self.DATA:
buf.append(i)
for i in range(CHK_Num):
Check_Sum=Check_Sum+buf[i]
buf.append(((Check_Sum&0x0000FF00)>>8)&0x000000FF)
buf.append(Check_Sum&0x000000FF)
buf.append(self.STOP[0])
buf.append(self.STOP[1])
self.Bytes_Buf=bytes(buf)
self.__Trans_to_Buf_Flag = True
return 1
Python测试
A=GUI_Struct()
buf=b'\x23\x55\x00\x29\x52\x04\x42\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01\x3C\x0D\x0A'
A.Bytes_Buf=buf
print(A.Trans_to_Struct())
print(A.COM,A.DATA)
print(A.Get_Trans_to_Struct_Flag())
B=A
print(B.Trans_to_Buf())
print(B.Bytes_Buf)
print(buf)
print(B.Get_Trans_to_Buf_Flag())
print(B.Trans_to_Struct())
print(A.Trans_to_Buf())
运行效果:
1
b'B' b'\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
True
1
b'#U\x00)R\x04B\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01<\r\n'
b'#U\x00)R\x04B\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x01<\r\n'
True
1
1
结构体嵌套的Python表示方法
如下C语言结构体:
typedef struct
{
unsigned char obj_src;
unsigned char obj_res0;
unsigned char obj_res1;
unsigned char objCount;
struct
{
unsigned short range;/* 0.01 m*/
short velocity; /* 0.01 km/h*/
} objects[MAX_OBJECTS];
/**/
float vel_self;
}miniradar_output_t;
该结构体中嵌套了一个结构体 子结构体还是一个数组形式 最大个数为MAX_OBJECTS 姑且定义为8
