论文链接:
https://arxiv.org/abs/1805.01334
问题提出:
对于一个文本,可以抽取到很多有用的实体,如何给实体对于该文章的重要程度打分?
应用背景:
如果能够基于实体关于文本的重要程度进行打分,那么提取用户query的实体对于候选文本进行打分即可完成搜索引擎场景下候选文本的ranking.
模型方案:
本文计算实体与文本相似度的方案为将实体对于文本是否重要(Salience or not)进行打分。输入数据集可以理解为实体候选集(每一个实体有是否对于文本为salience的标注)与对应文本的一一对应。
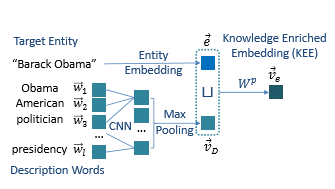
对于每一个实体计算其与候选集中所有实体的相似度(这里的计算相似度为计算二者embedding的COS,之后映射到rbf核空间并对不同的核映射值进行加总——类似于非参数核密度近似、在这里即为类比为语义距离的近似程度,后面的相似度也一样),再计算该实体与候选文本中所有token embedding的相似度,将这些相似度fuse成一个向量,将这个向量变换到1维得到实体与文本的相关度得分。

记下面为得分表示:

记如下salience标签表示
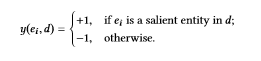
则可以如下定义损失:

经过优化后就可以使用实体关于文本的打分函数f来定义query关于文本的得分:

其中q为query,d为document。
下面给出训练打分函数的实现
数据说明:
本文采用原论文的第二个数据集Semantic Scholar corpus。其为json化的对象
数据连接:http://labs.semanticscholar.org/corpus/
按文中所述,entities域中为所有候选实体,实体是否出现在title域作为判定salience的准则,用于实体匹配打分的document为paperAbstract域。
实体的描述采用调用WiKIData api的方法(具体实现见下面爬虫代码)。
下面给出实现代码:
下载解压数据集,置于D:\download\corpus,下面给出scrapy调取WIKIData api的代码。
Item定义:
import scrapy
class WikidatacrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
entity = scrapy.Field()
description = scrapy.Field()
爬虫主体:
from scrapy.http import Request
from scrapy.spiders import Spider
from WikiDataCrawler.items import WikidatacrawlerItem
import os
import json
class file_Iter(object):
def __init__(self, rootDir):
req = []
list_dirs = os.walk(rootDir)
for root, dirs, files in list_dirs:
for d in dirs:
pass
for f in files:
req.append(os.path.join(root, f))
self.all_req_pos_files = req
def generate_entity(self, json_line):
json_obj = json.loads(json_line, encoding="utf-8")
if json_obj.get("entities"):
for ele in json_obj["entities"]:
yield ele
def __iter__(self):
for file in self.all_req_pos_files:
print("begin read {}".format(file) + "-" * 100)
with open(file, "r", encoding="utf-8") as f:
while True:
line = f.readline().strip()
if line:
for ele in self.generate_entity(line):
yield ele
else:
break
class DataSpider(Spider):
name = "dataSpider"
description_url_format = "https://www.wikidata.org/w/api.php?action=wbsearchentities&search={}&language=en&limit=20&format=json"
def data_loader(self):
print("call data_loader :")
self.file_Iter_ext = file_Iter("D:\download\corpus")
def start_requests(self):
self.data_loader()
for entity_str in self.file_Iter_ext:
yield Request(url = self.description_url_format.format(entity_str), meta={"entity": entity_str})
def parse(self, response):
if response.body:
json_obj = json.loads(response.body, encoding="utf-8")
if json_obj.get("search"):
first_item = json_obj["search"][0]
if first_item.get("description"):
item = WikidatacrawlerItem()
item["entity"] = response.meta["entity"]
item["description"] = first_item["description"]
yield item
pipeline 本地化:
import pandas as pd
class WikidatacrawlerPipeline(object):
def open_spider(self, spider):
self.df_chunk_size = 1e2
self.temp_list = []
self.df_dir = "ed.csv"
self.times = 0
def process_item(self, item, spider):
self.temp_list.append([item["entity"], item["description"]])
self.serialize()
return item
def serialize(self):
if len(self.temp_list) >= self.df_chunk_size:
df = pd.DataFrame(self.temp_list, columns=["entity", "description"])
if self.times:
with open(self.df_dir, "a", encoding="utf-8") as f:
df.to_csv(f, header=False)
else:
df.to_csv(self.df_dir, header=True, encoding="utf-8")
self.temp_list = []
self.times += 1
print("write times :{}".format(self.times))
def close_spider(self, spider):
print("will closed")
self.serialize()
如上得到实体描述后,进行数据处理:
import pandas as pd
from collections import Counter
