目录
参考资料
- 学习视频: 反向传播-刘二大人
- 上一节学习笔记: 【刘二大人】pytorch深度学习实践(二):梯度下降算法详解和代码实现(梯度下降、随机梯度下降、小批量梯度下降的对比)
- pytorch官方文档: pytorch官方文档
一、反向传播流程
1.1 问题
求loss函数对于w和x的偏导。
1.2 方法
基于导数的链式法则,依次求导。
1.3 步骤
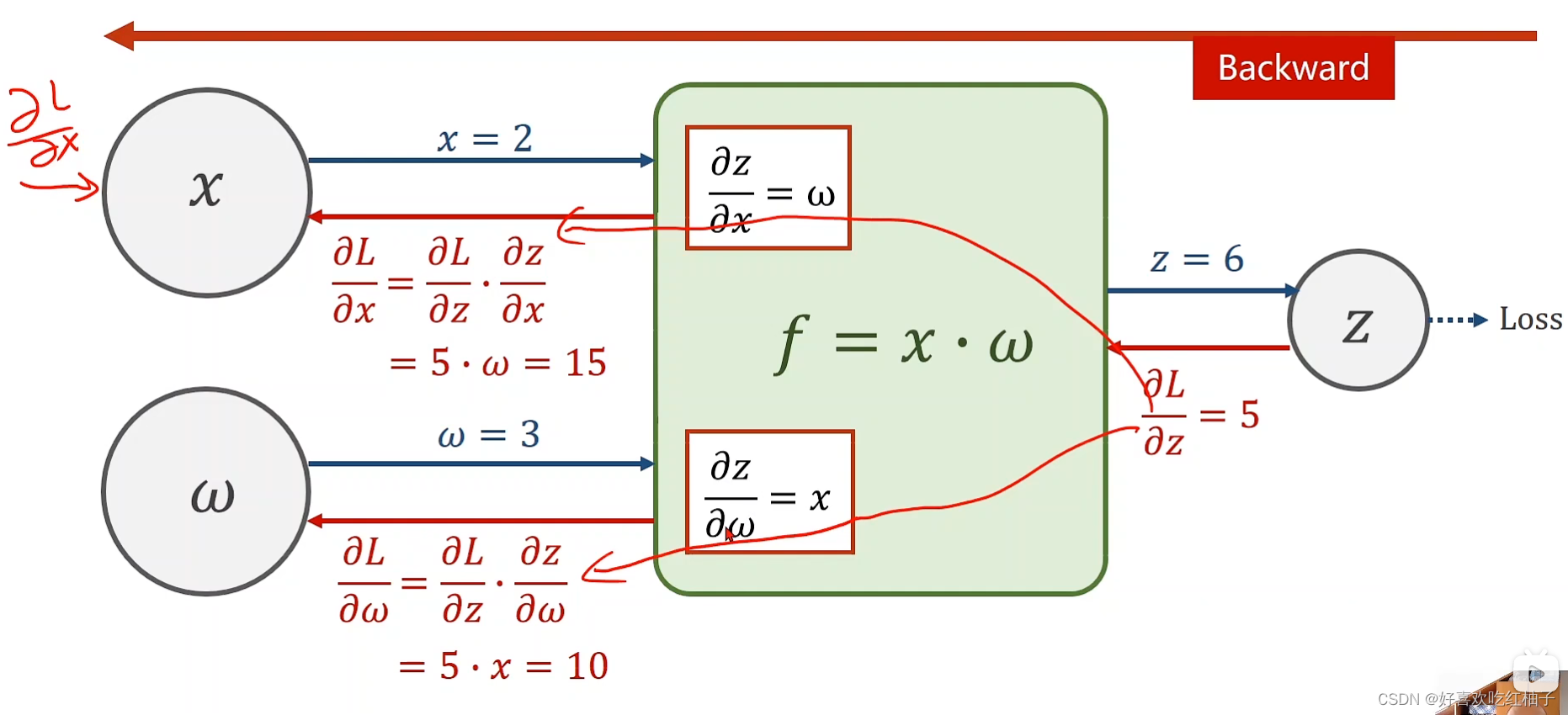
- 首先根据前向传播,可以得到 x = 2 , w = 3 , z = f ( x , w ) = x ∗ w = 6 , x =2 ,w = 3, z= f(x,w) = x*w = 6, x=2,w=3,z=f(x,w)=x∗w=6, 那么就可以求得z关于w和z的导数: ∂ z ∂ w = x = 2 , ∂ z ∂ x = w = 3 \frac{\partial z}{\partial w} =x=2,\frac{\partial z}{\partial x} =w=3 ∂w∂z=x=2,∂x∂z=w=3
- 继续前向传播, l o s s = ( y − y p r e d ) 2 loss = (y-y_{pred})^2 loss=(y−ypred)2,直到计算出loss函数
- 根据反向传播,程序可以计算出 ∂ L o s s ∂ z = 5 \frac{\partial Loss}{\partial z} =5 ∂z∂Loss=5
