Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
1.导读
不少工作已经意识到ChatGPT的秘密在于将指令微调和对其微调做到了极致,是继GPT-3后的又一次大力出奇迹。这篇文章来自清华大学5月份的工作,目的在于生成高质量的指令微调数据。
2.摘要和引言
指令微调的有效性已经被多个工作验证,ChatGPT更是是其中的代表。这个工作旨在提高开源模型的性能上限,提供了一个系统设计的、多样化的、信息丰富的、大规模的教学对话数据集UltraChat。UltraChat包含150万个高质量的多轮对话,并涵盖了广泛的主题和指令。UltraChat的统计分析揭示了其在尺度、平均长度、多样性、一致性等各种关键指标上的优势,巩固了其作为领先的开源数据集的地位。
这篇文章认为在训练过程中使用的数据的质量和多样性,对进一步提高聊天语言模型的性能起着至关重要的作用。
这个工作不再聚焦问答或总结等特定任务来构建数据,而是由3个部分组成:1.关于世界的问题、2.创建和生成,以及2.现有材料的辅助。
这个工作采用元信息、上下文内扩展和迭代提示 3种方式扩充指令的数量。
使用2个ChatGPT-turbo的API,一个表示用户user:生成问题queries;一个表示助手assistant:生成回答responses。
最后,使用生成的数据微调了llama模型,并使用ChatGPT评估(感觉存在瑕疵,因为ChatGPT已经被用于生成数据了)。结果如下图,取得了当时开源模型的最优性能。

3.相关工作
指令微调
这篇博客重点关注数据生成,略过。
数据生成
SelfInstruct (Wang et al., 2022),
Alpaca (Taori et al., 2023b),
code-alpaca (Chaudhary, 2023),
alpaca-cot (Si et al., 2023),
GPT4ALL (Anandet al., 2023),
ShareGPT (Domeccleston, 2023),
Dolly-v2 (Conover et al., 2023),
BELLE (Ji et al.,2023),
Vicuna (Chiang et al., 2023),
Koala (Genget al., 2023),
Baize (Xu et al., 2023),
CAMEL (Li et al.,2023)
4.方法
为了保证数据的质量和多样性,这个工作认为有两个关键点。
- 开场白直接决定了对话的主题。开场行应该高度多样化,并包含人类用户可能要求聊天模型执行的任何任务。
- 用户决定对话的情节,输出应该根据当前具有不同的语言风格和请求的主题进行定制。
4.1关于世界的问题
作者先问ChatGPT获得了30个元话题,然后对每个问题都进一步生成了30-50个子话题。对于每个子话题,又生成了10*10个question。
3030100=90000
3050100=150000
与此同时,作者还从Wikidata获得了10000个实体(例如,有机化学),每个实体生成了5*30个question。
10000*150=1500000
最后留下了500,000个关于世界的question。
4.2创造和生成
使用ChatGPT生成写作指令和数据。
4.3现有材料的辅助
首先收集了如下材料: C4:互联网数据(大概有20个T)。
然后,经过过滤得到了10,000个文本,对于每个文本都借助ChatGPT生成5个独特的instruction。
为了将instruction和文本对应起来,成为新的对话的开场白,作者设计了下面图中的模板,需要注意的是,有7行对应7种开场模板。最终,50万个模板被用于生成对话的开场白。

5.分析和评估
分析
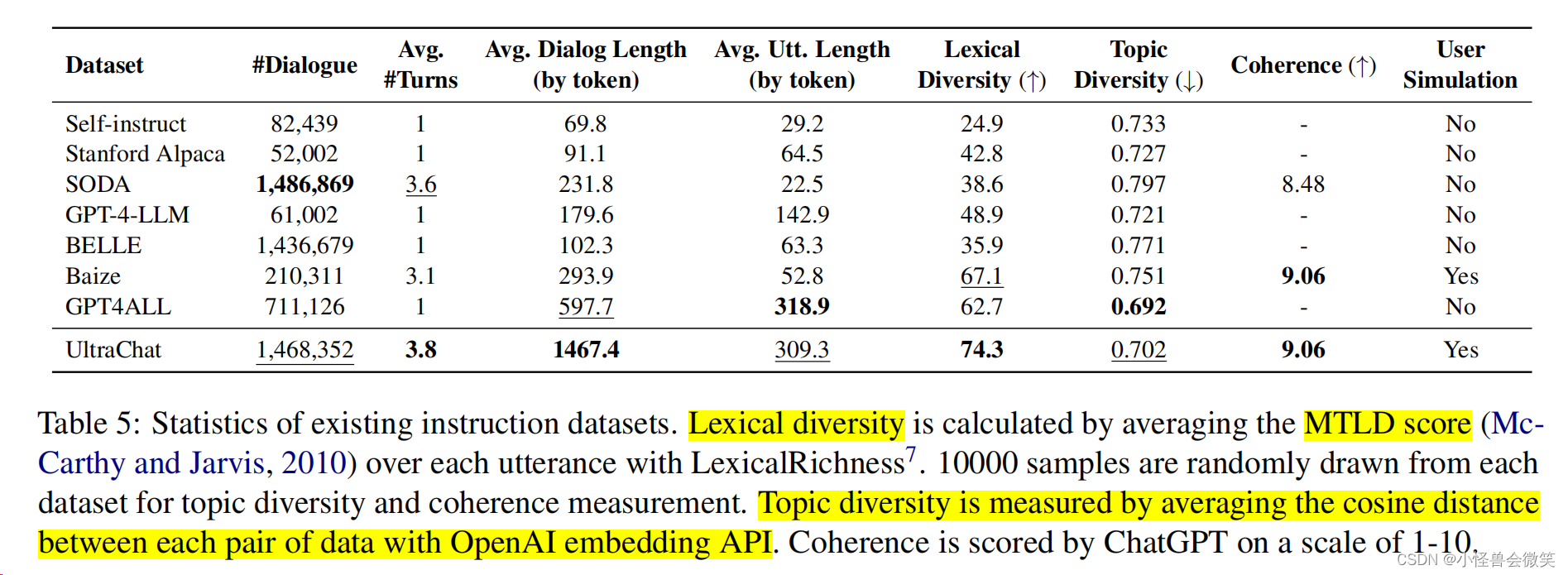
分析结果如下图所示,采用了:
- 对话轮数
- 对话长度
- 单轮对话长度
- 文本多样性(MTLD, 论文:Mtld, vocdd, and hd-d: A validation study of sophisticated approaches to lexical diversity assessment)
- 话题多样性(采样计算多少个话题和方差就行)
- 连贯性(ChatGPT)
评估
一个自己的评估集:Our Evaluation Set


世界知识评估集:Truthful QA: Principle-driven self-alignment of language models from scratch with
minimal human supervision.