from dl_text import dl
import nltk
import re
import json
import os
import pickle
class file_Iter(object):
def __init__(self, rootDir):
req = []
list_dirs = os.walk(rootDir)
for root, dirs, files in list_dirs:
for d in dirs:
pass
for f in files:
req.append(os.path.join(root, f))
self.all_req_pos_files = req
def generate_entity(self, json_line):
json_obj = json.loads(json_line, encoding="utf-8")
if json_obj.get("entities"):
for ele in json_obj["entities"]:
yield ele
def generate_corpus_req(self, json_line):
json_obj = json.loads(json_line, encoding="utf-8")
if json_obj.get("entities") and json_obj.get("paperAbstract") and json_obj.get("title"):
candidate_entities = json_obj["entities"]
lower_title = json_obj["title"].lower()
ture_target_entities = list(filter(lambda x: x.lower() in lower_title,candidate_entities))
false_target_entities = list(set(candidate_entities).difference(set(ture_target_entities)))
document_pos = clean_pos(json_obj["paperAbstract"])
yield [ture_target_entities, false_target_entities, document_pos]
def __iter__(self, entities_only = False):
for file in self.all_req_pos_files:
print("begin read {}".format(file) + "-" * 100)
with open(file, "r", encoding="utf-8") as f:
while True:
line = f.readline().strip()
if line:
if entities_only:
for ele in self.generate_entity(line):
yield ele
else:
for ele in self.generate_corpus_req(line):
yield ele
else:
break
def varify_token(token):
return re.match("[a-z]+", token)
def clean_pos(text):
return list(filter(varify_token ,nltk.tokenize.word_tokenize(dl.clean(text).lower())))
def process_corpos():
temp_list = []
df_chunk_size = int(1e4)
times = 0
df_dir = "corpus_df.csv"
def serialize(times, temp_list, final = False):
if final:
df = pd.DataFrame(temp_list, columns=["true_e", "false_e", "doc_pos"])
if times:
with open(df_dir, "a", encoding="utf-8") as f:
df.to_csv(f, header=False)
return
if len(temp_list) >= df_chunk_size:
df = pd.DataFrame(temp_list, columns=["true_e", "false_e", "doc_pos"])
if times:
with open(df_dir, "a", encoding="utf-8") as f:
df.to_csv(f, header=False)
else:
df.to_csv(df_dir, header=True, encoding="utf-8")
temp_list = []
times += 1
print("write times :{}".format(times))
return times, temp_list
file_Iter_ext = file_Iter("D:\download\corpus")
for l3 in file_Iter_ext:
temp_list.append(l3)
times, temp_list = serialize(times, temp_list)
serialize(times, temp_list, final = True)
def entity_and_word_idx(entity_num_filter_size = 10):
word_cnt = Counter()
entity_cnt = Counter()
entity_num_df = pd.read_csv(r"D:\Coding\python\KESM\data_process\corpus_with_entity_num.csv", encoding="utf-8")
req_entity_num_df = entity_num_df[entity_num_df["entity_intersect_count"] > entity_num_filter_size]
del entity_num_df
req_entity_num_df.to_csv("req_corpus_df.csv", encoding="utf-8")
print("serlize req_corpus_df end")
for ridx, r in req_entity_num_df.iterrows():
entities = eval(r["true_e"]) + eval(r["false_e"])
doc_pos = eval(r["doc_pos"])
entity_cnt.update(entities)
word_cnt.update(doc_pos)
if ridx % 10000 == 0:
print("ridx :{}".format(ridx))
entity_df = pd.DataFrame.from_csv(r"D:\Coding\python\KESM\data_process\entity_df.csv", encoding="utf-8")
for ridx, r in entity_df.iterrows():
#entity = r["entity"]
desp_token = eval(r["desp_token"])
word_cnt.update(desp_token)
if ridx % 10000 == 0:
print("ridx :{}".format(ridx))
with open("cnt.pkl", "wb") as f:
pickle.dump({
"word_cnt": word_cnt,
"entity_cnt": entity_cnt
}, f)
print("cnt serialize end")
def idx_file():