对于Python而言 数组的长度是可以添加的 并且可以把子结构体定义成一个二级结构体
那么 len(self.range)就表示objects中的元素个数
class RF_Struct:
def __init__(self):
self.obj_src = bytes([0])
self.obj_res0 = bytes([0])
self.obj_res1 = bytes([0])
self.objCount = bytes([0])
self.range=[]
self.velocity=[]
self.vel_self=bytes([0,0,0,0])
self.data_buf=bytes([])
同样 初始化属性:
def Init_All(self):
self.obj_src = bytes(list(self.obj_src))
self.obj_res0 = bytes(list(self.obj_res0))
self.obj_res1 = bytes(list(self.obj_res1))
self.objCount = bytes(list(self.objCount))
self.range=list(self.range)
for i in range(len(self.range)):
self.range[i]=bytes(list(i))
self.velocity=list(self.velocity)
for i in range(len(self.velocity)):
self.velocity[i]=bytes(list(i))
self.vel_self=bytes(list(self.vel_self))
self.data_buf=bytes(list(self.data_buf))
数组转类
这里就比较麻烦了
不仅有uint16类型 还有int16类型和flout类型
def Trans_to_Struct(self):
i=0
r_list=[]
v_list=[]
self.__Trans_to_Struct_Flag = False
buf = self.data_buf
d_size = int((len(buf)-8)%4)
if d_size:
return 0
size = int((len(buf)-8)/4)
self.obj_src=bytes([buf[0]])[0]
self.obj_res0=bytes([buf[1]])[0]
self.obj_res1=bytes([buf[2]])[0]
self.objCount=bytes([buf[3]])[0]
for i in range(size):
r_list.append(bytes([buf[4+4*i],buf[4+4*i+1]]))
v_list.append(bytes([buf[4+4*i+2],buf[4+4*i+3]]))
