
论文题目:A Technical Report for Polyglot-Ko: Open-Source Large-Scale Korean Language Models
1.介绍
尽管 mBERT、BLOOM、XGLM 等多语言语言模型已经发布,但使用非英语语言的研究人员仍在追求单语模型。这是因为公开的<多语言>模型的训练数据偏向于英语,在非英语语言任务上表现不佳。
2.数据集
2.1.数据收集
韩国数据由 TUNiB 863GB(预处理前为 1.2TB)Polyglot-Ko 收集用于训练,未开源,数据包含了以下内容:
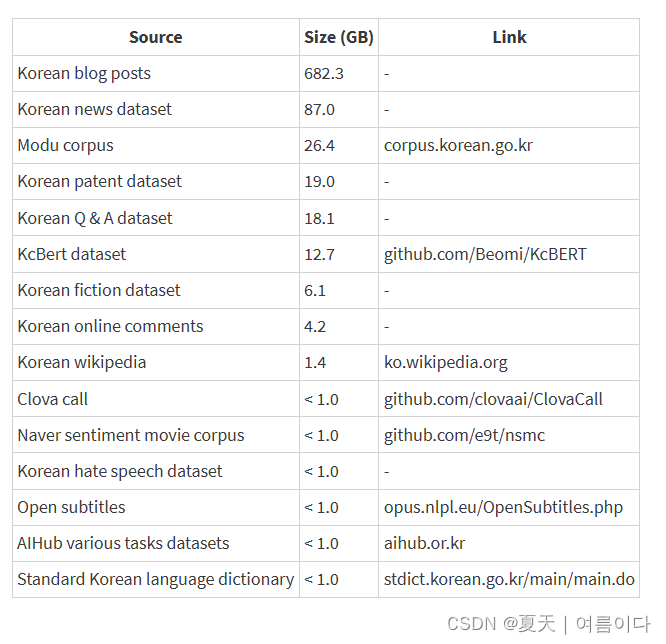
2.2. 数据分析
2.2.1.学习路径
- 句子太短或太长
- 重复的字词或字符
- 重复数据
2.2.2.推理过程
- 个人身份信息 ( PII )
在每个过程中,上述问题都可能造成风险,因此进行数据分析。
从降低上述风险的角度分析数据,将数据分为四种类型
- 可训练数据
- 新闻, 维基百科: 文本足够长的信息
- 上下文信息允许从数据中学习
- 博客,一些新闻:由许多短句组成的剪辑不佳
- 仇恨言论的不可训练数据
- 一些社区数据
- NLP 任务数据
- NLP任务数据,如文本分类、实体识别:可用于训练,但在评估时应排除
在训练数据之前,需要解决一些质量问题。
执行预处理,因为它可能会在学习过程中引起问题
- 空文本:空句
- Unnecessary space : 不必要的空间
- 去标识化:个人数据
- 未清除的 HTML 标记 :未清除 HTML 标记
- 重复数据删除:完全匹配重复数据实例
- 损坏的代码:仅存在 HML 或 Markdown 的一部分
- 短文本:句子太短
- 重复字符:数据实例中的重复字符
→ plyglot 旨在生成韩语句子,因此请尽可能删除所有类似 html 的代码。
另一个需要预处理的重要问题是数据的长度
→ 句子越长,模型学习的信息就越多
3.模型
为了训练polyglot模型,使用GPT-NeoX 为基础,也就是Transformer的decoder的构架。
- 1.3B的模型训练于213B tokens
- 3.8B的模型训练于219B tokens
- 5.8B的模型训练于172B tokens
- 12.8B的模型训练于167B tokens
特征词大小是30003,使用的tokenize是 morpheme-aware ByteLevel BPE (Byte-Pair Encoding).
