1,演示视频
https://www.bilibili.com/video/BV1nj41157L3/
Yi-34B(4):使用4个2080Ti显卡11G版本,运行Yi-34B模型,5年前老显卡是支持的,可以正常运行,速度 21 words/s
2,关于2080TI,5年前老显卡是支持的
NVIDIA GeForce RTX 2080Ti参数
显存容量: 11264MB 显存位宽:
352bit 核心频率: 1350/1635MHz 显存频率: 14000MHz
发布日期 2018年04月
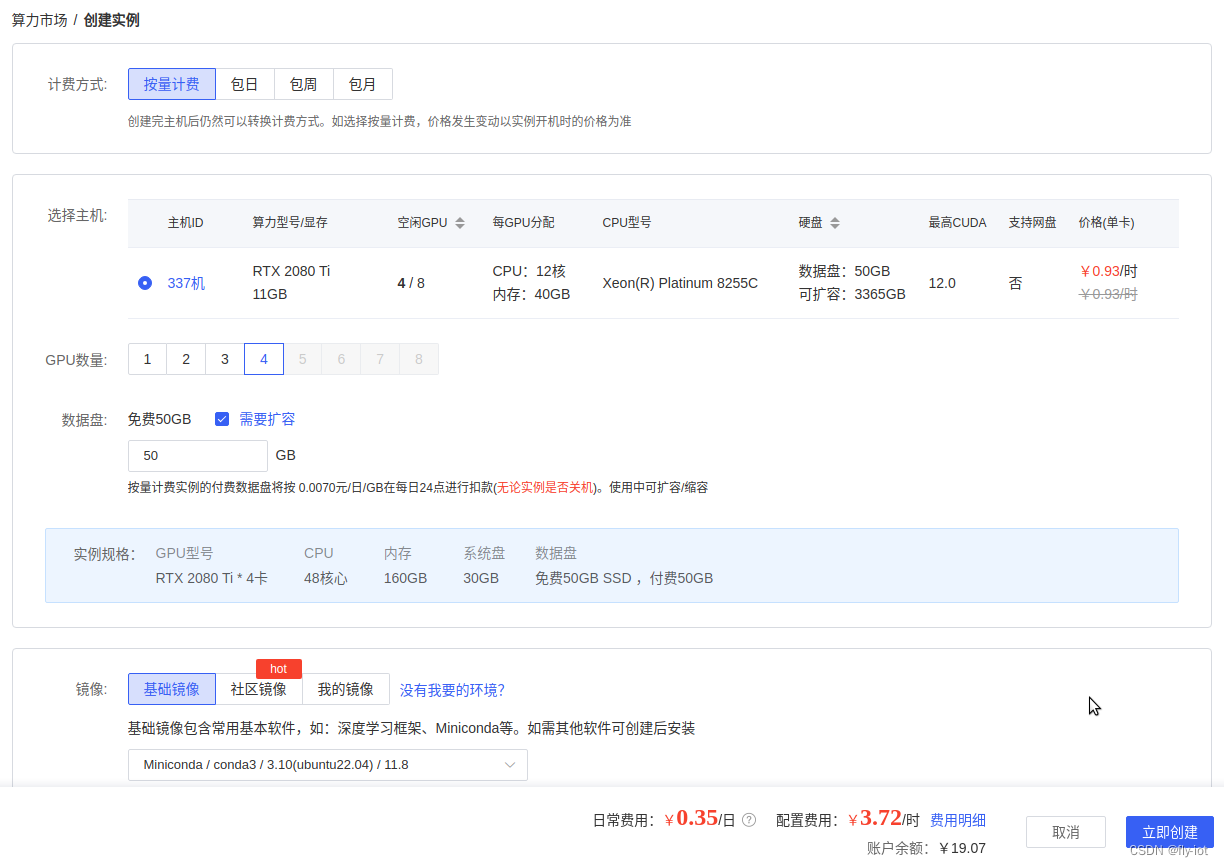
环境使用:
CPU :12 核心
内存:40 GB
GPU :NVIDIA A40, 1个
可以支持,理论上 7.0 算力的都支持。
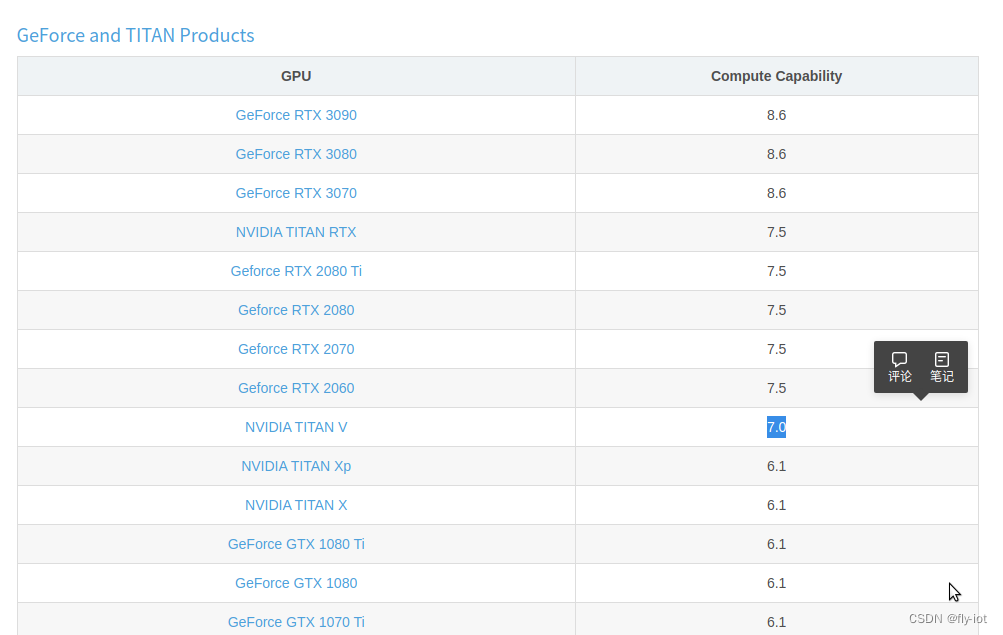
主要是vllm 支持就行:
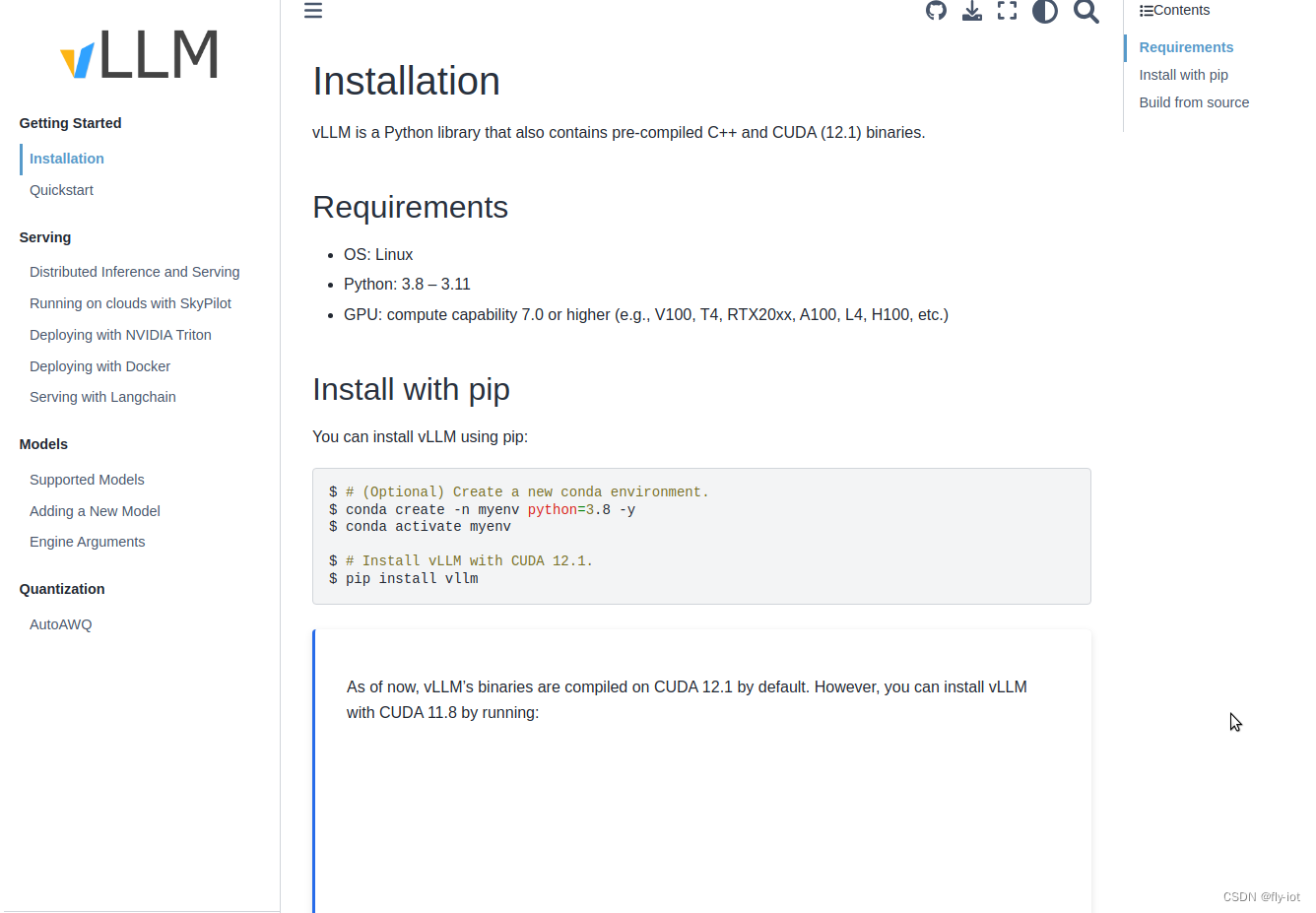
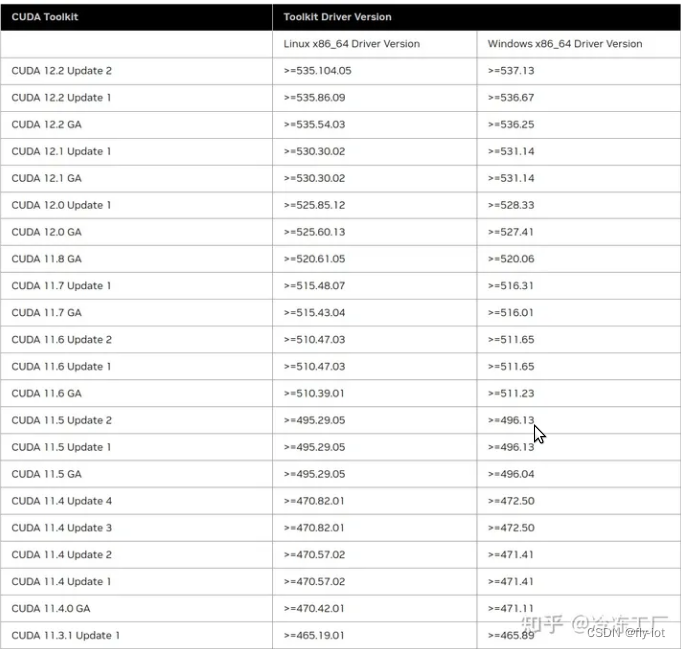
autodl cuda 12.0 驱动 525
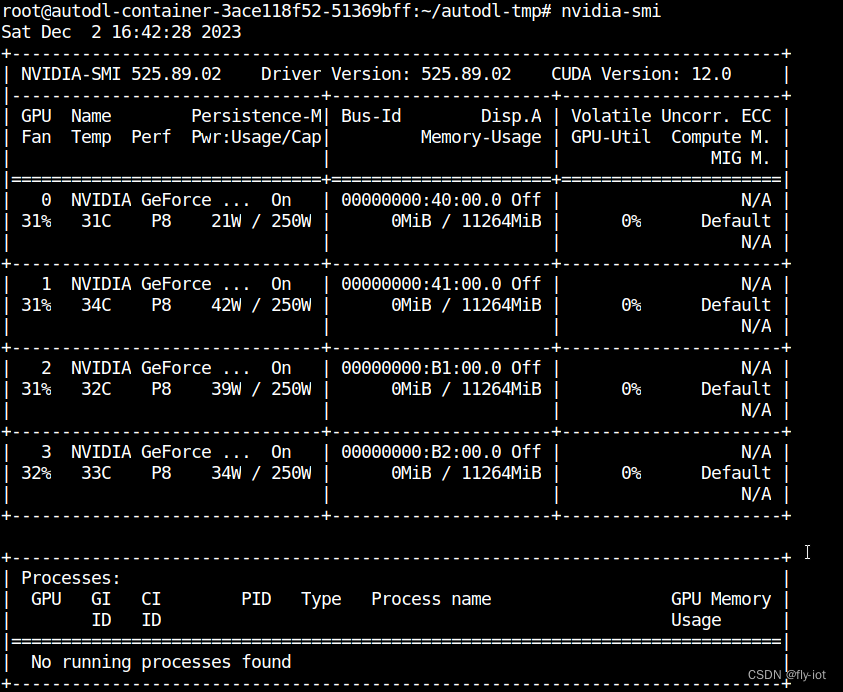
3,关于 Yi-34B 模型
11月24日,零一万物基正式发布并开源微调模型 Yi-34B-Chat,可申请免费商用。同时,零一万物还为开发者提供了 4bit/8bit 量化版模型,Yi-34B-Chat 4bit 量化版模型可以直接在消费级显卡(如RTX3090)上使用。
但是人家没有说是一张就行,经测试需要 42G 显存
官方网站:
https://www.lingyiwanwu.com/
模型下载地址:
https://huggingface.co/01-ai/Yi-34B-Chat-8bits
github地址:
https://github.com/01-ai/Yi
下载后占空间:
72G Yi-34B-Chat-4bits
3,使用autodl创建环境,安装最新的torch,vllm,fastchat