for i in range(len(r_list)):
r_list[i]=(r_list[i][0]<<8)|r_list[i][1]
v_list[i]=((v_list[i][0]<<8)|v_list[i][1])
if v_list[i]>>15:
v_list[i]=-v_list[i]&0x8000
else:
v_list[i]=v_list[i]&0x8000
self.range=r_list.copy()
self.velocity=v_list.copy()
self.vel_self=bytes([buf[4+4*size],buf[4+4*size+1],buf[4+4*size+2],buf[4+4*size+3]])
ba = bytearray()
ba.append(self.vel_self[3])
ba.append(self.vel_self[2])
ba.append(self.vel_self[1])
ba.append(self.vel_self[0])
self.vel_self=struct.unpack("!f",ba)[0]
self.__Trans_to_Struct_Flag = True
return 1
代码测试
data = b'\x03\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x80\x40'
R = RF_Struct()
R.data_buf=data
R.Trans_to_Struct()
print(R.Get_Trans_to_Struct_Flag())
运行结果:
True
长字节数据存储与解析
长字节数据包括16位 32位 64位整型 float double类型 以及压缩字符串等等
普通的字符串只是多个8位整型数据数组 所以不算长字节数据
长字节数据涉及到大小端转换
如果是小端格式的话 那就与内存存储一致 在C语言上直接用memcpy函数即可
否则就要用到大小端转换(见附录)
如:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
另外 在C语言中 长数据转为特定类型 直接可以进行指针强转完成 比如uint32转flout:
uint32_t i=0x40800000; //注意这里是小端格式 实际内存存储的是 00 00 80 40
flout f=0.0f;
f= *(float *)&i;
printf("%f\n",f);
运行结果:
4.0
16位整形解析
uint16就直接移位 int16移位以后要判断正负 32位 64位同理
for i in range(size):
r_list.append(bytes([buf[4+4*i],buf[4+4*i+1]]))