词素分析(morpheme analysis)使用MeCab,就是一种分词方法。
模型版本
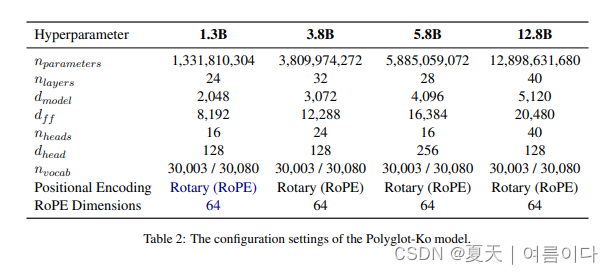
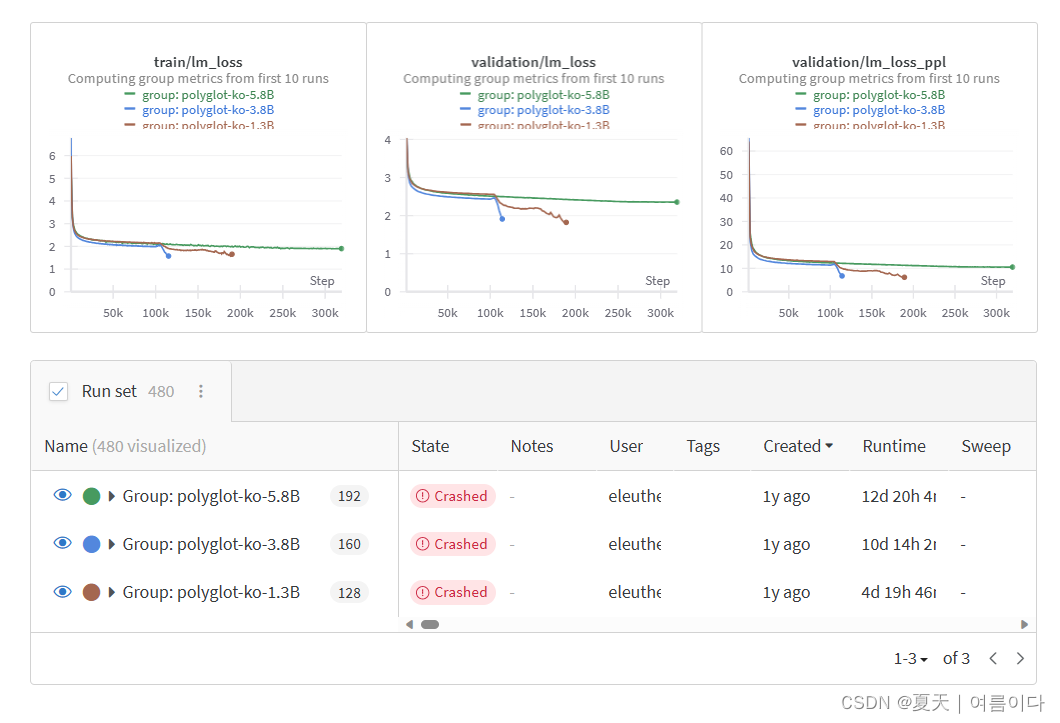
1.3B 模型没有使用模型并行,利用一个整的批量大小1024,训练,验证数据丢失发生过拟合(约 100000 步)并中断训练,推理也显示出性能的急剧下降,因此在过拟合之前,通过检查点的评估和验证来选择模型。
3.8 B使用Pipeline 并行化 batch size: 1024,1.3 与 100000 步一样,过拟合发生在大约 100000 步时.
5.8B 使用 流水线并行化 批量大小:256,批量较小,因此最多 320000 步没有过拟合,训练完成
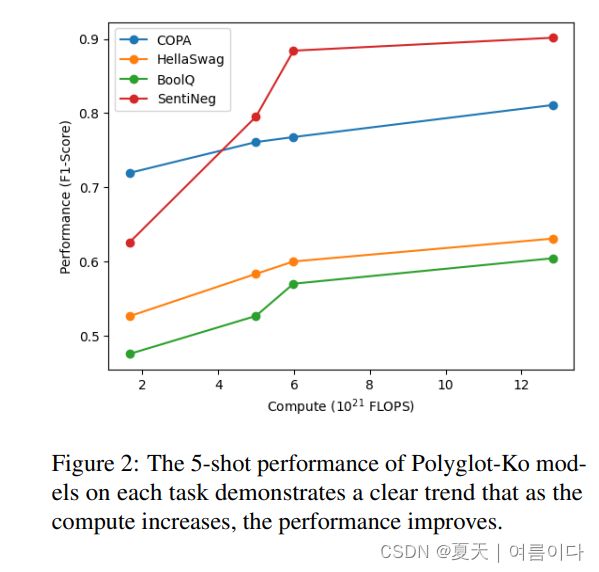
随着步骤的进展提高模型性能.