- 根据链式法则,我们知道 ∂ L o s s ∂ w = ∂ L o s s ∂ z ∗ ∂ z ∂ w \frac{\partial Loss}{\partial w}=\frac{\partial Loss}{\partial z}*\frac{\partial z}{\partial w} ∂w∂Loss=∂z∂Loss∗∂w∂z, 而我们已经计算出 ∂ z ∂ w = x = 2 \frac{\partial z}{\partial w} =x=2 ∂w∂z=x=2,所以 ∂ L o s s ∂ w = 2 ∗ 5 = 10 \frac{\partial Loss}{\partial w}=2*5=10 ∂w∂Loss=2∗5=10,同理可以计算出 ∂ L o s s ∂ x = 3 ∗ 5 = 15 \frac{\partial Loss}{\partial x}=3*5=15 ∂x∂Loss=3∗5=15
- 由此我们便完成了 ∂ z ∂ w , ∂ z ∂ x \frac{\partial z}{\partial w},\frac{\partial z}{\partial x} ∂w∂z,∂x∂z的计算。
1.4 例题
求loss函数关于w的偏导数
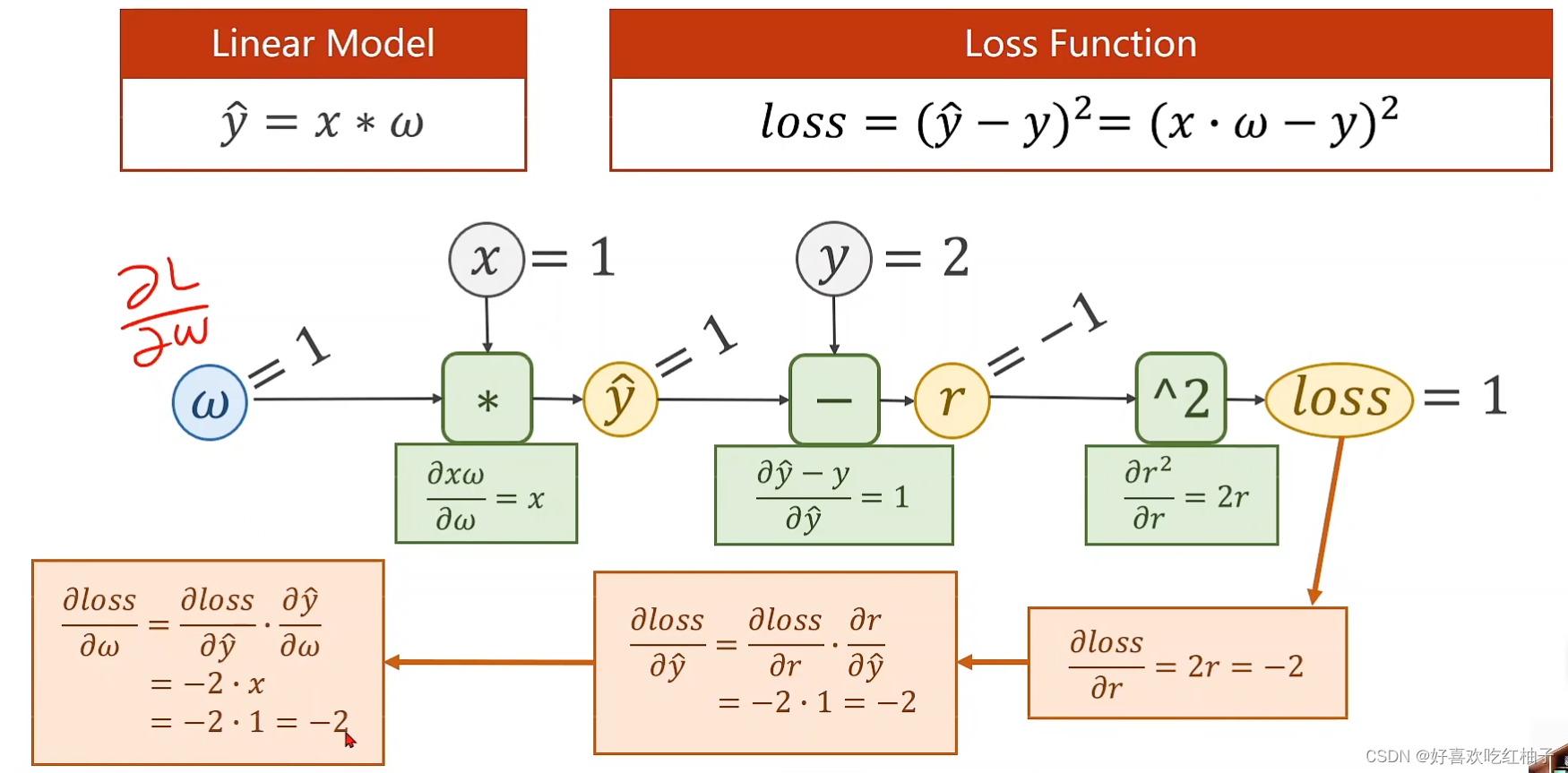
先前向传播求出局部梯度,再反向传播求得最终梯度
二、Pytorch中前向传播和反馈的计算