v_list.append(bytes([buf[4+4*i+2],buf[4+4*i+3]]))
for i in range(len(r_list)):
r_list[i]=(r_list[i][0]<<8)|r_list[i][1]
v_list[i]=((v_list[i][0]<<8)|v_list[i][1])
if v_list[i]>>15:
v_list[i]=-v_list[i]&0x8000
else:
v_list[i]=v_list[i]&0x8000
并且这两个数据是一个二维数组 所以要新定义两个列表(二维列表操作见附录)
r_list=[]
v_list=[]
最后使用copy()传入赋值
self.range=r_list.copy()
self.velocity=v_list.copy()
浮点数解析

数学方法
就是纯靠计算
比较复杂 不建议使用
C语言方法
指针地址类型强转
uint32_t i=0x40800000; //注意这里是小端格式 实际内存存储的是 00 00 80 40
flout f=0.0f;
f= *(float *)&i;
printf("%f\n",f);
Python方法
用struct库来操作:
同时要用bytearray类型来操作 注意这里要转成大端格式
ba = bytearray()
ba.append(self.vel_self[3])
ba.append(self.vel_self[2])
ba.append(self.vel_self[1])
ba.append(self.vel_self[0])
self.vel_self=struct.unpack("!f",ba)[0]
压缩字符串
见附录
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
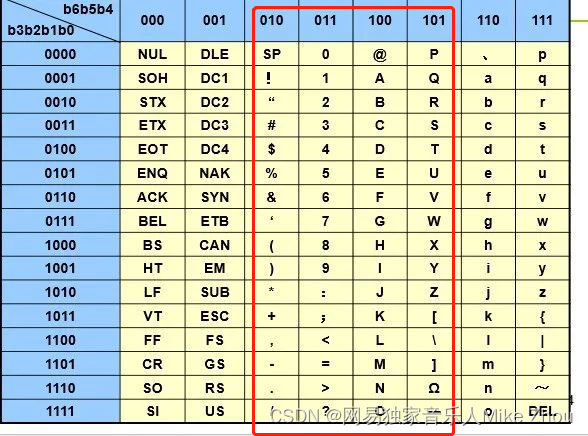
压缩Packed-ASCII字符串
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(buf,0,str_len/4*3);
for(i=0;i<str_len;i++)
{
if(str[i]==0x00)
{
str[i]=0x20;
}
}
for(i=0;i<str_len/4;i++)
{
buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);
buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);
buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);
}
return 1;
}