apt update && apt install -y git-lfs net-tools
# 一定要保证有大磁盘空间:
cd /root/autodl-tmp
git clone https://www.modelscope.cn/01ai/Yi-34B-Chat-4bits.git
# 1,安装 torch 模块,防止依赖多次下载
pip3 install torch==2.1.0
# 2,安装 vllm 模块:
pip3 install vllm
# 最后安装
pip3 install "fschat[model_worker,webui]" auto-gptq optimum
安装完成之后就可以使用fastchat启动了。
4,使用 vllm 进行加速,可以加速 Yi-34B-Chat-4bits 模型
https://docs.vllm.ai/en/latest/getting_started/installation.html
官方网站:https://github.com/vllm-project/vllm
说明模型不支持这个 vllm ,需要切换成 Yi-34B-Chat-4bits 可以启动
ValueError: Unknown quantization method: gptq. Must be one of ['awq', 'squeezellm'].
增加参数:fastchat.serve.vllm_worker --quantization awq
就可以切换成 fastchat 的 vllm 模式:
# run_all_vllm_yi.sh
# 清除全部 fastchat 服务
ps -ef | grep fastchat.serve | awk '{print$2}' | xargs kill -9
sleep 3
rm -f *.log
# 首先启动 controller :
nohup python3 -m fastchat.serve.controller --host 0.0.0.0 --port 21001 > controller.log 2>&1 &