2.1 tensor数据类型
Tensor中有两个重要的数据变量
- data:该节点的数据值,为Tensor类
- grad:该节点的梯度值,为Tensor类
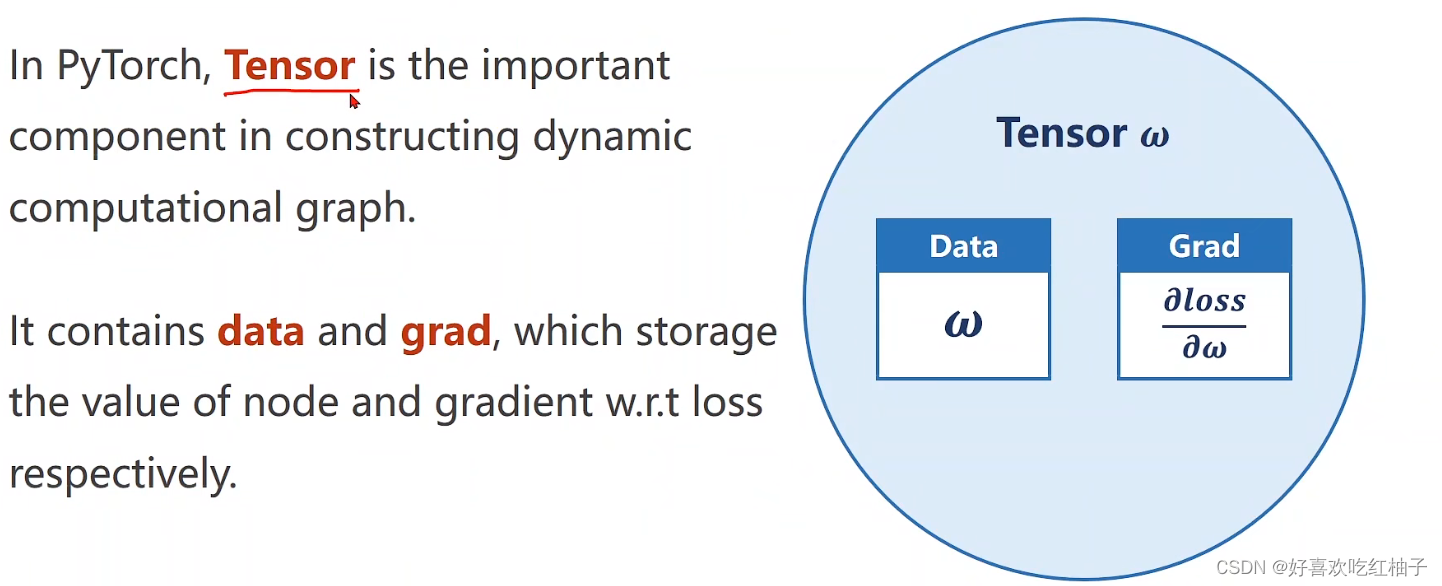
对w使用Tensor数据类型进行定义:设置requires_grad = True表明在计算过程中需要保留该值的梯度;
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = torch.tensor([1.0])
w.requires_grad = True
2.2 定义线性模型并且计算损失
y ′ = w ∗ x y' =w*x y′=w∗x
l o s s = ( y ′ − y ) 2 = ( x ∗ w − y ) 2 loss = (y'-y)^2 =(x*w-y)^2 loss=(y′−y)2=(x∗w−y)2
这段代码是在构建如下的计算图,前向传播并且求出loss值

此处的 l l l是一个张量(因为w是一个张量),所以后续需要 l l l的值时要使用 l . i t e m ( ) l.item() l.item()的方法进行取值
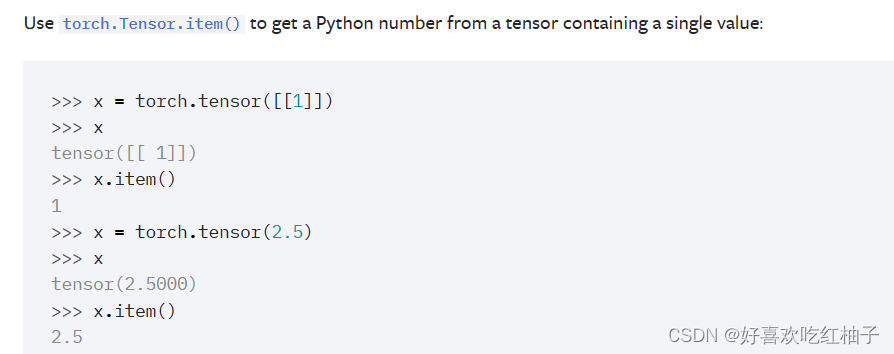
2.2.1 torch.tensor.item()
item()是将一个张量的值以一个python数字形式返回;