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(str,0,str_len);
for(i=0;i<str_len/4;i++)
{
str[4*i]=(buf[3*i]>>2)&0x3F;
str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);
str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);
str[4*i+3]=buf[3*i+2]&0x3F;
}
return 1;
}
大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={
0x00,0x00,0x80,0x40};
memcpy(&dat,buf,4);
float f=0.0f;
f=*((float*)&dat); //地址强转
printf("%f",f);
或更优解:
uint8_t buf[]={
0x00,0x00,0x80,0x40};
float f=0.0f;
memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={
0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&dat); //大小端转换
f=*((float*)&dat); //地址强转
printf("%f",f);
或:
uint8_t buf[]={
0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&f); //大小端转换
printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={
0x40,0x80,0x00,0x00};
float f=0.0f;
dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)
f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{
uint16_t *ptr=p;
uint16_t x = *ptr;
x = (x << 8) | (x >> 8);
*ptr=x;
}
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
void swap64(void * p)
{
uint64_t *ptr=p;
uint64_t x = *ptr;
x = (x << 32) | (x >> 32);
x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);
x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);
*ptr=x;
}
附录:列表的赋值类型和py打包
列表赋值
BUG复现
闲来无事写了个小程序 代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
我在程序中 做了一个16次的for循环 把列表a的每个值后面依次加上"_"和循环序号
比如循环第x次 就是把第x位加上_x 这一位变成x_x 我在输出测试中 列表a的每一次输出也是对的
循环16次后列表a应该变成[‘0_0’, ‘1_1’, ‘2_2’, ‘3_3’, ‘4_4’, ‘5_5’, ‘6_6’, ‘7_7’, ‘8_8’, ‘9_9’, ‘10_10’, ‘11_11’, ‘12_12’, ‘13_13’, ‘14_14’, ‘15_15’] 这也是对的
同时 我将每一次循环时列表a的值 写入到空列表c中 比如第x次循环 就是把更改以后的列表a的值 写入到列表c的第x位
第0次循环后 c[0]的值应该是[‘0_0’, ‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘10’, ‘11’, ‘12’, ‘13’, ‘14’, ‘15’] 这也是对的
但是在第1次循环以后 c[0]的值就一直在变 变成了c[x]的值
相当于把c_list[0]变成了c_list[1]…以此类推 最后得出的列表c的值也是每一项完全一样
我不明白这是怎么回事
我的c[0]只在第0次循环时被赋值了 但是后面它的值跟着在改变
如图:
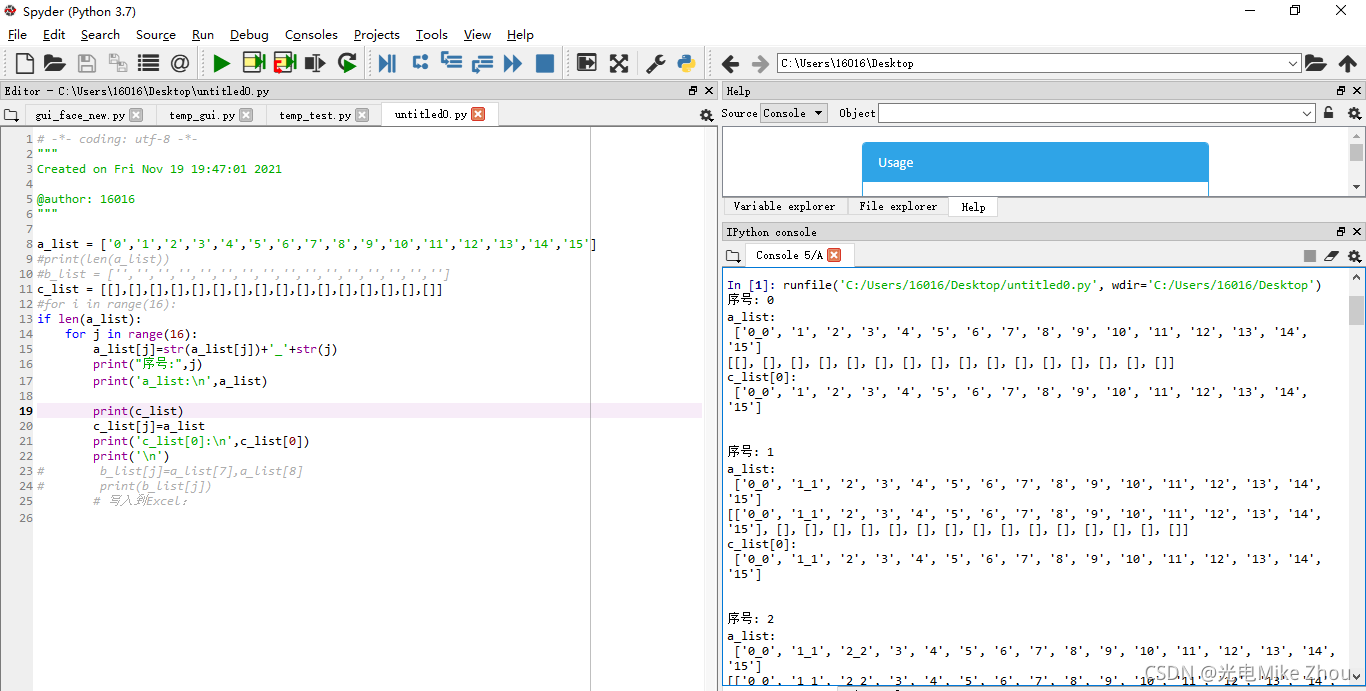
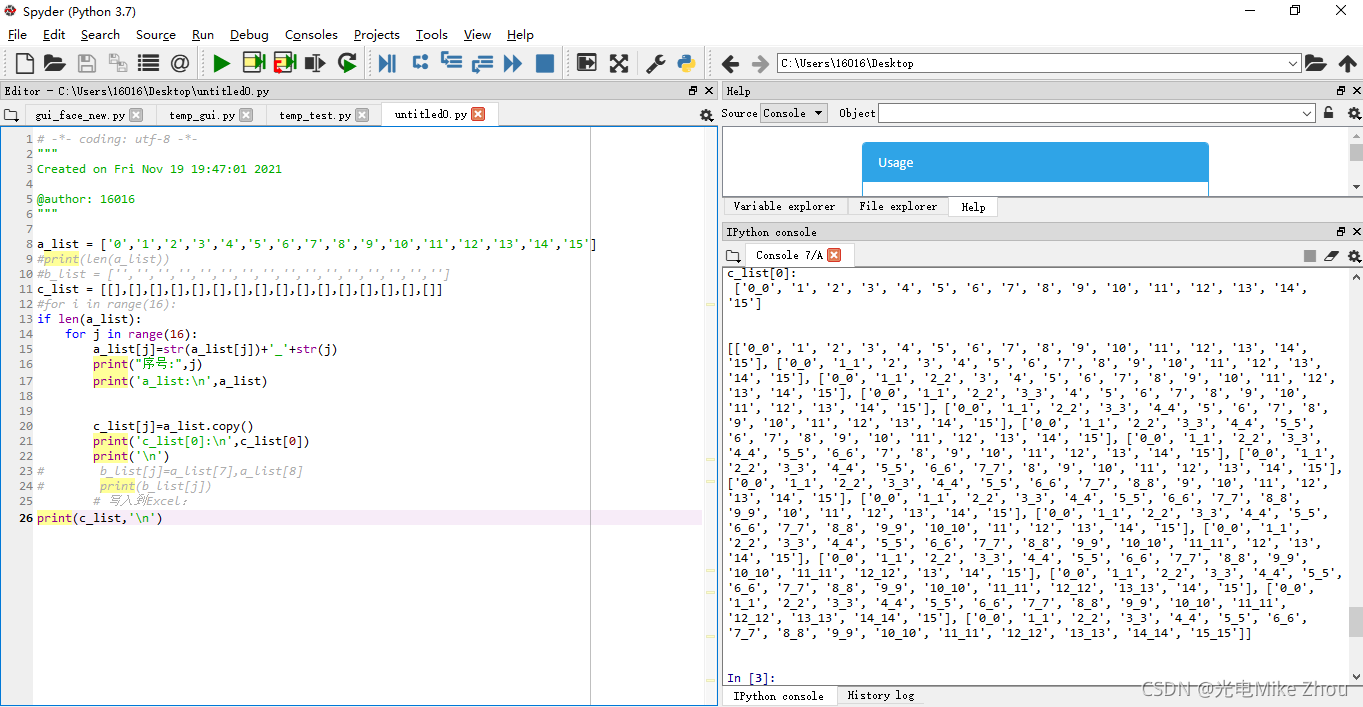
第一次老出bug 赋值以后 每次循环都改变c[0]的值 搞了半天都没搞出来
无论是用appen函数添加 还是用二维数组定义 或者增加第三个空数组来过渡 都无法解决
代码改进
后来在我华科同学的指导下 突然想到赋值可以赋的是个地址 地址里面的值一直变化 导致赋值也一直变化 于是用第二张图的循环套循环深度复制实现了
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
for i in range(16):
c_list[j].append(a_list[i])
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
print(c_list,'\n')
解决了问题
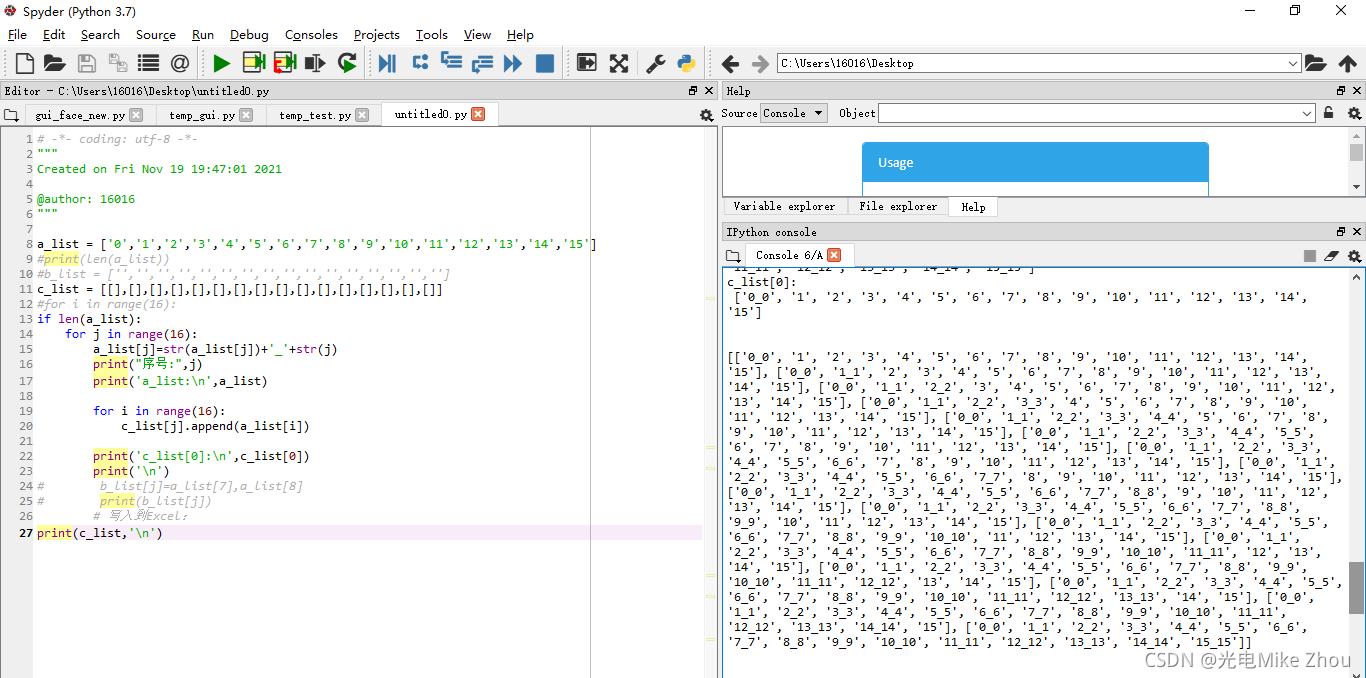
优化
第三次是请教了老师 用copy函数来赋真值
代码如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 19 19:47:01 2021