4.实验
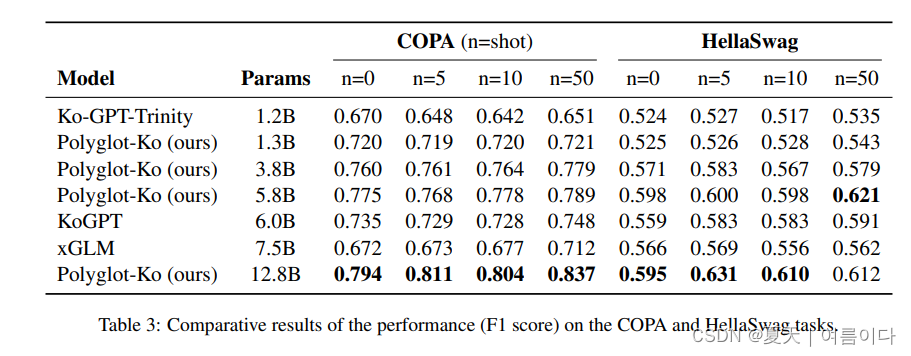
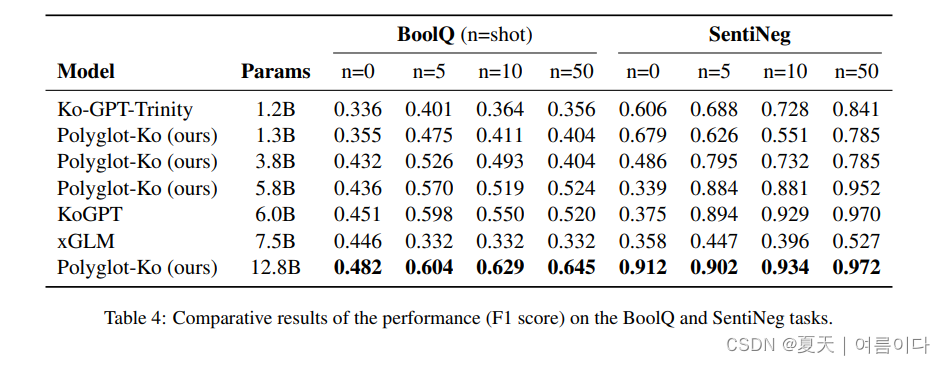
验证了KOBEST数据集,在五个下游任务中
- COPA
- HellaSwag
- BoolQ
- SentiNeg
- WiC
5.检查点合并和模型上传
将训练好的模型上传到 huggingface
GPT-NeoX 检查点需要合并为一个检查点,并转换为 Hugging Face Transformers 格式
为此创建一个脚本,并按照以下步骤操作。
- Creater 配置文件:GPT-NeoX 在 Hugging Face Transformer 中不可用。将特定于模型的参数放在 config.json 中。它不包括训练过程中使用的训练参数。
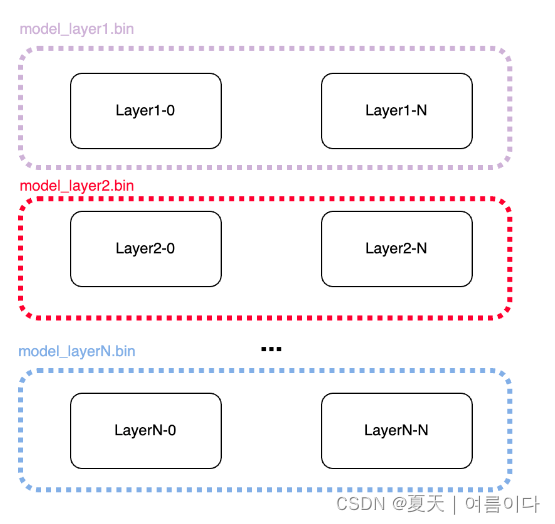
- 按层合并模型:合并划分的检查点。根据一层中每个 GPU 排序的张量在主进程 (GPU0) 中合并为单个检查点。(例如model_layer_1.bin)
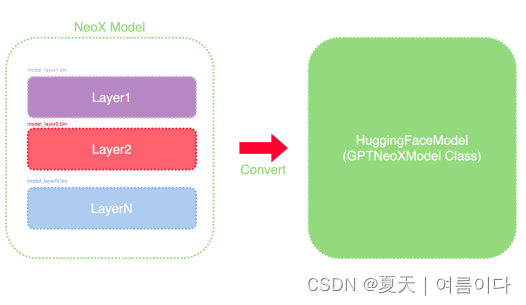
合并和转换模型检查点:使用 Hugging Face Transformer 的键将存储在每层楼一个文件中的 chekpoints 保存为状态字典。
论文总结
使用韩国数据进行预训练的 Polyglot-ko 模型,在通过各种预处理方法处理了 TUNiB 收集的 1.2TB 韩国数据后进行了预训练。只是一份报告,所以并没有什么创新点。
训练环境建议:4台RTX3090(4090/A5000)
基础知识点
MeCab
eunjeon / mecab-ko-dic — Bitbucket
형태소 분석기 mecab-ko 설치 + 사전 적용(+우선순위 높이기) :: 듐듐다다 (tistory.com)
RoPE
旋转位置编码(Rotary Position Embedding,RoPE)是论文Roformer: Enhanced Transformer With Rotray Position Embedding 提出的一种能够将相对位置信息依赖集成到 self-attention 中并提升 transformer 架构性能的位置编码方式。而目前很火的 LLaMA、GLM 模型也是采用该位置编码方式。
参考文献
【2】언어 천재가 된 AI, 다국어(Polyglot) 모델 (2) (letr.ai)
【3】한국어 (초)거대 공개 언어모델 - Polyglot, KoGPT (tistory.com)
【4】[OpenFlaminKO] - Polyglot-KO를 활용한 한국어 기반 MultiModal 도전기! (tistory.com)
【5】十分钟读懂旋转编码(RoPE) - 知乎 (zhihu.com)
【6】qwopqwop/KoAlpaca-Polyglot-12.8B-GPTQ at main (huggingface.co)