# 启动 openapi的 兼容服务 地址 8000
nohup python3 -m fastchat.serve.openai_api_server --controller-address http://127.0.0.1:21001 \
--host 0.0.0.0 --port 8000 > api_server.log 2>&1 &
# 启动 web ui
nohup python -m fastchat.serve.gradio_web_server --controller-address http://127.0.0.1:21001 \
--host 0.0.0.0 --port 6006 > web_server.log 2>&1 &
## 启动 worker
nohup python3 -m fastchat.serve.vllm_worker --quantization awq --model-names yi-34b \
--model-path ./Yi-34B-Chat-4bits --controller-address http://127.0.0.1:21001 \
--worker-address http://127.0.0.1:8080 --host 0.0.0.0 --port 8080 > model_worker.log 2>&1 &
解决问题:
## GPU 显存不够 忘记设置 :--num-gpus 4
2023-12-02 19:52:38 | ERROR | stderr | torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 140.00 MiB. GPU 0 has a total capacty of 10.75 GiB of which 132.50 MiB is free. Process 314866 has 10.62 GiB memory in use. Of the allocated memory 9.89 GiB is allocated by PyTorch, and 11.06 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
## 设置 --max-model-len 2080 解决,开启不了4096太大。
2023-12-02 20:00:07 | ERROR | stderr | logits = torch.matmul(hidden_states, embedding.t())
2023-12-02 20:00:07 | ERROR | stderr | RuntimeError: CUDA error: CUBLAS_STATUS_NOT_INITIALIZED when calling `cublasCreate(handle)`
然后在测试下 token 效果:
python3 -m fastchat.serve.test_throughput --controller-address http://127.0.0.1:21001 --model-name yi-34b --n-thread 1
Models: ['yi-34b']
worker_addr: http://127.0.0.1:8080
thread 0 goes to http://127.0.0.1:8080
Time (POST): 67.61790823936462 s
Time (Completion): 67.61794185638428, n threads: 1, throughput: 21.84331494645376 words/s.
5,总结
测试效果还可以,但是偶尔出现英文,需要说明强制转换成中文:
curl http://localhost:6006/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "chatglm3-6b",
"messages": [{"role": "user", "content": "北京景点,使用中文回答"}],
"temperature": 0.7
}'