@author: 16016
"""
a_list = ['0','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15']
#print(len(a_list))
#b_list = ['','','','','','','','','','','','','','','','']
c_list = [[],[],[],[],[],[],[],[],[],[],[],[],[],[],[],[]]
#for i in range(16):
if len(a_list):
for j in range(16):
a_list[j]=str(a_list[j])+'_'+str(j)
print("序号:",j)
print('a_list:\n',a_list)
c_list[j]=a_list.copy()
print('c_list[0]:\n',c_list[0])
print('\n')
# b_list[j]=a_list[7],a_list[8]
# print(b_list[j])
# 写入到Excel:
#print(c_list,'\n')
同样能解决问题
最后得出问题 就是指针惹的祸!
a_list指向的是个地址 而不是值 a_list[i]指向的才是单个的值 copy()函数也是复制值而不是地址
如果这个用C语言来写 就直观一些了 难怪C语言是基础 光学Python不学C 遇到这样的问题就解决不了
C语言yyds Python是什么垃圾弱智语言
总结
由于Python无法单独定义一个值为指针或者独立的值 所以只能用列表来传送
只要赋值是指向一个列表整体的 那么就是指向的一个指针内存地址 解决方法只有一个 那就是将每个值深度复制赋值(子列表内的元素提取出来重新依次连接) 或者用copy函数单独赋值
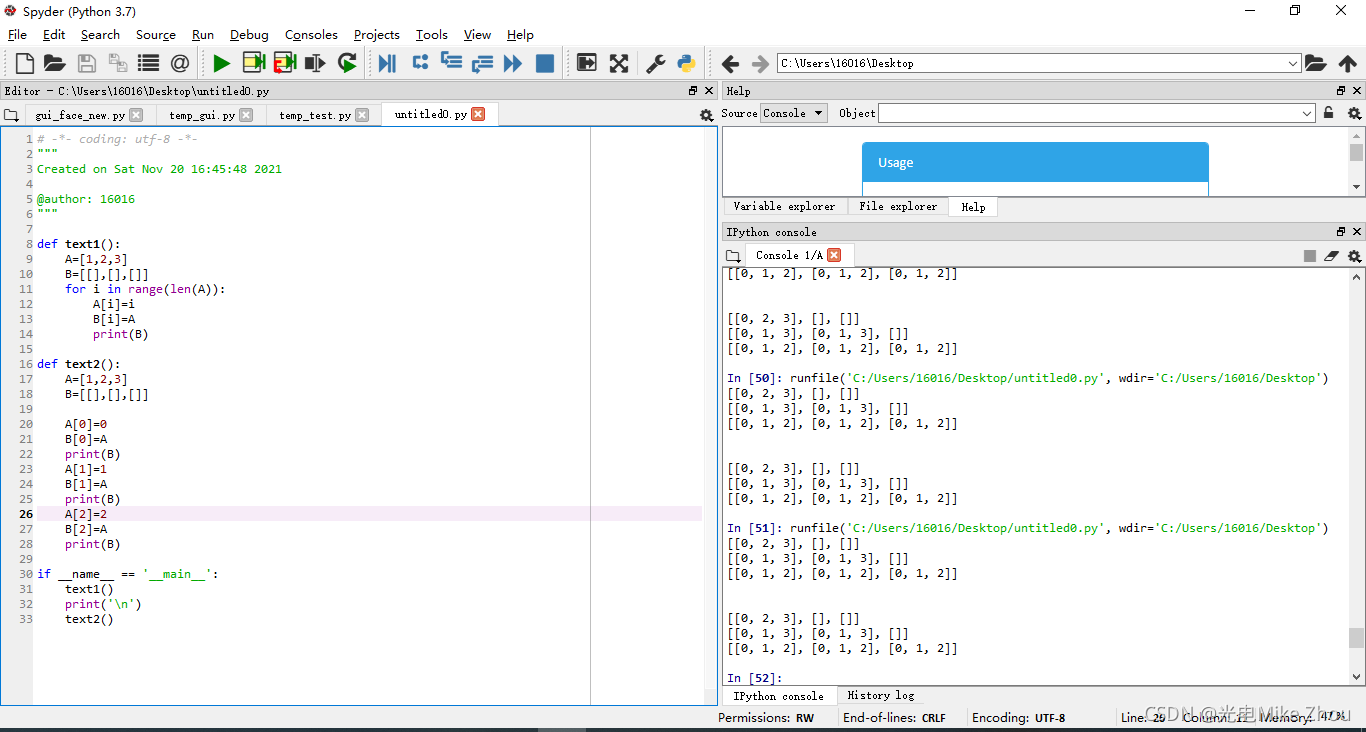
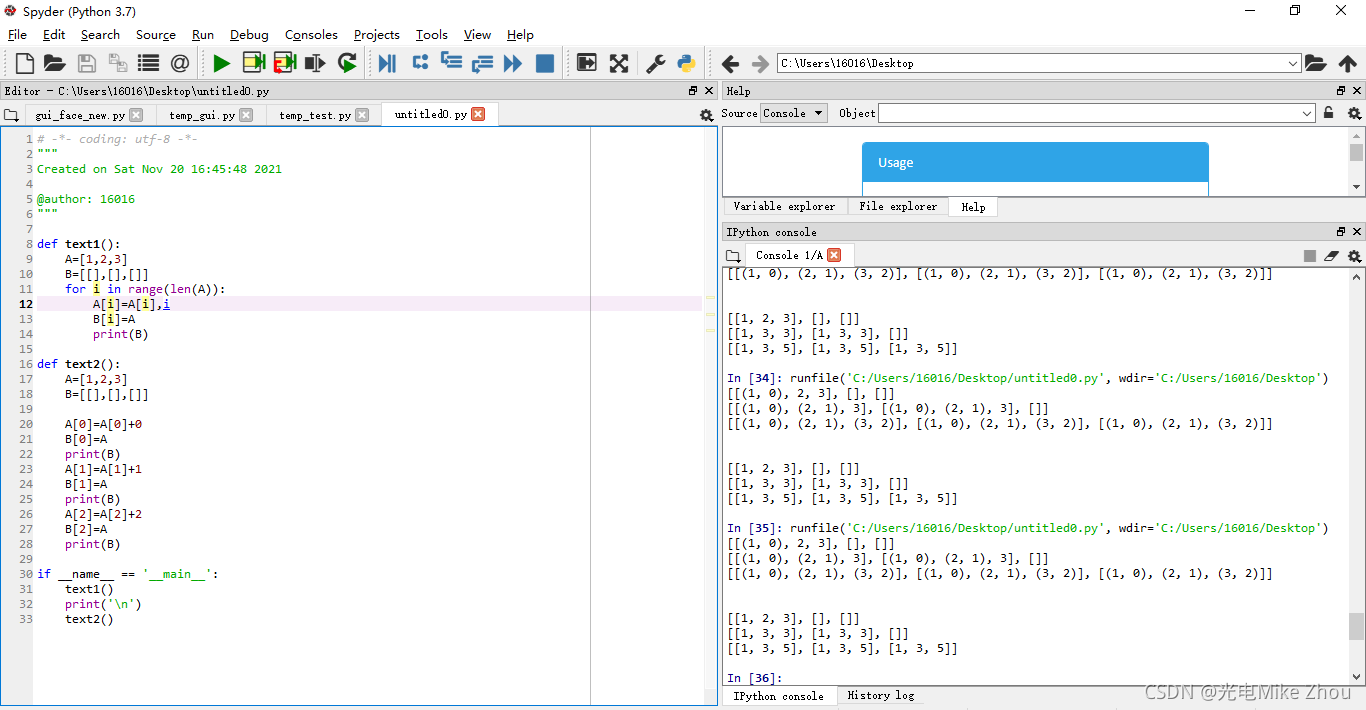
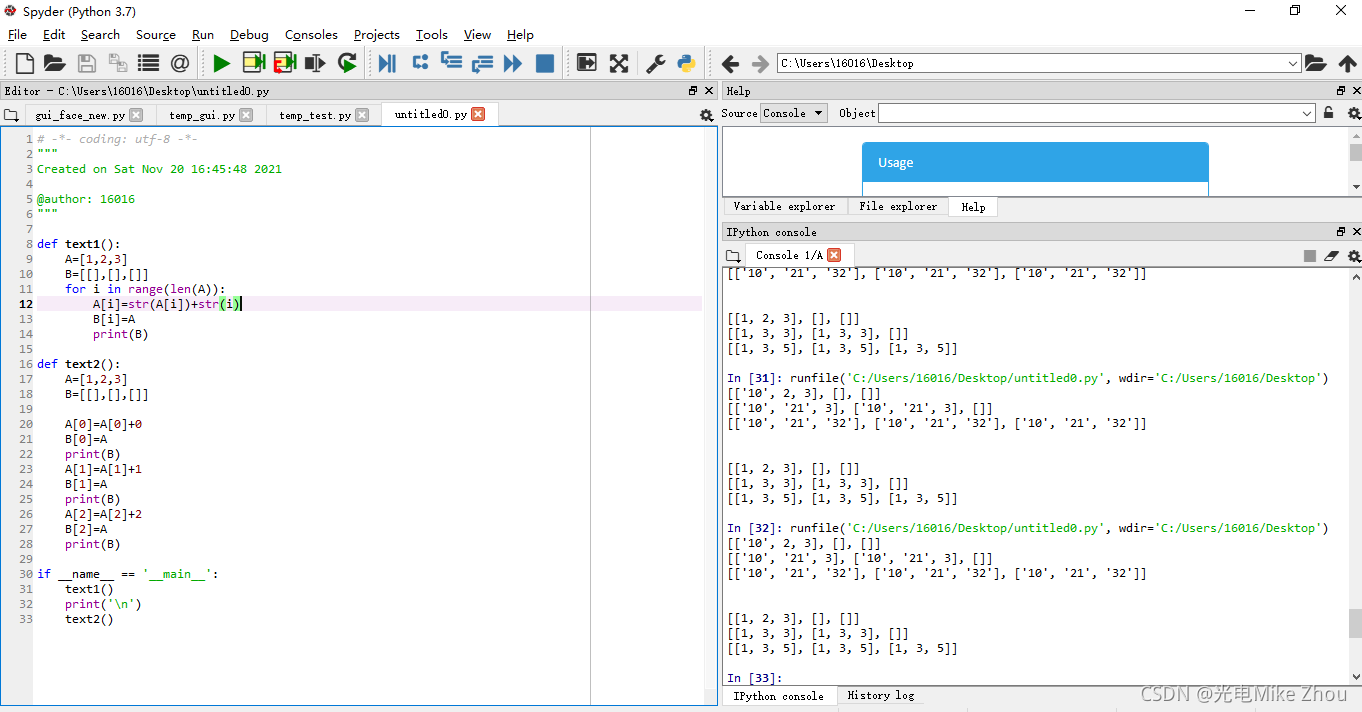
如图测试:

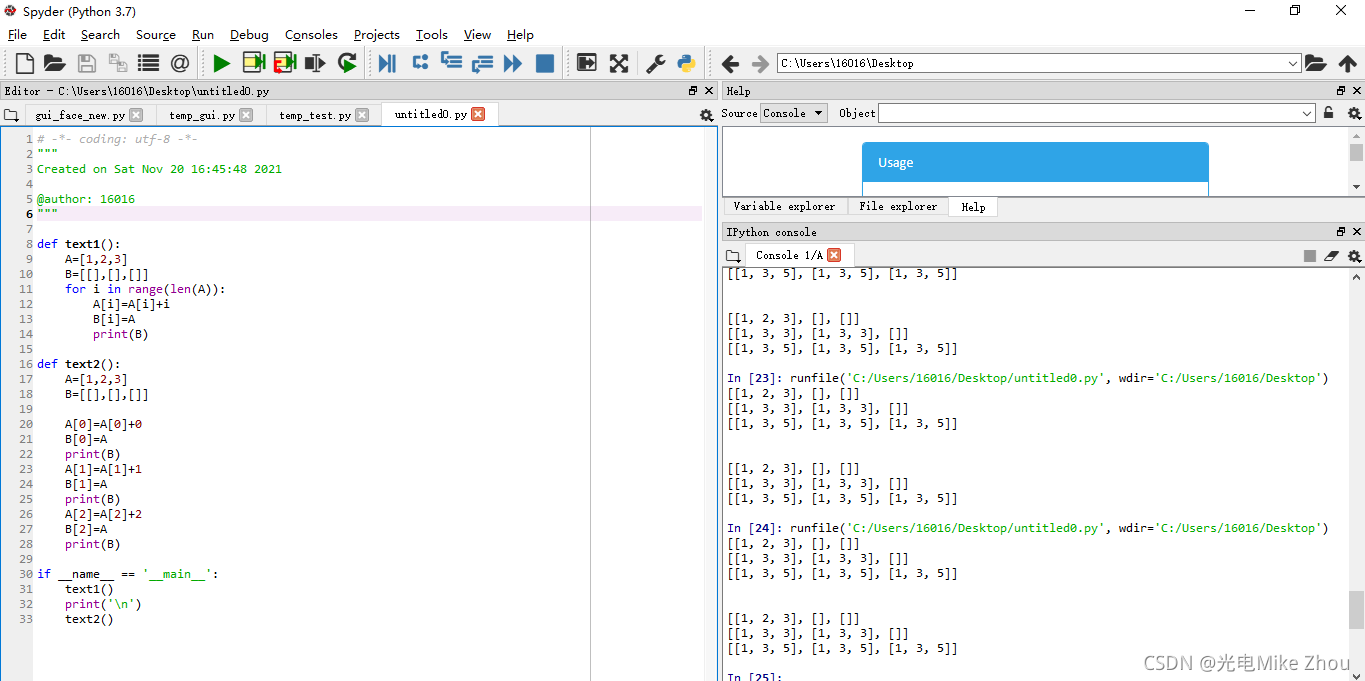
部分代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Nov 20 16:45:48 2021
@author: 16016
"""
def text1():
A=[1,2,3]
B=[[],[],[]]
for i in range(len(A)):
A[i]=A[i]+i
B[i]=A
print(B)
def text2():
A=[1,2,3]
B=[[],[],[]]