# full encode and mapping it by condition dynamicly.
req_entity_num_df = pd.read_csv(r"D:\Coding\python\KESM\data_process\req_corpus_df.csv", encoding="utf-8")
from collections import defaultdict
with open("cnt.pkl", "rb") as f:
cnt_dict = pickle.load(f)
word_cnt = cnt_dict["word_cnt"]
entity_cnt = cnt_dict["entity_cnt"]
word2idx = dict((t2[0], idx) for idx ,t2 in enumerate(sorted(word_cnt.items(), key = lambda x: -1 * x[1])))
word2idx = dict(list(word2idx.items()) + [("<unk>", len(word2idx))])
entity2idx = dict((t2[0], idx) for idx ,t2 in enumerate(sorted(entity_cnt.items(), key = lambda x: -1 * x[1])))
entity2idx = dict(list(entity2idx.items()) + [("<unk>", len(entity2idx))])
req_corpus_idx_collection = defaultdict(list)
times = 0
for ridx, r in req_entity_num_df.iterrows():
req_corpus_idx_collection["true_e"].append(list(map(lambda x: entity2idx[x] if entity2idx.get(x) else entity2idx["<unk>"],eval(r["true_e"]))))
req_corpus_idx_collection["false_e"].append(list(map(lambda x: entity2idx[x] if entity2idx.get(x) else entity2idx["<unk>"] ,eval(r["false_e"]))))
req_corpus_idx_collection["doc_pos"].append(list(map(lambda x: word2idx[x] if word2idx.get(x) else word2idx["<unk>"] ,eval(r["doc_pos"]))))
if len(req_corpus_idx_collection["true_e"]) == 1000:
temp_df = pd.DataFrame.from_dict(req_corpus_idx_collection)
req_corpus_idx_collection = defaultdict(list)
if times == 0:
temp_df.to_csv("req_corpus_idx_df.csv", encoding="utf-8", header=True)
else:
with open("req_corpus_idx_df.csv", "a", encoding="utf-8") as f:
temp_df.to_csv(f, header=False)
times += 1
print("times :{}".format(times))
print("corpus serlize end")
entity_df = pd.DataFrame.from_csv(r"D:\Coding\python\KESM\data_process\entity_df.csv", encoding="utf-8")
req_entity_idx_collection = defaultdict(list)
times = 0
for ridx, r in entity_df.iterrows():
req_entity_idx_collection["entity"].append(entity2idx[r["entity"]] if entity2idx.get(r["entity"]) else entity2idx["<unk>"])
req_entity_idx_collection["desp_token"].append(list(map(lambda x: word2idx[x] if word2idx.get(x) else word2idx["<unk>"] ,eval(r["desp_token"]))))
if len(req_entity_idx_collection["entity"]) == 1000:
temp_df = pd.DataFrame.from_dict(req_entity_idx_collection)
req_entity_idx_collection = defaultdict(list)
if times == 0:
temp_df.to_csv("entity_idx_df.csv", encoding="utf-8", header=True)
else:
with open("entity_idx_df.csv", "a", encoding="utf-8") as f:
temp_df.to_csv(f, header=False)
times += 1
print("times: {}".format(times))
print("entity serlize end")
with open("idx_dict.pkl", "wb") as f:
pickle.dump({
"word2idx": word2idx,
"entity2idx": entity2idx
}, f)
def process_ed_csv():
temp_list = []
df_chunk_size = int(1e4)
times = 0
df_dir = "entity_df.csv"
def serialize(times, temp_list, final = False):
if final:
df = pd.DataFrame(temp_list, columns=["entity", "desp_token"])
if times:
with open(df_dir, "a", encoding="utf-8") as f:
df.to_csv(f, header=False)
return
if len(temp_list) >= df_chunk_size:
df = pd.DataFrame(temp_list, columns=["entity", "desp_token"])
if times:
with open(df_dir, "a", encoding="utf-8") as f:
df.to_csv(f, header=False)
else:
df.to_csv(df_dir, header=True, encoding="utf-8")
temp_list = []
times += 1
print("write times :{}".format(times))
return times, temp_list
entity_description_df = pd.read_csv("D:\Coding\python\KESM\WikiDataCrawler\ed.csv", encoding="utf-8")
for row_idx, row in entity_description_df.iterrows():
entity = row["entity"]
description = row["description"]
desp_token = clean_pos(description)
temp_list.append([entity, desp_token])