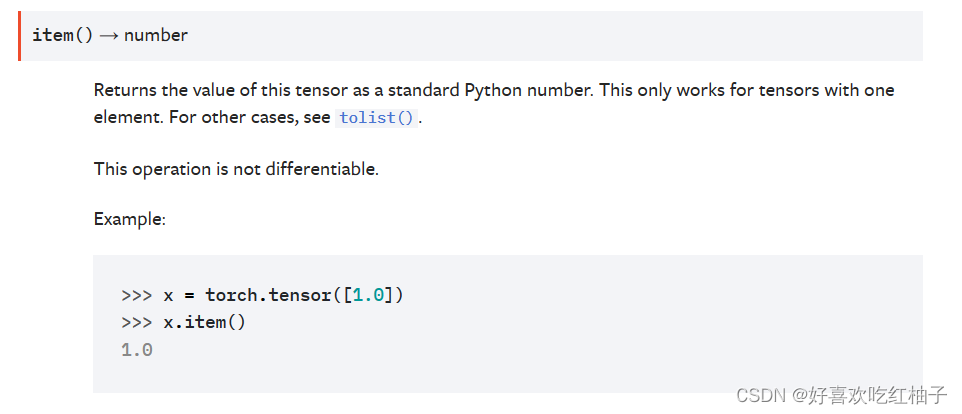
使用item()将Tensor张量转换为数字
2.2.2 代码
def forward(x):
return x*w
def loss(x,y):
return (y-forward(x))**2
2.3 反向传播
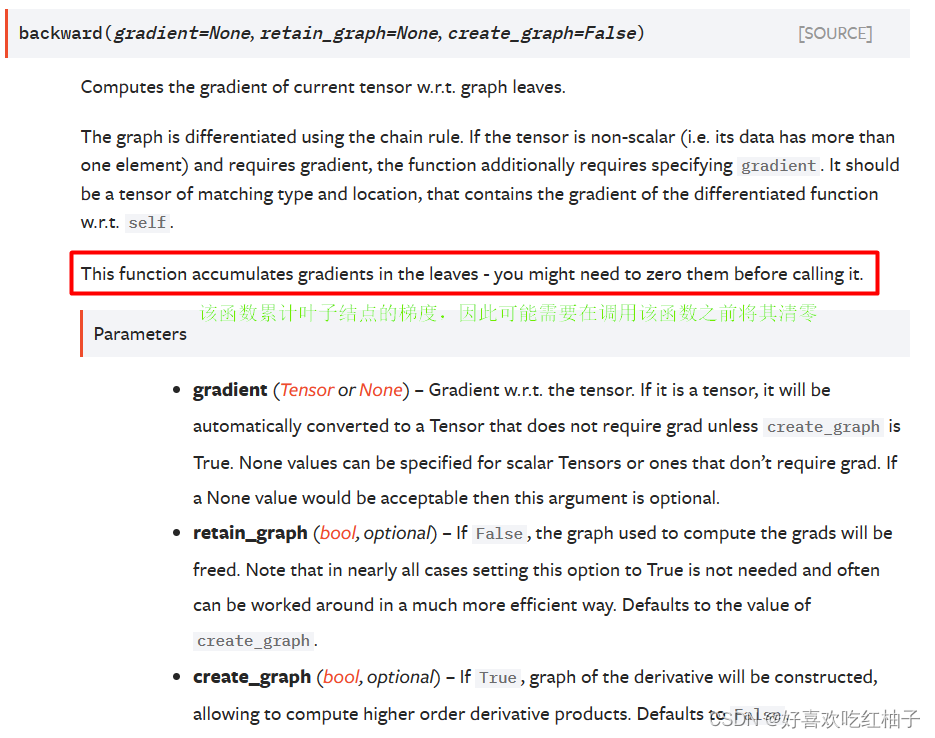
2.3.1 torch.tensor.backward()
该函数计算当前张量相对于计算图中所有叶子节点的梯度。
2.3.2 tensor.zero_( )
把Tensor的数值清零。

2.3.3 代码实现
- 使用for循环设置训练10个epoch
- 使用loss函数构建计算图,计算损失值
- 调用backward函数计算计算图上叶子节点的梯度值
- 根据w的梯度值更新w( w − = w ∗ 学习率 w-=w*学习率 w−=w∗学习率)
- 清空w的梯度,准备下一轮计算
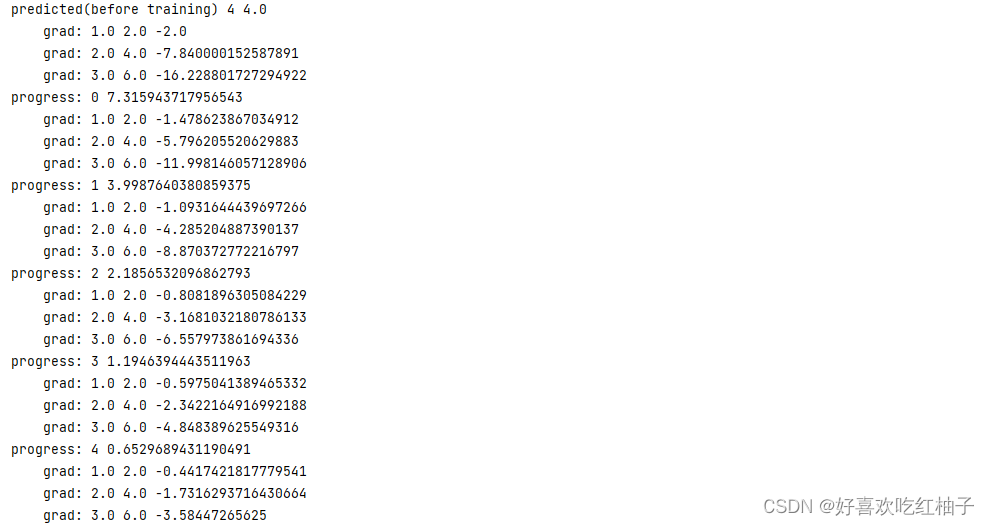
print("predicted(before training)",4,forward(4).item())
# 训练10个epoch
for epoch in range(10):
for x,y in zip(x_data,y_data):
# 计算损失值
l = loss(x,y)
# 反向传播
l.backward()
print("\tgrad:",x,y,w.grad.item())
# 更新w
w.data=w.data-0.01*w.grad
# 清空w的梯度
w.grad.zero_()
print("progress:",epoch,l.item())
print("predict(after training)",4,forward(4).item())
三、代码实现
import torch
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = torch.tensor([1.0])
w.requires_grad = True
def forward(x):
return x*w
def loss(x,y):
return (y-forward(x))**2
print("predicted(before training)",4,forward(4).item())
for epoch in range(10):
for x,y in zip(x_data,y_data):
l = loss(x,y)
l.backward()
print("\tgrad:",x,y,w.grad.item())
w.data=w.data-0.01*w.grad
w.grad.zero_()
print("progress:",epoch,l.item())
print("predict(after training)",4,forward(4).item())