A[0]=A[0]+0
B[0]=A
print(B)
A[1]=A[1]+1
B[1]=A
print(B)
A[2]=A[2]+2
B[2]=A
print(B)
if __name__ == '__main__':
text1()
print('\n')
text2()
py打包
Pyinstaller打包exe(包括打包资源文件 绝不出错版)
依赖包及其对应的版本号
PyQt5 5.10.1
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
pyinstaller 4.5.1
pyinstaller-hooks-contrib 2021.3
Pyinstaller -F setup.py 打包exe
Pyinstaller -F -w setup.py 不带控制台的打包
Pyinstaller -F -i xx.ico setup.py 打包指定exe图标打包
打包exe参数说明:
-F:打包后只生成单个exe格式文件;
-D:默认选项,创建一个目录,包含exe文件以及大量依赖文件;
-c:默认选项,使用控制台(就是类似cmd的黑框);
-w:不使用控制台;
-p:添加搜索路径,让其找到对应的库;
-i:改变生成程序的icon图标。
如果要打包资源文件
则需要对代码中的路径进行转换处理
另外要注意的是 如果要打包资源文件 则py程序里面的路径要从./xxx/yy换成xxx/yy 并且进行路径转换
但如果不打包资源文件的话 最好路径还是用作./xxx/yy 并且不进行路径转换
def get_resource_path(relative_path):
if hasattr(sys, '_MEIPASS'):
return os.path.join(sys._MEIPASS, relative_path)
return os.path.join(os.path.abspath("."), relative_path)
而后再spec文件中的datas部分加入目录
如:
a = Analysis(['cxk.py'],
pathex=['D:\\Python Test\\cxk'],
binaries=[],
datas=[('root','root')],
hiddenimports=[],
hookspath=[],
hooksconfig={
},
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
而后直接Pyinstaller -F setup.spec即可
如果打包的文件过大则更改spec文件中的excludes 把不需要的库写进去(但是已经在环境中安装了的)就行
这些不要了的库在上一次编译时的shell里面输出
比如:

然后用pyinstaller --clean -F 某某.spec