times, temp_list = serialize(times, temp_list)
serialize(times, temp_list, final=True)
def sort_corpus_df_entity_have_num():
entity_df = pd.read_csv("D:\Coding\python\KESM\data_process\entity_df.csv", encoding="utf-8", header=0)
corpus_df = pd.read_csv("D:\Coding\python\KESM\data_process\corpus_df.csv", encoding="utf-8", header=0)
all_entity_set = set(entity_df["entity"].tolist())
print("all_entity_set num :{}".format(len(all_entity_set)))
def count_intersection(x):
return len(set(eval(x["true_e"]) + eval(x["false_e"])).intersection(all_entity_set))
corpus_df["entity_intersect_count"] = corpus_df.apply(count_intersection, axis=1)
print("col calculate end")
corpus_df.to_csv("corpus_with_entity_num.csv", encoding="utf-8")
print("df serialize end")
if __name__ == "__main__":
process_ed_csv()
process_corpos()
sort_corpus_df_entity_have_num()
entity_and_word_idx()
idx_file()
上面的过程进行了简单的数据清洗、编码。sort_corpus_df_entity_have_num()entity_and_word_idx() 两个函数计算了每个样本有实体描述的个数,为了显示提升模型的效果,这里采用实体个数超过10个的进行实验。
数据导出:
import tensorflow as tf
import numpy as np
from functools import reduce
import pandas as pd
import pause
import gc
import pickle
with open(r"D:\Coding\python\KESM\data_process\idx_dict.pkl", "rb") as f:
idx_dict = pickle.load(f)
word2idx = idx_dict["word2idx"]
entity2idx = idx_dict["entity2idx"]
corpus_df = pd.DataFrame.from_csv(r"D:\Coding\python\KESM\data_process\req_corpus_idx_df.csv", encoding="utf-8", header=0)
test_basic_sample_num = int(1e4)
entity_df = pd.DataFrame.from_csv(r"D:\Coding\python\KESM\data_process\entity_idx_df.csv", encoding="utf-8", header=0)
entity_desp_dict = dict()
for _, r in entity_df.iterrows():
entity_desp_dict[r["entity"]] = r["desp_token"]
del entity_df
gc.collect()
# epi: entity padding index
# dpi word padding idx
def data_generator(type = "train", batch_num = 128, max_kee_num = 10, desp_max_length = 50, doc_max_length = 500,
epi = len(entity2idx) - 1, dpi = len(word2idx) - 1):
take_nums = 1e10
take_num = 0
global corpus_df
if type == "train":
corpus_df = corpus_df.iloc[test_basic_sample_num:, :]
else:
corpus_df = corpus_df.iloc[:test_basic_sample_num, :]
input_kee_1 = np.full(shape=[batch_num, max_kee_num], fill_value=epi, dtype=np.int32)
input_kee_desp_1 = np.full(shape=[batch_num, max_kee_num, desp_max_length], fill_value=dpi, dtype=np.int32)
input_kee_2 = np.full(shape=[batch_num, max_kee_num], fill_value=epi, dtype=np.int32)
input_kee_desp_2 = np.full(shape=[batch_num, max_kee_num, desp_max_length], fill_value=dpi, dtype=np.int32)
input_doc = np.full(shape=[batch_num, doc_max_length], fill_value=dpi, dtype=np.int32)
input_kee_mask = np.ones(shape=[batch_num], dtype=np.int32)
start_idx = 0
for idx, r in corpus_df.iterrows():
doc_pos, true_e, false_e = map(eval ,[r["doc_pos"], r["true_e"], r["false_e"]])
all_e = (true_e + false_e)[:max_kee_num]
false_e = list(set(all_e).difference(set(true_e)))[:len(true_e)]
if len(false_e) != len(true_e):
continue
# input_kee* part
for ele_idx ,true_e_ele in enumerate(true_e):
input_kee_1[start_idx][0] = true_e_ele
entity_desp_str = entity_desp_dict.get(true_e_ele)
input_kee_desp_1[start_idx][0] = eval(entity_desp_str)[:desp_max_length] + \
[dpi] * (desp_max_length - len(eval(entity_desp_str))) \
if entity_desp_str else [dpi] * desp_max_length
for oidx ,other in enumerate(set(all_e).difference(set([true_e_ele]))):
if oidx == max_kee_num - 2:
break
input_kee_1[start_idx][oidx + 1] = other
entity_desp_str = entity_desp_dict.get(other)
input_kee_desp_1[start_idx][oidx + 1] = eval(entity_desp_str)[:desp_max_length] \
+ [dpi] * (desp_max_length - len(eval(entity_desp_str))) \
if entity_desp_str else [dpi] * desp_max_length
false_e_ele = false_e[ele_idx]
input_kee_2[start_idx][0] = false_e_ele
entity_desp_str = entity_desp_dict.get(false_e_ele)
input_kee_desp_2[start_idx][0] = eval(entity_desp_str)[:desp_max_length] + \
[dpi] * (desp_max_length - len(eval(entity_desp_str))) \
if entity_desp_str else [dpi] * desp_max_length
for oidx ,other in enumerate(set(all_e).difference(set([false_e_ele]))):
if oidx == max_kee_num - 2:
break
input_kee_2[start_idx][oidx + 1] = other
entity_desp_str = entity_desp_dict.get(other)
input_kee_desp_2[start_idx][oidx + 1] = eval(entity_desp_str)[:desp_max_length] \
+ [dpi] * (desp_max_length - len(eval(entity_desp_str))) \
if entity_desp_str else [dpi] * desp_max_length
# input doc part
input_doc[start_idx] = doc_pos[:doc_max_length] + [dpi] * (doc_max_length - len(doc_pos))
# y part
#y[start_idx] = 1
# input_kee_mask part
input_kee_mask[start_idx] = len(all_e)
start_idx += 1
if start_idx == batch_num:
yield (input_kee_1, input_kee_desp_1, input_kee_2, input_kee_desp_2, input_doc, input_kee_mask)
start_idx = 0
take_num += 1
if take_num == take_nums:
return
input_kee_1 = np.full(shape=[batch_num, max_kee_num], fill_value=epi, dtype=np.int32)
input_kee_desp_1 = np.full(shape=[batch_num, max_kee_num, desp_max_length], fill_value=dpi, dtype=np.int32)
input_kee_2 = np.full(shape=[batch_num, max_kee_num], fill_value=epi, dtype=np.int32)
input_kee_desp_2 = np.full(shape=[batch_num, max_kee_num, desp_max_length], fill_value=dpi, dtype=np.int32)
input_doc = np.full(shape=[batch_num, doc_max_length], fill_value=dpi, dtype=np.int32)
input_kee_mask = np.ones(shape=[batch_num], dtype=np.int32)
从数据导出部分可以窥见模型输入数据的格式。由于最后损失为score对的形式(这并不是偶然的,可以参见的learning to rank模型,这里提一句,如果将配对训练打分的形式改成单个实体的简单二分类,结果是很差的,因为所有的实体不论salience与否都与原文有关,进行二分类无法突出序上的准确度),故在实体输入上也采用正负配对输入的格式,即
input_kee_1对应salience实体的信息,input_kee_desp_1是其对应的描述,input_kee_2为非salience实体(input_kee_desp_2)。
这里input_kee_*第一维为batch维度,第二维第一个元素部分为目标实体(即用来与所有实体及文本算相似度的元素),实际这里相当于input_kee_1 input_kee_2第二个维度除了第一位元素都是相同的(懒得改网络结构了),从编程的角度累赘了,感兴趣的话可以改一下。input_doc为样本的文本输入,input_kee_mask为描述input_kee_*第二个维度实际长度的mask向量。
有了上述数据输入,如下定义网络结构:
# 为网络输入简单,将target kee 与 kee of doc拼接输入,
# 第一个为target 及其对应描述,后面的可以进行slice得到。
kernel_params_list = []
mu_array = np.arange(-0.9, 1.0, 0.1)
sigma = 0.1
for mu in mu_array:
kernel_params_list.append((mu, sigma, mu, sigma))
class KESM(object):
def __init__(self, desp_max_length = 50, doc_max_length = 500, entity_size = int(1e4),
vocab_size = int(1e5), entity_embedding_dim = 100, word_embedding_dim = 100,
cnn_filter_sizes = [3, 4, 5], num_filters = 3, batch_num = 128,
kernel_params_list = kernel_params_list):
self.desp_max_length = desp_max_length
self.doc_max_length = doc_max_length
self.entity_size = entity_size
self.vocab_size = vocab_size
self.entity_embedding_dim = entity_embedding_dim
self.word_embedding_dim = word_embedding_dim
self.batch_num = batch_num
self.kernel_params_list = kernel_params_list
# nn params
self.cnn_filter_sizes = cnn_filter_sizes
self.num_filters = num_filters
self.input_kee_1 = tf.placeholder(tf.int32, shape=[None, None])
self.input_kee_desp_1 = tf.placeholder(tf.int32, shape=[None, None, desp_max_length])
self.input_kee_2 = tf.placeholder(tf.int32, shape=[None, None])
self.input_kee_desp_2 = tf.placeholder(tf.int32, shape=[None, None, desp_max_length])
self.input_doc = tf.placeholder(tf.int32, shape=[None, doc_max_length])
#input all kee num in int format
self.input_kee_mask = tf.placeholder(tf.int32, [None])
# same input tensors which will be init in the graph construct time.
self.ve_before_reshape_1 = None
self.ve_before_reshape_2 = None
self.max_mask_num = None
self.loss = None
with tf.name_scope("entity_embeddings"):
self.Entity_Embedding = tf.Variable(
tf.random_normal(shape=[self.entity_size, self.entity_embedding_dim]),
name="EE"
)
with tf.name_scope("word_embeddings"):
self.Word_Embedding = tf.Variable(
tf.random_normal(shape=[self.vocab_size, self.word_embedding_dim])
,name="WE"
)
# model construct
self.opt_construct()
def model_construct(self, input_kee_desp, input_kee):
reshape_padding_ve = self.knowledge_enriched_embedding_layer(input_kee_desp, input_kee)
doc_lookup = tf.nn.embedding_lookup(self.Word_Embedding ,self.input_doc)
param_tuple_map = list(map(lambda inner_tuple: tuple([reshape_padding_ve, doc_lookup] + list(inner_tuple)) ,self.kernel_params_list))
batch_kernel_list = reduce(lambda x, y: x + y,map(self.kernel_interaction_kernel, param_tuple_map))
# [batch, total_kernel_dim]
# fuse kee doc information into a vector
KIM = tf.concat(batch_kernel_list, axis = -1)
#f_score = tf.layers.dense(KIM, units=1, reuse=True)
f_score = tf.layers.dense(KIM, units=1)
return f_score
def opt_construct(self):
with tf.variable_scope("f_score_layer", reuse=tf.AUTO_REUSE):
f_score_1 = self.model_construct(self.input_kee_desp_1, self.input_kee_1)
f_score_2 = self.model_construct(self.input_kee_desp_2, self.input_kee_2)
self.f_score_1 = f_score_1
self.f_score_2 = f_score_2
# f_score_1 indicate positive f_score_2 indicate negative
self.loss = tf.reduce_mean(tf.nn.relu(1 - f_score_1 + f_score_2))
self.train_op = tf.train.AdamOptimizer(0.001).minimize(self.loss)
def cnn_layer(self, M):
# Create a convolution + maxpool layer for each filter size
sequence_length = int(M.get_shape()[1])
pooled_outputs = []
for i, filter_size in enumerate(self.cnn_filter_sizes):
with tf.variable_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, self.word_embedding_dim, 1, self.num_filters]
W = tf.get_variable(
shape=filter_shape,dtype=tf.float32,initializer=tf.initializers.random_normal(),
name="cnn_W_{}".format(filter_size)
)
b = tf.get_variable(
shape=[self.num_filters], dtype=tf.float32, initializer=tf.initializers.constant(1.0),
name= "cnn_b_{}".format(filter_size)
)
conv = tf.nn.conv2d(
M,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_final_shape = pooled.get_shape()
final_size = int(pooled_final_shape[-1]) * int(pooled_final_shape[-2]) * int(pooled_final_shape[-3])
pooled_outputs.append(tf.reshape(pooled, [-1, final_size]))
return tf.concat(pooled_outputs, -1, name="kee_desp_cnn_output")
def knowledge_enriched_embedding_layer(self, input_kee_desp, input_kee):
input_kee_desp_reshape = tf.reshape(input_kee_desp, [-1, self.desp_max_length])
input_kee_reshape = tf.reshape(input_kee, [-1])
with tf.name_scope("kee_desp_cnn_layer"):
kee_desp_lookup = tf.nn.embedding_lookup(self.Word_Embedding, input_kee_desp_reshape)
#[batch_hat, desp_len, embedding, 1]
kee_desp_lookup_expd = tf.expand_dims(kee_desp_lookup, -1)
#[batch_hat, cnn_flat_dim]
kee_desp_cnn_output = self.cnn_layer(kee_desp_lookup_expd)
#[batch_hat, entity_dim]
kee_lookup = tf.nn.embedding_lookup(self.Entity_Embedding, input_kee_reshape)
fuse_desp_entity = tf.concat([kee_desp_cnn_output, kee_lookup], axis=-1)
ve_dim = self.word_embedding_dim
ve_before_reshape = tf.layers.dense(fuse_desp_entity, units=ve_dim, name="ve_layer")
self.ve_before_reshape = ve_before_reshape
# slice entire sequence by generate bool sequences.
sum_mask_num = tf.reduce_sum(self.input_kee_mask)
cumsum_mask_num_second = tf.cumsum(self.input_kee_mask)
cumsum_mask_num_first = tf.slice(tf.concat([tf.constant([0]), cumsum_mask_num_second], axis=0), [0], [self.batch_num])
cumsum_seq_mask_first = tf.cast(tf.sequence_mask(cumsum_mask_num_first, maxlen=sum_mask_num), tf.int32)
cumsum_seq_mask_second = tf.cast(tf.sequence_mask(cumsum_mask_num_second, maxlen=sum_mask_num), tf.int32)
cumsum_seq_mask = tf.cast(cumsum_seq_mask_second - cumsum_seq_mask_first, tf.bool)
max_mask_num = tf.reduce_max(self.input_kee_mask)
self.max_mask_num = max_mask_num
def reshape_padding_ve_func(cumsum_seq_mask_ele):
head = tf.boolean_mask(self.ve_before_reshape, cumsum_seq_mask_ele)
padding = tf.zeros(shape=[max_mask_num - tf.reduce_sum(tf.cast(cumsum_seq_mask_ele, tf.int32)), ve_dim])
return tf.concat([head, padding], axis=0)
# [batch, max_mask_num, fuse_dim]
reshape_padding_ve = tf.map_fn(reshape_padding_ve_func, cumsum_seq_mask, dtype=tf.float32)
return reshape_padding_ve
def kernel_interaction_kernel(self, input):
kee_input, doc_input, mu_k_e, sigma_k_e, mu_k_d, sigma_k_d = input
# kee_input [batch, max_mask_num, fuse_dim]
# doc_input [batch, doc_max_len, word_embedding_dim]
kee_target_part = tf.nn.l2_normalize(tf.slice(kee_input, [0, 0, 0], [-1, 1, -1]), dim=1)
kee_others_part = tf.nn.l2_normalize(tf.slice(kee_input, [0, 1, 0], [-1, -1, -1]), dim=1)
kee_target_part_tiled = tf.tile(kee_target_part, [1, self.max_mask_num - 1 ,1])
# [batch, max_mask_num - 1]
kee_cos_part = tf.reduce_sum(kee_target_part_tiled * kee_others_part, axis=-1)
exp_kee_cos_part = tf.exp(-1 * (kee_cos_part - mu_k_e) * (kee_cos_part - mu_k_e) / sigma_k_e)
kee_valid_part_mask = tf.cast(tf.sequence_mask(self.input_kee_mask - 1, maxlen=self.max_mask_num - 1), tf.float32)
#[batch]
kee_batch_kernel = tf.reduce_sum(exp_kee_cos_part * kee_valid_part_mask, axis=-1)
doc_max_len = int(doc_input.get_shape()[1])
doc_target_part_tiled = tf.tile(kee_target_part, [1, doc_max_len ,1])
doc_cos_part = tf.reduce_sum(doc_target_part_tiled * doc_input, axis=-1)
exp_doc_cos_part = tf.exp(-1 * (doc_cos_part - mu_k_d) * (doc_cos_part - mu_k_d) / sigma_k_d)
#[batch]
doc_batch_kernel = tf.reduce_sum(exp_doc_cos_part, axis=-1)
return [tf.expand_dims(kee_batch_kernel, -1), tf.expand_dims(doc_batch_kernel, -1)]
@staticmethod
def train():
import pause
batch_num = 128
model = KESM(batch_num=batch_num, vocab_size=len(word2idx), entity_size=len(entity2idx))
times = 0
train_gen = data_generator(batch_num = batch_num)
test_gen = data_generator(type="test" ,batch_num = batch_num)
epoch = 0
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
while True:
try:
input_kee_1, input_kee_desp_1, input_kee_2, input_kee_desp_2, input_doc, input_kee_mask = train_gen.__next__()
except:
print("epoch {} end".format(epoch))
train_gen = data_generator(batch_num = batch_num)
epoch += 1
_ ,train_loss, = sess.run([model.train_op ,model.loss], feed_dict={
model.input_kee_1: input_kee_1,
model.input_kee_desp_1: input_kee_desp_1,
model.input_kee_2: input_kee_2,
model.input_kee_desp_2: input_kee_desp_2,
model.input_doc: input_doc,
model.input_kee_mask: input_kee_mask
})
print("train loss :{}".format(train_loss))
if times % 10 == 0:
try:
input_kee_1, input_kee_desp_1, input_kee_2, input_kee_desp_2, input_doc, input_kee_mask = test_gen.__next__()
except:
print("epoch {} end".format(epoch))
test_gen = data_generator(type="test" ,batch_num = batch_num)
epoch += 1
test_loss, f_score_1, f_score_2 = sess.run([model.loss, model.f_score_1, model.f_score_2], feed_dict={
model.input_kee_1: input_kee_1,
model.input_kee_desp_1: input_kee_desp_1,
model.input_kee_2: input_kee_2,
model.input_kee_desp_2: input_kee_desp_2,
model.input_doc: input_doc,
model.input_kee_mask: input_kee_mask
})
acc = np.array(f_score_1 > f_score_2, dtype=np.float32).mean()
print("test loss :{} acc:{}".format(test_loss, acc))
times += 1
if __name__ == "__main__":
KESM.train()
这里rbf核的超参数与原文的设定一致,并对于测试集计算了acc看精度(训练集训练时拟合较好,不记录),这里的收敛精度定义为,f_score_1 > f_score_2的比例,因为从输入角度看应有这个结果成立。
由于之前数据处理的特征,及挑选的都是有大量实体描述的样本,收敛程度较好,下面是训练先期记录:
train loss :32.136802673339844 test loss :29.226028442382812 acc:0.0234375 train loss :31.882282257080078 train loss :30.8996639251709 train loss :28.286611557006836 train loss :31.86393165588379 train loss :27.266090393066406 train loss :20.51707649230957 train loss :19.864543914794922 train loss :24.485538482666016 train loss :21.631492614746094 train loss :20.699556350708008 test loss :20.515953063964844 acc:0.078125 train loss :21.719375610351562 train loss :18.175708770751953 train loss :18.79627227783203 train loss :15.973711967468262 train loss :22.51378059387207 train loss :16.266401290893555 train loss :16.994487762451172 train loss :19.631580352783203 train loss :19.612144470214844 train loss :16.92822265625 test loss :17.485687255859375 acc:0.0546875 train loss :14.07847785949707 train loss :17.884946823120117 train loss :18.433307647705078 train loss :15.116429328918457 train loss :14.5866117477417 train loss :12.568949699401855 train loss :16.726009368896484 train loss :16.02698516845703 train loss :12.45231819152832 train loss :18.996814727783203 test loss :14.900018692016602 acc:0.078125 train loss :12.213709831237793 train loss :14.977048873901367 train loss :14.515562057495117 train loss :16.51100730895996 train loss :19.332717895507812 train loss :14.827428817749023 train loss :16.82861328125 train loss :9.731084823608398 train loss :10.145099639892578 train loss :10.770788192749023 test loss :13.10962200164795 acc:0.21875 train loss :10.626840591430664 train loss :10.669485092163086 train loss :9.882623672485352 train loss :14.196492195129395 train loss :12.102956771850586 train loss :10.761802673339844 train loss :6.499850273132324 train loss :9.159351348876953 train loss :6.764830112457275 train loss :9.540651321411133 test loss :7.350927829742432 acc:0.375 train loss :11.662117004394531 train loss :10.092960357666016 train loss :8.116621017456055 train loss :7.211489677429199 train loss :6.5933051109313965 train loss :8.281878471374512 train loss :9.252912521362305 train loss :8.742061614990234 train loss :11.99124526977539 train loss :7.668788909912109 test loss :5.253876686096191 acc:0.46875 train loss :10.226776123046875 train loss :10.507610321044922 train loss :10.862887382507324 train loss :6.5200276374816895 train loss :6.80426025390625 train loss :3.6178395748138428 train loss :5.657415866851807 train loss :5.388607978820801 train loss :6.250310897827148 train loss :5.500130653381348 test loss :8.942505836486816 acc:0.6328125 train loss :5.482635498046875 train loss :5.60318660736084 train loss :6.55861234664917 train loss :5.086772918701172 train loss :3.8880820274353027 train loss :8.441230773925781 train loss :7.050711631774902 train loss :6.250699043273926 train loss :5.3991241455078125 train loss :2.348048210144043 test loss :6.638607978820801 acc:0.7734375 train loss :4.900678634643555 train loss :3.669212579727173 train loss :5.357037544250488 train loss :3.8981685638427734 train loss :4.366262435913086 train loss :1.9637587070465088 train loss :3.004202365875244 train loss :4.238396167755127 train loss :4.1686506271362305 train loss :6.312758445739746 test loss :2.175901412963867 acc:0.921875 train loss :2.532480478286743 train loss :2.8864879608154297 train loss :2.166124105453491 train loss :2.396486282348633 train loss :3.142045021057129 train loss :1.9758951663970947 train loss :4.525737762451172 train loss :1.556884527206421 train loss :2.350480794906616 train loss :1.3652114868164062 test loss :1.55498206615448 acc:0.9140625 train loss :1.553002119064331 train loss :1.5114221572875977 train loss :1.7723044157028198 train loss :2.9699597358703613 train loss :1.4816454648971558 train loss :1.3616077899932861 train loss :1.8693952560424805 train loss :2.3389508724212646 train loss :2.7014565467834473 train loss :1.9040240049362183 test loss :2.8285391330718994 acc:0.9140625 train loss :2.5975096225738525 train loss :1.7298221588134766 train loss :2.5001325607299805 train loss :2.3010199069976807 train loss :0.4678676426410675 train loss :0.6357259750366211 train loss :0.695709764957428 train loss :2.253744125366211 train loss :1.4345471858978271 train loss :1.1282814741134644 test loss :0.5373156070709229 acc:0.953125 train loss :0.311814546585083 train loss :1.4651544094085693 train loss :0.8269515037536621 train loss :0.5220216512680054 train loss :0.1606338918209076 train loss :0.1128043532371521 train loss :0.8103121519088745 train loss :0.4834401309490204 train loss :1.2986313104629517 train loss :0.4324950575828552 test loss :0.2764070928096771 acc:0.9453125 train loss :0.18162190914154053 train loss :0.47013553977012634 train loss :0.34739431738853455 train loss :0.3420702815055847 train loss :1.5287249088287354 train loss :0.9801853895187378 train loss :0.6511420607566833 train loss :0.6557278633117676 train loss :0.4798915982246399 train loss :0.5535762906074524 test loss :0.07494109869003296 acc:0.984375 train loss :0.511849045753479 train loss :0.8412278294563293 train loss :0.4313739538192749 train loss :0.449565052986145 train loss :0.252207487821579 train loss :0.30550551414489746 train loss :0.4194437265396118 train loss :0.5475836396217346 train loss :0.6809948086738586 train loss :0.21016159653663635 test loss :0.10047291219234467 acc:0.984375 train loss :0.5512081980705261 train loss :0.46260714530944824 train loss :0.1845911145210266 train loss :1.8909573554992676e-05 train loss :0.00864720344543457 train loss :0.003664463758468628 train loss :0.3173838257789612 train loss :0.3461763858795166 train loss :0.0414513535797596 train loss :0.02685767412185669 test loss :0.3495218753814697 acc:0.9765625
如果感兴趣,可以尝试把搜索引擎部分做了。